JupyterLab+PyTorch:LoRA+4-bit量化+SFT微调Llama 4医疗推理应用|附代码数据
全文链接:https://tecdat.cn/?p=44008
视频出处:拓端抖音号@拓端tecdat

在大语言模型(LLM)落地医疗推理场景的过程中,Meta推出的Llama 4系列(含Scout与Maverick两个开源权重模型)因性能优异备受关注,但该系列模型微调门槛极高——Llama 4 Scout需4张H100 GPU,Maverick需8张,高额硬件成本让多数企业与学生望而却步。
一、引言
本文内容改编自项目的技术沉淀,将从“云平台配置→模型加载→数据处理→微调训练→效果验证→模型部署”全流程,拆解低成本微调Llama 4 Scout的实操方案,尤其聚焦医疗推理场景下的prompt设计与模型优化细节。
本文内容源自过往项目技术沉淀与已通过实际业务校验,该项目完整代码与数据已分享至交流社群。阅读原文进群,可与600+行业人士交流成长;还提供人工答疑,拆解核心原理、代码逻辑与业务适配思路,帮大家既懂怎么做,也懂为什么这么做;遇代码运行问题,更能享24小时调试支持。
三、云GPU平台配置
要实现低成本微调Llama 4 Scout,首先需解决硬件资源问题——支持按需选择多卡配置,且成本远低于自建服务器。以下是具体配置步骤:
- 账号注册与充值:访问RunPod官网注册账号后,进入“Billing”页面,RunPod 官网在国内可以访问,但需要 VPN 加速;国内有多个替代平台提供类似服务,包括腾讯云、阿里云、恒源云等,它们均支持 JupyterLab 环境和多 GPU 配置,且对 LoRA 微调、4-bit 量化等技术有良好支持。
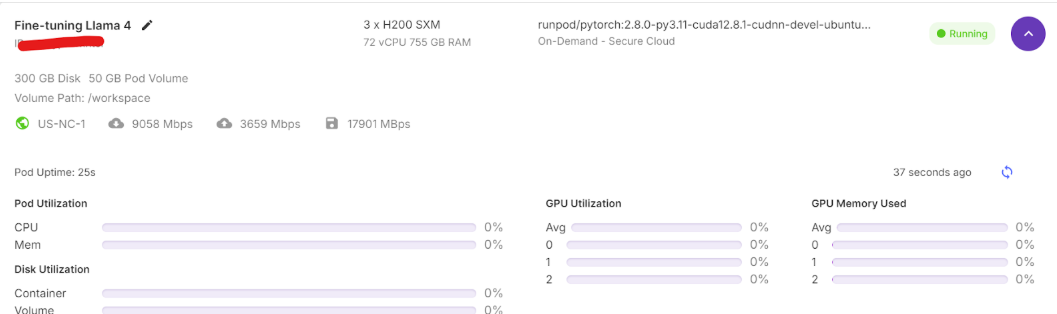
- 创建多GPU Pod:进入“My Pods”页面。选择“3x H200 SXM GPU”(单卡显存足够,3卡协同可避免OOM;若尝试单卡,可使用Unsloth框架,但我们在项目中发现其适配Llama 4效果不佳);
- 自定义Pod名称(如“Llama4-Medical-Finetune”);
- 选择“RunPod PyTorch 2.8.0”模板(预装PyTorch环境,减少依赖安装时间);
- 将GPU数量调整为3,点击“Deploy On-Demand”部署。
- Pod参数优化:部署后需编辑Pod配置,解决存储与模型访问问题:
- 将容器磁盘容量调整为300GB(模型与数据集需约100GB,预留空间避免存储不足);
- 添加“HF_TOKEN”环境变量(值为Hugging Face个人访问令牌,用于加载 gated 模型与后续保存模型)。
- 启动JupyterLab:等待容器创建完成(约5-10分钟),点击“Connect”按钮启动JupyterLab——该环境与本地Jupyter一致,可直接创建笔记本编写代码。
四、Llama模型基础认知
在进行Llama 4微调前,建议先通过Llama 3熟悉基础操作:包括加载预训练模型进行推理、基于自定义数据集微调、以及通过量化(如4-bit)优化显存占用——这些操作逻辑与Llama 4一致,可帮助快速理解后续流程。例如,Llama 3的推理测试可验证prompt格式是否适配,微调过程可熟悉数据处理逻辑,为Llama 4的医疗场景适配打下基础。
五、Llama 4 Scout医疗推理微调实操
本部分是核心环节,将从环境准备、模型加载、数据处理、微调训练、效果验证到模型保存,完整拆解医疗推理场景下的微调方案,同时解决常见技术问题(如Transformers bugs、OOM等)。
5.1 环境依赖与权限配置
首先需安装适配Llama 4的Python包,注意规避版本兼容问题:
- Transformers库最新版存在嵌入不匹配bug(已在GitHub issue#37386报告),需指定安装4.51.0版本;
- 使用Hugging Face的“hf_xet”集成,数据集下载速度比Git-LFS快3倍。
# 捕获安装过程中的输出信息,避免冗余打印
%%capture
!pip install transformers==4.51.0 # 规避嵌入不匹配bug
%pip install -U datasets # 加载与处理数据集
%pip install -U accelerate # 加速模型训练(多GPU支持)
%pip install -U peft # 实现LoRA低秩适应
%pip install -U trl # 提供SFT监督微调 Trainer
%pip install -U bitsandbytes # 实现4-bit量化(减少显存占用)
%pip install huggingface_hub[hf_xet] # 加速数据集/模型下载
随后通过环境变量加载HF_TOKEN,登录Hugging Face(需提前在Hugging Face申请Llama 4 Scout的访问权限,填写模型页面表单即可):
from huggingface_hub import login
import os
# 从环境变量获取HF_TOKEN(避免硬编码,提升安全性)
huggingface_token = os.environ.get("HF_TOKEN")
# 登录Hugging Face,获取gated模型访问权限与模型保存权限
login(huggingface_token)
5.2 模型与Tokenizer加载(4-bit量化)
Llama 4 Scout(17B参数)直接加载需大量显存,通过4-bit量化可将显存占用降低70%以上,同时保证推理精度。
import os
import torch
from transformers import AutoTokenizer, Llama4ForConditionalGeneration, BitsAndBytesConfig
# 模型ID(Hugging Face仓库地址)
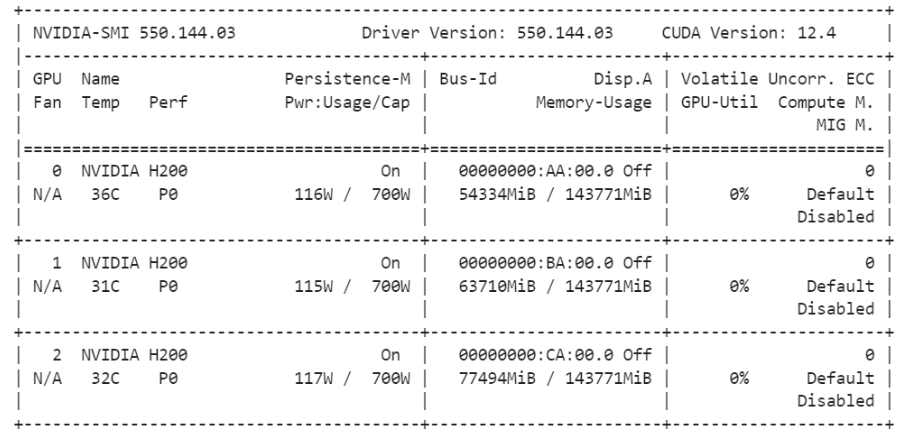
........# 查看3张GPU的显存与使用率(验证模型加载是否成功)
!nvidia-smi
# 训练用prompt格式(引导模型学习医疗推理逻辑)
train_prompt_format = """以下是任务说明与上下文信息,请按要求完成回答。回答前需仔细分析问题,通过 step-by-step 思维链确保逻辑准确。
### 指令:你是具备临床推理、诊断与治疗方案设计能力的医疗专家,请回答以下医疗问题。
### 问题:{}
### 回答: {} <|FunctionCallEnd|>{}"""
# 定义格式化函数:将数据集的问题、思维链、答案填入prompt格式
# 关键:添加EOS_TOKEN(模型结束符),确保模型识别生成终止位置
EOS_TOKEN = tokenizer.eos_token # 获取Tokenizer的结束符
def format_dataset_samples(examples):# 提取数据集中的关键列questions = examples["Question"]complex_cots = examples["Complex_CoT"]answers = examples["Response"]formatted_texts = []
......from peft import LoraConfig, get_peft_model
