StarRocks:Connect Data Analytics with the World

作者:StarRocks TSC Member、镜舟科技 CTO——张友东
本文基于镜舟科技 CTO、StarRocks TSC 成员张友东在 StarRocks Connect 2025 活动上的主题分享整理而成。围绕大会的核心主题——“数据与世界的连接”,本文将从三个维度进行阐述:
过去:StarRocks 通过开源的力量,将全球的社区用户紧密联系在一起。
现在:StarRocks 正在推动数据与现代化数据分析应用的融合。
未来:StarRocks 将进一步探索数据分析与 AI Agent 的结合。
连接世界(过去)
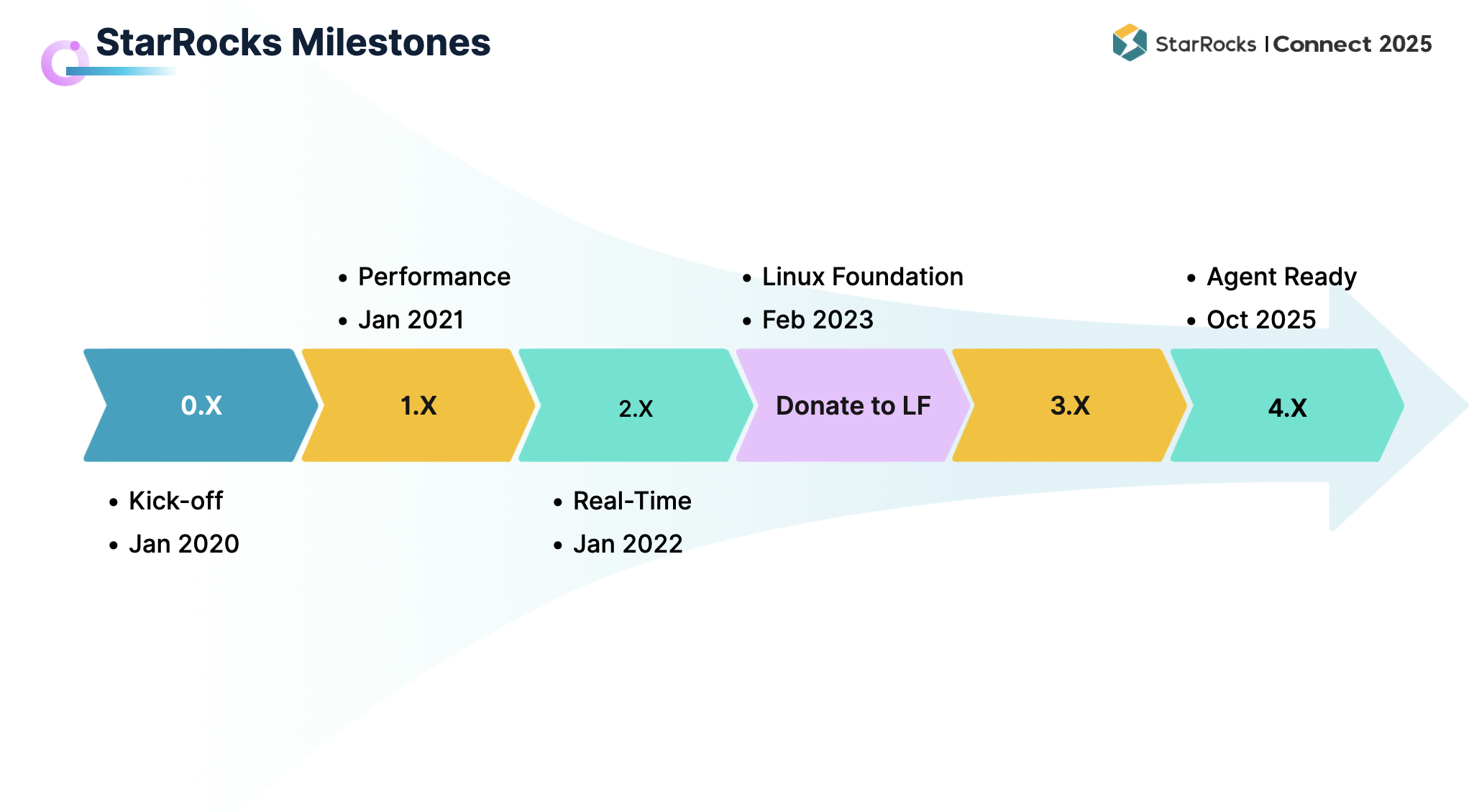
在过去五年中,StarRocks 始终保持着快速迭代。今年 10 月,StarRocks 即将发布 4.0 版本,至此已经完成了从 1.0 到 4.0 的四次重要升级。
-
1.0 于 2021 年发布。凭借强大的性能,StarRocks 让众多社区用户认识并开始使用。
这 -
