打破“形似”桎梏,OmniHuman-1.5让数字人“由内而外”活起来。
当前视频角色模型虽能生成流畅动画,却困于“低级同步”陷阱——动作仅与音频节奏机械匹配,难以捕捉情感、意图等深层语义,导致角色缺乏真实灵魂。为突破这一瓶颈,字节跳动与谷歌联合提出的OmniHuman-1.5框架,以“双系统认知架构”重新定义角色动画生成逻辑。
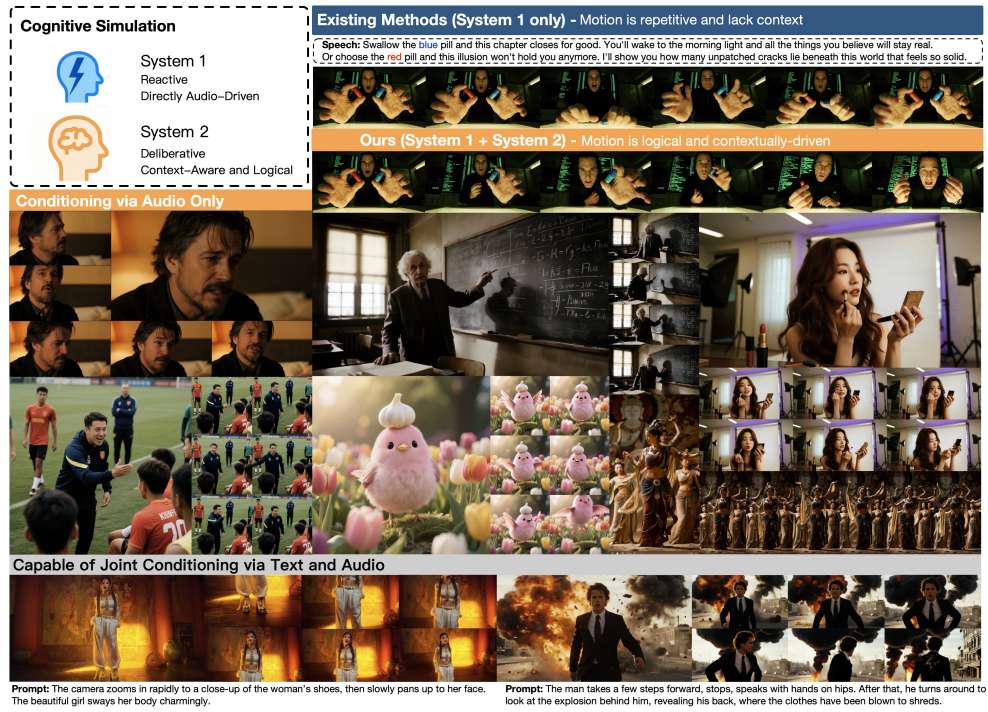
该模型通过多模态大语言模型(MLLM)合成结构化文本语义,赋予动作生成器对语境与情感的感知能力,使角色动作从“节奏同步”升级为“情感共鸣”。在口型同步、视频质量、运动自然度及语义一致性上全面领先,更可扩展至多人交互、非人类角色等复杂场景,为影视动画、虚拟社交等领域带来颠覆性可能。
双虚拟系统
OmniHuman-1.5 仅通过一张图片和一条语音轨道,即可生成富有表现力的角色动画,这些动画与语音的节奏、韵律和语义内容相一致,并可选配文本提示以供进一步完善。受大脑“系统 1 和系统 2”认知理论的启发,我们的架构连接了多模态大型语言模型和扩散变换器,模拟了两种不同的思维模式:缓慢、深思熟虑的计划和快速、直觉的反应。这种强大的协同作用使得生成超过一分钟的视频成为可能,其中包含高度动态的动作、连续的摄像机运动以及复杂的多角色交互。
节奏表演
