【Big Data】DataX 3.0 星型数据链路架构的实践与价值
目录
一、DataX的定义与基本概念
二、DataX的诞生背景与发展历程
三、DataX的架构设计
1. 框架核心组件
2. 数据流与执行流程
3. 模块交互机制
四、DataX解决的核心问题
1. 异构数据源之间的批量同步
2. 高吞吐量的数据传输
3. 数据质量与容错保障
4. 复杂网络环境下的数据同步
五、DataX的关键特性
1. 插件化架构
2. 高性能传输
3. 灵活的任务切分
4. 强大的数据转换能力
5. 健壮的容错机制
六、DataX与同类产品对比
1. 与Kettle对比
2. 与SeaTunnel对比
3. 与Flink CDC对比
七、DataX的使用方法
1. 安装配置
2. 基本使用
3. 高级功能使用
1. Transformer数据转换
2. 增量同步
3. 集群部署(通过DataX-Web)
八、DataX的使用场景与最佳实践
1. 适用场景
2. 最佳实践
九、总结与展望
十、附录:常见问题解答
1. DataX为什么使用Python启动?
2. DataX与DataWorks数据集成的关系?
3. DataX如何保证数据一致性?
4. DataX如何处理大数据量?
5. DataX如何与Hadoop生态集成?
DataX是阿里云DataWorks数据集成模块的开源版本,作为一款离线数据同步工具,它在阿里巴巴集团内部被广泛使用,每天完成超过8万次数据同步作业,传输数据量超过300TB。DataX的核心价值在于解决异构数据源之间的高效批量数据迁移问题,通过其独特的Framework+Plugin架构设计,实现了对多种数据源的无缝对接,成为大数据生态中不可或缺的数据集成组件。

一、DataX的定义与基本概念
DataX是一个轻量级、高性能的离线数据同步工具/平台,由阿里巴巴集团开源。它专注于解决异构数据源之间的数据传输问题,将复杂的网状同步链路转化为星型数据链路,极大简化了数据源之间的连接方式 。DataX的核心思想是:当需要接入一个新的数据源时,只需开发对应的插件,即可实现与已有所有数据源的互导,无需重新开发每一对数据源之间的传输逻辑。
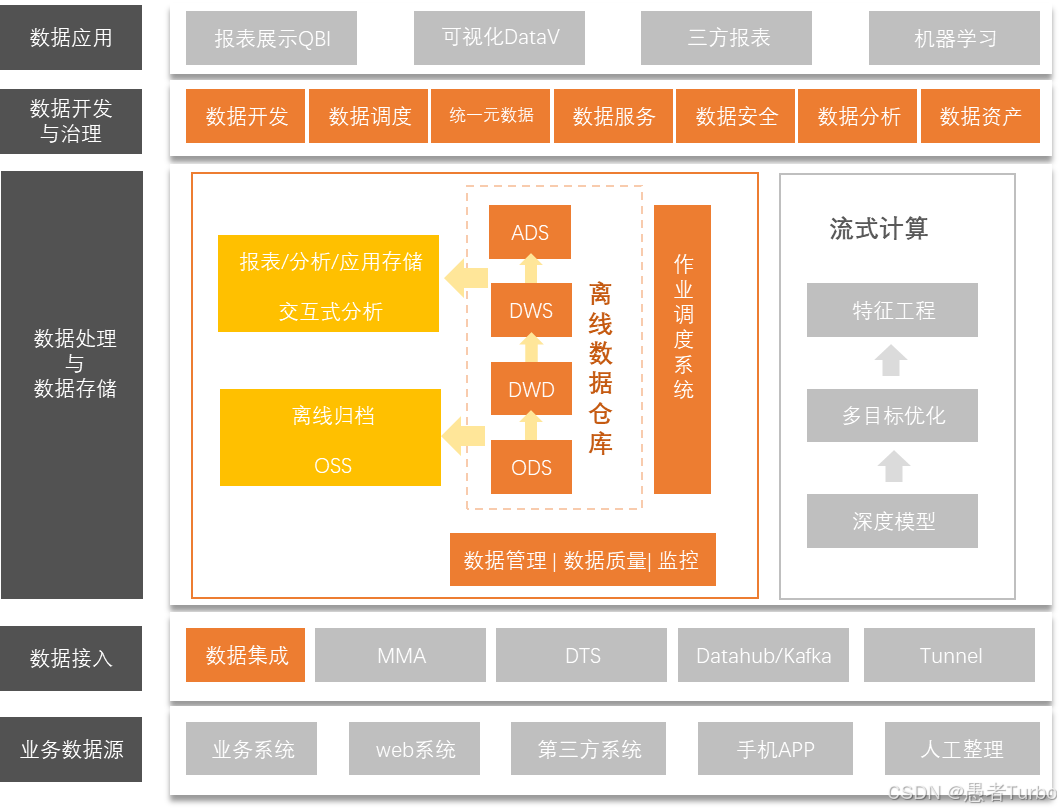
DataX采用的是纯Java开发,但启动脚本使用Python编写,这种设计使其能够充分利用Java的高性能和Python的易用性。DataX的运行模式是单机多线程,通过配置通道数(channel)来实现并行处理,提高数据传输效率。在DataX中,数据同步作业被定义为Job,每个Job可以切分为多个Task并行执行,每个Task负责一部分数据的同步工作 。
二、DataX的诞生背景与发展历程
DataX的诞生可以追溯到2011年,当时阿里云数据平台事业部成立,DataX 1.0与2.0版本相继发布,主要用于解决阿里巴巴内部异构数据源之间的数据同步问题。2014年,阿里云DataWorks数据集成服务正式对外提供,同年DataX 3.0版本发布。2016年左右,DataX作为DataWorks数据集成的开源版本正式对外发布,成为行业标准工具。
DataX的发展历程经历了多个关键阶段:
