java面试day5 | 消息中间件、RabbitMQ、kafka、高可用机制、死信队列、消息不丢失、重复消费
目录
RabbitMQ
如何保证消息不丢失
消息的重复消费问题是怎么解决的?
死信交换机/延迟队列
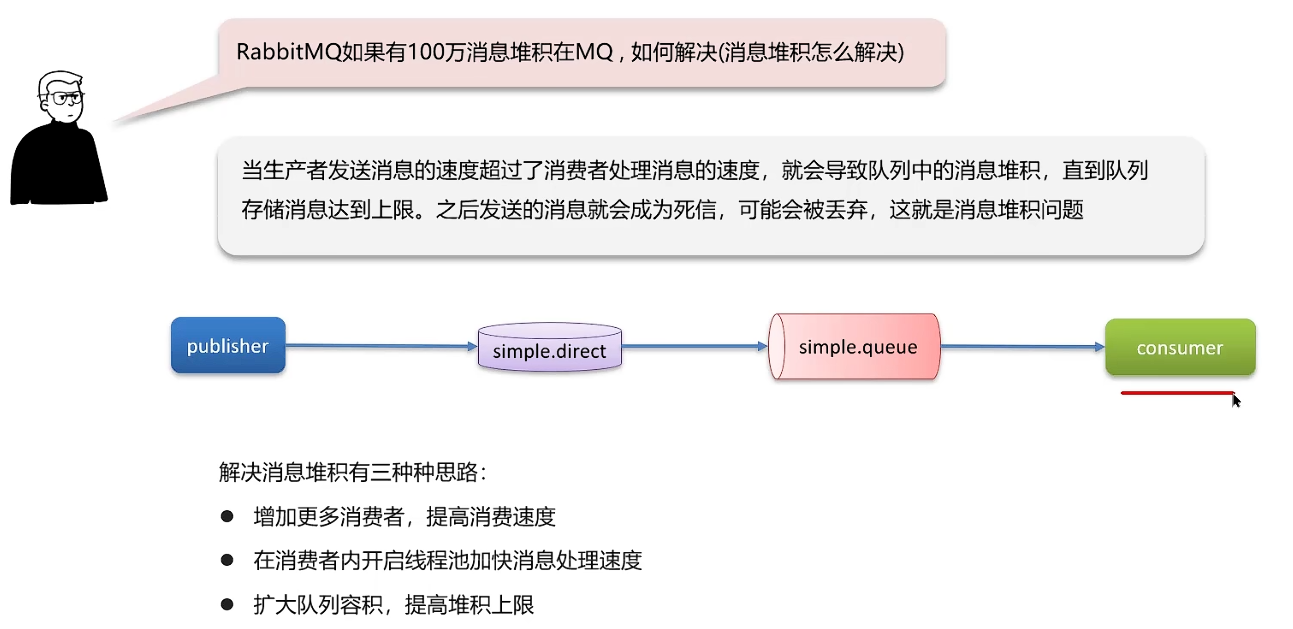
如果有100万消息堆积在MQ,怎么解决?(消息堆积怎么解决)
高可用机制
kafka
如何保证消息不丢失?
如何保证消费顺序性
高可用机制
数据清理机制
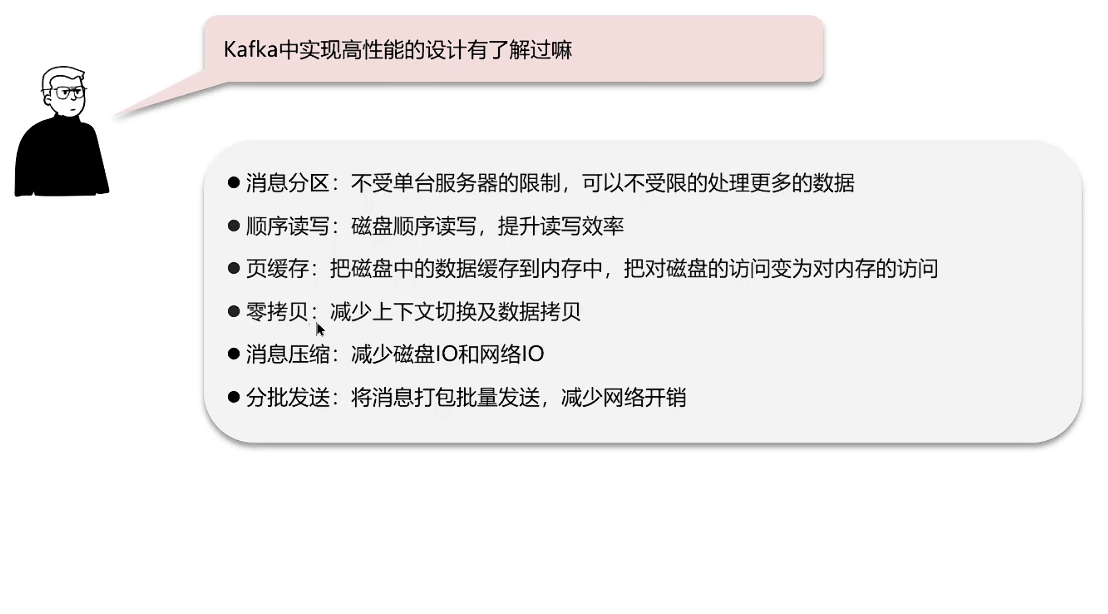
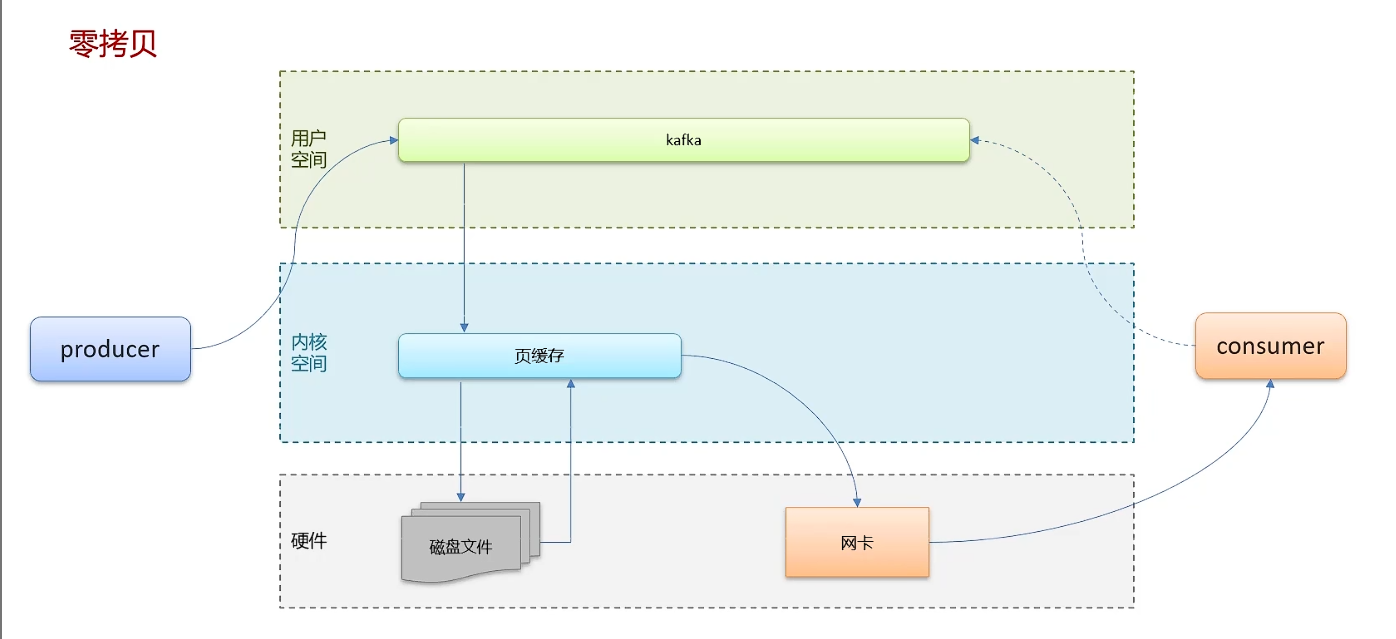
kafka高性能设计
中间件:位于应用系统和底层系统(如操作系统、数据库、网络)之间的“桥梁软件”,核心作用是解耦、协调不同系统,简化复杂的交互逻辑。
“消息中间件” 则聚焦于 “消息” 的传递与管理 ,是专门处理分布式系统中 “跨应用、跨服务数据通信” 的工具。
消息中间件是一种基于 “消息” 的异步通信组件,能够在分布式架构下,让不同的应用 / 服务(比如 A 系统和 B 系统)无需直接连接,而是通过 “消息”(本质是结构化的数据,如 JSON、XML)进行间接通信。
