ChatBI的相关学习
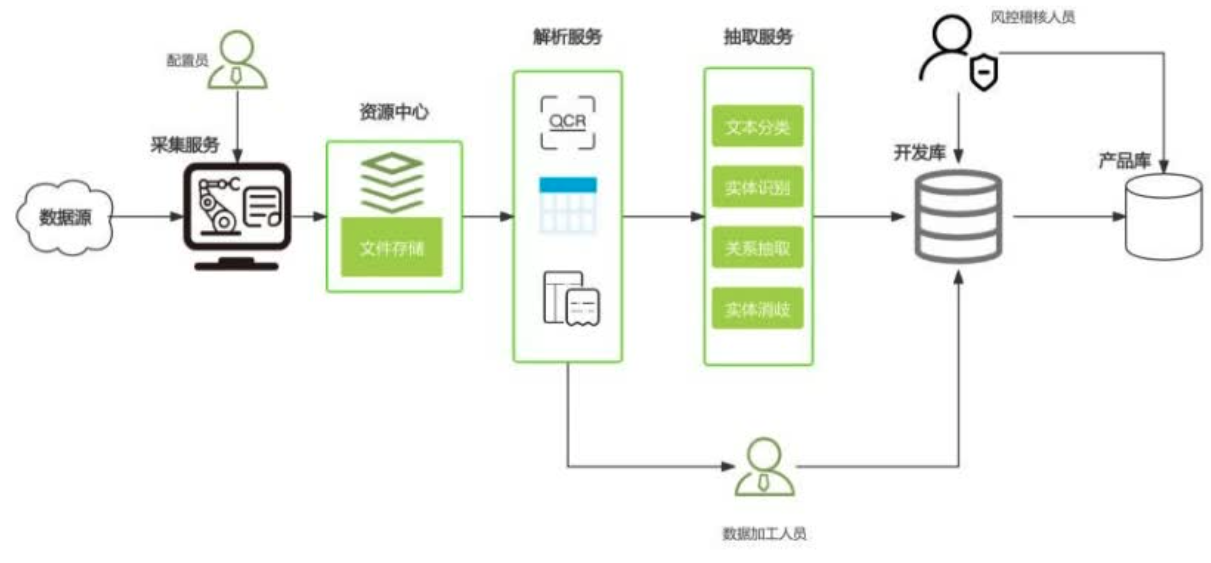
常见的解析服务,第一个就是PDF文件解析,然后就是OCR,对图片进行文字提取,除此之外也会涉及到一些表格,如PDF里面的结构化的表格,提取会容易一些,否则涉及到一些表格单元格识别分割,还有单元格关系的重建,也会涉及到一些页眉、页脚或者目录版面分割等任务,会涉及到基于文本消除歧义和进行基于自然语言下的纠错。
下一步进入NLP域抽取服务,大的层面上会分成文本的分类,然后对这些公司等实体做识别,也会做一些关系抽取、实体消歧。
抽取完导入到开发库,在这个过程中会出现在解析阶段或者抽取阶段有一些错误要修订,需要一些数据加工人员来进行人工操作处理,极端情况下可能某些数据质量很差,就需要全程重做,从爬虫爬下来数据之后的人工处理和入库。
入库后为了保证数据质量,会有一些风控或者数据集合人员持续地在开发库和产品库里做一些相应的数据集合抽检,发现问题反馈或者直接修正。
