分词和词向量的学习记录
词向量工具
词向量和分词一样,也是自然语言处理中的基础性工作。词向量一方面解决了词语的编码问题,另一方面也解决了词的同义关系,使得基于LSTM等深度学习模型的自然语言处理成为了可能。和分词不同,中英文文本,均需要进行词向量编码。
目前用的较多的就是2013年google开源的工具 word2vec,它可以进行词向量训练,加载已有模型进行增量训练,求两个词向量相似度,求与某个词接近的词语,等等。功能十分丰富,基本能满足我们对于词向量的需求。
1.模型训练
词向量模型训练只需要有训练语料即可,语料越丰富准确率越高,属于无监督学习。
# gensim是自然语言处理的一个重要Python库,它包括了Word2vec
import gensim
from gensim.models import word2vec# 语句,由原始语句经过分词后划分为的一个个词语
sentences = [['网商银行', '体验', '好'], ['网商银行','转账','快']]# 使用word2vec进行训练
# min_count: 词语频度,低于这个阈值的词语不做词向量
# size:每个词对应向量的维度,也就是向量长度
# workers:并行训练任务数
model = word2vec.Word2Vec(sentences, size=256, min_count=1)# 保存词向量模型,下次只需要load就可以用了
model.save("word2vec_atec")
2.增量训练
针对垂直场景做特定语义增量训练。
# 先加载已有模型
model = gensim.models.Word2Vec.load("word2vec_atec")# 进行增量训练
corpus = [['网商银行','余利宝','收益','高'],['贷款','发放','快']] # 新增语料
model.build_vocab(corpus, update=True) # 训练该行
model.train(corpus, total_examples=model.corpus_count, epochs=model.iter)# 保存增量训练后的新模型
model.save("../data/word2vec_atec")
3.求词语相似度
通过余弦向量夹角来判定,夹角越小相似度越高。
# 验证词相似程度
print model.wv.similarity('花呗'.decode('utf-8'), '借呗'.decode('utf-8'))
4.求与词语相近的多个词语
for i in model.most_similar(u"我"):print i[0],i[1]
词向量训练算法
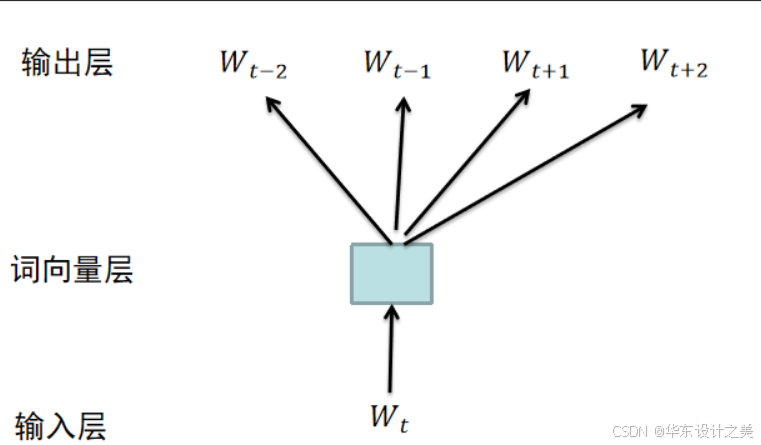
词向量可以通过使用大规模语料进行无监督学习训练得到,常用的算法有CBOW连续词袋模型和skip-gram跳字模型。二者没有本质的区别,算法框架完全相同。区别在于,CBOW利用上下文来预测中心词。而skip-gram则相反,利用中心词来预测上下文。比如对于语料 {“The”, “cat”, “jump”, “over”, “the”, “puddle”} ,CBOW利用上下文{“The”, “cat”, “over”, “the”, “puddle”} 预测中心词“jump”,而skip-gram则利用jump来预测上下文的词,比如jump->cat, jump->over。一般来说,CBOW适合小规模训练语料,对其进行平滑处理。skip-gram适合大规模训练语料,可以基于滑窗随机选择上下文词语。word2vec模型训练时默认采用skip-gram。
词向量训练代码实现
基于skip-gram的词向量训练的代码实现,CBOW算法和skip-gram基本相同。代码来自TensorFlow官方教程。
# -*- coding: utf-8 -*-
from __future__ import absolute_import
from __future__ import division
from __future__ import print_functionimport collections
import math
import os
import random
import zipfileimport numpy as np
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf# 1 下载语料文件,并校验文件字节数是否正确
url = 'http://mattmahoney.net/dc/'
def maybe_download(filename, expected_bytes):if not os.path.exists(filename):urllib.request.urlretrieve(url + filename, filename)statinfo = os.stat(filename)if (statinfo.st_size == expected_bytes):print("get text and verified")else:raise Exception("text size is not correct")return filenamefilename = maybe_download("text8.zip", 31344016)# 2 语料处理,弄成一个个word组成的list, 以空格作为分隔符。
# 如果是中文语料,这一步还需要进行分词
def read_data(filename):with zipfile.ZipFile(filename) as f:data = tf.compat.as_str(f.read(f.namelist()[0])).split()return datavocabulay = read_data(filename)
print("total word size %d" % len(vocabulay))
print("100 words at first: ", vocabulay[0:100])# 3 词表制作,根据出现频率排序,序号代表这个单词。词语编码的一种常用方式
