DynImg论文阅读

2025.7
1.摘要
background
近年来,多模态大语言模型(MLLM)在视频理解任务中越来越普遍。然而,如何有效整合时间信息仍然是一个关键挑战。传统方法通常将空间和时间信息分开处理,由于运动模糊等问题,很难精确表示快速移动物体的空间信息。这导致在特征提取过程中,时间上的重要区域(如运动物体)没有得到足够重视,从而阻碍了后续准确的时空交互和整体视频理解。
innovation
1.提出DynImg (动态图像) 表示法: 为了解决上述问题,论文提出了一种名为 Dynamic-Image (DynImg) 的创新视频表示方法。它将一组“非关键帧”作为“时间提示”(Temporal Prompts),与“关键帧”组合成一张单一的图像。
2.实现早期、细粒度的时空交互: 这种组合方式使得视觉编码器在特征提取的初始阶段,就能通过自注意力机制同时处理关键帧的精细空间细节和非关键帧中的运动信息。这与传统方法在高级特征(token层面)进行交互的方式形成对比,DynImg在像素/图像块(pixel/patch)级别就促进了时空信息的融合,从而避免了早期特征提取过程中的信息损失。
3.提出4D旋转位置编码 (4D-ROPE): 由于DynImg是一种全新的、结构复杂的输入格式,为了帮助下游的大语言模型(LLM)理解其时空顺序,论文设计了一种配套的4D视频旋转位置编码。这种编码能够保留DynImg中正确的空间(高、宽)和时间(帧顺序、序列顺序)邻接关系。
2. 方法 Method
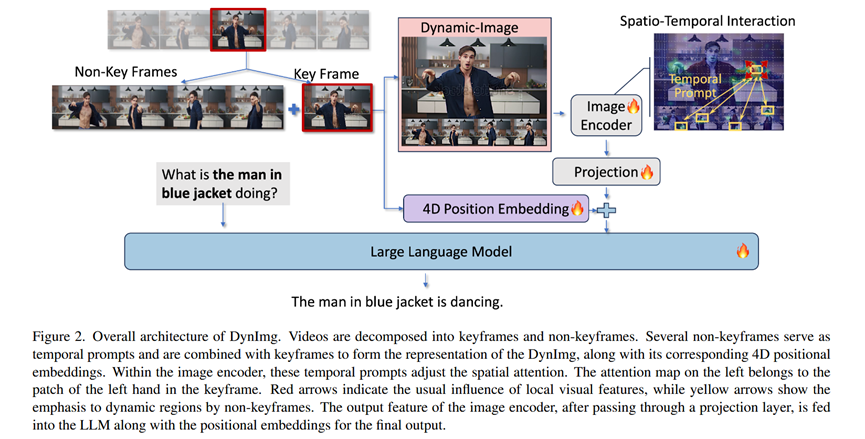
Pipeline (总体流程):
整体架构如图2所示。首先,视频被分解为关键帧(K-frame)和非关键帧(N-frame)。然后,选取一个关键帧和其前后的四个非关键帧,将非关键帧缩放后拼接在关键帧下方,形成一张DynImg。这张DynImg与一个专门设计的4D位置编码一起被送入视觉编码器提取特征。提取出的视觉token经过投影层后,与文本token一起输入到大语言模型(LLM)中,最终由LLM生成文本答案。
各部分详解:
1.时间提示 (Temporal Prompts) 的构成:
输入: 一段视频。
过程:
关键帧选择: 采用MPEG-4方法,均匀采样4个I帧作为关键帧。
非关键帧选择: 对每个关键帧,从其前后随机选择总共4个非关键帧。
DynImg组合: 将高分辨率的关键帧作为基础图像,下方按时间顺序从左到右拼接4个缩放后的非关键帧。
输出: 一张组合好的“动态图像”DynImg。其作用是在视觉编码器内部,让关键帧中的图像块(patch)能够注意到非关键帧对应区域的变化,从而为静态的空间特征注入动态信息。
2.4D位置编码 (4D Position Embedding):
输入: 来自视觉编码器的视觉token和文本token。
过程: 为了让LLM理解DynImg这种新格式,论文将传统LLM使用的一维旋转位置编码(RoPE)扩展到四维:高度(H)、宽度(W)、时间(T)和序列(S)。
对于视觉token,其H, W坐标根据在原图中的位置决定;T坐标在关键帧部分为0,在时间提示部分根据其时序对称变化;同一张DynImg的所有token共享一个S坐标。
对于文本token,其H, W, T坐标与S坐标相同。
最终的旋转角度是这四个维度坐标的加权和,其中H, W, T三个维度的权重是可学习的。
输出: 一个能够精确描述每个token时空位置的编码,引导LLM正确理解DynImg的内部结构。
3. 实验 Experimental Results
实验数据集:
训练数据: 使用了来自十多个不同数据集的视频-文本对,涵盖视频字幕、分类、对话、推理和问答等多种任务,总量超过70万。
评测数据:
开放式问答: MSVD, MSRVTT, TGIF, ActivityNet。
多维度基准: Video-ChatGPT benchmark。
多项选择问答: MVBench。
实验结论:
1.与SOTA对比: 在多个开放式视频问答基准上,DynImg的准确率超越了之前最好的方法约2.0%。在强调时空理解的MVBench测试中,模型在大多数类别上取得了最佳性能,尤其是在对运动敏感的任务上提升显著,如“运动方向”(+21.0%)、“运动计数”(+15.0%)和“运动属性”(+26.5%),这直接证明了该方法对动态信息的捕捉能力。
2.Token效率分析: 实验证明DynImg非常高效。它仅使用4个DynImg(代表4个关键时刻)就能达到甚至超过基线模型PLaVA使用16帧图像的效果,大幅减少了输入到LLM的视觉token数量,提升了训练和推理效率。
3.消融实验:
时间提示的作用阶段: 证明了在送入视觉编码器之前组合DynImg(Pre-encoder)远优于在编码器之后融合特征(Post-encoder),性能差距约为2.4%。这验证了“早期、细粒度时空交互”的核心思想。
4D-ROPE的有效性: 使用4D-ROPE比使用传统1D位置编码效果更好,说明为LLM提供准确的多维时空坐标是必要的。
提示帧数量的影响: 使用4个非关键帧作为时间提示时效果最好。太少则时间信息不足,太多则因图像缩放过度导致信息损失。
4. 总结 Conclusion
论文提出了一种新颖、高效且有效的视频表示方法DynImg。通过将非关键帧作为时间提示,它在视觉特征提取的早期阶段就实现了细粒度的时空交互,解决了传统方法中因时空分离处理导致的运动信息损失问题。配套的4D位置编码保证了LLM能够正确理解这种新颖的表示。实验证明,该方法显著提升了视频理解的准确性,尤其是在处理动态场景时,同时还提高了计算效率。