这种多功能性延伸到了音乐领域,我们的框架只需一张图片和一首歌,就能打造出一位充满灵魂的数字歌手。在推理模块的驱动下,该动作能够捕捉丰富的音乐表达,而不仅仅是唇形同步,包括自然的停顿和停顿,从而熟练地处理从独唱民谣到轻快音乐会的各种风格。
情感表演
只需一张图片和一段音频,就能赋予数字演员生命。无需文字提示,通过分析音频的情感潜台词,它能够生成引人入胜、具有电影般张力的表演,涵盖从爆发性的愤怒到真挚的告白等各种戏剧性场景。
情境感知音频驱动动画
模型通过解释音频的语义背景超越了简单的口型同步和重复的手势,使角色能够表现出真实的情绪变化,并将手势与他们的言语和意图相匹配,就好像由他们自己的意志驱动一样。
文本引导的多模式动画
接受文本提示并展示出色的提示跟踪,从而能够精确控制对象生成、摄像机移动和特定动作,同时保持完美的音频同步。
多人场景表演
我们的框架可扩展到复杂的多人场景。它通过将单独的音轨路由到单帧中正确的角色,生成动态的群组对话和合奏表演。
多样化输入带来更多结果
我们的模型通过生成涵盖各种主题(包括真实动物、拟人人物和风格化卡通)的高质量同步视频,展现了真正的稳健性。
相关链接
论文:https://arxiv.org/pdf/2508.19209
主页:https://omnihuman-lab.github.io/v1_5/
论文介绍

当前视频角色模型虽能生成流畅动画,却困于“低级同步”陷阱——动作仅与音频节奏机械匹配,难以捕捉情感、意图等深层语义,导致角色缺乏真实灵魂。 为突破这一瓶颈,字节跳动与谷歌联合提出的OmniHuman-1.5框架,以“双系统认知架构”重新定义角色动画生成逻辑。