| 痛点场景 | 直接通信的问题 | 消息中间件的解决方案 |
|---|---|---|
| 系统耦合 | A 服务调用 B 服务时,必须知道 B 的地址、接口格式;若 B 升级或下线,A 也得改代码。 | 解耦:A 只需要把消息发给中间件,不用管谁来接收;B 从中间件拿消息,也不用管谁发来的。A 和 B 完全独立。 |
| 同步阻塞 | A 调用 B 后,必须等 B 处理完、返回结果才能继续执行;若 B 处理慢(如生成订单后发邮件),A 会被 “卡住”。 | 异步通信:A 发完消息就立即返回,继续做自己的事(如完成订单支付);B 异步从中间件取消息处理(如后台发邮件),互不阻塞。 |
| 流量峰值 | 秒杀活动中,瞬间有 10 万请求打向支付服务,直接超出服务承载能力,导致服务崩溃。 | 削峰填谷:中间件先接收所有请求消息并暂存起来,再按照支付服务的处理能力 “匀速” 把消息发给它,避免服务被冲垮。 |
| 数据丢失 | A 调用 B 时,若网络中断或 B 突然宕机,数据会直接丢失(如用户付款后订单没生成)。 | 可靠存储:消息中间件会把消息持久化到磁盘,直到接收方确认 “已处理” 才删除,避免网络 / 服务故障导致的数据丢失。 |
