PostgreSQL的逻辑复制spill溢出案例和启停库逻辑
本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:刘智龙。
引言
在数据库运维过程中,停库与起库是绕不开的核心环节。然而,在复杂的生产环境中,这些操作并非总能顺利完成。以下结合实际案例,对 PostgreSQL 在停库和起库过程中可能遇到的典型问题进行技术剖析。
WALsender、archiver 如何优雅阻止停库
WALsender 阻止停库
在逻辑复制场景下,WALsender 进程会阻止数据库停库,此时仅保留 checkpointer 和 WALsender 等关键进程,控制文件状态显示为 in production,表明数据库仍处于运行中。
WALsender 阻止停库时,数据库的停库状态:

此时的控制文件:

在停库过程中,WALsender 进程卡在WalSndWaitStopping函数,导致 checkpointer 也被阻塞在该函数中,数据库因此停在“半停库”状态。若此时强行执行 kill-9,将造成数据库以非一致性方式停库。

怎么优雅的停库
在逻辑复制场景下,WALsender 进程可能阻止数据库停库。常见处理方案有两种:
方案一:关闭下游进程

- 执行
ALTER SUBSCRIPTION sub_lzl DISABLE;—需提前找到所有关联的下游 PG 库。 - 停止同步工具—同步工具可能无法及时维护。
方案二:发送 SIGTERM 给 WALsender
可直接向 WALsender 进程发送 SIGTERM 信号,使其正常退出。
running 状态:
select pg_terminate_backend($WALsender_pid)
「pg_terminate_backend() 本质上就是在发送 SIGTERM 给子进程」
停一半的状态:
kill -SIGTERM $WALsender_pid
同 kill -15 $WALsender_pid
同 kill $WALsender_pid
archiver 阻止停库
除了 WALsender 外,常见的还有 archiver 进程也可能阻止停库。reaper checkpointer 会发送 SIGUSR2 给 archiver 让其最后一次归档并退出:

PM 进程的退出依赖于归档进程:

在模拟归档场景时可以看到,停库状态与 WALsender 阻止停库的情况并不相同:此时存在 archiver 进程,但 checkpointer 进程并未出现,表现出不同的停库特征:

可能的原因:归档延迟较多,归档盘写入较慢。
不可能的原因:归档失败,NUM_ARCHIVE_RETRIES限制。
此时暴力停库是否有问题?
当只有 archiver 进程阻止停库时,checkpointer已完成停止操作,shutdown checkpoint 条目已写入 WAL,controldata 状态为 shut down,表明数据库已实现一致性停库。此时,即使 archiver 仍在运行,执行 kill-9 也不会影响数据库本身的完整性。
怎么优雅的停库
在数据库停库时,可以通过以下操作实现更安全可控的关闭流程:
- 锁定逻辑同步用户。
- 执行
pg_terminate_backend($logical_WALsender);。 - 临时关闭归档(可选,将 archive_command 置空)。
- 手动执行 checkpoint。
- 执行 stop fast。
- 如果仅有 archiver 阻止停库,可以考虑暴力停库。
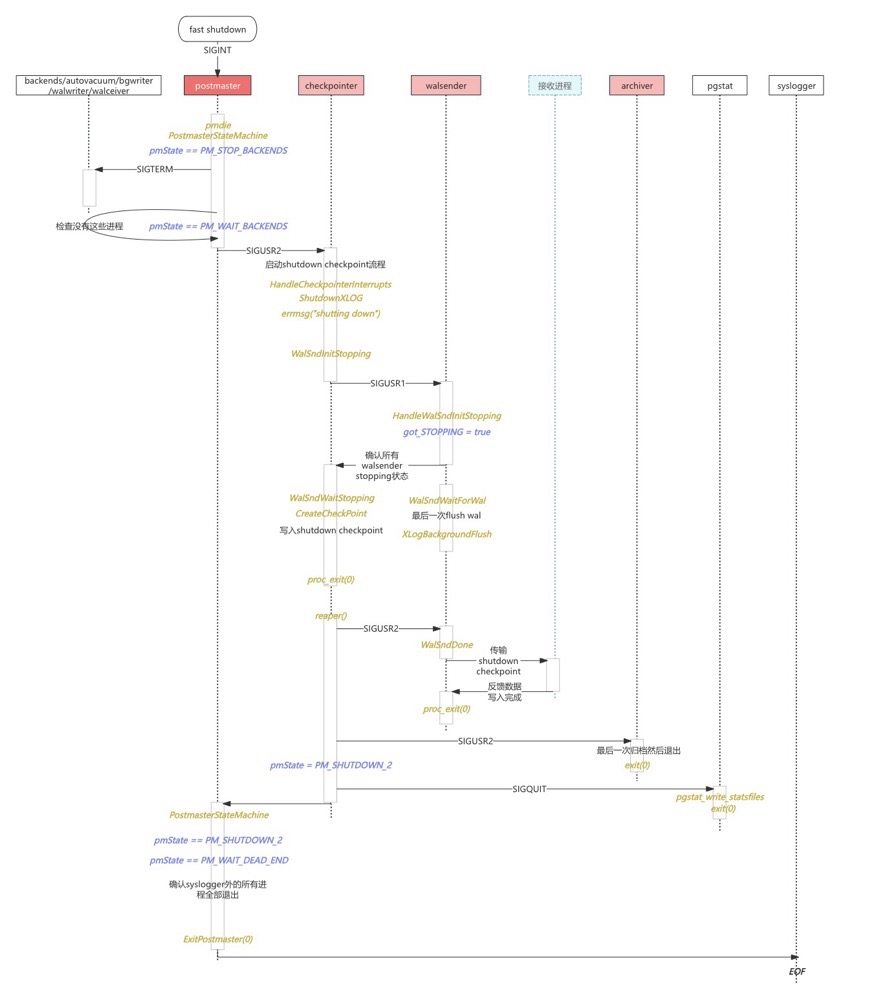
PostgreSQL 停库逻辑
停库的信号机制
PostgreSQL 的停库依赖操作系统的信号机制。在 Linux 中,进程间可以通过信号进行通信,系统也定义了多种信号来控制进程的行为。
PG 常用的信号包括:

pg_ctl 通过信号管理停库方式

pg_ctl 通过发送不同的信号来控制PostgreSQL的停库方式。其中,kill -9(SIGKILL)与 pg_ctl stop -m immediate是不同的:
- pg_ctl 不支持直接发送 SIGKILL。虽然可以手动向 PM 进程发送 SIGKILL ,但这种方式不推荐,因为 PM 在收到 SIGKILL 时不会对子进程、共享内存或信号做任何清理工作。
- SIGQUIT 停库更安全。当 PM 收到 SIGQUIT 时,会触发兜底逻辑,对子进程发送
SIGKILL,并做必要清理,从而基本保证数据库能完整停下来。
PM 注册的信号
接收到该信号后,会调用两个关键函数:pmdie 和 reaper,分别用于处理关闭逻辑与子进程回收。

子进程注册的信号(以 checkpointer 为例)
每个子进程都会注册信号,整体逻辑类似,仅根据职责略有差异。以 checkpointer 为例,它不屏蔽 SIGTERM,实际停止时使用 SIGUSR2 发出请求后再退出。

reaper 函数
reaper 是进程回收函数,子进程退出后会发送 pm SIGCHLD 信号,pm 通过 reaper 函数清理进程。 如 backend、startup、checkpointer 等进程都有自己的清理流程。
以 checkpointer 进程退出,reaper 回收为例:退出时会先判断归档进程是否存在,并向归档进程和 WALsender 发送 SIGUSR2,最后调用 PostmasterStateMachine() 完成状态转换。

pmdie 函数
pmdie 函数用于处理不同的 postmaster signals,包括子进程给 pm 发送的 SIGCHILD 和 pg_ctl 发送的停库信号。pm 信号处理主体逻辑是根据 signal 转换 pmState 状态机状态,并进入状态机 PostmasterStateMachine 处理。

