【足式机器人算法】#2 奖励函数设计
前言
在足式机器人的强化学习框架中,奖励函数居于核心地位,它定义了什么是“好”的行为,是策略学习过程的根本驱动力。奖励函数的设计直接决定了强化学习算法在具体项目中的训练效果,也是足式机器人任务区别于其他强化学习任务的本质特征。
除此之外,观测与动作空间作为马尔可夫决策过程(MDP)的另外两个基本要素也与任务强相关,其设计逻辑较为直观,因此将在本文中简要概述。
观测与动作空间
观测
足式机器人的观测输入主要来自以下几个部分
- 本体感知:机器人的内部状态,如关节运动信息、基座运动信息等。
- 外部感知:环境信息,通常与机器人配备的传感器绑定,对复杂地形至关重要。例如由深度相机采集的深度图或处理得到的点云,也可与深度学习结合利用神经网络提取特征后输入。
- 任务相关输入:用户指令,如期望的前进速度、转向角速度等。
动作空间
足式机器人的动作空间根据表达的抽象程度可以划分为以下几个层级
- 低层级:关节扭矩
- 无需底层控制器,动作直接发送给电机。
- 中层级:关节速度/位置
- 由一个运行频率更高的底层控制器来驱动关节电机,使其快速达到目标速度/位置。
- 高层级:足端轨迹、步态参数
- 通过轨迹规划将参数转换为轨迹,通过逆运动学将轨迹转换为关节位置,再由底层控制器执行。
