小米投下语音AI“核弹”:MiMo-Audio开源,语音领域的“GPT-3时刻”来了
目录
引言:语音AI为何亟需自己的“GPT-3时刻”?
一、核心突破:“涌现”与“举一反三”是如何实现的?
1.1 亿级小时数据的“大力出奇迹”
1.2 创新的架构:为语音信号无损“编码”
1.3 “思考”模式:让语音模型拥有“脑子”
二、性能“屠榜”:当开源模型叫板闭源巨头
三、不止是模型:开启语音领域的“LLaMA时刻”
3.1 开源了什么?一个完整的工具箱
3.2 这对开发者和行业意味着什么?
四、从快板到哲学:一个能说会道、高情商的语音模型
结语:迈向真正的语音AGI

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 小米MiMo-Audio开源
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
引言:语音AI为何亟需自己的“GPT-3时刻”?
五年前,GPT-3的横空出世,向世界展示了语言模型通过海量数据预训练,能够获得惊人的“上下文学习”(In-Context Learning, ICL)能力。这意味着模型不再需要为每个特定任务进行繁重的训练,仅需少量示例就能“举一反三”,快速迁移到新任务上。这被视为通往通用人工智能(AGI)的关键一步。
然而,在过去的五年里,语音领域似乎一直在等待自己的“GPT-3时刻”。传统的语音模型严重依赖大规模、高质量的“标注”数据(即人工告诉模型这段声音是什么意思),像是一个只会做题、不会思考的学生,难以泛化到训练数据之外的新场景,导致我们手机里的语音助手常常显得机械、呆板。
现在,小米正式开源的首个原生端到端语音大模型——Xiaomi-MiMo-Audio,似乎就是那个姗姗来迟的答案。它首次在语音领域,通过无监督预训练的方式,让模型自发地“涌现”出了跨任务的泛化能力,真正实现了“举一反三”。
一、核心突破:“涌现”与“举一反三”是如何实现的?
MiMo-Audio的成功并非偶然,而是建立在海量数据、创新架构和独特训练方法之上的必然结果。
1.1 亿级小时数据的“大力出奇迹”
MiMo-Audio的预训练数据量达到了惊人的“上亿小时”。这是一个关键的“临界点”。研究人员发现,当训练数据量突破某个阈值后,模型的能力会发生质变,出现“涌现”行为。
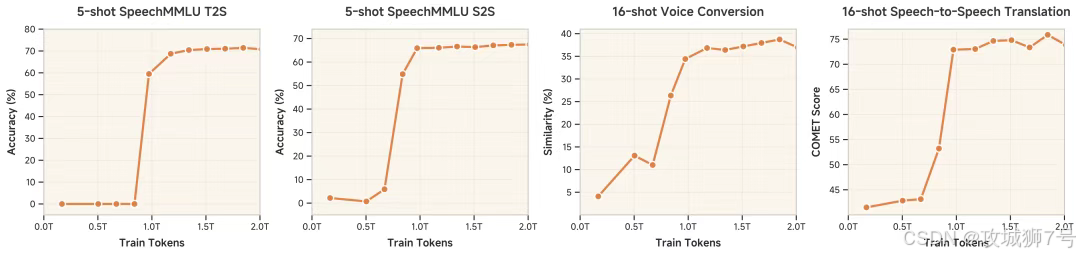
这意味着,MiMo-Audio学会了很多我们并未直接“教”它的东西。比如,训练数据里可能并没有专门的“语音风格转换”或“语音编辑”任务,但模型通过学习海量的声音规律,自发地理解了什么是音色、什么是语调、什么是情感,从而获得了这些高级能力。这正是从“死记硬背”到“融会贯通”的飞跃。