2.0 于 2022 年发布, 以“新一代实时分析引擎”的定位逐渐被用户广泛接受,在实时能力方面持续增强,帮助用户更好地支撑实时业务洞察。
-
3.0 于 2023 年 4 月发布,标志着 StarRocks 架构由存算一体向存算分离的升级,并显著提升了湖仓分析能力。
-
全球化发展方面,2023 年 StarRocks 项目正式捐赠给 Linux 基金会。该基金会汇聚了包括 Linux、Kubernetes 在内的重量级开源项目,如今 StarRocks 也成为其中一员。
-
4.0 将于 2025 年 10 月推出,在 AI Agent 方向实现更多突破。

过去几年,StarRocks 得到了全球众多知名企业的广泛采用。仅我们直接接触到的,就有超过 500 家估值 10 亿美元以上的公司在使用 StarRocks,而在更广阔的开源社区中,实际用户数量远超这一数字。
目前,StarRocks 的应用已经遍布全球:
-
亚洲:在中国,各行各业的头部企业几乎都在尝试使用 StarRocks 来加速业务,历届 Summit 上的“Logo 墙”便是最直观的见证。在东南亚,新加坡、马来西亚的代表性企业包括电商平台 Shopee、本地生活服务商 Grab,以及跨境电商巨头 SHEIN,均已选择 StarRocks。在日韩,韩国知名搜索引擎 NAVER、金融支付公司 Toss 也在生产环境中使用 StarRocks;此外,在印度、菲律宾等国家,StarRocks 也在快速拓展。
-
北美:StarRocks 在多个行业的领先企业中得到应用。金融与财税领域的 Intuit、电信巨头 Verizon、Web3 领域的 Coinbase、兴趣社交平台 Pinterest、科技巨头 Microsoft、体育电商平台 Fanatics、旅游巨头 Expedia 等,都已在不同业务场景中使用 StarRocks。
-
欧洲:流程挖掘领军企业 Celonis、游戏公司 InnoGames、本地生活 SaaS 企业 Fresha 等,也在其业务中部署了 StarRocks。
可以说,StarRocks 已经逐步实现了全球范围的覆盖。展望未来,我们相信,StarRocks 将会像 Oracle、MySQL、PostgreSQL 一样,成为数据分析领域耳熟能详的名字,并成为更多企业的首选。