PostmasterStateMachine 函数
PostmasterStateMachine 函数是处理 pm 退出的主体函数,主要是处理 pm 在不同停库状态下做什么。比如一般进程退出、WALsender、归档进程退出、异常退出等等状态。
正常停库时,除 checkpointer、archiver、stats 和 syslogger 外的子进程会收到 SIGTERM 并退出,然后向 checkpointer 发送 SIGUSR2 ,进入 SHUTDOWN 状态。
SHUTDOWN_2 状态在 checkpointer 退出时设置,等待 WALsender 和 archiver 完全退出,保证数据库一致性停库。

checkpointer 和 WALsender 的退出
checkpointer 进程在 pm 退出时会被唤醒做最后一次 shutdown checkpoint 等工作,但是创建 shutdown checkpoint 需要等 WALsender 全部进入退出状态。

WalSndWaitStopping会等待 WALsender 退出,如果不退出是死循环等待。

停库逻辑
Spill 阻止起库和加速起库
Spill 阻止起库
现象:数据库启动缓慢,startup 进程在读取 Spill 文件,文件名在变化。查看 Spill 文件也很慢,ls-l 最后跑出来 1000 万个文件 Spill 文件。
- 数据库虽然在启动,但整个过程非常耗时。
- 1000 万个 Spill 文件严重影响 Linux 系统性能,任何操作都很费劲。
问题关注点:
- 1000 万 Spill 文件是如何产生的?
- 当数据库起库受阻时,应采取什么措施?
Spill 怎么来的,怎么定位到 WAL 文件
Spill 文件主要由 WALsender 在事务溢出时生成。当定位到 Spill 文件后,可以写入 ReorderBuffer 存放在 replslot 目录下。
这些文件名中包含事务的相关信息,例如 xid。通过读取文件名中的 xid,就能追溯到对应事务的来源。

在定位某个 Spill 文件对应的 WAL 位置时,如果单纯依赖 xid 去过滤,面对上千万个事务显然效率极低。更可行的办法是结合 LSN 信息来定位。

Spill 怎么来的
Spill 文件生成规则如下:
- 同一个事务 id,如果跨 WAL 就会产生多个 Spill。如:一个不含子事务的大事务跨越 3 个 WAL,就会对应 3 个 Spill 文件。
- 不同的事务 id 对应不同的 Spill。如:1000w 个子事务对应 1000w 个 Spill。
例如:Spill 文件名结构xid-407989064-lsn-42D1E-20000000.Spill。

Spill 溢出逻辑的版本差异:
- PG12 及以前是固定 4096 条 changes 后触发 Spill。
- PG13 新增
logical_decoding_work_mem参数,可通过调整内存大小来降低 Spill 发生概率。 - PG14 及以后支持流式复制(Streaming),但仍需满足特定条件才能触发,因此并非完全避免 Spill。
- PG17 新增
debug_logical_replication_streaming参数以强制触发流式传输。
如何加速起库
库起不来怎么办?
数据库启动时的核心进程是 startup 进程,无论如何都会在起库时拉起。
当遇到非一致性停库时,startup 需要执行更多逻辑,其一便是 sync data 目录:根据控制文件状态触发对整个 data 目录的持久化操作,以确保在数据库重新运行前,所有数据文件处于一致状态。

因为控制文件状态显示为非正常停库,系统会进入 if 分支并调用 SyncDataDirectory() 执行 fsync 持久化操作,以确保在数据库重新运行前,data 目录已被完整持久化。
startup 除了执行 fsync data 外,还会处理与 Spill 相关的逻辑,其中关键一步是启动 ReorderBuffer。由于 Spill 文件对应的事务尚未完成,startup 会清理所有 replslot 目录下的 Spill 文件,确保复制槽状态恢复正常。