- 2011-2014年:DataX作为阿里内部数据同步工具,完成1.0到3.0版本迭代,奠定核心架构
- 2016年:DataX开源,成为阿里云大数据生态的重要开源组件
- 2017年:DataX在阿里云上线,到2017年Q3完成了大部分特性开发,后续仅做少量修补
- 2020年:阿里云DataWorks数据集成正式推出实时同步服务,DataX作为其开源版本继续迭代
- 2023年:DataX持续迭代,新增支持GaussDB等数据库,优化流控和性能
在阿里云DataWorks数据集成服务中,DataX主要负责离线批量同步场景,而实时同步则由Flink CDC等组件负责。DataX的定位是数据上云的核心枢纽,致力于打造一个可靠、安全、低成本且可弹性伸缩的异构数据源之间的数据同步平台。
三、DataX的架构设计
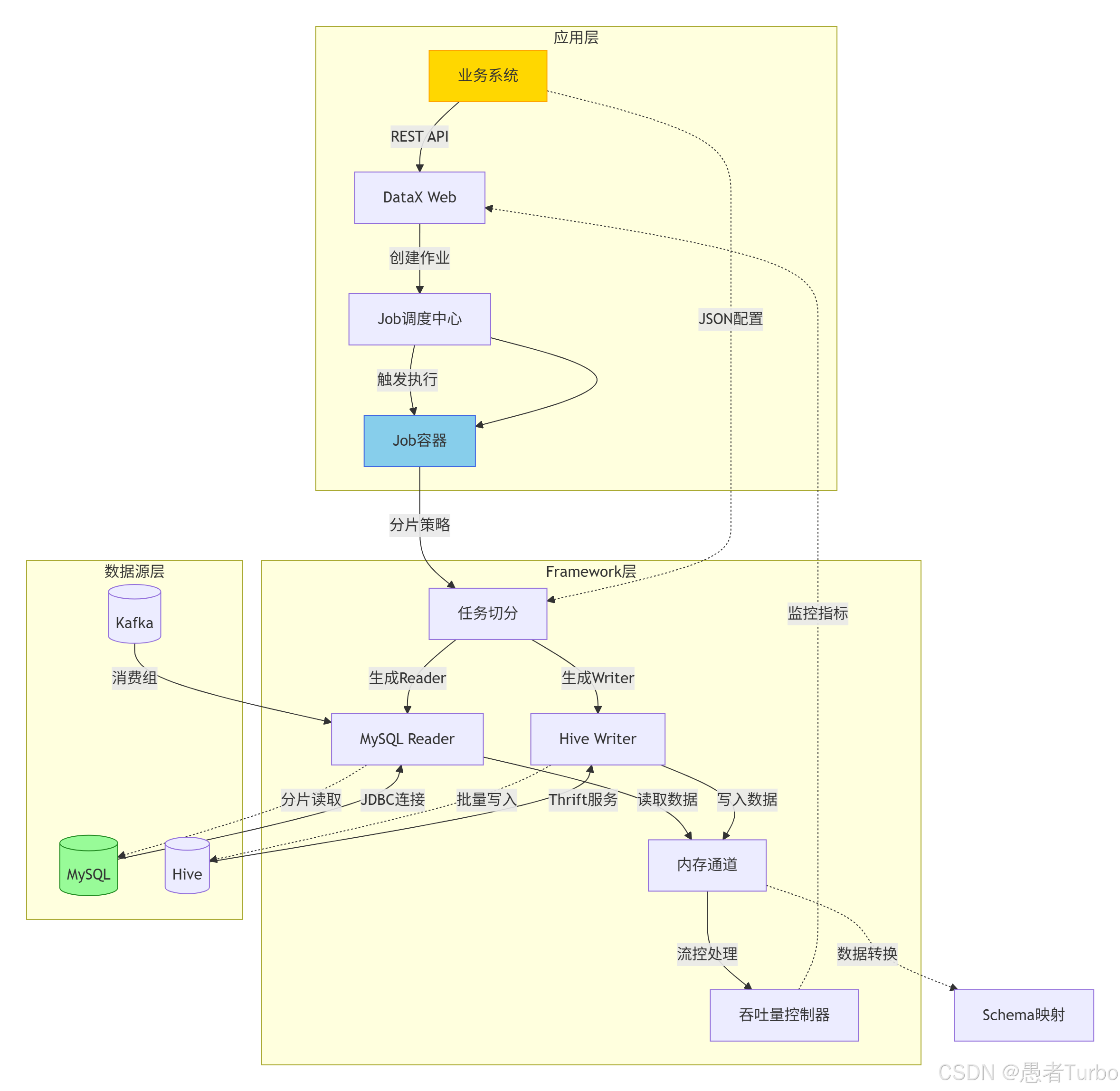
DataX采用的是Framework+Plugin架构,将数据同步过程中的读取和写入操作抽象为Reader和Writer插件,而Framework负责连接和管理这些插件,处理缓冲、流控、并发等核心技术问题 。这种设计使得DataX能够灵活支持各种数据源,只需开发对应的插件即可实现数据的读取或写入。
1. 框架核心组件
DataX架构主要包括以下几个核心组件:
- Job:作为数据同步作业的中枢管理节点,负责整个作业的配置校验、任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能 。
- TaskGroup:任务组,负责管理分配到它下面的所有Task,并根据Task运行情况分配合适的并发。每个TaskGroup默认支持5个并发Task 。
- Task:数据同步的最小执行单元,每个Task包含Reader→Channel→Writer的完整数据流,负责一部分数据的同步工作 。
- Reader:数据采集模块,负责从源端数据源读取数据并发送给Framework 。
- Writer:数据写入模块,负责从Framework获取数据并写入到目标数据源 。
- Channel:数据传输通道,作为Reader和Writer之间的缓冲层,负责数据在内存中的存储和传输。
- Transformer:数据转换模块,可选组件,用于在数据传输过程中进行转换处理,如数据脱敏、补全、过滤等 。
2. 数据流与执行流程
DataX的数据同步流程如下:
- 用户配置Job的JSON文件,定义数据源、同步参数和转换逻辑 。
- DataX启动Job进程,进行配置校验 。
- Job根据源端切分策略(如主键、时间范围、文件分片等)将Job切分为多个Task 。
- Job调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup 。
- 每个TaskGroup启动并管理其下的多个Task 。
- 每个Task启动后,固定启动Reader→Channel→Writer的线程来完成任务同步工作 。
- Reader从源端读取数据,写入Channel的内存缓冲区。
- Writer从Channel的内存缓冲区读取数据,写入目标端。