| 并发过载 | 若 A 服务同时调用 B、C、D 三个服务,A 需要处理三个服务的返回结果,并发逻辑复杂,容易出错。 | 异步分发:A 只需发 1 条消息到中间件,中间件可自动将消息分发给 B、C、D(“发布 - 订阅” 模式),A 无需关心后续流程。 |
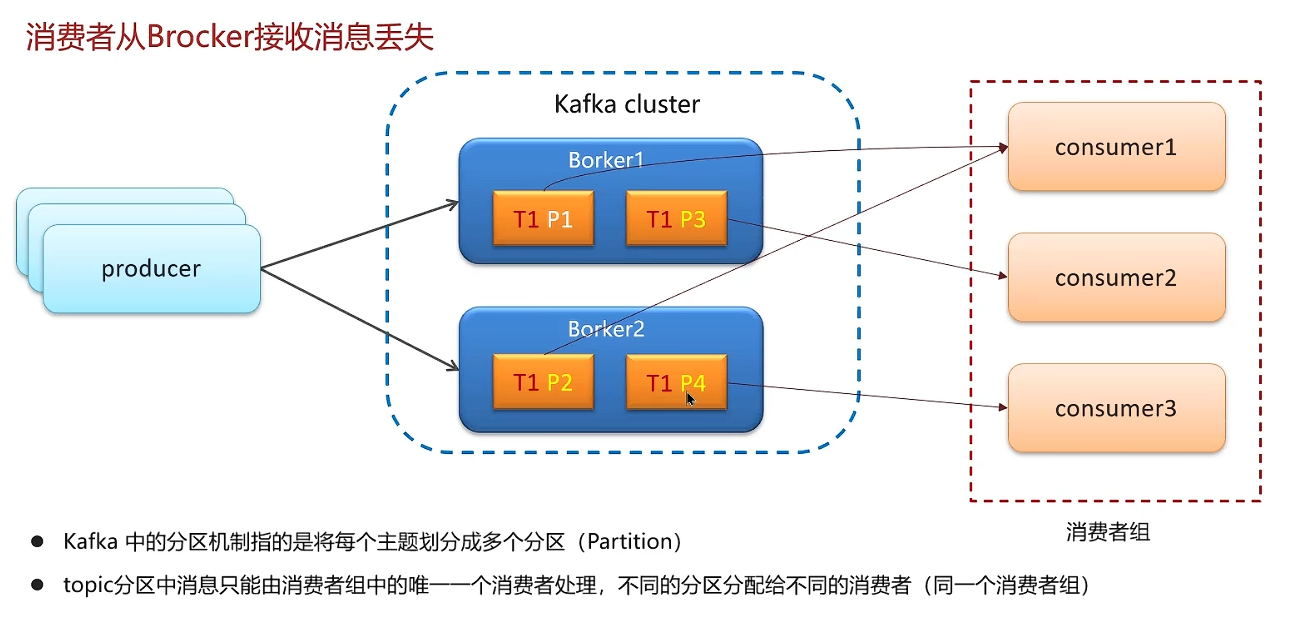
三个角色:生产者、消费者、消息队列
两种核心通信方式:P2P点对点,发布-订阅模式
RabbitMQ
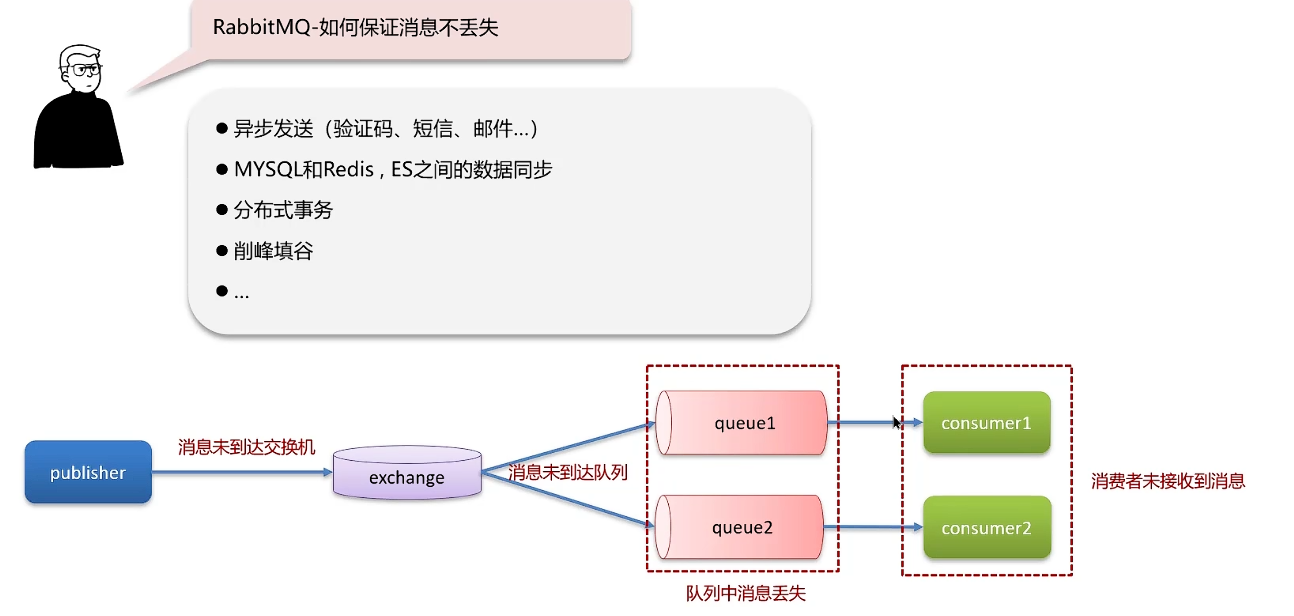
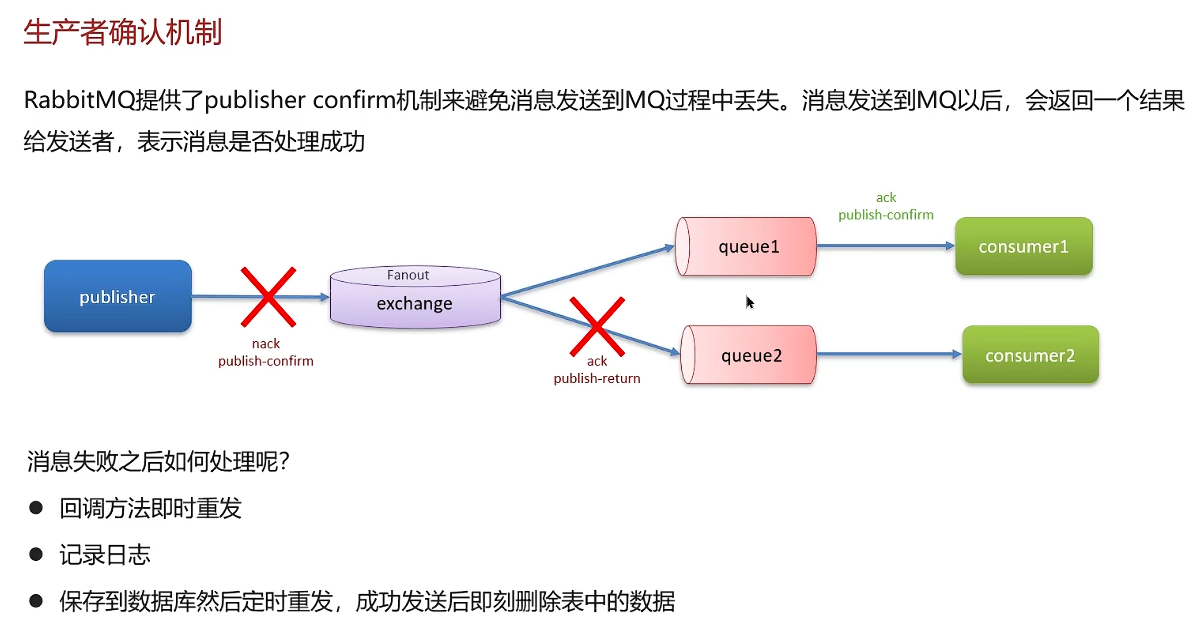
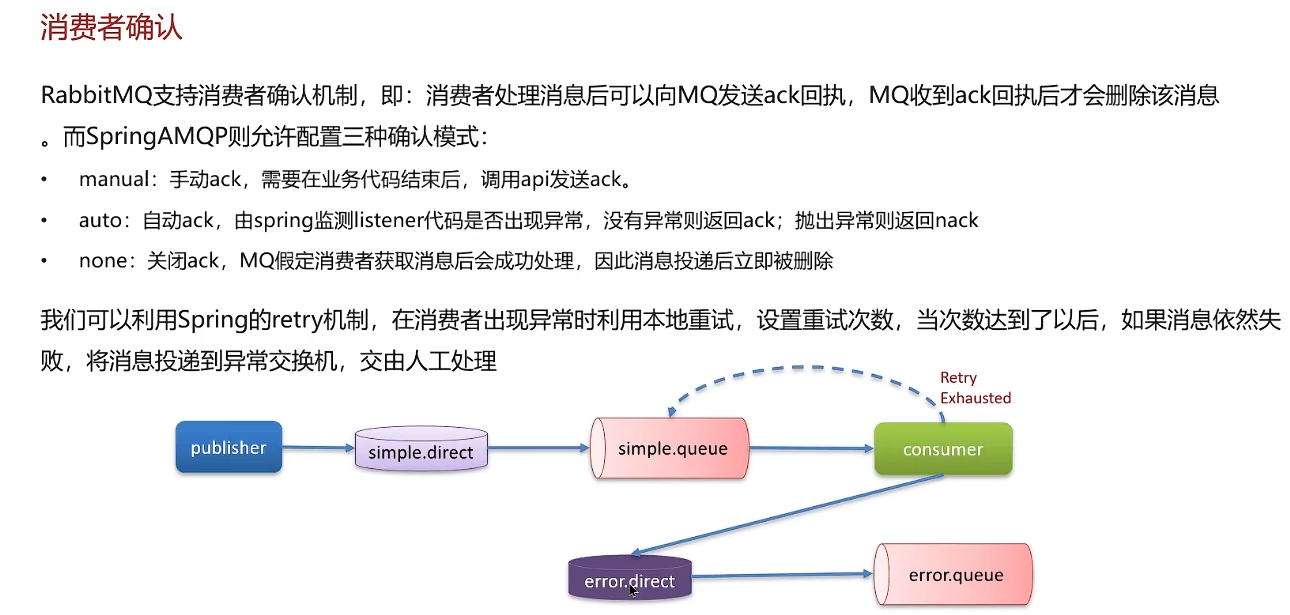
如何保证消息不丢失
三种情况可能丢失消息:
- 生产者发送消息没有到达交换机或消息队列
- MQ宕机导致消息丢失
- 消费者服务宕机丢失消息



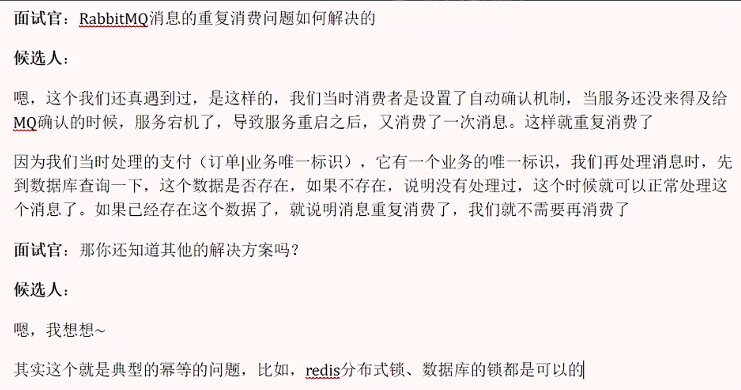
消息的重复消费问题是怎么解决的?
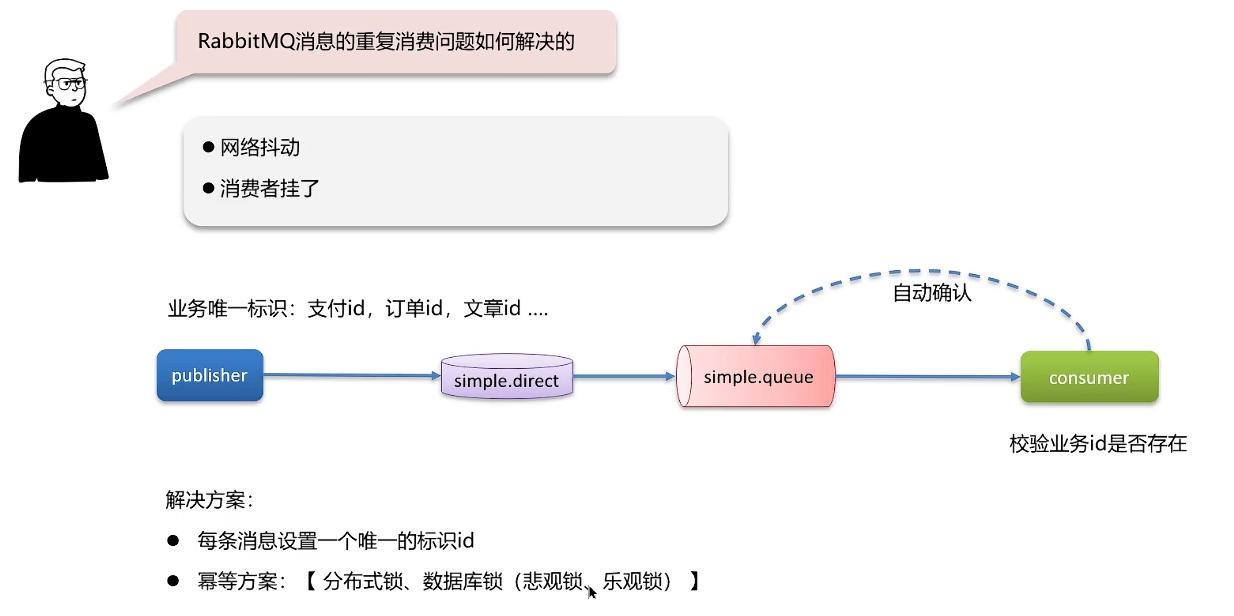
加锁之后的性能会低,优先采用第一个方案:为每条消息设置一个标识id
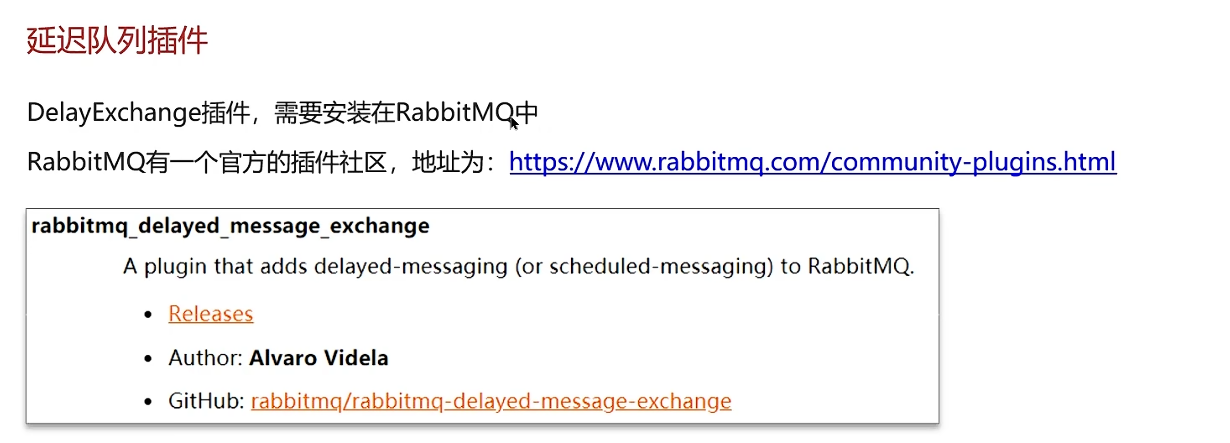