def build_dataset(words, n_words):count = [["UNK", -1]]count.extend(collections.Counter(words).most_common(n_words - 1))dictionay = dict()for word, _ in count:# 利用按照出现频率排序好的词语的位置,来代表这个词语dictionay[word] = len(dictionay)# data包含语料库中的所有词语,低频的词语标注为UNK。这些词语都是各不相同的data = list()unk_count = 0for word in words:if word in dictionay:index = dictionay[word]else:index = 0unk_count += 1data.append(index)count[0][1] = unk_count # unk的个数# 将key value reverse一下,使用数字来代表这个词语reversed_dictionary = dict(zip(dictionay.values(), dictionay.keys()))return data, count, dictionay, reversed_dictionaryVOC_SIZE = 50000
data, count, dictionary, reversed_dictionary = build_dataset(vocabulay, VOC_SIZE)
del vocabulay
print("most common words", count[0:5])
# 打印前10个单词的数字序号
print("sample data", data[:10], [reversed_dictionary[i] for i in data[:10]])# 4 生成训练的batch label对
data_index = 0
# skip_window表示与target中心词相关联的上下文的长度。整个Buffer为 (2 * skip_window + 1),从skip_window中随机选取num_skips个单词作为label
# 最后形成 target->label1 target->label2的batch label对组合
def generate_batch(batch_size, num_skips, skip_window):global data_indexbatch = np.ndarray(shape=(batch_size), dtype=np.int32)labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)# 将skip_window的数据组合放入Buffer中span = 2 * skip_window + 1buffer = collections.deque(maxlen=span)for _ in range(span):buffer.append(data[data_index])data_index = (data_index + 1) % len(data) # 防止超出data数组范围,因为batch可以取很多次迭代。所以可以循环重复# num_skips表示一个Buffer中选取几个batch->label对,每一对为一个batch,故需要batch_size // num_skips个Bufferfor i in range(batch_size // num_skips):target = skip_windowtargets_to_avoid = [skip_window]# 一个Buffer内部寻找num_skips个labelfor j in range(num_skips):# 寻找label的位置,总共会有num_skips个labelwhile target in targets_to_avoid: # 中间那个为batch,不能选为target.也不能重复选targettarget = random.randint(0, span - 1)targets_to_avoid.append(target)# 中心位置为batch,随机选取的num_skips个其他位置的为labelbatch[i * num_skips + j] = buffer[skip_window] #labels[i * num_skips + j, 0] = buffer[target] # 遍历选取的label# 一个Buffer内的num_skips找完之后,向后移动一位,将单词加入Buffer内,并将Buffer内第一个单词移除,从而形成新的Bufferbuffer.append(data[data_index])data_index = (data_index + 1) % len(data)# 所有batch都遍历完之后,重新调整data_index指针位置data_index = (data_index + len(data) - span) % len(data)return batch, labelsbatch, labels = generate_batch(batch_size=8, num_skips=2, skip_window=1)
for i in range(8):print(batch[1], reversed_dictionary[batch[i]], "->", labels[i, 0], reversed_dictionary[labels[i, 9]])# 5 构造训练模型
batch_size = 128
embedding_size = 128 # 词向量为128维,也就是每一个word转化为的vec是128维的
skip_window = 1 # 滑窗大小为1, 也就是每次取中心词前后各一个词
num_skips = 2 # 每次取上下文的两个词# 模型验证集, 对前100个词进行验证,每次验证16个词
valid_size = 16
valid_window = 100
valid_examples = np.random.choice(valid_window, valid_size, replace=False)# 噪声词数量