RAG是一个放大模型的能力的作用,它就是大模型。如一个文档如果不进行RAG的增强,直接提问可能也能问出一些东西,但是相对准确率可能不高,可能换问题比较严重。如果用RAG的方法,对它做切片,做向量化,可能效果上就会更好,相当于是把大模型的能力增强,但Agent一定程度上相当于丰富大模型的能力,因为大模型其实现在狭义上是大语言模型,在自然语言里面可能有比较强的能力,但是要扩展到自然语言之外,如一个常见的场景,就是订机票、订酒店,那它就不是一个单纯的NLP的任务,用agent的方式,可以用大模型的编排能力,工具助手来实现一个丰富大模型的能力的目的。
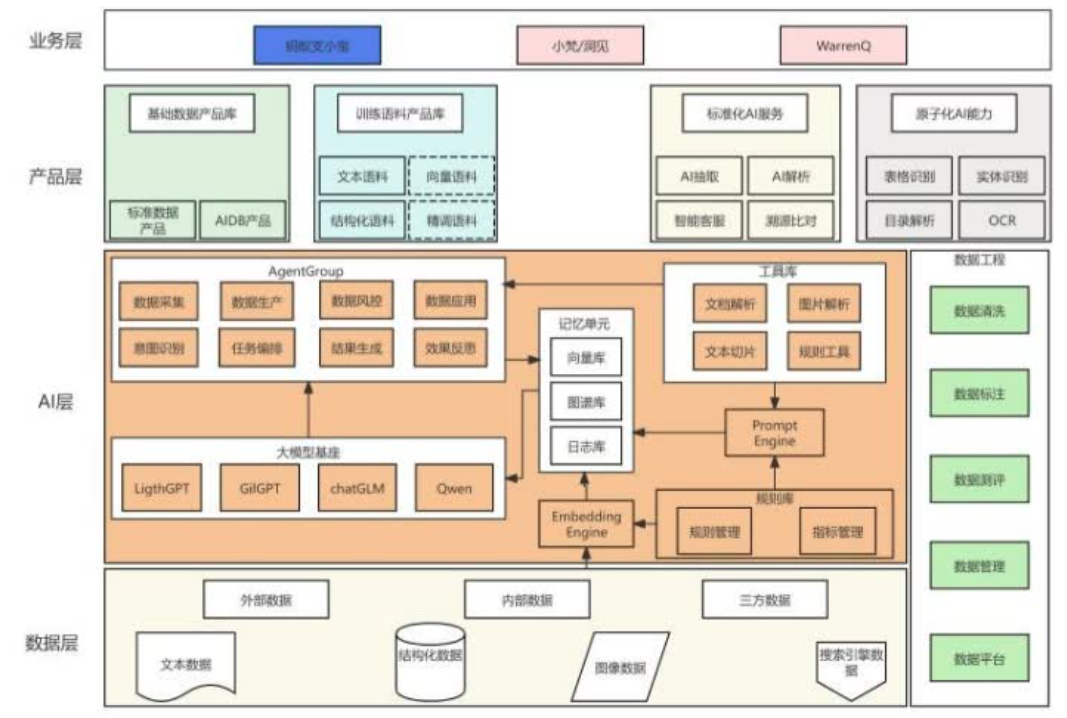
外网实时得到的一些数据,采集后对数据先做embedding,就是统一的向量化。在整个数据生产过程中,根据人工的规则和经验,进入规则库,字段、库表的管理知识的导入,指标知识导入,进入Prompt引擎,输入到一个记忆单元。