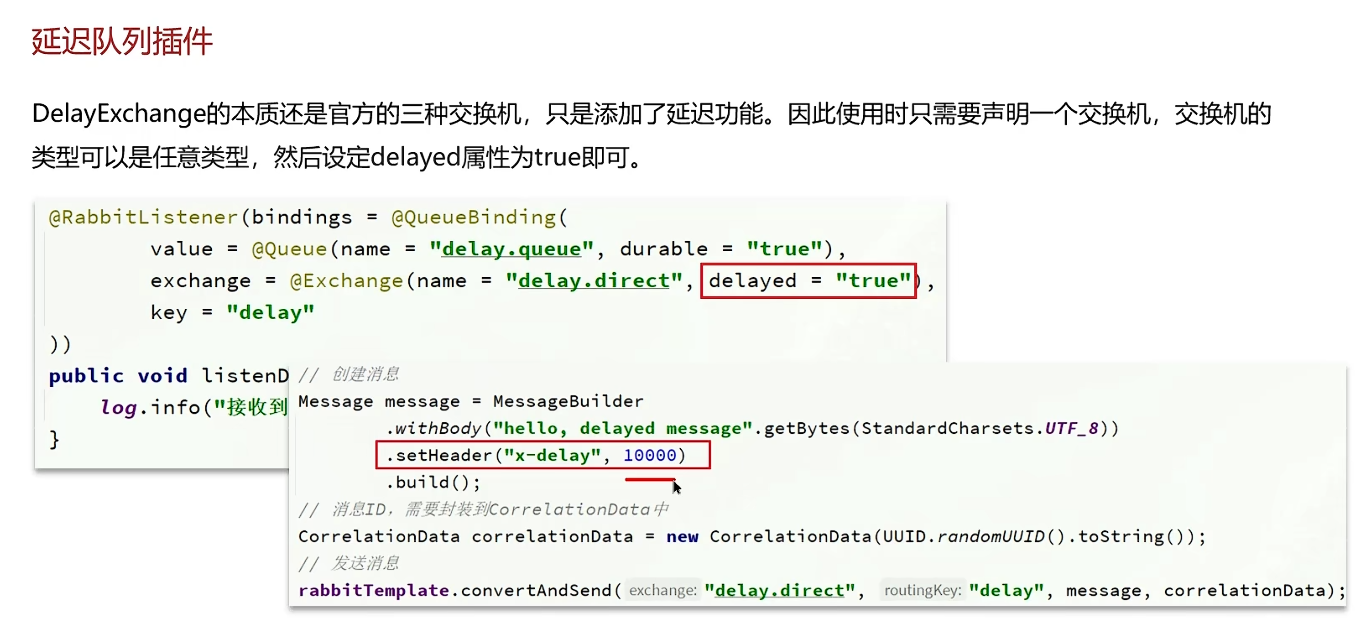
死信交换机/延迟队列
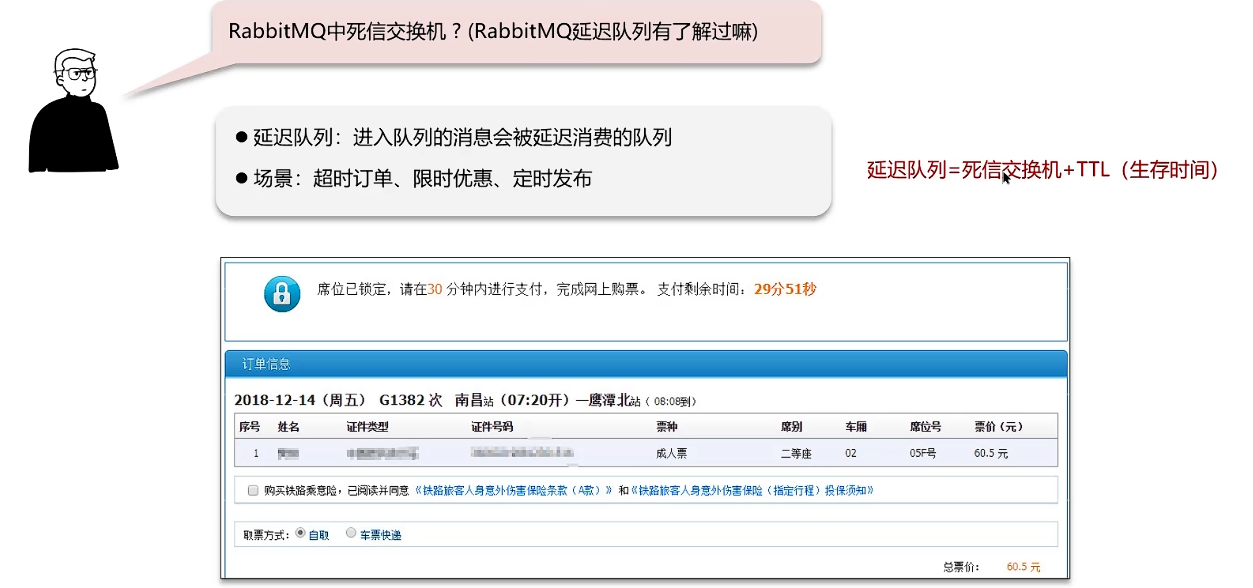
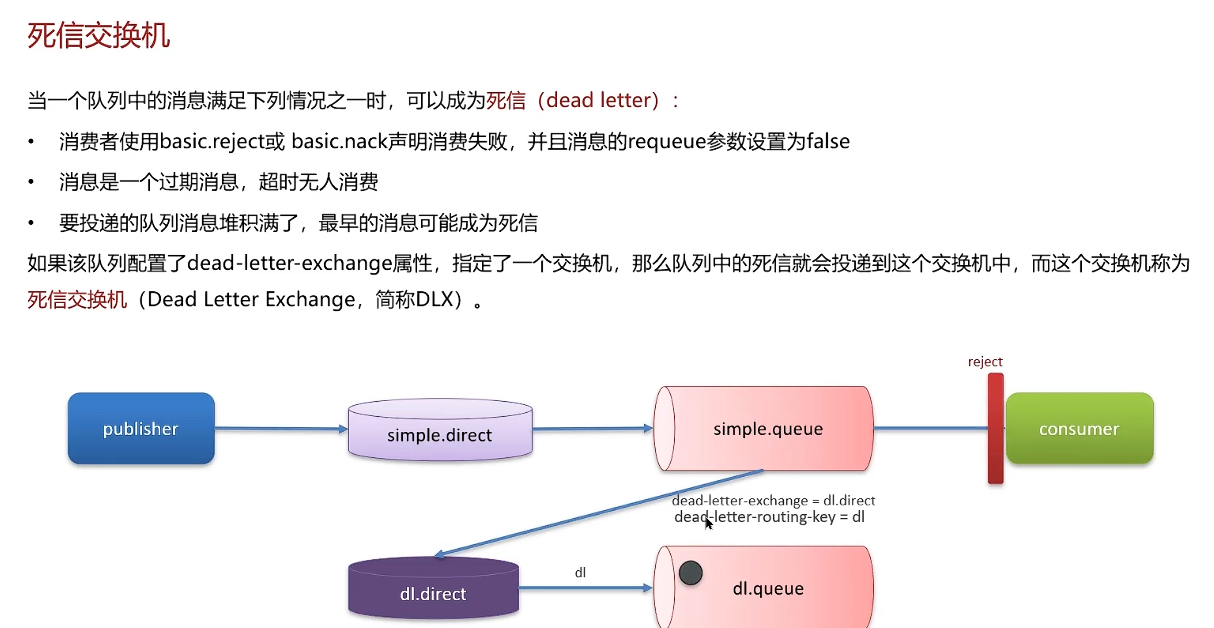

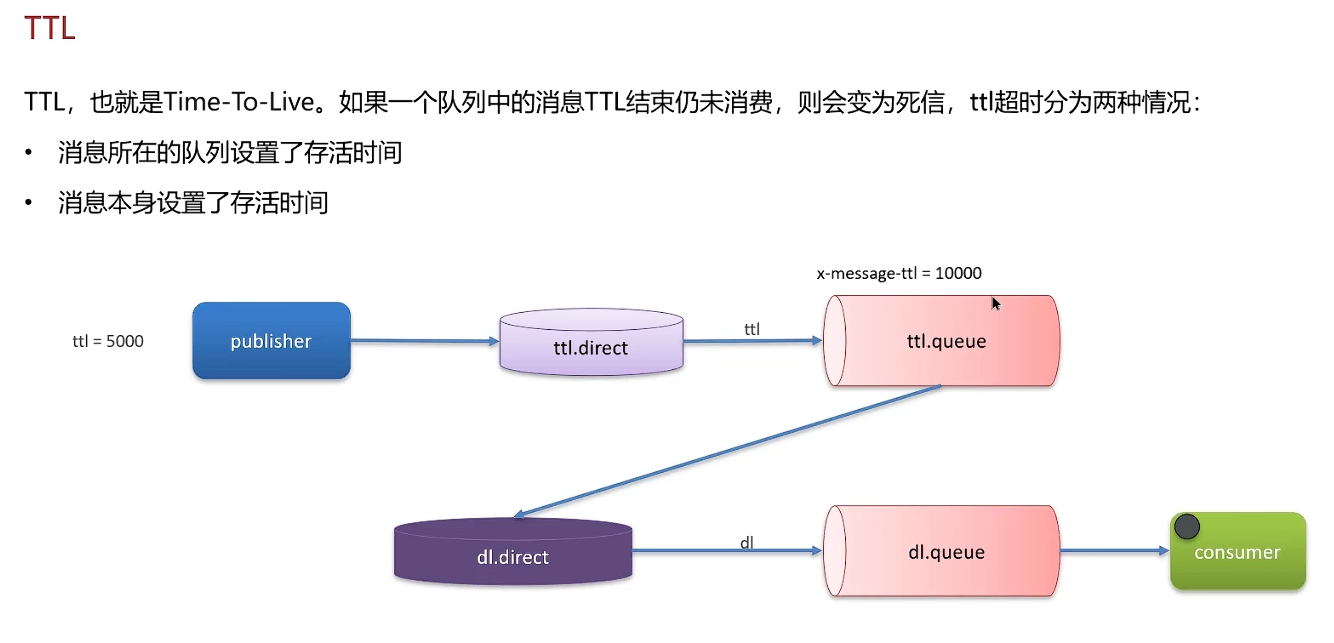
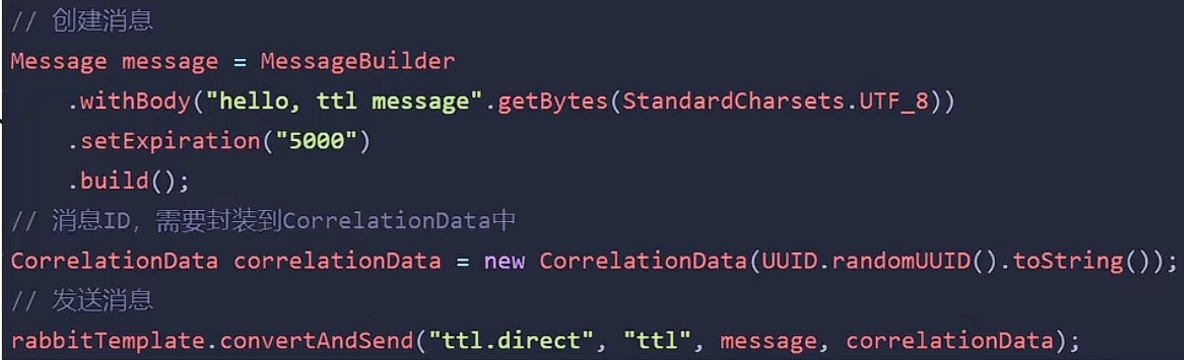
TTL哪个地方设置的短,以短的为准


如果有100万消息堆积在MQ,怎么解决?(消息堆积怎么解决)
线程池:一种线程管理机制,预先创建一定数量的线程并维护在一个“池”中,当有任务需要处理时,直接从池中取出线程执行任务,任务完成后线程不会被销毁,而是放回池中等待下一次使用。核心作用是:优化线程的创建、销毁成本、提高系统资源利用率。 “线程工厂+回收站”
java.util.concurrent.ExecutorService(如ThreadPoolExecutor、Executors工具类);
在多线程编程中,如果每次有任务就创建新线程,会存在明显问题:
-
资源消耗大线程的创建和销毁需要消耗 CPU 和内存资源(比如分配栈空间、内核态与用户态切换),频繁创建销毁线程会导致系统资源浪费。
-