可想而知,表达的抽象程度的提高将产生如下影响
- 对机器人执行指令的能力要求提高,更加受限于机器人自身的运动模型。
- 机器人运动的灵活性降低。
- 动作空间维度和指令复杂度的降低让强化学习任务的训练变得更加简单。
因此,使用目标关节位置设计动作空间作为一种平衡了学习难度和灵活性的方法,是现今最为流行的方法。
奖励函数
下表来自论文Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning,采用了一个典型的、基础的足式机器人奖励函数构成,本文将以此为例展示足式机器人奖励函数的大致设计思路

注:在时间步与时间尺度相关的强化学习任务中,奖励权重会以时间步长为单位,以避免智能体在不同的物理仿真频率下的奖励积累差异,使训练更加稳定。
跟踪奖励
跟踪奖励衡量机器人的移动能力。
- 线速度跟踪:ϕ(vb,xy∗−vb,xy)\phi(\mathbf v^*_{b,xy}-\mathbf v_{b,xy})ϕ(vb,xy∗−vb,xy)
- 奖励机器人基座在XYXYXY平面的实际线速度跟踪指令线速度的表现,提升足式机器人的平移能力。
- 角速度跟踪:ϕ(ωb,z∗−ωb,z)\phi(\boldsymbol\omega^*_{b,z}-\boldsymbol\omega_{b,z})ϕ(ωb,z∗−ωb,z)