- 若配置了Transformer,则在Reader和Writer之间进行数据转换处理 。
- Job监控并等待多个TaskGroup模块任务完成,所有TaskGroup任务完成后Job成功退出 。
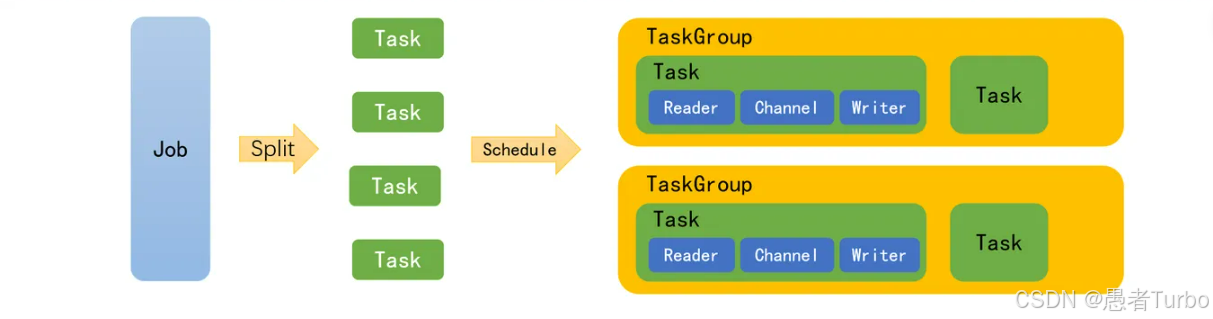
3. 模块交互机制
DataX的架构设计中,各个模块之间的交互机制非常关键:
- Framework与插件的交互:Framework通过标准化接口与Reader、Writer、Transformer插件交互,插件只需实现特定接口即可融入框架 。
- Channel的缓冲机制:使用ArrayBlockingQueue作为内存缓冲区,通过bufferSize控制容量,支持记录数(record)和字节数(byte)的流控策略 。当Reader读取数据时,将数据写入Channel的缓冲区;Writer则从缓冲区读取数据,写入目标端 。
- Transformer的实现:在数据流中,Transformer插件用于数据转换,可实现自定义业务逻辑,如字段解密、数据过滤等 。
四、DataX解决的核心问题
DataX主要解决以下几类数据同步问题:
1. 异构数据源之间的批量同步
DataX支持20多种主流数据源之间的互导,包括关系型数据库(MySQL、Oracle、PostgreSQL等)、NoSQL数据库(HBase、MongoDB等)、大数据存储(HDFS、Hive等)、云存储(OSS等)以及文件系统(TXT、FTP等)。通过星型数据链路设计,DataX解决了传统网状同步链路的复杂性和耦合性问题 ,使得不同数据源之间的同步变得简单高效。
2. 高吞吐量的数据传输
DataX采用单机多线程模型,通过合理的任务切分和并行处理,实现了线性增长的同步性能。在测试环境中,基于24核48GB的DataX服务器和32核256G的MySQL服务器,在4通道,4000+批量提交行数的基础上,其同步写入速度可以达到8万条/秒,随着通道数的提高,其性能指标还能继续提升。
3. 数据质量与容错保障
DataX提供了可靠的数据质量监控机制,包括强数据类型支持、脏数据探测与过滤、线程级重试等。DataX3.0版本解决了旧版对部分数据类型(如时间戳)传输时的毫秒级失真问题,每一种插件都有自己的数据类型转换策略,确保数据完整无损地传输到目的端。
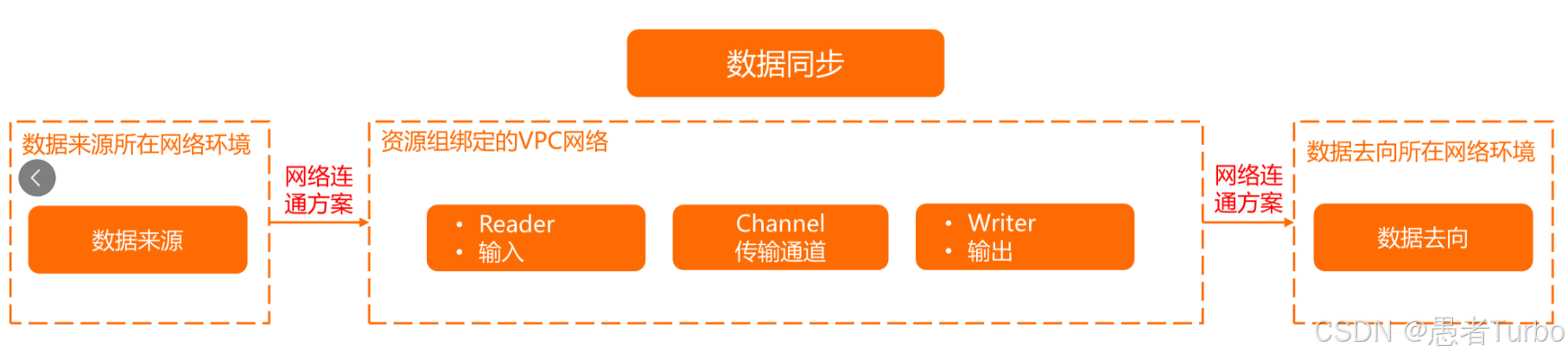
4. 复杂网络环境下的数据同步
DataX支持在复杂网络环境下的数据源同步,包括数据源与DataWorks工作空间在同一个阿里云主账号的不同地域、跨IDC环境等。通过灵活的配置,DataX能够适应各种网络环境,确保数据同步的稳定性和可靠性。
五、DataX的关键特性
1. 插件化架构
DataX最大的特点是其插件化架构,将数据源的读取和写入抽象为Reader和Writer插件。这种设计使得DataX能够轻松扩展新的数据源支持,只需开发对应的插件即可。目前DataX已经支持了20多种主流数据源,包括关系型数据库、NoSQL数据库、大数据存储系统等。
2. 高性能传输
