苏大团队联合阿丘科技发表异常生成新方法:创新双分支训练法,同步攻克异常图像生成、分割及下游模型性能提升难题。
苏州大学与阿丘科技团队发表论文《Free Lunch of Image-mask Alignment for Anomaly Image Generation and Segmentation》,聚焦异常图像生成与分割,旨在解决真实世界中异常样本匮乏难题。传统方法仅用掩码引导生成,该论文提出双分支训练策略,可同时生成异常图像与掩码,借助对齐正则化损失解决标签偏移问题。推理时仅激活图像生成分支生成合成样本,用于训练下游分割模型。此外,论文还创新性地将训练好的生成模型融入分割模型训练,利用生成反馈损失提升分割模型性能,为缓解样本不均衡、降低标注成本等提供了新思路。目前论文已被IJCAI20205接受。
研究背景
异常图像生成与分割的目标是生成异常图像,并在同一流程中生成其对应的掩码标签。异常样本在工业制造与医疗诊断领域普遍稀缺:工业场景中,生产线以零缺陷为目标的工艺优化、刻意制造缺陷的高成本与技术难度,以及在线检测设备的提前拦截共同导致样本不足;医疗场景下,病变的低发病率、隐私伦理对数据共享的限制及专业标注门槛进一步加剧了这一问题。