起库逻辑小结:
- PostgreSQL 在启动时会拉起一个专门的辅助进程 startup,不同于常见的子进程(如 WALwriter、checkpointer 等),它是起库过程中必定存在的核心进程,负责多项关键操作。
- StartupXLOG 在起库时必然会被调用,无论数据库是否一致性停库。
- 只有非正常停库状态下,才会触发
SyncDataDirectory。 - SyncDataDirectory 会 fsync 持久化所有 data 文件,并查看所有 data 文件的 stat 信息。
- fsync 用于保证库启动前数据文件一致性,stat 则用于验证文件的完整性和可读性(在 startup 进程启动前只验证过 datadir 目录可读性)。
- 无论停库状态如何,StartupReorderBuffer 都会被调用,用于清理所有复制槽中的 Spill 文件。
思考如何去加速起库?
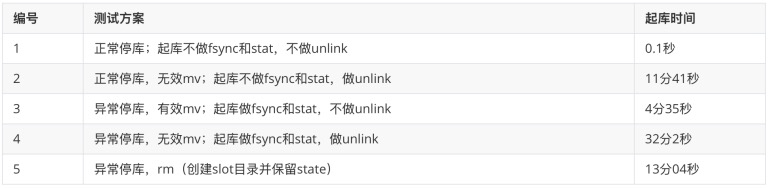
1000w 个 Spill 删除起来肯定是很慢的,直接 mv 目录的话就非常快。但是直接 mv 需要注意 mv 后的名称和 state 文件,以及需要知道 mv 到底跳过了哪一个源码步骤。
由于是异常停库,startup 进程会执行SyncDataDirectoryfsync和 stat 所有 data 文件,这一点是比较难绕过的。SyncDataDirectory 做完以后,才开始处理复制槽。处理复制槽时会调用StartupReorderBuffer()->ReorderBufferCleanupSerializedTXNs全量清理 Spill 文件。
在进入清理前,会调用ReplicationSlotValidateName校验复制槽名称的有效性,我们可以在ReplicationSlotValidateName上做文章,以骗过 startup 进程跳过ReorderBufferCleanupSerializedTXNs的过程。
当 Spill 文件数量达到千万级时,直接逐个删除会极其缓慢,而通过 mv 整个目录的方式则非常迅速。但此操作需注意:
- 目录改名后需保持与 state 文件 的一致性。
- 必须清楚 mv 跳过了源码中的哪些步骤,避免后续逻辑异常。
由于是异常停库,startup 进程会强制执行 SyncDataDirectory,对所有 data 文件进行 fsync 和 stat,这一环节无法绕过。SyncDataDirectory完成后,startup 才会处理复制槽,并调用:StartupReorderBuffer()->ReorderBufferCleanupSerializedTXNs
以全量清理 Spill 文件。
在进入清理流程前,会先调用ReplicationSlotValidateName校验复制槽名称的有效性。
因此,可以在该校验逻辑上“做文章”,让 startup 进程跳过ReorderBufferCleanupSerializedTXNs,从而避免耗时的 Spill 文件全量清理。
复制槽校验与清理
ReplicationSlotValidateName(const char *name, int elevel)
{...if (!((*cp >= 'a' && *cp <= 'z')|| (*cp >= '0' && *cp <= '9')|| (*cp == '_')))
...
}
- 有效 slot name 只包含 a-z;0-9;_。rename 时建议加个点.。
- 建议
slotname.bak,slotname.20241215等。 - 不建议
slotnamebackup,slotname20241215,slotname_bak等等。 - 不建议.tmp 后缀,slotname 有.tmp 后缀有特殊含义。
最后 rename 后,要创建目录和拷贝 state,不然启动的 slot 会表现的很反常(比如重复的 slotname、自动生产一个 slotname、删不到 slot、下游起不来链路等等)。
cd pg_replslot
mv slotname slotname.bak
mkdir slotname
cp slotname.bak/state slotname/
伪造 2000w 个 Spill 测试起库时间:
总结
数据库的停库与起库是运维中的关键环节,也是最容易遇到挑战的地方。通过本次分享,我们看到,无论是 WALsender、archiver 的阻止,还是大量 Spill 文件带来的起库延迟,都有对应的分析与解决思路。理解 PostgreSQL 的信号机制、启动流程以及复制槽管理,不仅能够帮助我们优雅停库、快速起库,也能在异常状态下保持数据一致性和系统稳定性。在实际运维中,将理论与操作结合,才能真正做到既安全又高效。