DataX采用单机多线程模型,通过通道(channel)的并行处理实现高性能数据传输。DataX3.0版本提供了三种流控模式:通道(并发)、记录流、字节流,可以根据数据源的性能特点灵活调整同步速度,确保在源端和目标端性能足够的情况下,单个作业能够充分利用网络带宽。
3. 灵活的任务切分
DataX支持多种任务切分策略,包括按主键、时间范围、文件分片等 。通过合理的任务切分,DataX能够将大数据量的同步作业分解为多个小任务并行执行 ,提高整体同步效率。例如,在MySQL到HDFS的同步中,可以根据主键范围将数据切分为多个Task,每个Task负责一部分数据的同步。
4. 强大的数据转换能力
DataX提供了丰富的数据转换功能,包括内置的Transformer(如FilterTransformer、JavaScriptTransformer等)和自定义Transformer。通过Transformer,可以在数据传输过程中实现数据脱敏、补全、过滤等转换操作,满足复杂的业务需求。例如,在数据同步到MaxCompute前,可以使用Transformer将日期格式转换为符合要求的格式。
5. 健壮的容错机制
DataX设计了完善的容错机制,包括线程内部重试、线程级别重试、TaskFailover等。当同步过程中出现网络闪断、数据源不稳定等异常时,DataX能够自动进行重试或重新调度,保证作业的稳定运行。例如,在医学数据同步案例中,DataX能够根据数据库性能自动调整同步速度,避免对源数据库造成压力。
六、DataX与同类产品对比
1. 与Kettle对比
| 对比维度 | DataX | Kettle |
|---|---|---|
| 架构设计 | Framework+Plugin架构,插件化设计 2 | 纯Java编写,可视化界面 |
| 部署复杂度 | 仅需JDK+Python环境,部署简单 3 | 部署复杂,学习成本高 |
| 性能 | 单机多线程模型,高吞吐量(如MySQL到HDFS同步速度达11596条/秒) | 性能较弱,对源数据库有侵入性(如需要时间戳字段) |
| 适用场景 | 适合批量同步,对源数据库压力小 | 擅长数据清理和转换,但批量同步性能不足 |
DataX与Kettle的核心差异在于设计目标和适用场景。DataX专注于高效的数据传输,而Kettle则更注重数据的清洗和转换。在性能方面,DataX明显优于Kettle,尤其是在处理大数据量时。例如,在医学数据同步案例中,DataX的平均同步速度达每秒11596条,而Kettle最快仅能达到每秒2540条,还会对源头数据库造成压力 。
2. 与SeaTunnel对比
| 对比维度 | DataX | SeaTunnel |
|---|---|---|
| 部署模式 | 单机部署,无分布式架构 11 | 支持分布式架构,可集群部署 |
| 并发度 | 依赖单机多线程,最大并发受限于单机资源 4 | 支持多节点并行,可弹性扩展 |
| 数据源支持 | 支持20+种数据源 11 | 支持100+种数据源,覆盖更广 11 |
| 性能 | 单机性能较好,但受限于单机 11 | 单机性能比DataX高40%-80%,且支持集群高吞吐 19 |
| 功能特性 | 支持基本的数据转换和过滤 4 | 支持自动建表、整库同步、断点续传等高级功能 19 |