而异常图像生成与分割任务通过同步输出模拟真实的异常图像及其对应掩码标签,区别于传统仅追求视觉逼真的图像生成任务,能有效填补真实样本缺口,进而缓解样本不均衡问题、降低标注成本,同时提升下游分割模型对异常的识别能力与复杂场景适应性。论文由苏州大学与阿丘科技共同完成。
论文介绍
论文旨在生成异常图像及其分割标签,以解决真实世界中异常样本匮乏问题。传统方法仅利用掩码引导异常图像生成,与之不同的是,论文为生成模型提出了一种双分支训练策略。该策略能够同时生成异常图像与掩码,且通过对齐正则化损失确保生成图像与其掩码之间的一致性,因而解决了标签偏移问题。在推理阶段,仅激活图像生成分支以生成合成样本,用于训练下游分割模型。此外,论文提出将训练良好的生成模型融入分割模型的训练过程,并利用生成反馈损失提升分割模型的性能。
与之前方法的对比
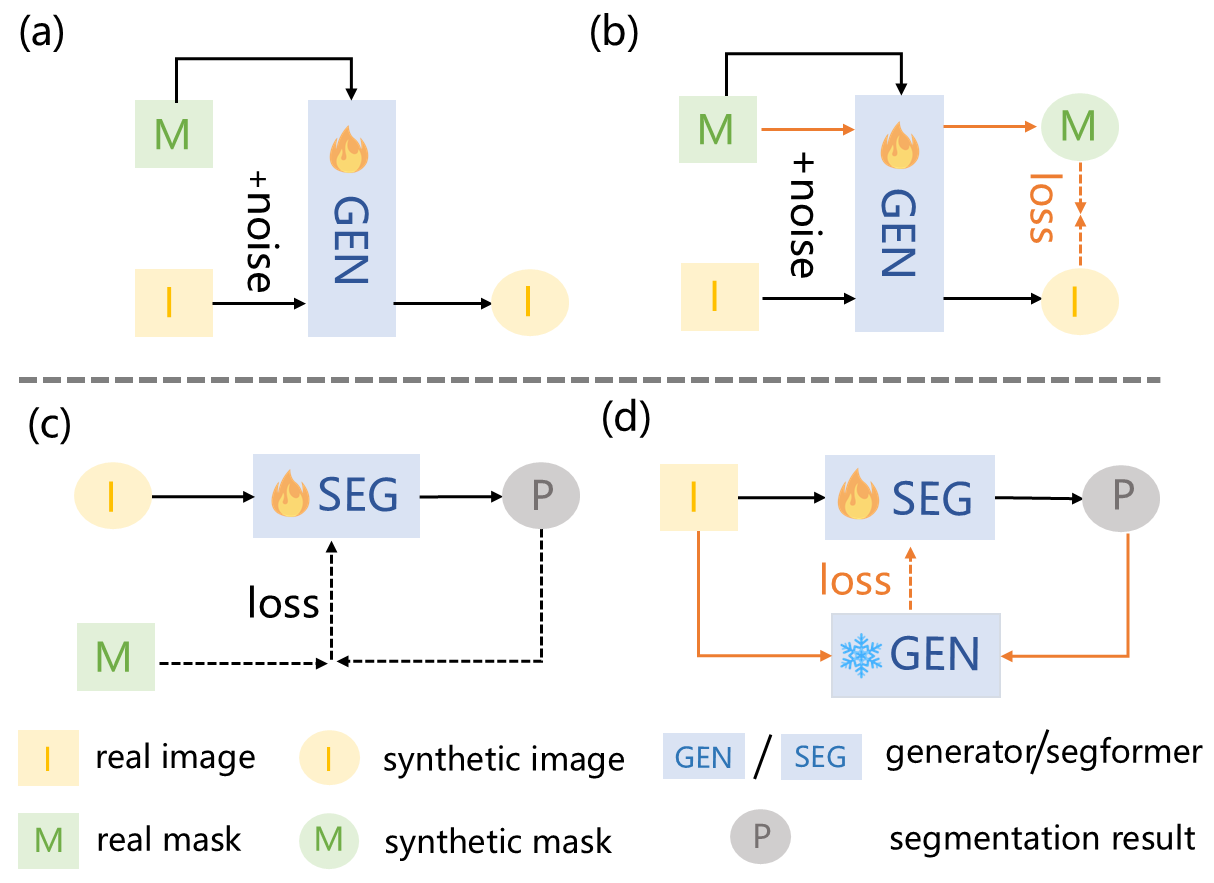
在训练生成模型时:以前的方法(a)采用掩码引导的图像生成方式。这会引发标签漂移问题:生成的图像与掩码对齐效果不佳,进而导致图像 - 掩码对齐质量较差。论文的方法(b)为扩散模型提出了一种双分支训练策略,该策略融入了对齐正则化损失,以减少扩散模型中的漂移问题。
