科技信息差(9.29)

🌍V5 强势发布!Vue3 生态最强大的 3D 开发框架!
✨DeepSeek开源V3.2-Exp,公开新稀疏注意力机制DSA

1.苹果探索自研多模态 AI 模型 Manzano:兼具理解与生成能力,不弱于 OpenAI GPT-4o 和谷歌 Nano Banana
Manzano 的整体架构包括三部分:混合分词器、统一语言模型,以及独立的图像解码器。苹果为解码器构建了三个版本,参数规模分别为 9 亿、17.5 亿和 35.2 亿,支持 256 像素至 2048 像素分辨率。
训练过程分为三个阶段,使用 23 亿对图像-文本样本(来自公开和内部数据),以及 10 亿对文本-图像样本,总计处理 1.6 万亿标记。部分训练数据来自合成生成,如 DALL-E3 和 ShareGPT-4o。
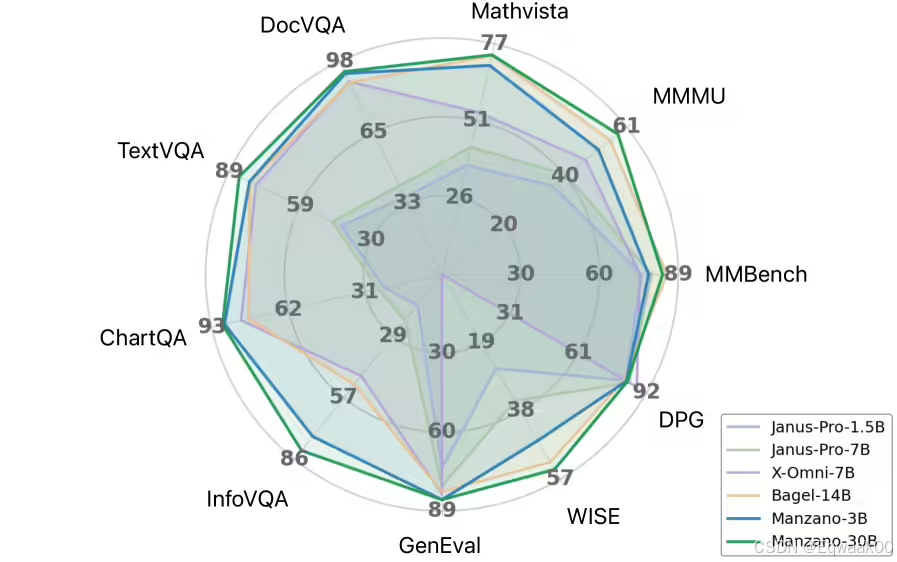
在内部测试中,Manzano 在 ScienceQA、MMMU 和 MathVista 等基准上表现优异,尤其在图表和文档分析等文字密集型任务中,300 亿参数版本成绩突出。扩展测试显示,模型性能随规模提升而持续改善,例如 30 亿参数版本在部分任务中比最小模型高出 10 分以上。
苹果还将统一模型与专业化系统对比,差距仅为个位数分值:在 30 亿参数版本中,差距不到 1 分。在图像生成测试中,Manzano 亦接近前列,可执行复杂指令、风格迁移、图像叠加与深度估计等任务。
苹果认为,Manzano 是现有模型的有力替代方案,其模块化设计可支持各部分独立更新,并借鉴不同研究领域的训练方法,有潜力推动未来多模态 AI 的发展。
不过,目前苹果的基础模型整体仍落后于行业领先者。即便推出新的端侧 AI 框架,苹果仍计划在 iOS 26 的 Apple Intelligence 中引入 OpenAI GPT-5。Manzano 展示了技术上的进展,但是否能减少对外部模型的依赖,还需未来版本进一步验证。
2.杨立昆团队将世界模型塞进了代码生成,AI也能一边写一边“调试”代码了
Meta旗下的人工智能研究部门FAIR(Facebook AI Research)发布了全球首个代码世界模型(CWM),把“世界模型”(World Model)用在了代码生成上。
“预训练”(Pre-training)找了8万亿(8T)个tokens的通用代码和自然语言资料,先让模型把基础打好,学会认字、组词、造句,对代码有个基本的理解。
“中段训练”(Mid-training),模型不再是简单地看静态代码了,而是开始大规模观摩代码的“现场直播”。Meta准备了超过3万个可执行的Docker容器镜像,这玩意可以理解为一个个打包好的、真实的软件运行环境。然后,他们让超过2亿条Python程序在这些环境里跑起来。
跑的时候,CWM全程在旁边盯着。它记录下程序内存里发生的一切,形成所谓的“内存轨迹”(memory traces)。比如一个变量被赋值了,一个函数被调用了,一个列表的元素被修改了,甚至程序抛出了一个异常,这些细节全都被CWM看在眼里,记在心里。
这就像让一个医学生不光背诵理论,还直接把他扔到手术室里,观摩成千上万台手术,看主刀医生怎么处理各种状况,看病人的生命体征如何变化。
训练数据里还包括300万条模拟的智能体交互轨迹。在这些轨迹里,模型需要自己尝试和文件系统、解释器这些计算环境打交道,完成一个个小任务,在一次次交互和试错中,学习行为和结果之间的因果关系。
经过这个阶段5万亿tokens数据的“熏陶”,CWM逐渐就有了“代码感”,也就是对代码执行动态的理解能力。
“后训练”(Post-training)阶段则包含监督微调(SFT)和强化学习(RL)。监督微调主要是教模型如何更好地理解和遵循人类的指令。而强化学习则更有意思,它不是靠人来打分(RLHF),而是靠环境来反馈。
比如,让CWM去修复一个bug,修复成功了,单元测试通过了,环境就给它一个“奖励”;修复失败了,就给个“惩罚”。让它去证明一道数学题,证明对了,奖励;证错了,惩罚。这种来自环境的、可验证的奖励信号,比人的主观判断要客观、高效得多,也更容易规模化。
通过这种方式,CWM的各项专业技能被进一步打磨,最终成型。
它的身体构造有何不同
CWM是一个拥有320亿(32B)参数的“大块头”,属于稠密(dense)架构模型。
它最长能处理131,072个tokens的上下文,这意味着它可以一口气读完一个非常非常长的代码文件,理解里面的来龙去脉,这对于处理复杂的现代软件项目至关重要。
在最核心的注意力机制上,CWM也玩了点新花样。它没有一视同仁,而是创新地把局部注意力和全局注意力结合起来用,并且按3:1的比例交替进行。
局部注意力的“视野”是8192个tokens,负责精读一小段代码里的细节。全局注意力的“视野”则拉满到131,072个tokens,负责鸟瞰整个代码文件的宏观结构。
这种设计很聪明,就像我们读一本书,既要仔细看懂当前这一页的字句,也要时不时抬头想想这一章和前后章节的联系。这样既能高效处理局部逻辑,又不会丢失长距离的依赖关系,比如一个在文件开头定义的函数,在文件末尾被调用了,模型也能捕捉到。
为了在保持高性能的同时省点力气,CWM还用了分组查询注意力(Grouped-Query Attention, GQA)技术,算是一种在效果和计算开销之间的精明平衡。