同时过往也会积累到已经成熟的文章,文档解析的服务能力,也涉及到一些图片解析,具体就是一些表格OCR能力,也会做一些文本的切片,对某些场景下可能基于正则或者其他人工经验写的一些规则的导入。然后进入AgentGroup,会涉及到采集层面、数据生产层面、数据风控层面数据应用,包括意图识别、任务编排、结果生成和反思,最终形成整个的生产过程。
多模态文档理解
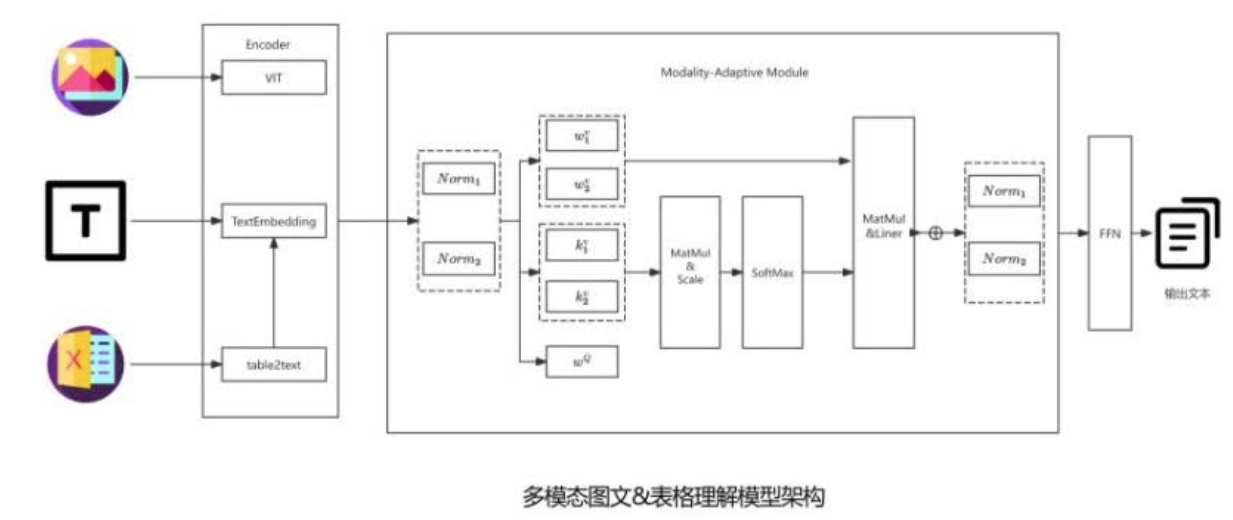
整体做一个自适应模态,能实现比较清晰的图表、文档和里面图表的识别。比较关心的模态是图片、文本、表格,对表格进行一个tabletotext的一个重新表达,之后和文本一起做一些文本向量化。
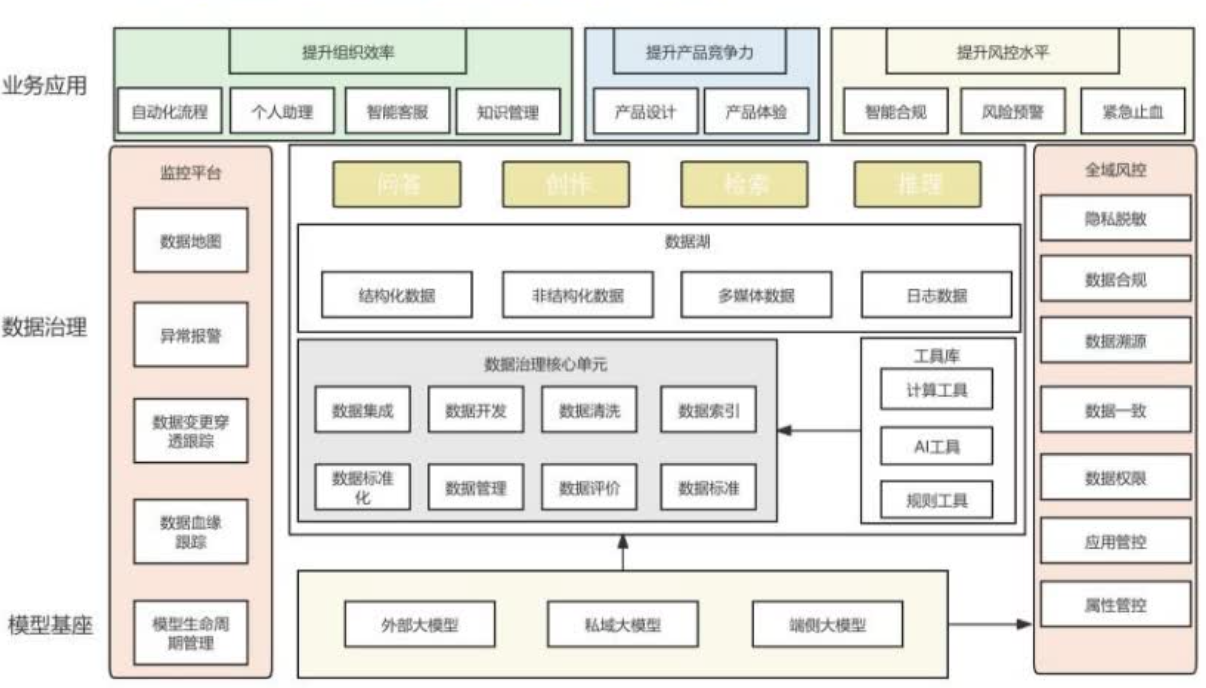
大部分企业尤其是金融企业,模型是部署到本地,数据不会出来。端侧大模型,是企业里面会有一些人、部门或者一些很敏感的数据,即使注入私域大模型也有可能导致数据由于大模型的原因外泄到它管控范围之外的状态,可能更适合端侧大模型,把模型能力主要贡献到一个全流程的风控能力。