在训练分割模型时:以前的方法(c)仅对真实样本与合成样本进行常规训练,未能充分利用训练成熟的扩散模型内部蕴含的图像 - 掩码对应关系。论文的方法(d)通过生成反馈损失将训练成熟的生成模型融入下游分割模型的训练过程,有效利用生成模型来提升分割模型的性能。
方法框架
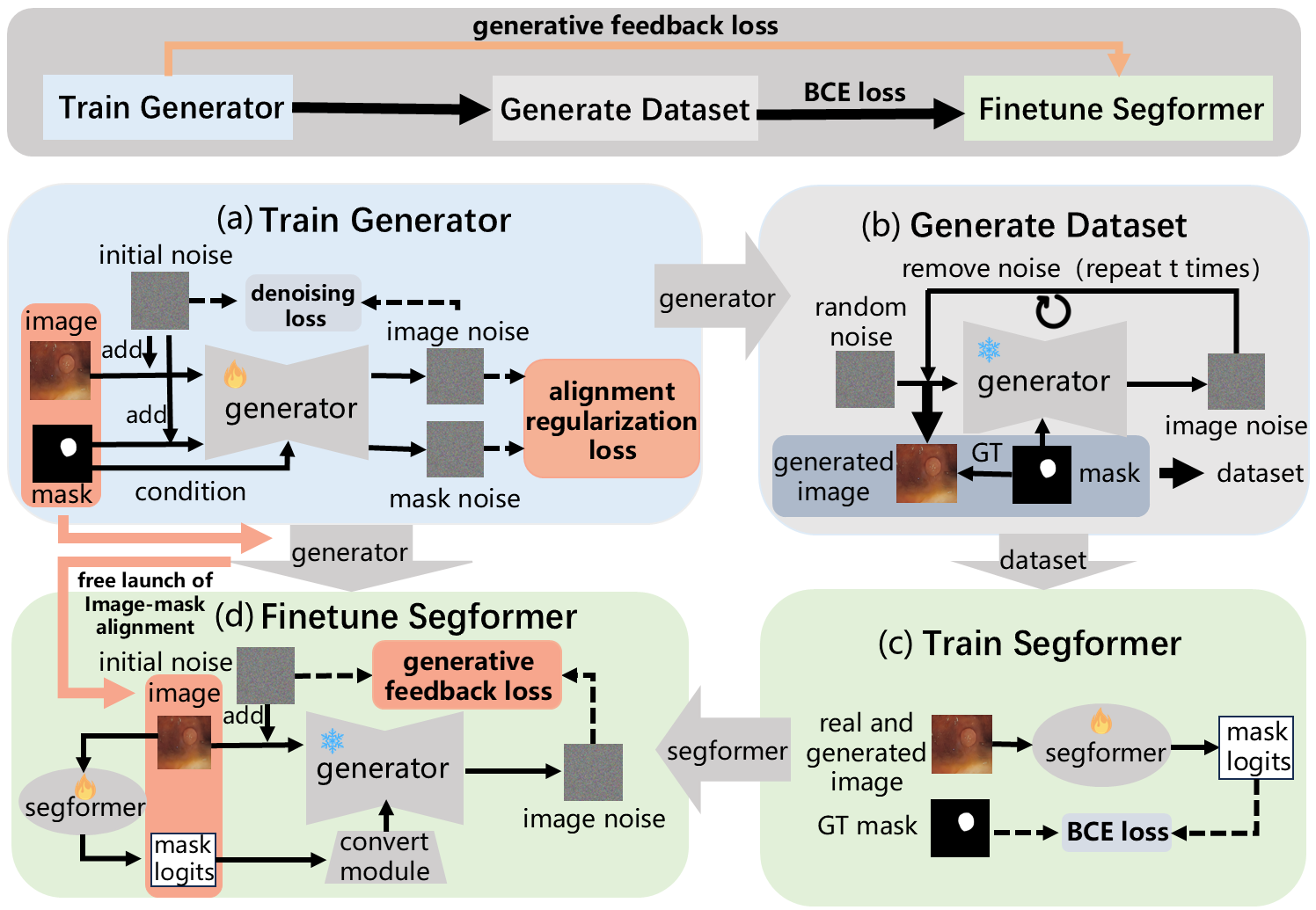
(a)首先训练生成模型(双分支训练策略,融入了对齐正则化损失)。(b)然后利用少部分真实掩码进行数据增强,再以掩码为条件生成对应的缺陷图像,最终得到生成缺陷图像及掩码数据集。(c)之后用真实图像和生成图像及对应掩码来训练分割模型。(d)最后通过生成反馈损失利用训练成熟的生成模型来微调分割模型。
训练生成模型的细节
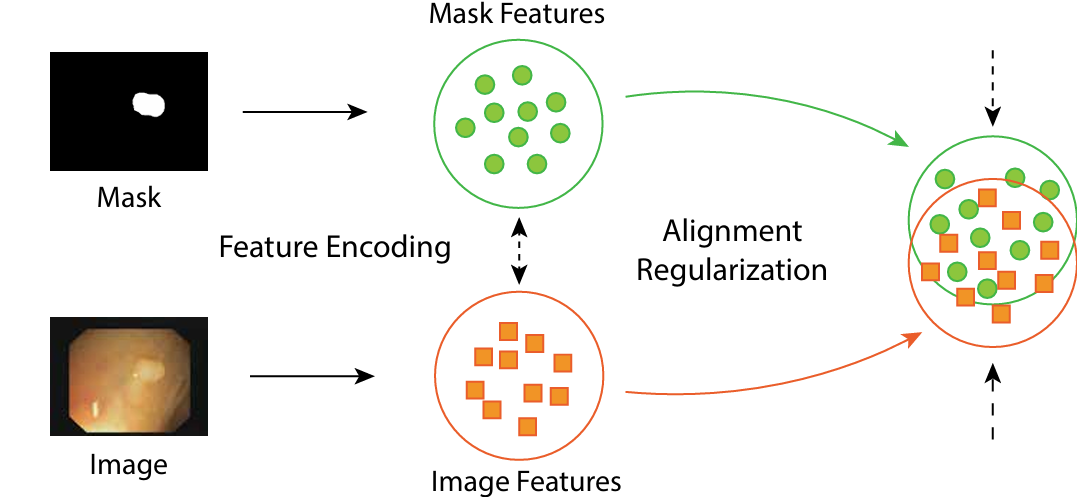
论文展示了对齐正则化机制的效果。具体来说,论文对图像和掩码应用相同的噪声,然后通过正则化项强制它们各自噪声预测之间的一致性。通过确保掩码与图像两者的噪声预测保持一致性,使得掩码与图像之间的特征分布差异得以缩小,进而增强掩码的引导作用。