| 引擎支持 | 仅支持DataX自己的引擎 19 | 支持SeaTunnel Zeta、Flink和Spark三种引擎 |
SeaTunnel是DataX的升级版,解决了DataX在分布式和功能扩展方面的不足 。SeaTunnel采用了更先进的架构设计,支持分布式快照算法,保证数据一致性,并且提供了更丰富的监控和调优功能。例如,在电商订单同步案例中,SeaTunnel的峰值吞吐量达到45万行/秒,而DataX受限于单机性能,无法达到如此高的吞吐量。
3. 与Flink CDC对比
| 对比维度 | DataX | Flink CDC |
|---|---|---|
| 同步类型 | 离线批量同步 | 实时CDC同步 |
| 实时性 | 实时性较差,依赖查询方式 | 实时性好,基于日志解析 |
| 数据一致性 | 支持至少一次传输保障机制(at least once) 14 | 支持精确一次(exactly once) |
| 部署复杂度 | 部署简单,但扩展性差 3 | 部署复杂,依赖Flink生态 |
| 资源占用 | 内存占用相对较低 19 | 资源占用较高,尤其是状态存储 19 |
Flink CDC专注于实时数据同步,而DataX专注于离线批量同步 。两者在数据同步领域各有所长,可以互补使用。例如,在金融核心系统迁移项目中,可以使用DataX进行全量数据同步,再使用Flink CDC进行增量同步,实现零停机迁移。
七、DataX的使用方法
1. 安装配置
DataX的安装非常简单,仅需以下步骤:
- 安装JDK(推荐1.8.201以上版本)
- 安装Python(支持Python2.7或Python3,但需注意DataX启动脚本默认使用Python2,若使用Python3需修改替换datax/bin下的三个python文件)
- 下载DataX:从GitHub或Gitee下载最新版本
wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz - 解压并测试
tar -xvf datax.tar.gz cd datax/bin python datax.py ../job/job.json
对于特定数据源(如HDFS、MaxCompute等),还需要安装相应的客户端依赖:
- HDFS:需要Hadoop客户端,配置hadoopConfig参数
- MaxCompute:需要安装MaxCompute Tunnel SDK,配置odpsConfig参数
2. 基本使用
DataX的基本使用是通过编写JSON配置文件定义数据同步任务,然后通过命令行启动。以下是一个从MySQL读取数据并写入HDFS的简单示例:
{"job": {"setting": {"speed": {"channel": 4 // 设置通道数,即并行度},"errorLimit": {"record": 0, // 允许失败的记录数"percentage": 0.02 // 