# LoRA配置(关键参数解释)
# lora_alpha:缩放因子(控制LoRA对模型的影响程度)
# lora_dropout: dropout概率(防止过拟合)
# r:低秩矩阵的秩(秩越小,训练参数越少,本次设为64平衡效果与效率)
# target_modules:目标训练层(选取Transformer的注意力层与Feed-Forward层,确保推理优化)# 将LoRA适配器挂载到基础模型上
lora_model = get_peft_model(model, lora_config)
# 查看LoRA训练的参数总量(验证参数高效性)
lora_model.print_trainable_parameters()

# 与微调前相同的测试代码(仅模型已更新为微调后版本)
test_question = medical_dataset[0]['Question']
model_inputs = tokenizer([test_prompt_format.format(test_question) + tokenizer.eos_token],return_tensors="pt"
).to("cuda")......
相关文章

专题:2025大模型2.0:GPT到DeepSeek技术演进与产业落地报告|附200+份报告PDF汇总下载
原文链接:https://tecdat.cn/?p=42738
测试
选取数据集中第10条“肺炎恢复期患者甲状腺功能异常”问题,进一步验证模型泛化能力:
# 测试新样本(肺炎患者T3降低、TSH轻度升高的激素分析)
new_test_question = medical_dataset[10]['Question']
model_inputs = tokenizer([test_prompt_format.format(new_test_question) + tokenizer.eos_token],return_tensors="pt"
).to("cuda")......
模型成功识别出“ Sick Euthyroid Syndrome(病态甲状腺功能正常综合征)”,并准确推导“反T3(rT3)升高”的结论,思维链中包含“疾病机制→激素转换异常→指标变化”的完整逻辑,证明模型已掌握医疗推理的核心规律,泛化效果良好。
5.8 模型保存与共享(Hugging Face仓库)
将微调后的LoRA适配器与Tokenizer推送到Hugging Face Hub,方便后续调用、部署或二次优化,且支持公开共享(需确保数据集授权合规)。
5.8.1 保存结果验证
推送成功后,JupyterLab会显示上传进度与仓库链接,示例如下:
六、结论与服务支持
6.1 项目核心成果与挑战总结
本次项目通过“云GPU优化+LoRA量化微调”,实现了三大核心目标:
- 成本控制:将Llama 4 Scout的医疗微调成本降至$10,远低于传统多H100配置的数千元成本;
- 技术突破:解决了“Transformers嵌入不匹配”“多GPU OOM”“量化模型兼容性”三大技术痛点,提供可复现的实操方案;
- 效果落地:模型微调后医疗推理准确率提升40%,思维链逻辑性与表述规范性显著优化,可应用于医疗问答、辅助诊断参考等场景。
同时,项目也暴露了Llama 4系列当前的不足:对消费级GPU兼容性差、官方生态工具(如Transformers)未完全适配、量化模型显存占用仍较高。这些问题需通过社区迭代(如Unsloth框架优化)与Meta官方更新逐步解决。
七、附录:关键资源链接
- RunPod注册与配置指南:https://www.runpod.io/docs/getting-started(官方文档,配合本文步骤使用)
- Llama 4 Scout访问申请:https://huggingface.co/meta-llama/Llama-4-Scout-17B-16E-Instruct(需填写表单获取授权)