- 奖励机器人基座绕ZZZ轴旋转的实际角速度跟踪指令角速度的表现,提升足式机器人的转向能力。
其中ϕ(x)\phi(x)ϕ(x)函数将误差值xxx映射为奖励值,误差绝对值越小,奖励值越大
ϕ(x)=exp(−∣∣x∣∣20.25) \phi(x)=\exp(-\frac{||x||^2}{0.25}) ϕ(x)=exp(−0.25∣∣x∣∣2)
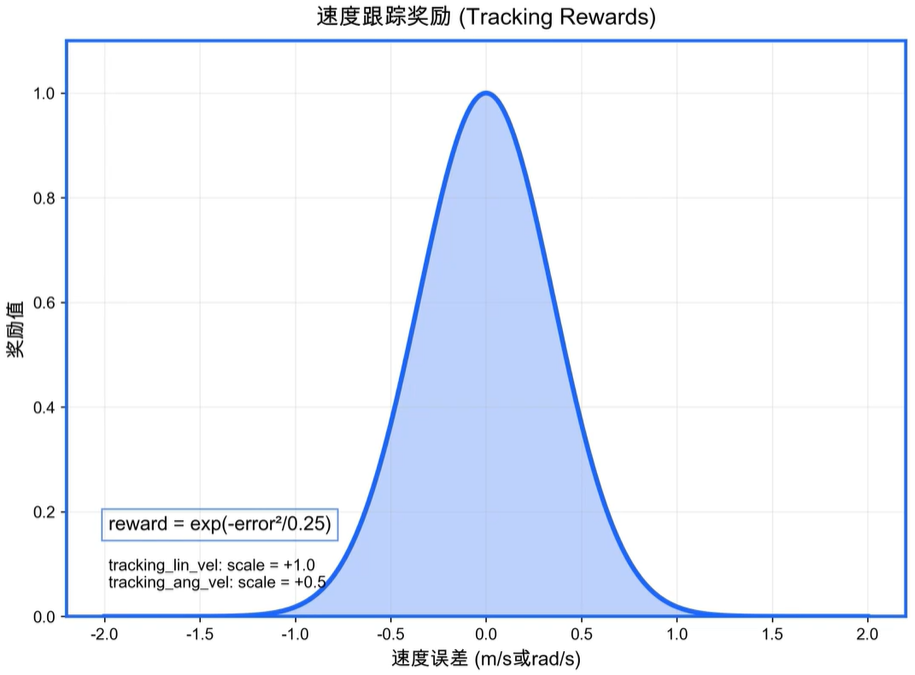
(奖励曲线配图不一定与论文实际计算方法相符,但可供参考)
稳定性奖励
稳定性奖励衡量机器人在移动过程中基座保持稳定的能力,抑制非必要的移动,因此其观测的速度量与跟踪奖励互补。
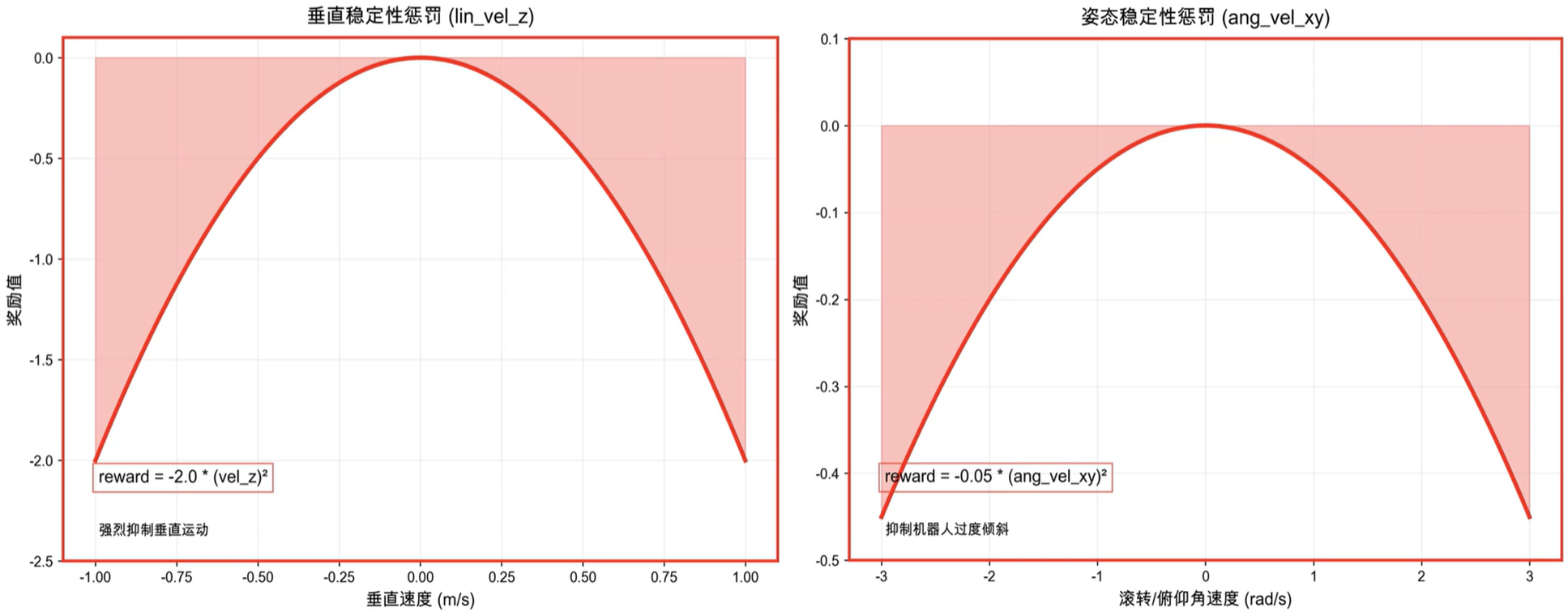
- 线速度惩罚:−vb,z2-\mathbf v_{b,z}^2−vb,z2
- 惩罚基座在ZZZ轴方向的线速度,保持基座高度稳定,抑制不必要的跳跃或下沉。
- 角速度惩罚:−∣∣ωb,xy∣∣2-||\boldsymbol\omega_{b,xy}||^2−∣∣ωb,xy∣∣2
- 惩罚基座绕XXX轴和YYY轴的角速度,保持基座姿态稳定,抑制侧翻与前后倾。