允许失败的百分比}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","column": ["id", "name", "age"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test","table": ["user"]}]}},"writer": {"name": "hdfswriter","parameter": {"column": ["id", "name", "age"],"defaultFS": "hdfs://hadoop131:9000","path": "/mysql2hdfs","hadoopConfig": {"dfs.client.failover.proxy provider.mytest": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider","dfs.ha.namenodes.mytest": "nn1,nn2","dfs.namenode.rpc-address.mytest.nn1": "192.168.1.100:9000","dfs.namenode.rpc-address.mytest.nn2": "192.168.1.101:9000","dfs(nameservices": "mytest"}}}}]}
}启动命令:
python bin/datax.py job/mysql2hdfs.json3. 高级功能使用
1. Transformer数据转换
Transformer是DataX的高级功能,用于在数据传输过程中进行转换处理。以下是一个使用Transformer对字段进行解密的示例:
{"job": {"setting": {"speed": {"channel": 4},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","column": ["id", "encrypted_name", "age"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test","table": ["user"]}]}},"transformer": [{"name": "dx_test_transformer", // 自定义Transformer名称"parameter": {"columnIndex": "1", // 要处理的列索引"script": "解密脚本内容" // 解密脚本}}],"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "root","column": ["id", "name", "age"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test","table": ["user_new"]}]}}]}}
}2. 增量同步
DataX支持基于时间戳和自增主键的增量同步。以下是一个基于时间戳的增量同步示例:
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "root","column": ["id", "name", "create_time"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test","querySql": ["select * from user where create_time >= FROM_UNIXTIME(${lastTime}) and create_time < FROM_UNIXTIME(${currentTime})"]}]}},"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "root","column": ["id", "name", "create_time"],"connection": [{"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test","table": ["user_new"]}]}}]]}
}启动命令中传递时间参数:
python bin/datax.py -p "-DlastTime=1609459200 -DcurrentTime=1609545600" job/增量同步.json3. 集群部署(通过DataX-Web)
DataX本身是单机部署的,但可以通过DataX-Web实现分布式数据同步 。DataX-Web是在DataX之上开发的分布式数据同步工具,提供可视化界面和任务管理功能。
集群部署步骤:
- 安装MySQL(5.7或8.x版本)
- 下载并解压DataX-Web
- 执行安装脚本
./bin/install.sh - 修改执行器配置文件
env.properties,指定DataX的Python脚本位置PYTHON_PATH=/opt/datax/bin/datax.py - 修改执行器配置文件
application.yml,指定DataX-Web地址和执行器名称addresses: http://192.168.10.151:9527 appname: datax-executor - 启动DataX-Web和执行器
./bin/start-all.sh./bin/start.sh -m datax-executor - 通过Web界面创建任务并选择执行器
八、DataX的使用场景与最佳实践
1. 适用场景
DataX主要适用于以下场景:
- 离线批量数据迁移:如将传统数据库中的历史数据迁移至大数据平台
- 数据仓库建设:将各种业务系统的数据同步到数据仓库,进行统一管理
- 跨平台数据共享:在不同技术栈的系统之间实现数据共享
- 数据备份与恢复:定期备份重要数据,或在系统迁移时进行数据恢复
2. 最佳实践
在使用DataX时,建议遵循以下最佳实践:
- 合理配置通道数:通道数(channel)决定了并行度,应根据源端和目标端的性能进行调整。如,在MySQL到HDFS的同步中,可以设置channel为4-8,以充分利用网络带宽。
- 使用Transformer简化配置:对于需要数据转换的场景,应优先使用Transformer,而不是在源端或目标端进行转换。
- 增量同步策略:对于需要定期同步的场景,应采用增量同步策略,减少数据传输量 。
- 监控与调优:通过DataX-Web或日志监控同步过程,及时发现和解决性能问题 。