1.2 创新的架构:为语音信号无损“编码”
声音是一种高维度的连续信号,如何将其高效、无损地转化为模型能够理解的数字“令牌”(Token),是语音大模型的核心难题。
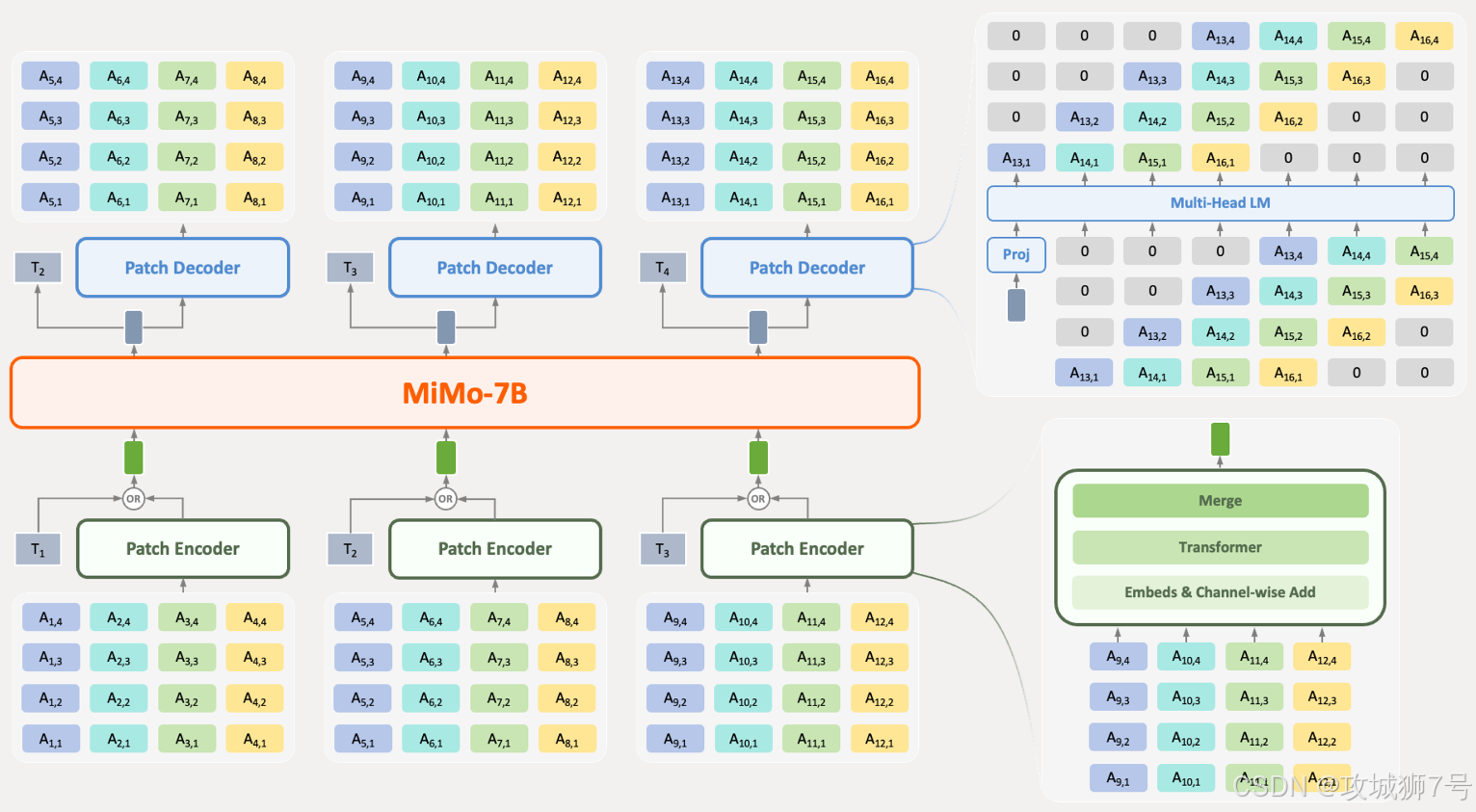
为此,小米专门研发并开源了一个强大的MiMo-Audio-Tokenizer。这个拥有12亿参数的“音频编码器”,基于Transformer架构,能够在保证音频重建保真度的前提下,高效地将声音压缩成Token。它就像一个顶级的速记员,能把复杂的声音信息,快速、准确地记录下来,供“大脑”(大模型)处理。
同时,MiMo-Audio采用了“补丁编码器 + 大语言模型 + 补丁解码器”的新型三段式架构,能够高效处理高码率的音频序列,解决了语音和文本模态之间长度差异的难题。
1.3 “思考”模式:让语音模型拥有“脑子”
MiMo-Audio是首个将“思考”(Thinking)机制同时引入语音理解和生成过程的开源模型。
其指令微调版本`MiMo-Audio-7B-Instruct`,可以通过一个简单的提示词,在“非思考”和“思考”两种模式间切换。在“思考”模式下,模型在生成回答前,会先进行一步内部的逻辑推理和规划。
这带来了什么好处?面对一个复杂问题,比如“如果手机内存不足,必须删掉我和GPT中的一个,你选谁?”,模型不再是脱口而出,而是会像人类一样先分析利弊,给出客观建议(先清缓存),最后再表达自己的立场,展现出极高的“情商”。这种“三思而后言”的能力,是其对话自然度远超传统模型的关键。
二、性能“屠榜”:当开源模型叫板闭源巨头
MiMo-Audio的发布,最令人振奋的莫过于其亮眼的性能评测数据。作为一个7B(70亿)参数的模型,它不仅在同规模的开源模型中取得了最佳性能,甚至在多项基准测试中,正面挑战并超越了Google和OpenAI的闭源模型。
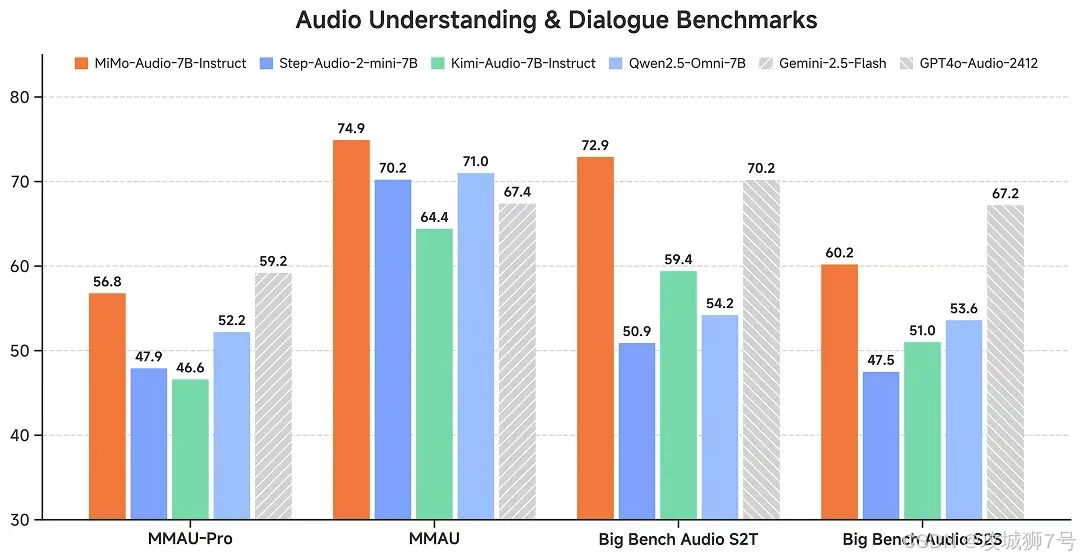
在音频理解基准MMAU的标准测试集上,MiMo-Audio超越了Google的Gemini-2.5-Flash。
在面向音频复杂推理的基准Big Bench Audio S2T任务中,MiMo-Audio超越了OpenAI的GPT-4o-Audio-Preview。
这一成绩打破了人们对于“开源模型性能不及闭源”的固有印象,证明了通过正确的路径,中等规模的开源模型同样可以达到世界顶尖水平。
三、不止是模型:开启语音领域的“LLaMA时刻”