该模型通过多模态大语言模型(MLLM)合成结构化文本语义,赋予动作生成器对语境与情感的感知能力,使角色动作从“节奏同步”升级为“情感共鸣”;同时,创新的多模态DiT架构与“伪最后一帧”设计,有效融合音频、图像、文本特征,缓解模态冲突,确保生成动作与角色设定、场景逻辑高度一致。 实验表明,其在口型同步、视频质量、运动自然度及语义一致性上全面领先,更可扩展至多人交互、非人类角色等复杂场景,为影视动画、虚拟社交等领域带来颠覆性可能。
方法概述
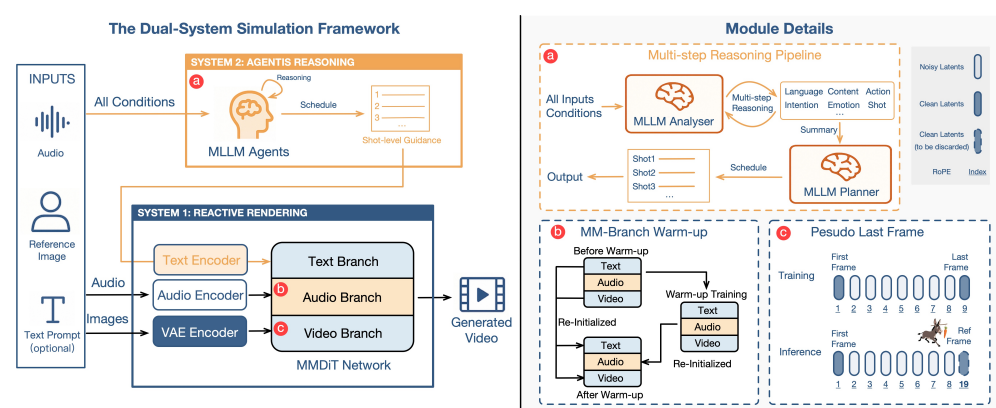
传统数字人模型(如音频驱动动画)如同人类的“System1”——依赖直觉快速反应,却缺乏对情绪、意图和语境的深层理解。而OmniHuman-1.5首次引入“双系统架构”:
System1(反应系统):通过多模态扩散变换器(MMDiT)实现唇形同步、基础动作生成等实时反应;
System2(认知系统):利用多模态大语言模型(MLLM)模拟人类推理过程,生成符合逻辑的高层次语义指导。
这一设计让数字人不仅能“动起来”,更能“想明白”——比如根据对话内容自然切换表情,甚至在多人场景中协调动作优先级。
三大核心设计
多模态语义融合:通过“伪最后一帧”策略,将参考图像转化为动态引导信号,避免静态图像对运动范围的限制;
跨模态冲突缓解:采用对称的多模态分支架构,让音频、文本、视频特征在共享语义空间中深度对齐;