连接现代数据分析(现在)
现代数据分析的挑战
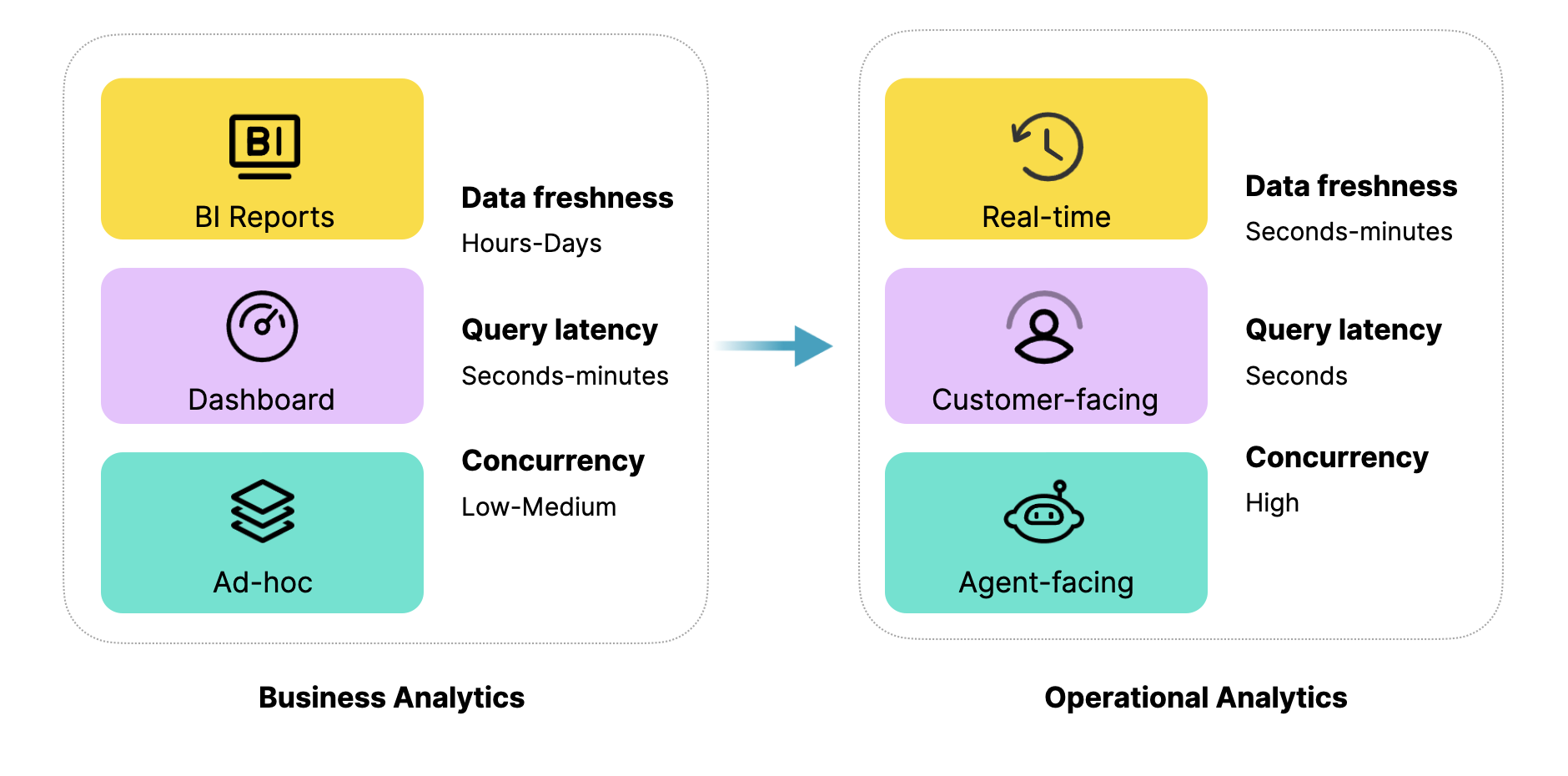
当前的数据分析应用正面临新的挑战。从场景演进的角度来看,现代化数据分析正在从 Business Analytics 向 Operational Analytics 拓展。
-
Business Analytics:主要面向企业的战略层面,强调公司级的大指标对齐和战略分析。例如报表、Dashboard,以及分析师通过 Ad-hoc 查询来判断业务上涨或下降的原因。
-
Operational Analytics:强调数据分析在战略落地过程中的战术支撑。其核心价值在于通过实时的分析洞察和针对客户的应用场景,为具体的运营动作提供指导。未来,随着 AI Agent 的兴起,这类场景还将进一步扩展。
在这两类场景中,对数据分析的要求存在显著差异。以常见的几个核心维度为例:数据新鲜度、查询延时、查询并发。在 Operational Analytics 中,这些要求远高于传统的 Business Analytics。