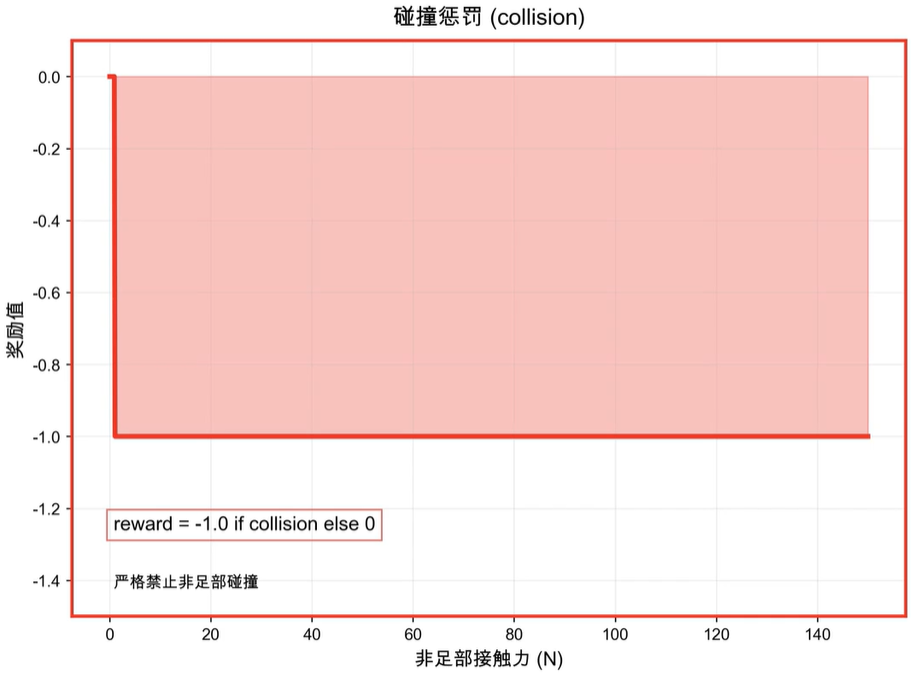
- 碰撞惩罚:−nc-n_c−nc
- 惩罚机器人非足端部分与环境的碰撞次数,保障硬件安全和运动合理性。
效率奖励
效率奖励衡量机器人的能量利用效率。
- 关节运动惩罚:−∣∣q¨j∣∣2−∣∣q˙j∣∣2-||\ddot{\mathbf q}_j||^2-||\dot{\mathbf q}_j||^2−∣∣q¨j∣∣2−∣∣q˙j∣∣2
- 惩罚关节速度与加速度,减少电机负荷,鼓励节能。
- 关节力矩惩罚:−∣∣τj∣∣2-||\boldsymbol\tau_j||^2−∣∣τj∣∣2
- 惩罚关节输出力矩,比关节运动惩罚更加直接。
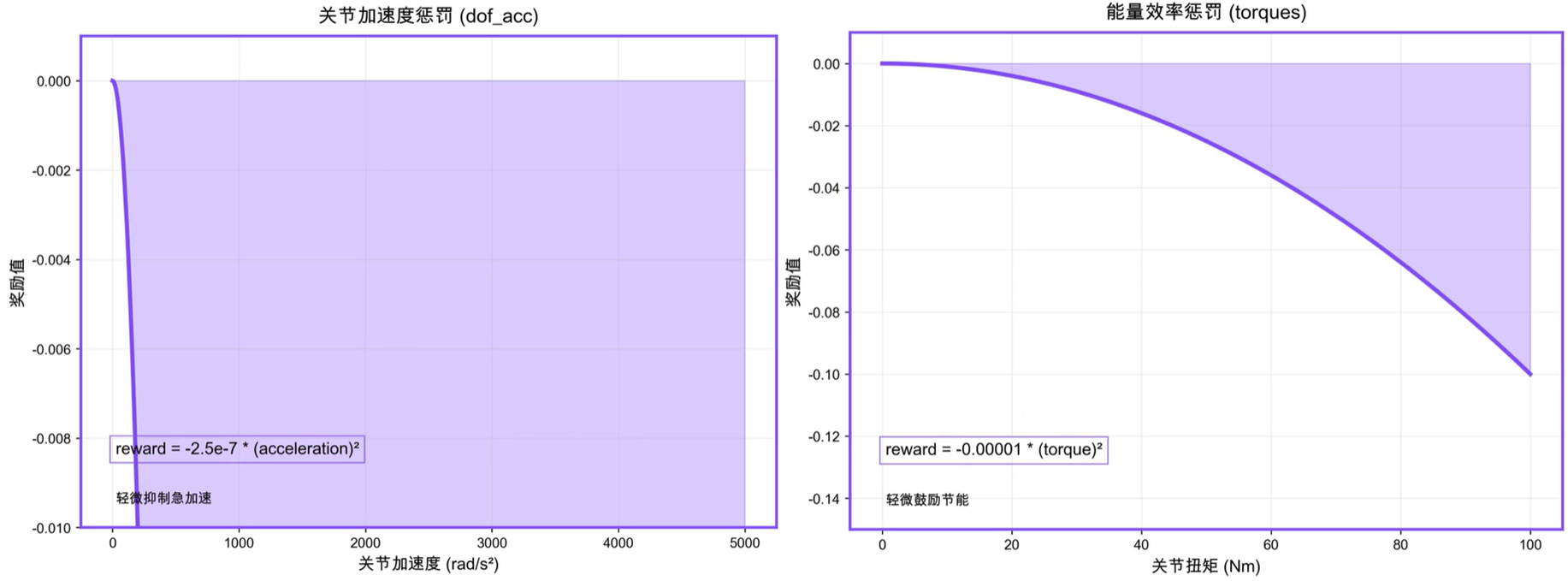
平滑度奖励
平滑度奖励衡量机器人的动作平滑度。
- 动作速率惩罚:−∣∣q˙∗∣∣2-||\dot{\mathbf q}^*||^2−∣∣q˙∗∣∣2
- 惩罚连续时间步之间动作的变化量,鼓励平滑运动,抑制抖动。动作即智能体策略采取的动作,由动作空间定义,论文中为关节速度。
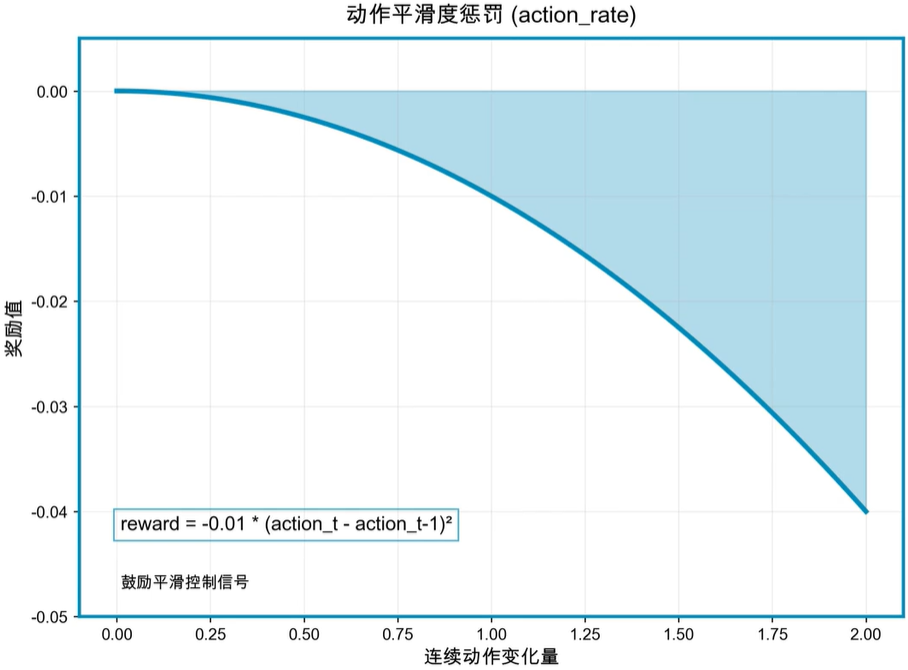
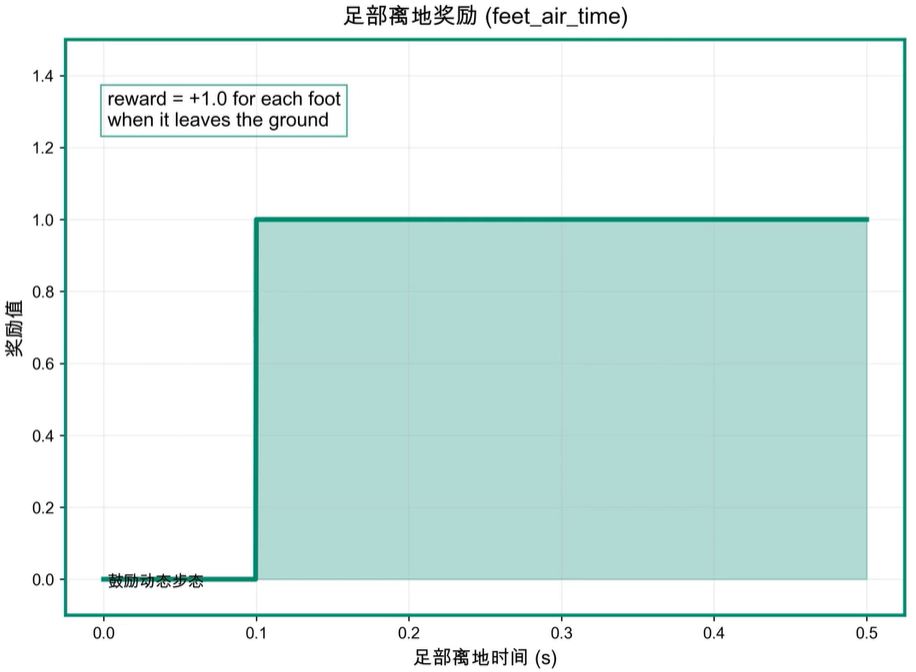