- 结合其他工具使用:对于需要实时同步的场景,可以结合Flink CDC使用;对于需要复杂数据处理的场景,可以结合Kettle使用 。
九、总结与展望
DataX作为阿里云开源的数据同步工具,以其轻量级、高性能、插件化等特性,成为大数据生态中不可或缺的组件。它解决了异构数据源之间的批量同步问题,为数据中台建设提供了坚实基础 。
随着技术的发展,DataX也在不断迭代和升级。未来,我们可以期待DataX在以下几个方面的改进:
- 增强实时同步能力:虽然DataX主要专注于离线同步,但未来可能会增强其实时同步能力,或与Flink CDC等工具更好地集成。
- 支持更多数据源:随着大数据生态的扩展,DataX可能会支持更多新兴的数据源。
- 改进监控和管理功能:提供更完善的监控和管理功能,方便用户了解同步状态和性能。
- 支持分布式架构:虽然DataX本身是单机部署,但未来可能会支持分布式架构,或与SeaTunnel等工具更好地集成 。
对于技术开发人员来说,DataX是一个值得掌握的数据同步工具,它不仅能够解决实际的数据迁移问题,还能帮助我们理解大数据生态中的数据集成原理。随着DataX的不断演进,它将继续在数据同步领域发挥重要作用,成为构建企业级数据平台的重要工具之一。
十、附录:常见问题解答
1. DataX为什么使用Python启动?
DataX是Java开发的,但启动脚本使用Python编写,这是因为Python的脚本语言特性使得配置管理和任务调度更加灵活和简单。同时,Python的轻量级部署也使得DataX更容易在各种环境中运行。
2. DataX与DataWorks数据集成的关系?
DataX是DataWorks数据集成模块的开源版本,两者在功能上是互补的。DataWorks数据集成提供了更全面的数据集成解决方案,包括实时同步、数据清洗、任务调度等,而DataX专注于离线批量同步的高性能实现。
3. DataX如何保证数据一致性?
DataX采用的是至少一次(at least once)的数据一致性保障机制,即数据可能会出现重复,但不会丢失。为了保证数据一致性,可以结合目标端的特性(如主键约束)或使用Transformer进行数据去重处理。
4. DataX如何处理大数据量?
DataX通过任务切分(split)和并行处理(parallel)来处理大数据量 。任务切分将大数据量的同步作业分解为多个小任务,每个小任务负责一部分数据的同步;并行处理则通过配置通道数(channel)来实现多线程并行处理,提高整体同步效率。
5. DataX如何与Hadoop生态集成?
DataX可以通过HDFS插件与Hadoop生态集成,实现与HDFS、Hive等组件的数据同步。对于需要与Hadoop生态深度集成的场景,可以考虑使用SeaTunnel等工具,它们提供了更完善的Hadoop生态集成支持。
通过本文的全面解析,相信技术开发人员已经对DataX有了深入的理解,能够根据实际需求选择合适的工具和配置,实现高效、可靠的数据同步。
参考资料:
- dataX 源码
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于愚者Turbo:
🌟博主GitHub
🌞博主知识星球