例如,数据新鲜度需要达到秒级或分钟级的实时;面向客户的查询延时必须控制在秒级以内;而在面向 Agent 的场景下,查询并发量更是成倍提升。因此,新的运营分析场景对数据系统提出了前所未有的挑战。
速度优先,治理缺失
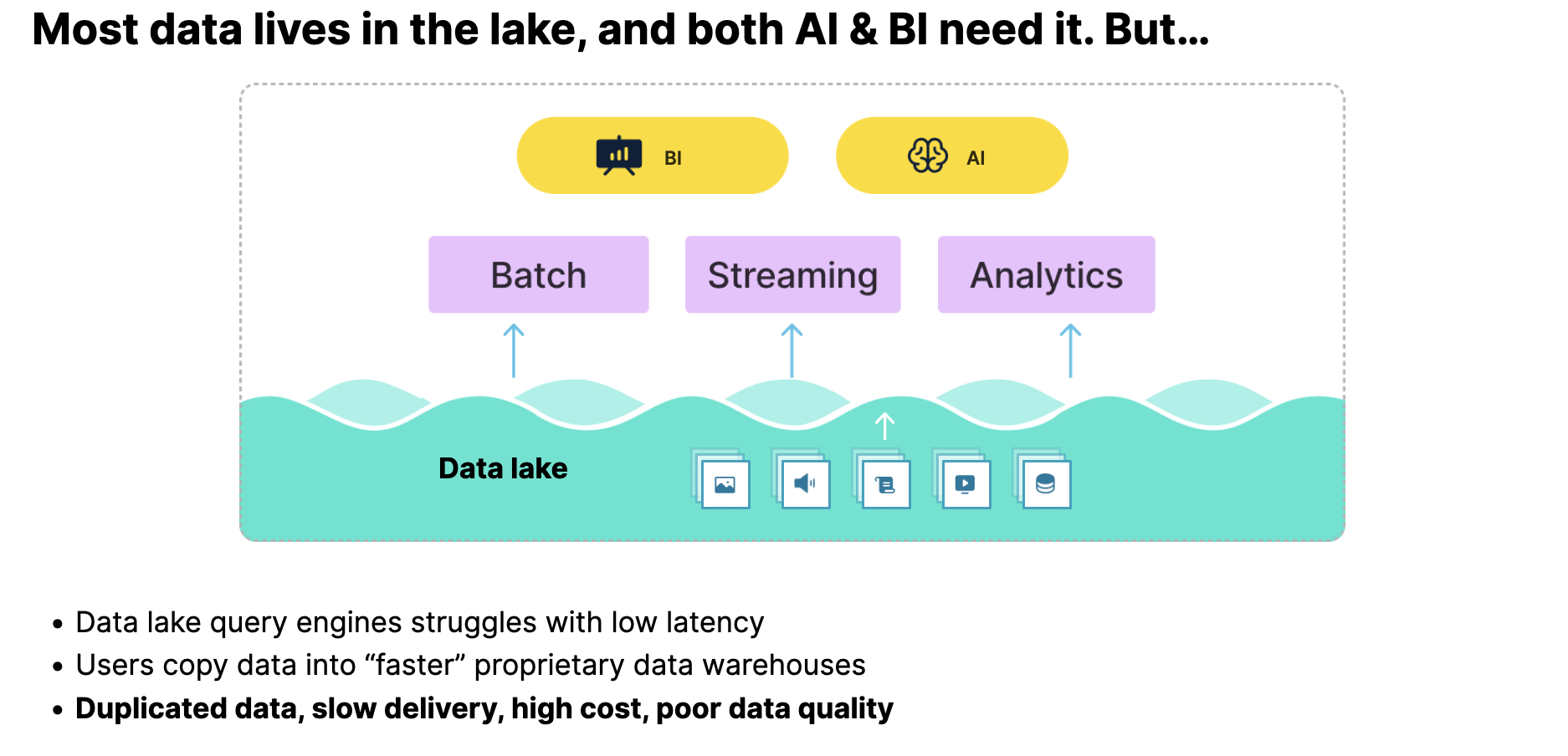
面对当前的挑战,Lakehouse 已成为数据分析架构发展的主要趋势。StarRocks 早在几年前便持续推动 Lakehouse 在国内的发展,并不断分享相关实践。如果在过去,仍有人对这一趋势持怀疑态度,那么经过近几年的行业巨变,Lakehouse 已逐渐被证明是数据分析的未来基础。如今,大多数企业正在建设 Lakehouse,使数据能够在 Data Lake 中统一存储,并同时支持 AI 和 BI 场景的使用。
然而,理想与现实之间仍存在差距。当前,直接在 Data Lake 上进行分析,许多引擎都会面临查询性能不足的问题。为弥补性能与实时性,企业往往选择将 Lake 上的数据再导入专用数据仓库(如 ClickHouse 等)进行处理。这种方式导致架构呈现“烟囱式”特征,即为每个业务场景单独构建一套底层数据系统。