如果说能力的“涌现”是MiMo-Audio的“GPT-3时刻”,那么其彻底的开源策略,则开启了语音领域的“LLaMA时刻”。小米此次开源的并非仅仅是模型权重,而是一整套完整的解决方案。
3.1 开源了什么?一个完整的工具箱
小米的开源清单堪称豪华:
(1)预训练模型 (MiMo-Audio-7B-Base):具备强大语音续写能力的基座模型。
(2)指令微调模型 (MiMo-Audio-7B-Instruct):为对话和任务优化,支持“思考”模式。
(3)Tokenizer模型:上文提到的1.2B参数音频编码器。
(4)技术报告:详细阐述模型和训练细节。
(5)评估框架 (MiMo-Audio-Eval):一套完整的评测体系,支持10余项评测任务。
3.2 这对开发者和行业意味着什么?
这种“全家桶”式的开源,将极大地降低语音AI技术的应用和研究门槛。
(1)对于中小企业和开发者:无需投入巨额成本从零开始训练,就能在一个世界级的基座模型上,快速开发出定制化的、具备高度拟人化交互能力的应用,比如智能客服、有声读物制作、AI口语陪练等。
(2)对于学术研究:提供了一个强大的、可复现的研究平台,将加速语音领域的强化学习(RL)和智能体(Agentic)训练等前沿探索。
四、从快板到哲学:一个能说会道、高情商的语音模型
抛开技术细节,MiMo-Audio在实际演示中展现出的能力,才最直观地体现了它的革命性。
它不再是一个只能执行简单指令的工具,而是一个可以“交流”的伙伴。它可以和你探讨西西弗斯的哲学故事,被打断后能迅速接上话茬;可以惟妙惟肖地模仿天津方言说一段快板,甚至还会给自己“找补”;可以化身英语陪练,不仅能纠正你的发音,还能讲解语法错误的原因。
这种高度的自然度、丰富的情感表达和强大的逻辑推理能力,预示着未来的人机交互将不再是冰冷的问答,而是有温度、有深度的对话。
结语:迈向真正的语音AGI
小米MiMo-Audio的开源,不仅仅是发布了一款强大的模型,更是为整个语音AI领域注入了前所未有的活力。它证明了通过大规模数据和正确的训练方法,语音模型同样可以实现能力的“涌现”,达到甚至超越闭源模型的水平。
更重要的是,其彻底的开源生态策略,为全球开发者提供了一把开启未来语音交互大门的钥匙。当技术门槛被夷平,创新的浪潮才会真正到来。这或许是我们迈向那个能听懂、会思考、有情感的语音通用人工智能(AG-I)的,最坚实的一步。
GitHub:https://github.com/XiaomiMiMo/MiMo-Audio
项目官网:https://xiaomimimo.github.io/MiMo-Audio-Demo
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!