稳定性风险若短时间内有大量任务(比如高并发请求),无限制创建线程可能导致内存溢出(OOM)或线程调度开销剧增,甚至引发系统崩溃。
-
管理复杂手动管理大量线程的生命周期(创建、运行、销毁)会增加代码复杂度,容易出现线程泄漏、同步问题等。
线程池通过 “复用线程” 和 “统一管理” 解决上述问题,主要价值体现在:
- 降低资源消耗:线程复用避免了频繁创建销毁线程的开销。
- 提高响应速度:任务到达时,无需等待线程创建,直接使用池中的空闲线程。
- 控制并发数量:通过设置线程池最大容量,防止线程数量失控,避免系统过载。
- 便于管理监控:统一管理线程的生命周期,支持任务排队、超时控制、状态监控等高级功能
第三种方法:扩大队列容积,提高堆积上限。
使用 惰性队列



高可用机制

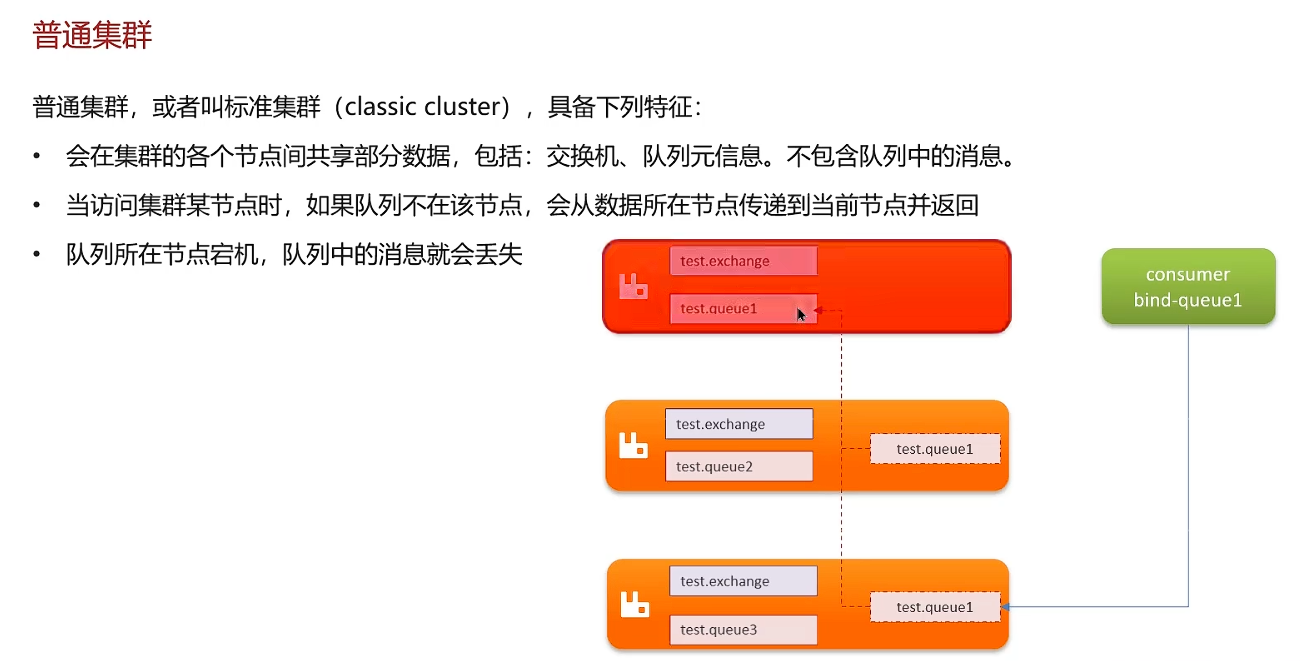
普通集群的缺点:如果某个队列所在节点宕机,队列中的消息就会丢失。
所以一般不会使用普通集群
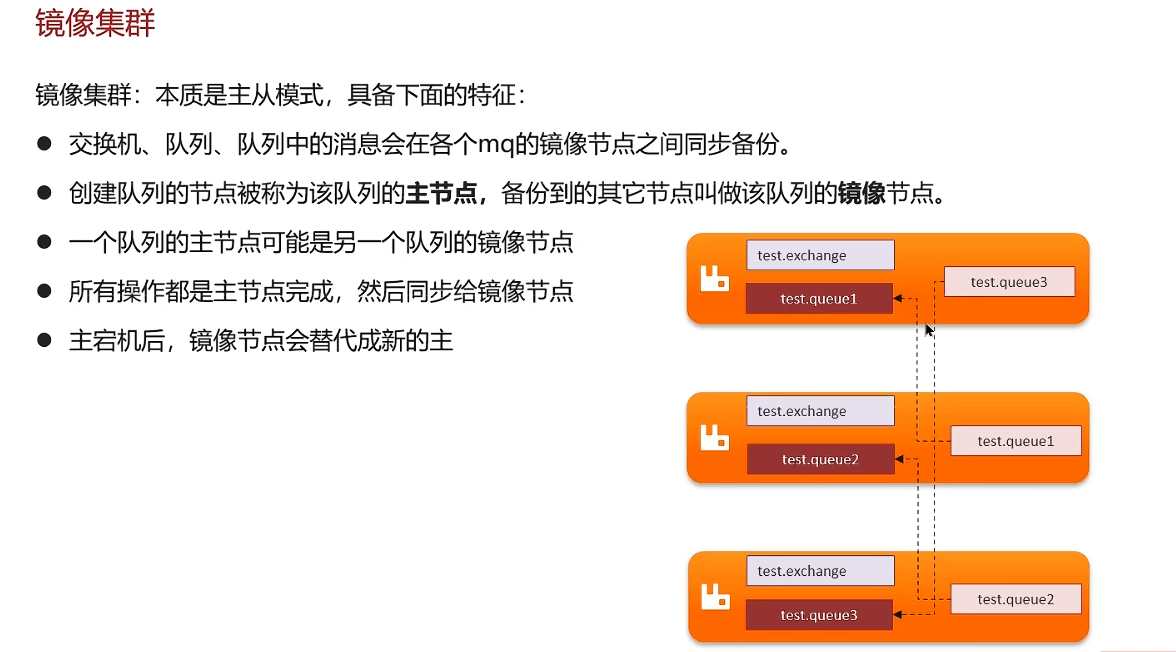
有一个小缺点:如果镜像节点还没来得及同步完成,主节点就宕机了,可能就会丢失数据。但是相对来说这种情况很少见。如果非要解决的话,就使用仲裁队列



kafka
如何保证消息不丢失?