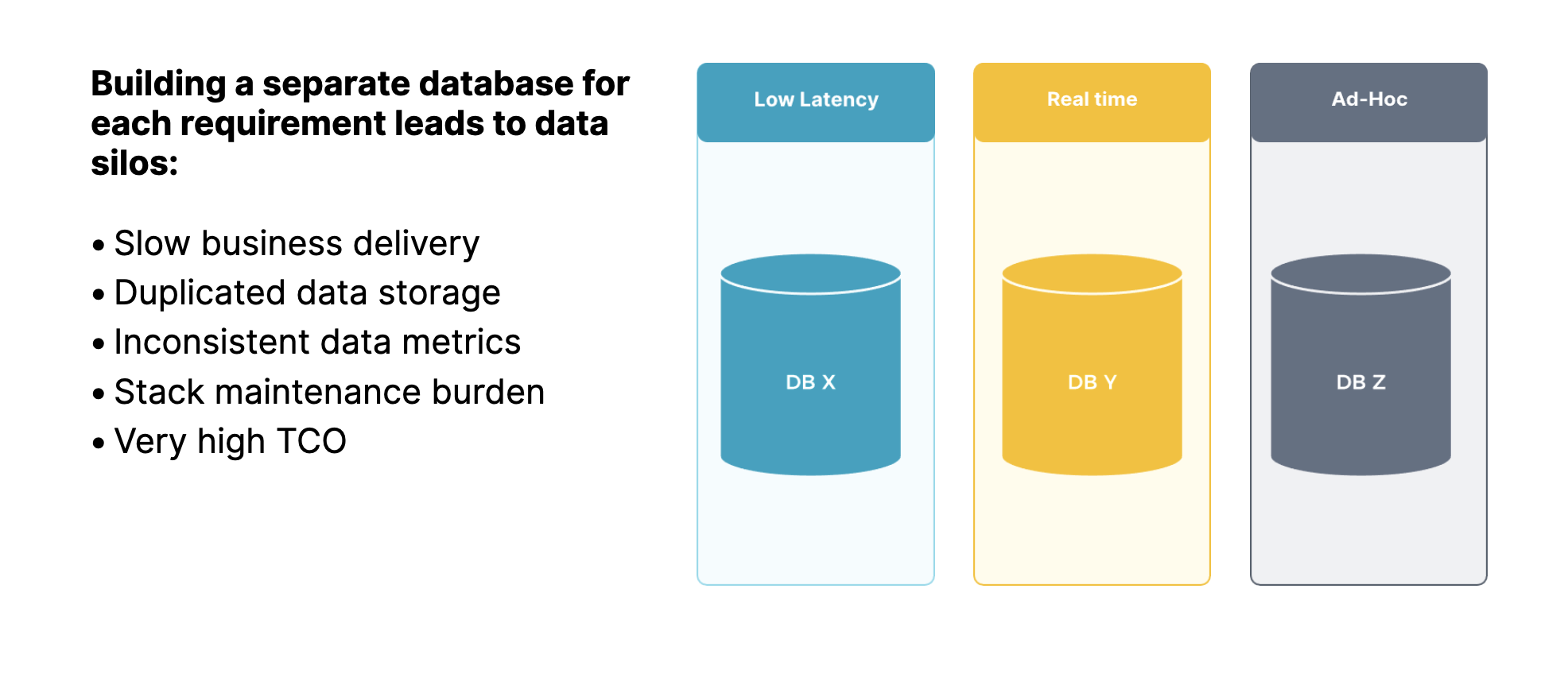
烟囱式架构的问题十分突出:
-
重复开发:不同场景需要独立建设,业务交付效率低。
-
数据冗余:同一份数据被多次存储,占用大量资源。
-
口径不一致:数据分散在多个系统,导致指标口径不一致。
-
运维复杂:多套系统并行运行,整体运维与运营成本高企。
正是为了解决这些痛点,StarRocks 应运而生。
面向现代分析的统一引擎
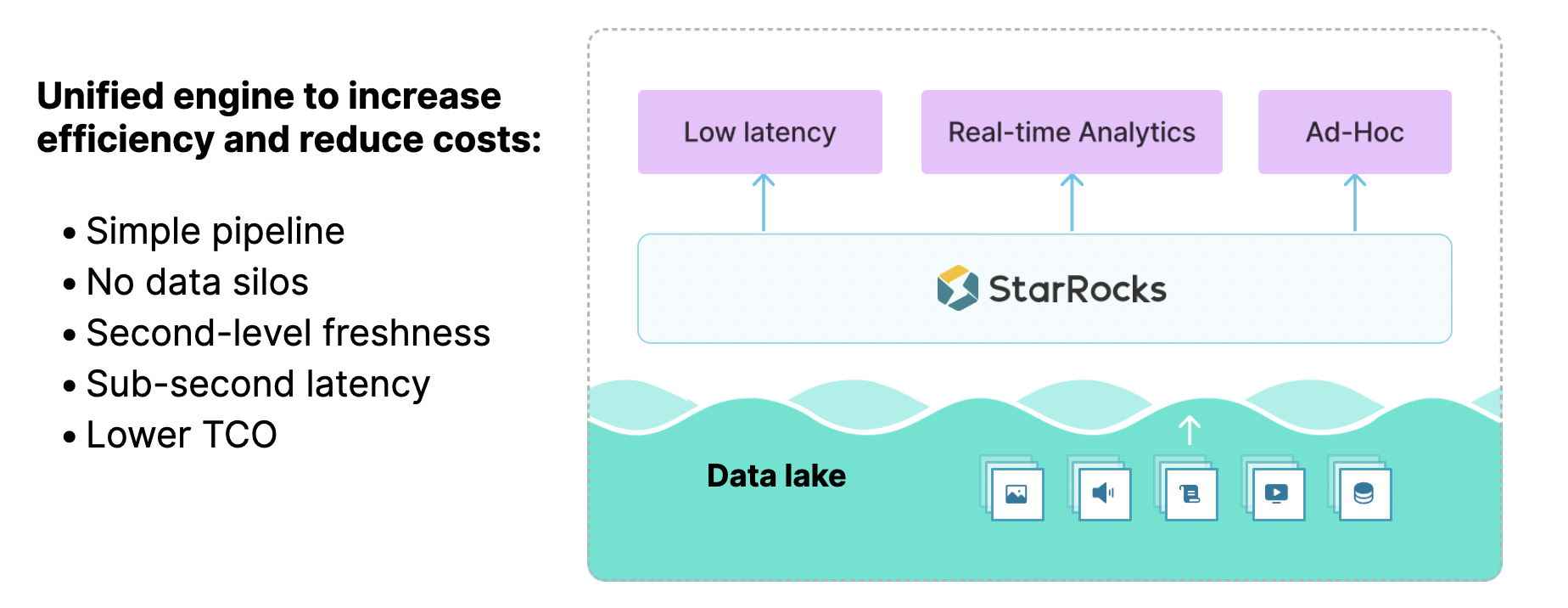
StarRocks 致力于成为统一的分析引擎,使数据在湖上即可支撑实时与离线的多样化场景。这样的统一带来诸多价值:
-
架构简化:技术栈与数据管道得到显著简化,避免了“数据烟囱”的割裂问题。
-
性能提升:依托 StarRocks 强大的引擎能力,能够为业务提供秒级的数据新鲜度和亚秒级的查询性能。
-
成本优化:整体架构的构建成本与业务交付效率,均较以往基于烟囱式架构有显著改善。
当然,实现这一理想并非易事。StarRocks 之所以能够承担统一引擎的角色,源于其在多个关键能力上的持续突破,包括实时分析、查询性能以及湖仓分析。