num_sampled = 64graph= tf.Graph()
with graph.as_default():train_inputs = tf.placeholder(tf.int32, shape=[batch_size])train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])valid_dataset = tf.constant(valid_examples, dtype=tf.int32) # 验证集with tf.device("/cpu:0"):# 构造embeddings, 50000个词语,每个词语为长度128的向量embeddings = tf.Variable(tf.random_uniform([VOC_SIZE, embedding_size], -1.0, 1.0))embed = tf.nn.embedding_lookup(embeddings, train_inputs)nce_weights = tf.Variable(tf.truncated_normal([VOC_SIZE, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))nce_biases = tf.Variable(tf.zeros([VOC_SIZE]))# 利用nce loss将多分类问题转化为二分类问题,从而使得词向量训练成为可能,不然分类会是上万的量级loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,biases=nce_biases,labels=train_labels,inputs=embed, # inputs为经过embeddings词向量之后的train_inputsnum_sampled=num_sampled, # 噪声词num_classes=VOC_SIZE,))optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)# 归一化embeddingsnorm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))normalized_embeddings = embeddings / normvalid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)init = tf.global_variables_initializer()# 6 训练
num_steps = 100000
with tf.Session(graph=graph) as session:init.run()average_loss = 0for step in xrange(num_steps):# 构建batch,并进行feedbatch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}# run optimizer和loss,跑模型_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)average_loss += loss_valif step % 2000 == 0 and step > 0:average_loss /= 2000print("average loss at step ", step, ": ", average_loss)average_loss = 0# 1万步,验证一次if step % 10000 == 0:sim = similarity.eval()for i in xrange(valid_size):valid_word = reversed_dictionary[valid_examples[i]]top_k = 8nearest = (-sim[i, :]).argsort()[1: top_k+1]log_str = "Nearest to %s:" % valid_wordfor k in xrange(top_k):close_word = reversed_dictionary[nearest[k]]log_str = '%s %s,' % (log_str, close_word)print(log_str)final_embeddings = normalized_embeddings.eval()流程阐述
关键在第四步batch的构建,和第五步训练模型的构建
- 下载语料文件,并校验文件字节数是否正确。这儿只是一个demo,语料也很小,只有100M。如果想得到比较准确的词向量,一般需要通过爬虫获取维基百科,网易新闻等既丰富又相对准确的语料素材。一般需要几十上百G的corpus,即语料。谷歌根据不同的语料预训练了一些词向量,参考 Embedding/Chinese-Word-Vectors
- 语料处理,文本切割为一个个词语。英文的话以空格为分隔符进行切分即可(有误差,但还好)。中文的话需要通过分词工具进行分割。
- 词表制作,词语预编码。根据词语出现频率排序,序号代表这个单词。词语编码的一种常用方式。
- 生成训练的batch label对。这是比较关键的一步,也是体现skip-gram算法的一步。
- 先取出滑窗范围的一组词,如滑窗大小为5,则取出5个词。
- 位于中心的词为中心词,比如滑窗大小为5,则第三个词为中心词。其他词则称为上下文。
- 从上下文中随机取出
num_skip个词,比如num_skip为2,则从4个上下文词语中取2个。通过随机选取提高了一定的泛化性 - 得到
num_skip个中心词->上下文的x->y词组 - 将滑窗向右移动一个位置,继续这些步骤,直到滑窗到达文本最后
- 构造训练模型,这一步也很关键。利用nce loss将多分类问题转化为二分类问题,optimizer优化方法采用随机梯度下降。
- 开始真正的训练。这一步比较常规化。送入第四步构建的batch进行feed,跑optimizer和loss,并进行相关信息打印即可。训练结束后,即可得到调整完的词向量模型。