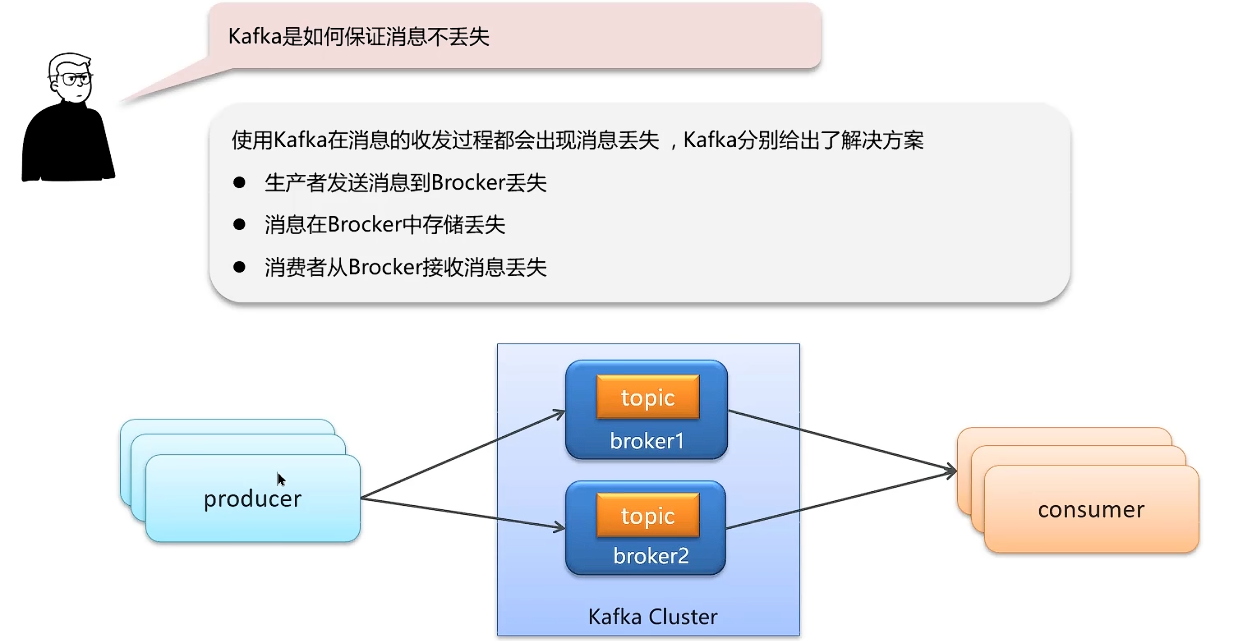
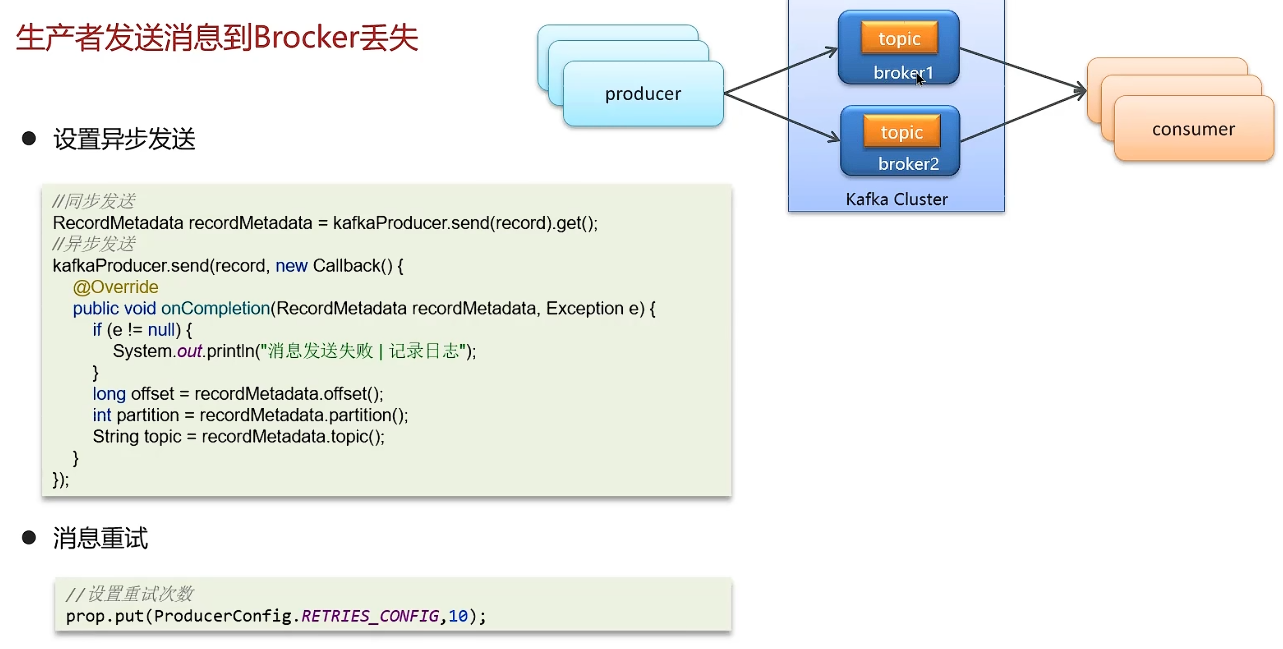
如果网络不稳定导致的发送失败:消息重试
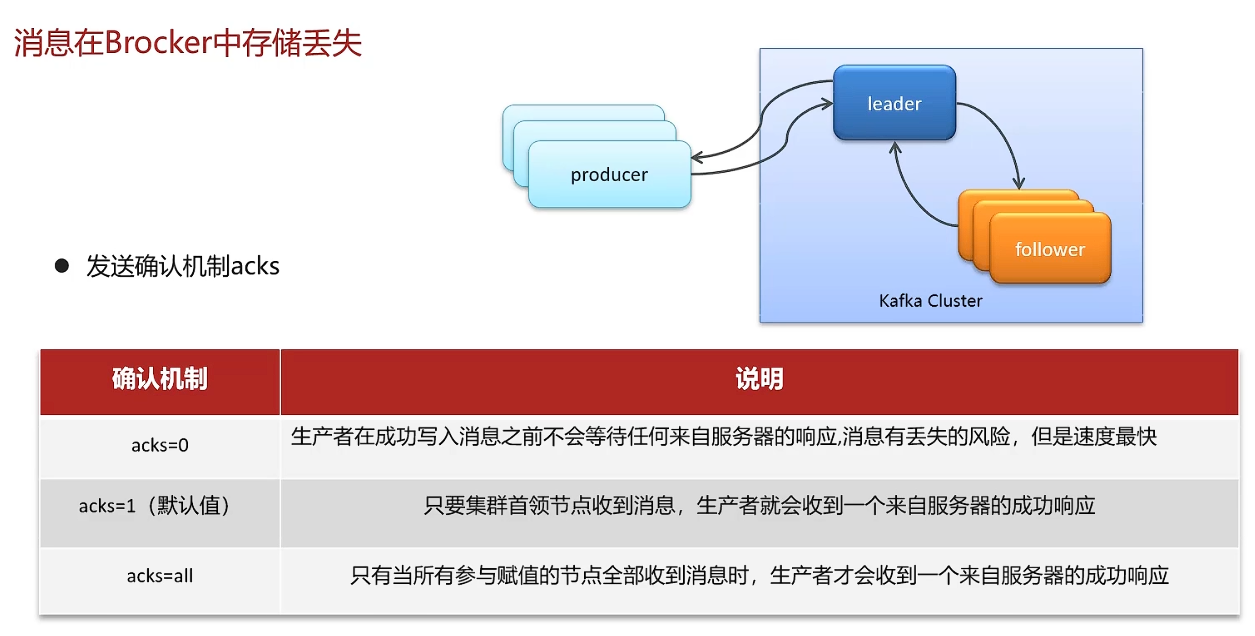
一般生产环境下设置acks=1
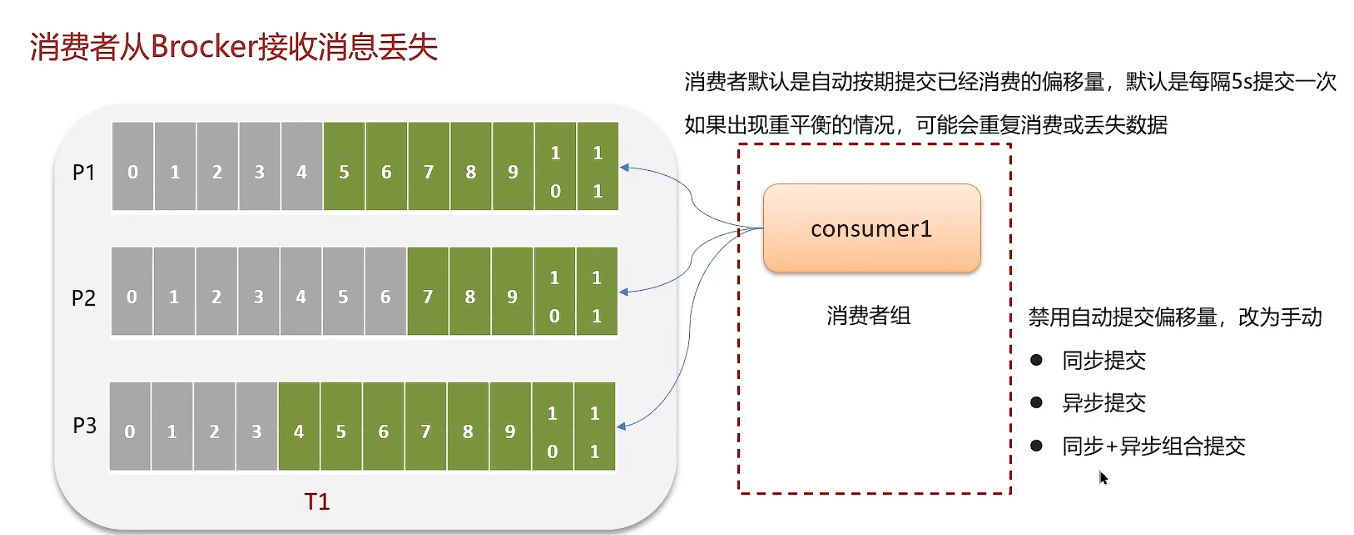
由于消费者默认是自动按期提交已经消费的偏移量,默认是每隔5s提交一次,如果出现重平衡的情况,可能会重复消费或丢失数据。