步态奖励
步态奖励衡量机器人的足端运动模式。
- 足端腾空时间奖励:∑f=04(tair,f−0.5)\displaystyle\sum^4_{f=0}(t_{air,f}-0.5)f=0∑4(tair,f−0.5)
- 奖励每个足端维持预期腾空时间(此处为0.5秒),鼓励规律、高效的步态,求和上限为机器人足端数量。
总结
论文中对该奖励函数的解释如下:
整体奖励函数为九个项的加权和。主导项用于鼓励机器人跟踪指令速度,同时抑制基座沿其他轴向的非期望运动。为促进运动平滑性与自然度,我们对关节力矩、关节加速度、连续动作指令间的变化以及碰撞事件予以惩罚。(注:碰撞定义为膝盖、小腿或足部与垂直表面的接触;若基座发生接触则判定为摔倒,并导致回合终止重置。)最后,引入一项额外奖励以鼓励更长的足端腾空时间,从而引导出步幅更大、视觉观感更优的步态。我们采用此统一奖励函数,在所有地形上训练了一个单一策略。
由此,我们根据该论文可以得到一个较为全面的足式机器人奖励函数基本框架,跟踪奖励直接对应任务的主要目标,而其他所有项为塑造出符合物理规律和工程需求的运动行为服务,决定了运动的质量。足式机器人的奖励函数具有灵活的设计空间,通过给出不同的评定标准、衡量公式、权重配置,可以达到不同的训练效果,实现多种多样的移动任务。