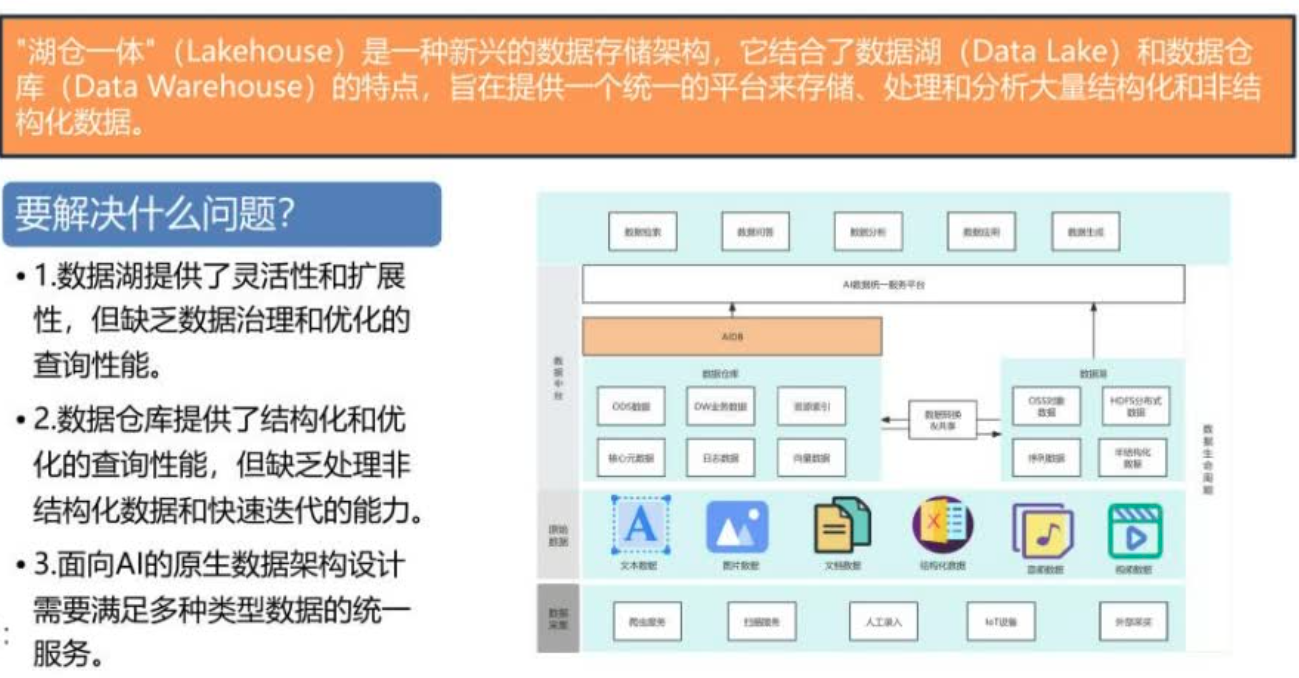
"湖仓一体"(Lakehouse)是一种新兴的数据存储架构,它结合了数据湖(DataLake)和数据仓库(DataWarehouse)的特点,旨在提供一个统一的平台来存储、处理和分析大量结构化和非结构化数据。
湖仓一体要解决以下三个问题:数据湖提供了灵活性和扩展性,但缺乏数据治理和优化的查询性能。数据仓库提供了结构化和优化的查询性能,但缺乏处理非结构化数据和快速迭代的能力。面向AI的原生数据架构设计需要满足多种类型数据的统一服务。
基于此架构,在底层,数据采集包括爬虫服务、扫描服务、人工录入、IoT设备的序列数据、外部采买的第三方数据,上层是原始数据,包括文本、图片、文档、优化数据、音频、视频等。在上层,分成两个环节,数据湖中构建OSS对象存储和HDFS分布式存储,把相关的数据先存下来,数仓中ODS数据、DW业务数据、资源索引、核心元数据、日志数据,向量化数据,有相应的资源索引能力,构造数据仓库上基于AIDB的设计,要求一些自然语言能力的语义增强。