同步提交会阻塞,异步提交可能会导致偏移量不准确
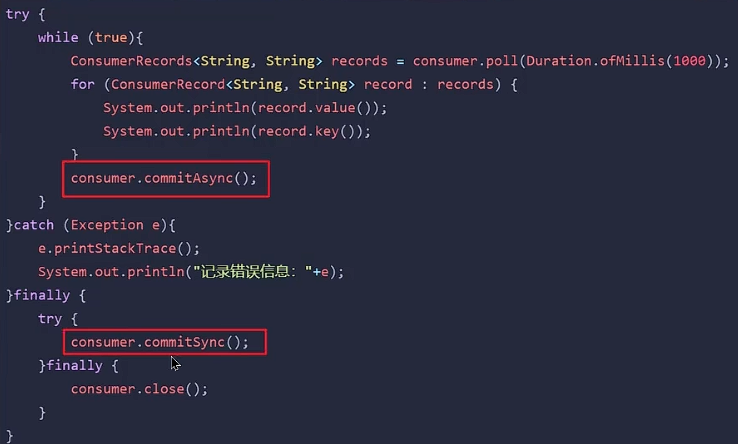
同步+异步提交:在消费完消息之后设置一个异步提交,最后在finally代码块中设置同步提交


如何保证消费顺序性

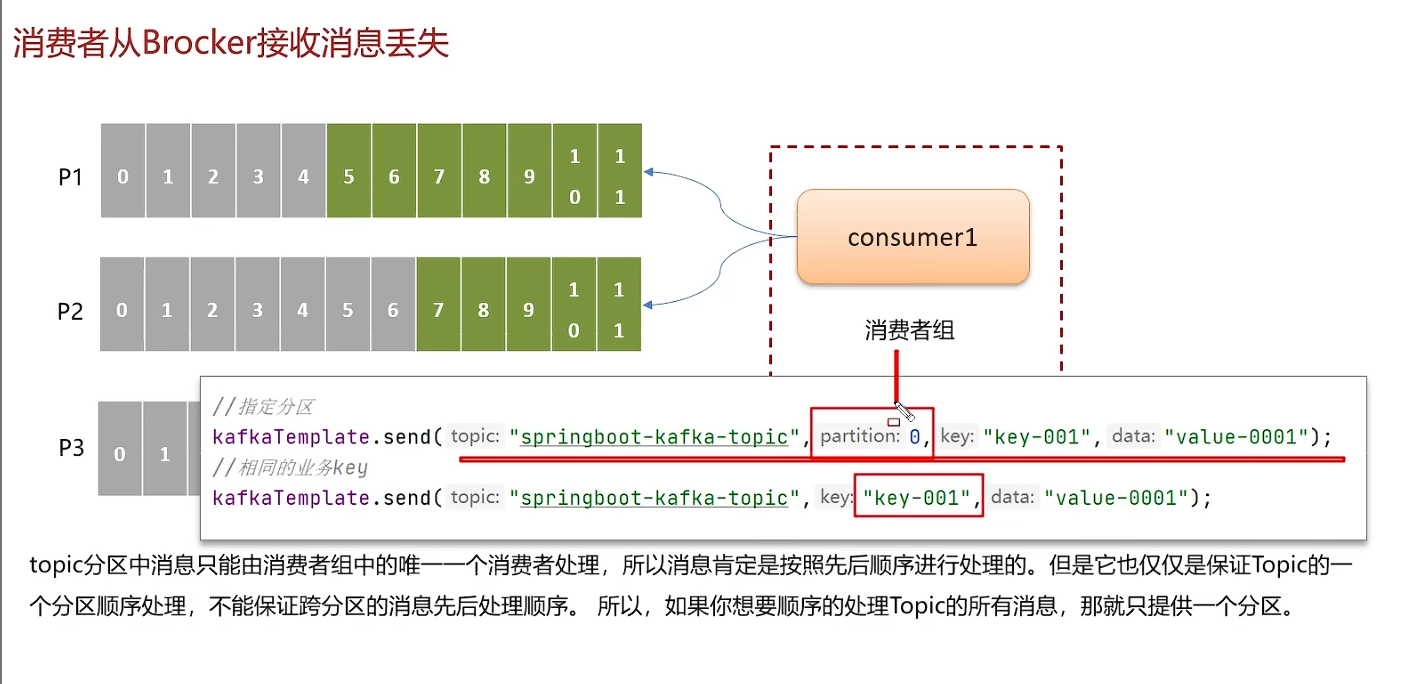
把有顺序需求的消息都放在同一个分区


高可用机制