为实现结构对齐,对齐正则化项 $ \mathcal{L}{al}会计算输入图像分支所预测的噪声 \epsilon{z}与掩码分支所预测的噪声 \epsilon_{h}$ 之间的均方误差。
训练分割模型的细节
训练过程中,分割模型首先对给定的输入图像预测 logits。随后,这些 logits 通过一个转换模块进行处理,进而得到近似掩码 。该转换模块的示意流程图如下所示,首先对初始的掩码进行缩放操作,然后对缩放后的掩码应用 softmax 函数,将其转换为掩码概率,最后通过切片操作提取特定部分的概率分布,进而得到近似掩码。

随后,近似掩码 会与文本嵌入向量 一同作为扩散模型的条件。接着,扩散模型对添加噪声后的潜在图像特征 进行处理,生成预测噪声 。论文提出的反馈损失 定义为:前向扩散过程中添加的真实噪声 ,与稳定扩散模型预测的噪声 之间的均方误差。该损失基于扩散模型的原始去噪损失精心推导得出,可有效作为衡量分割模型准确率的可靠指标。
生成效果展示

论文提供了生成数据的分布图像。该图展示了经过 VAE 编码后,真实掩码、真实图像、无对齐损失的生成图像以及有对齐损失的生成图像的数据分布。结果显示,在没有对齐损失的情况下,生成图像与真实掩码、真实图像之间均存在显著的分布差距;而加入对齐损失后,生成图像与真实掩码的分布差距明显缩小,与真实图像的差距也相对减小,说明方法的有效性。
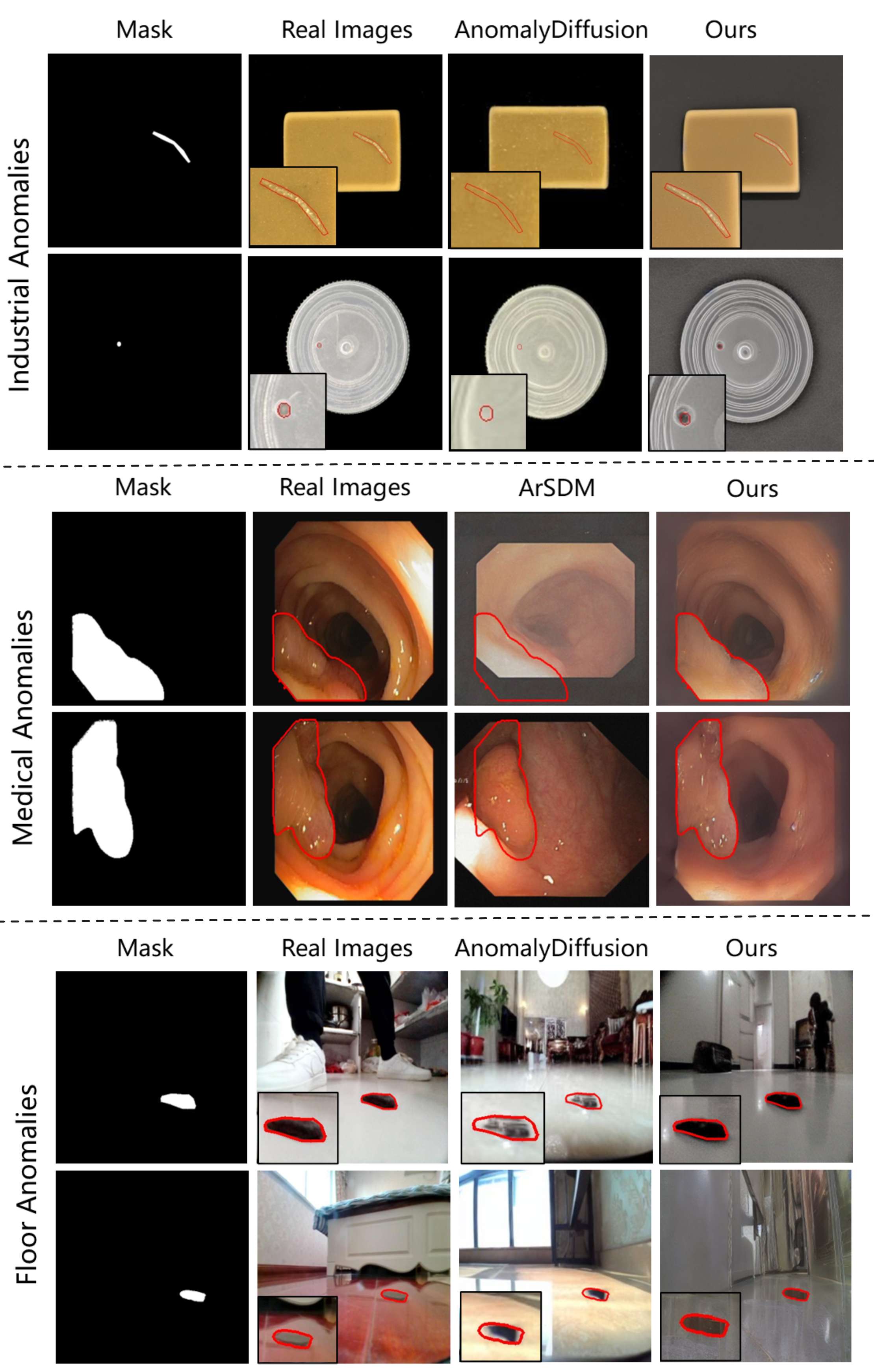
论文提供了在不同场景下与其他生成模型方法的对比。从图中可以看到,论文方法生成的图像和掩码能够很好地贴合,而其他方法则会出现图像和掩码不对齐的现象。
结论
为生成异常图像及其对应的掩码标签,可通过小规模数据集训练掩码引导的图像生成模型,使其能够在掩码条件下生成异常图像。
以往方法的局限性:
生成模型训练:标签漂移导致生成图像与掩码的对齐效果不佳。
分割模型训练:仅对真实样本与合成样本进行常规训练,未能利用训练成熟的扩散模型中蕴含的图像 - 掩码对应关系。
我们的改进方案:
生成模型训练:为扩散模型设计双分支策略,并引入对齐正则化损失以减少漂移问题,使生成模型能够稳定学习到精确的图像 - 掩码对齐关系。
分割模型训练:通过生成反馈损失,将训练成熟的生成模型融入分割模型训练。该损失可反映分割模型在异常区域识别任务中的准确率,助力其在不同场景下实现高效微调。