同时供上游的AI数据的统一服务平台,最上层应用层有数据的检索任务、问答任务、数据分析任务、数据的应用和数据的生成等,构造一个AI数据统一服务平台。
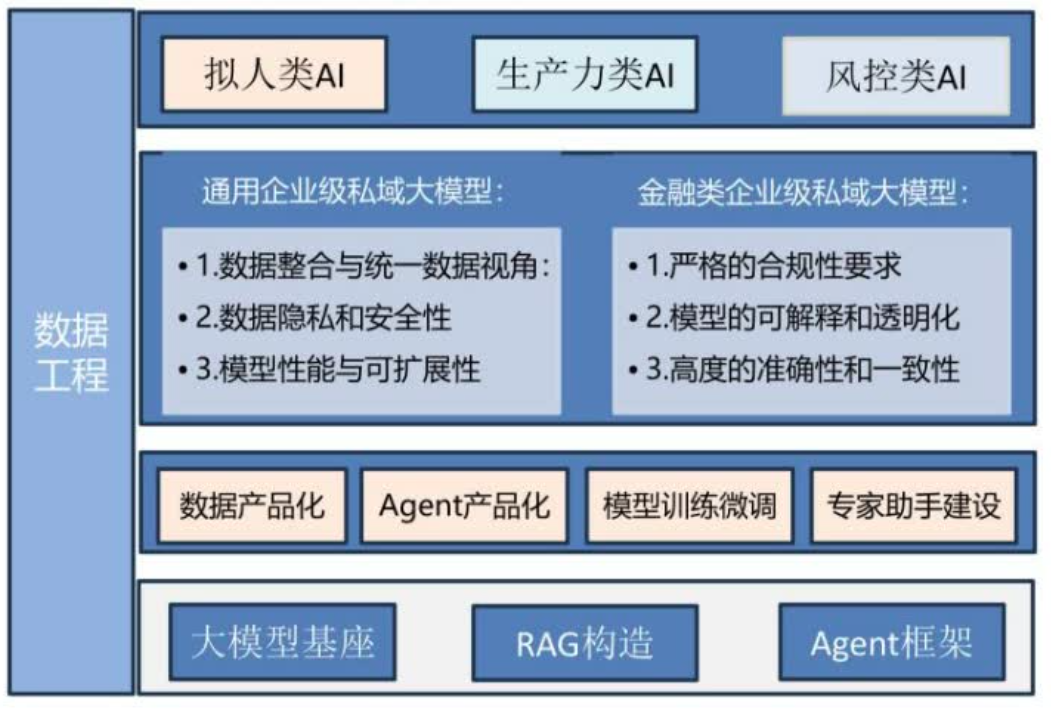
在底层的AI能力方面,要建设大模型基座或者做基座测评,选好基座,基于RAG增强构造,整个流程有一套适应公司的业务需求特点的Agent框架。

重点是看数据的表达能力,通过数据切片、向量化、ES召回、实体抽取技术,形成输入大模型前的数据表达服务能力。
第二个是数据服务的能力,提供一个简单易用的服务提供数据。建立NL2API、NLP2SQL的数据服务,形成大模型对数据的消费能力。
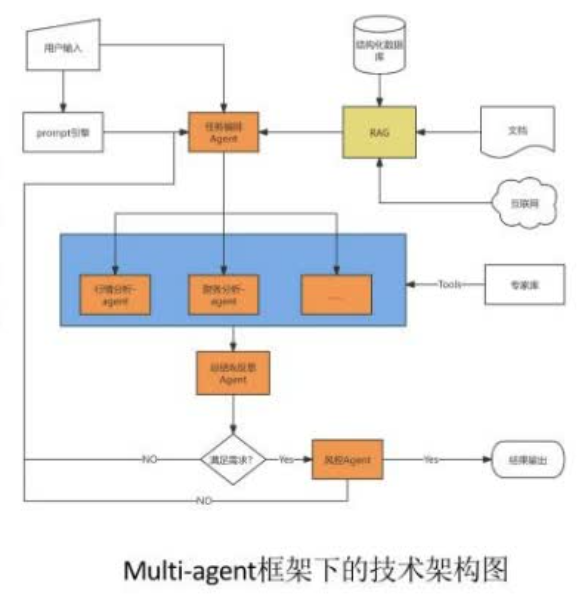
用户如果问一些头部问题,先经过prompt引擎,形成一套prompt范例,进入任务编排agent,agent同时会外挂一个RAG输入,把全金融领域的财务类的数据库与任务挂钩。