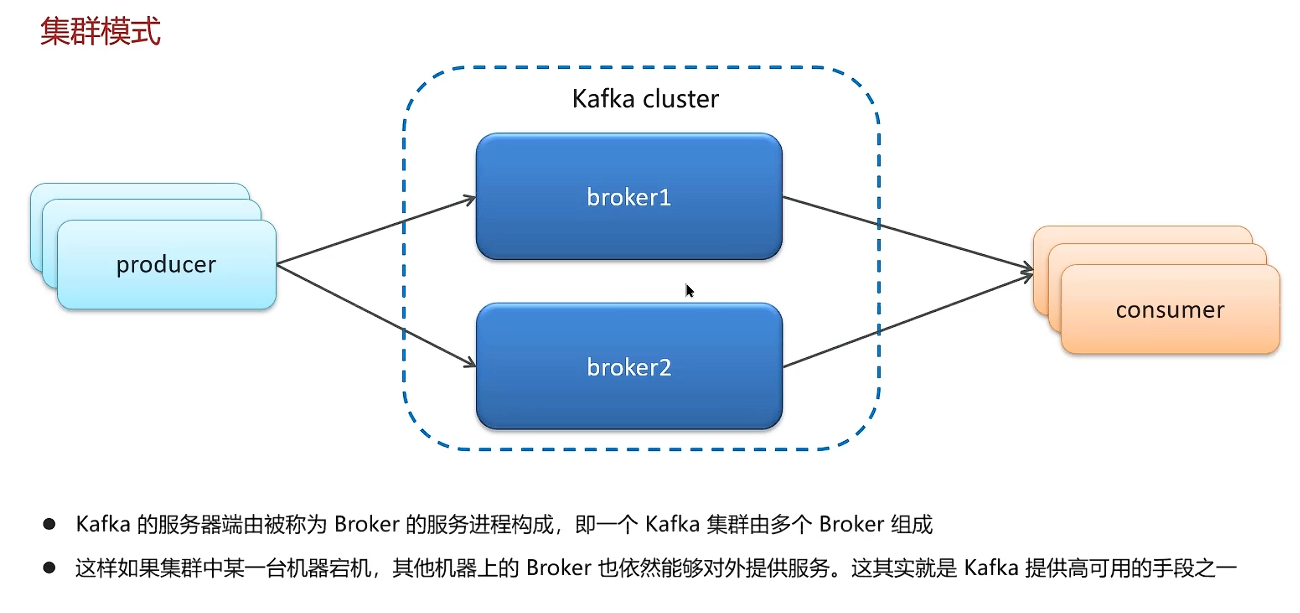
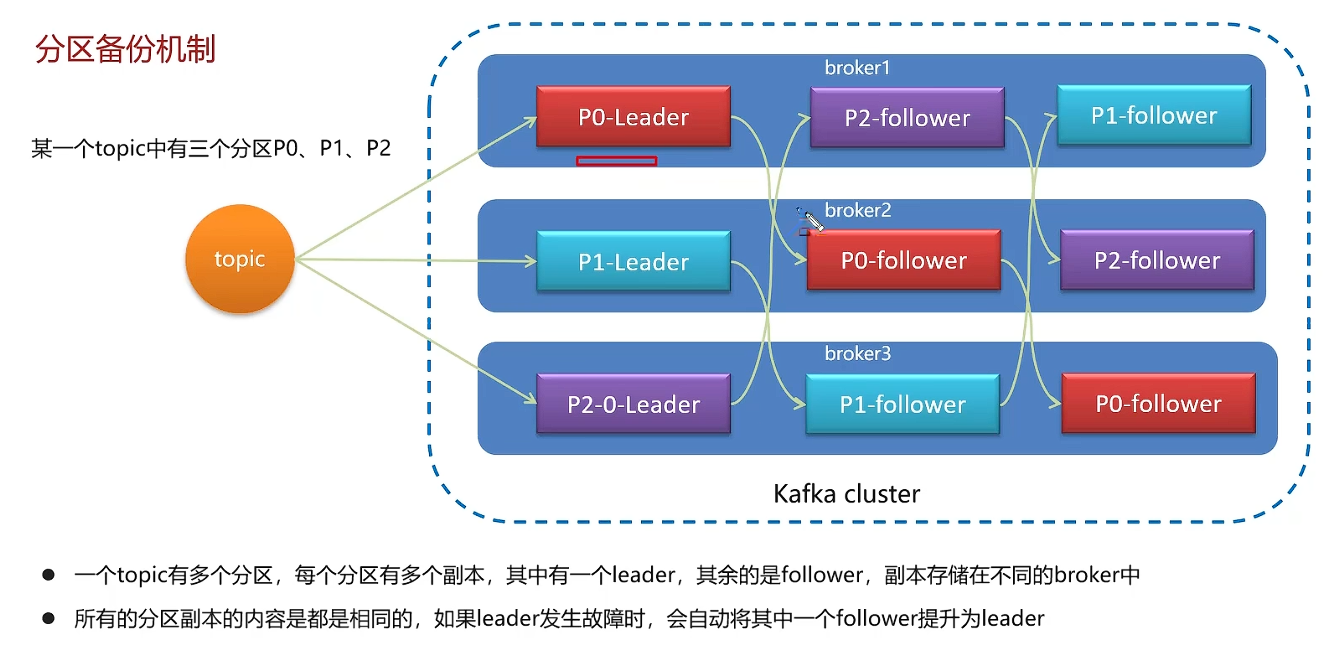
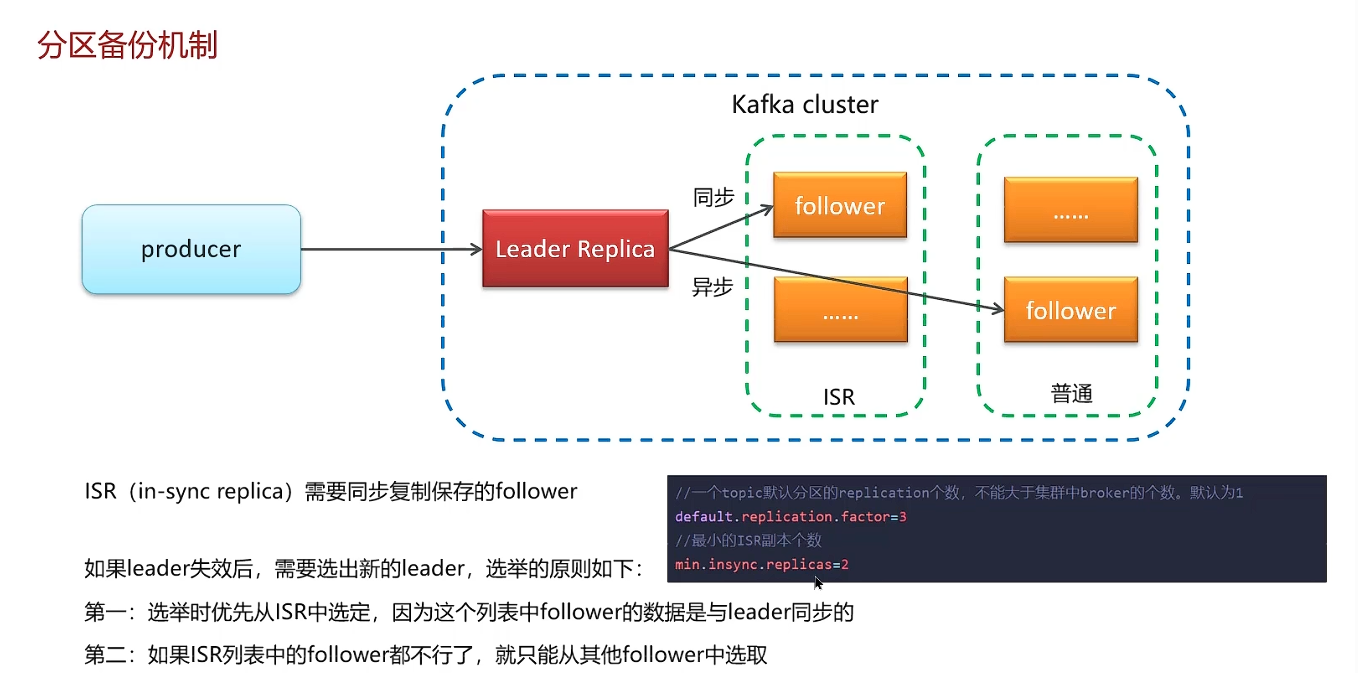
ISR是同步保存数据,性能不高;异步保存数据的效率更高
这样可以在保证高可用性的前提下,保证数据存储的时效性


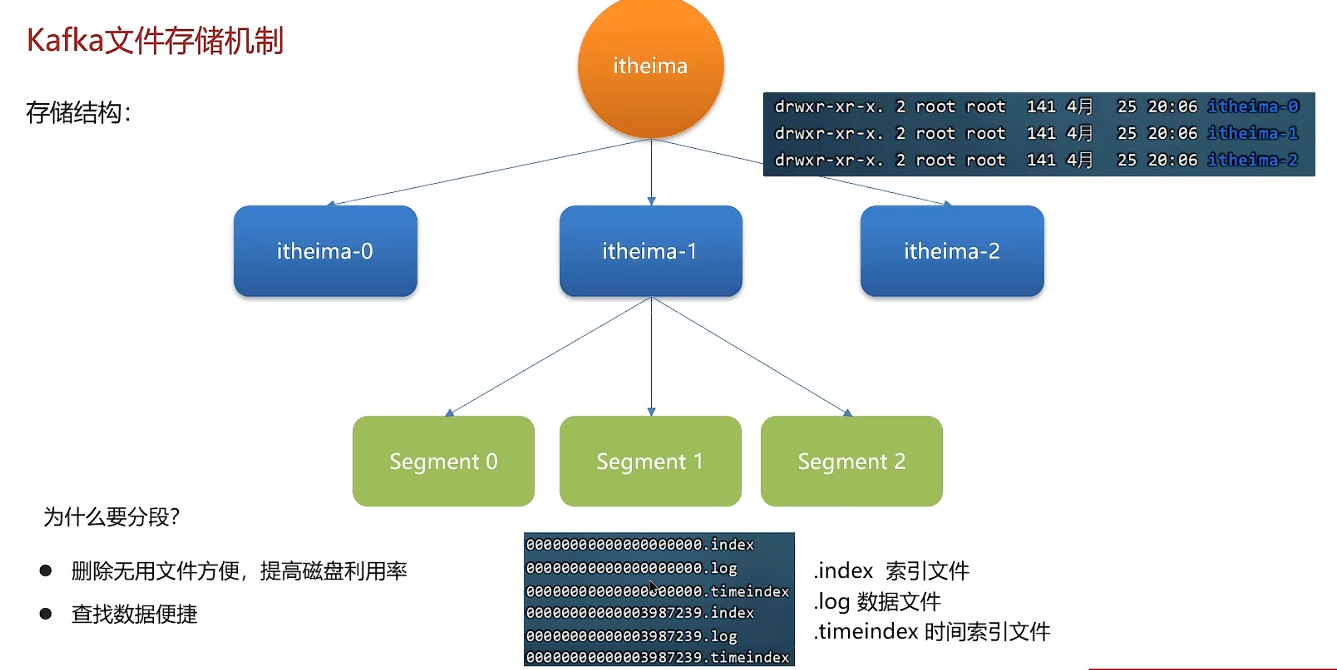
数据清理机制



kafka高性能设计