反思性重规划:在长视频生成中,模型会动态评估已生成内容,修正逻辑偏差(如避免“擦桌子”动作后物体消失的穿帮)。
实验结果
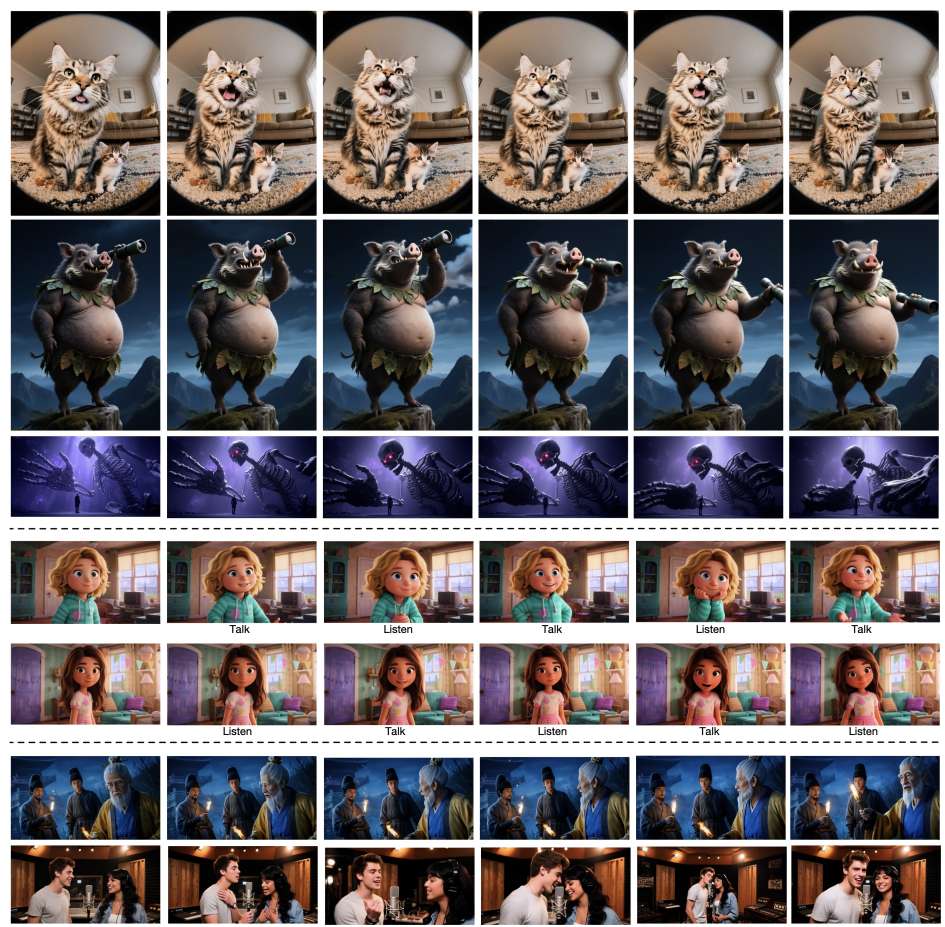
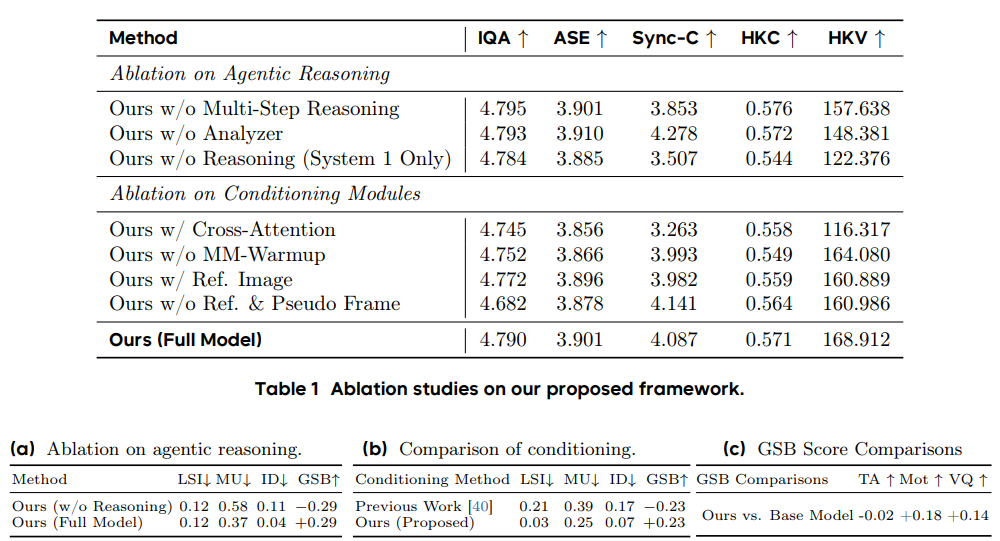
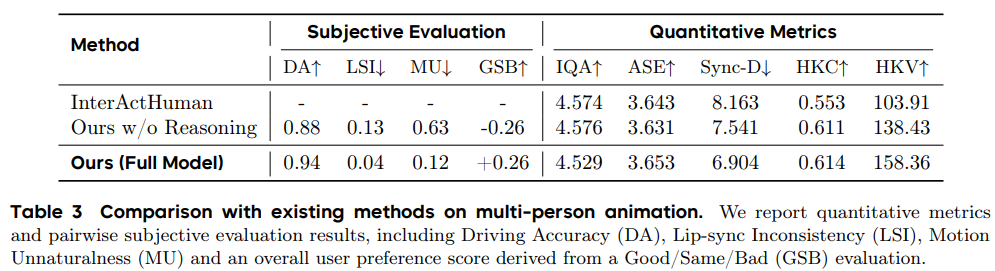
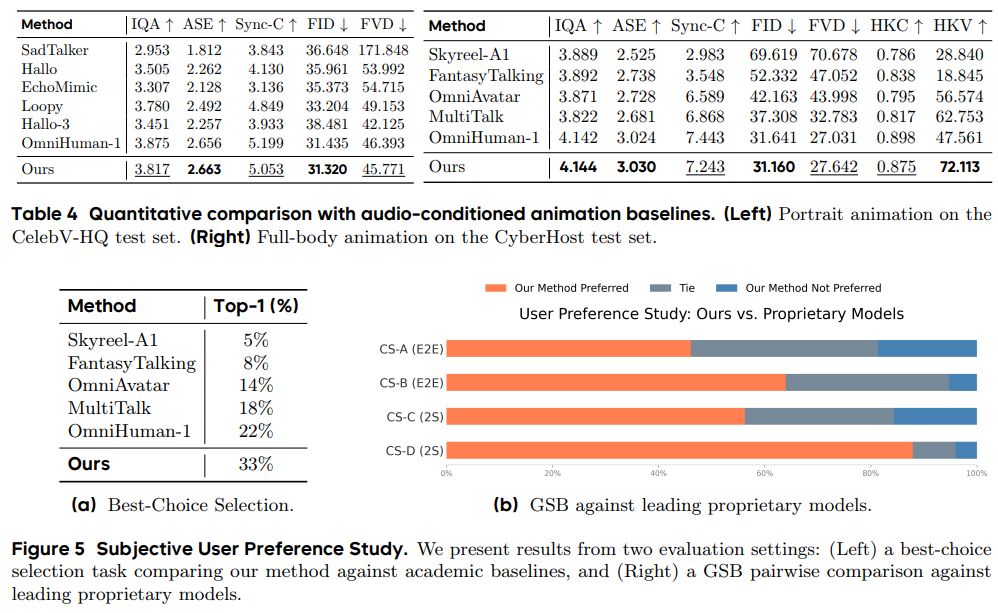
在包含150个单主体案例和57个多主体场景的测试中,OmniHuman-1.5的唇形同步精度、视频质量、动作自然度及文本语义一致性均达到行业领先水平。尤其在复杂场景(如多人对话、非人类角色)中,用户对其“上下文合理性”的偏好度比第二名高出33%,甚至能精准还原“施法时水晶球发光”等细节指令。
未来已来:从影视制作到实时交互 这项技术不仅为AI驱动的电影生产、音乐视频创作开辟新可能,更通过实时反射机制支持多角色场景的动态协调。研究团队已公开项目页面([链接]),并呼吁行业建立AI生成内容的可见水印、输入过滤等伦理框架,防止技术滥用。
结语
OmniHuman-1.5框架通过两项关键创新,额外模拟了深思熟虑的“系统2”流程:一个基于MLLM的语义规划代理,以及一个专门的MMDiT架构,该架构采用新颖的伪末帧策略来融合多模态信号。实验表明该方法可以生成更具表现力和逻辑一致性的结果,这些结果因其自然性和可信度而受到用户的青睐。