做一个文档,有结构化数据、有互联网的三方爬取的数据注入,注入完后进入任务编排反思,进入基于细分专家,包括行情、财务,还有风险预警等模块,这种agent模块,各个子模块拿到的结果做一个agent的总结和反思。
-----------------------------------------------------------
数据治理的整体思路是,从数据标准、数据架构、数据开发以及数据成本多方面着手,用技术去牵引数据全链路的降本增效。
制定数据标准、标准系统化、数据认证
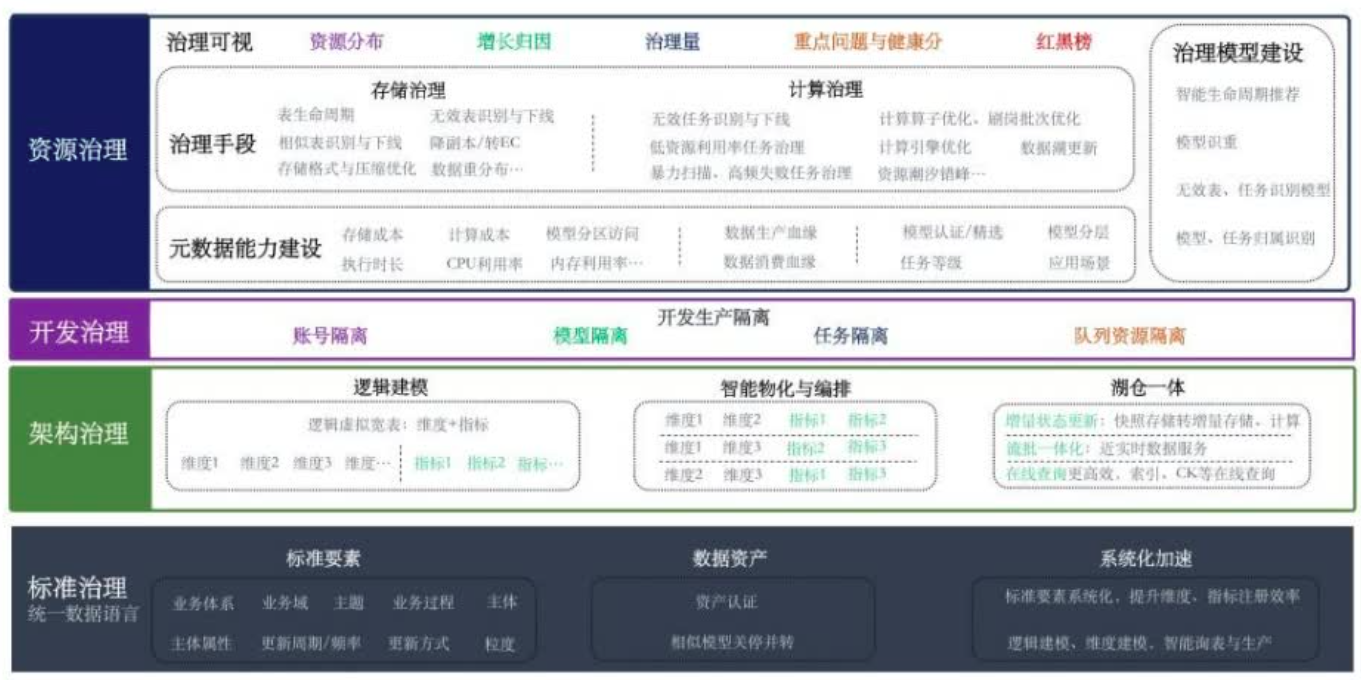
(1)标准治理
---------------------------------------------------------------------


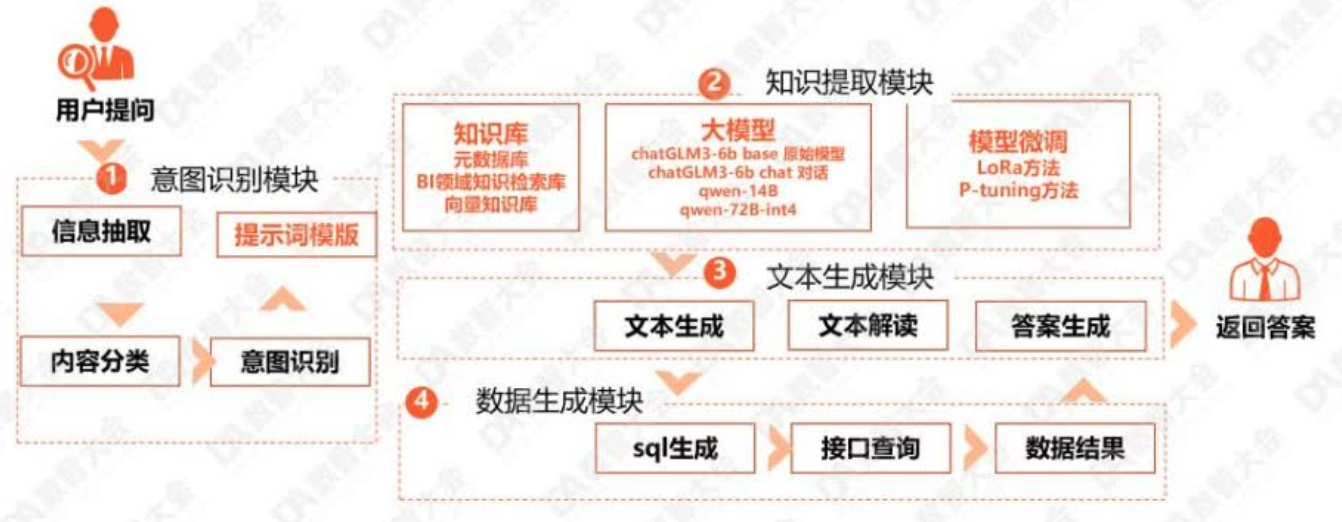
我们整个问数的流程,包括意图识别、知识提取、文本生成、数据生成等步骤,整个过程中会多次与大模型进行交互。

知识库是我们的开发过程中最重要的工作之一,我们采用了两种技术:RAG技术和外挂知识库。RAG技术用于提高准确率,大模型在进行语义解析后会调用知识库进行检索,然后用这些知识进行文本和数据的语义分析和生成,从而大幅提高准确率。
知识库分为常见知识库和进阶知识库,常见知识库包含常见名词、知识和SQL语法等,而进阶知识库则是垂直领域内的知识,如BI知识库的同环比、累计等术语,保险知识库的各种保险行业名词,以及SQL知识库的SQL编写规范。

统通过大模型、意图识别和知识库对意图进行识别,解析出时间、指标、计算方法和维度,然后通过知识库进行二次校准,进入任务编排阶段。接下来是UM鉴权,根据用户账号确定用户是否有权限使用该指标。之后是SQL生成,调用数据库进行秒级查询。最后是对结果进行可视化包装和美化。
“言出必答”,用户可以查询指标的元数据和口径,系统能快速展示数据库底层的数据治理知识。

随机报表功能主要生成SQL语句,大模型主要负责语义理解,之后通过API方式和NLP技术生成代码,我们底层的数据服务中台可以快速生成数据查询。