实时洞察与成本效益并行
先来看实时分析。这里需要特别强调的是——必须具备高性价比的实时分析能力。StarRocks 在 2.0 版本基于存算一体架构,已经具备了强大的实时分析性能,并在社区中积累了大量应用案例。然而,如果进一步要求在保证实时性的同时兼顾性价比,则需要在架构上做出更多优化。
因此,在 3.0 版本中,StarRocks 完成了从存算一体到存算分离的架构升级。当前,基于存算分离架构的用户规模正在快速增长。
存算分离的优势主要体现在三个方面(如下图所示):
-
更低的存储成本:通过对象存储,显著降低整体存储开销。
-
计算弹性:计算与存储解耦,可根据业务需求实现弹性扩展。
-
多仓隔离:数据共享的同时,不同 workload 可通过 Multi-warehouse 能力实现独立隔离。
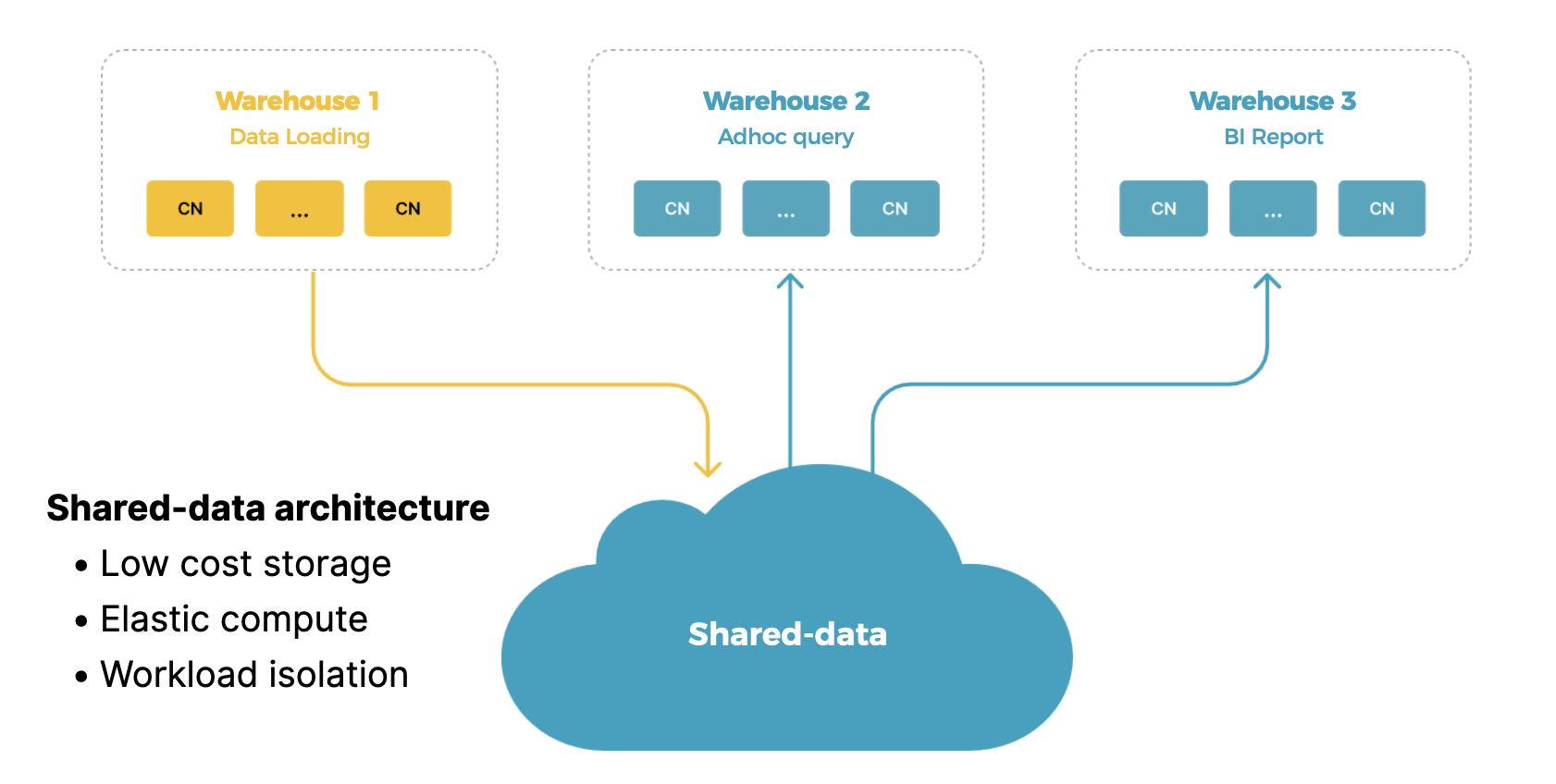
在存算一体架构下,StarRocks 已经在实时分析方面积累了大量经验。但在存算分离架构下,如何同时保证实时分析能力与低成本,这在业界也是一个很大的挑战。
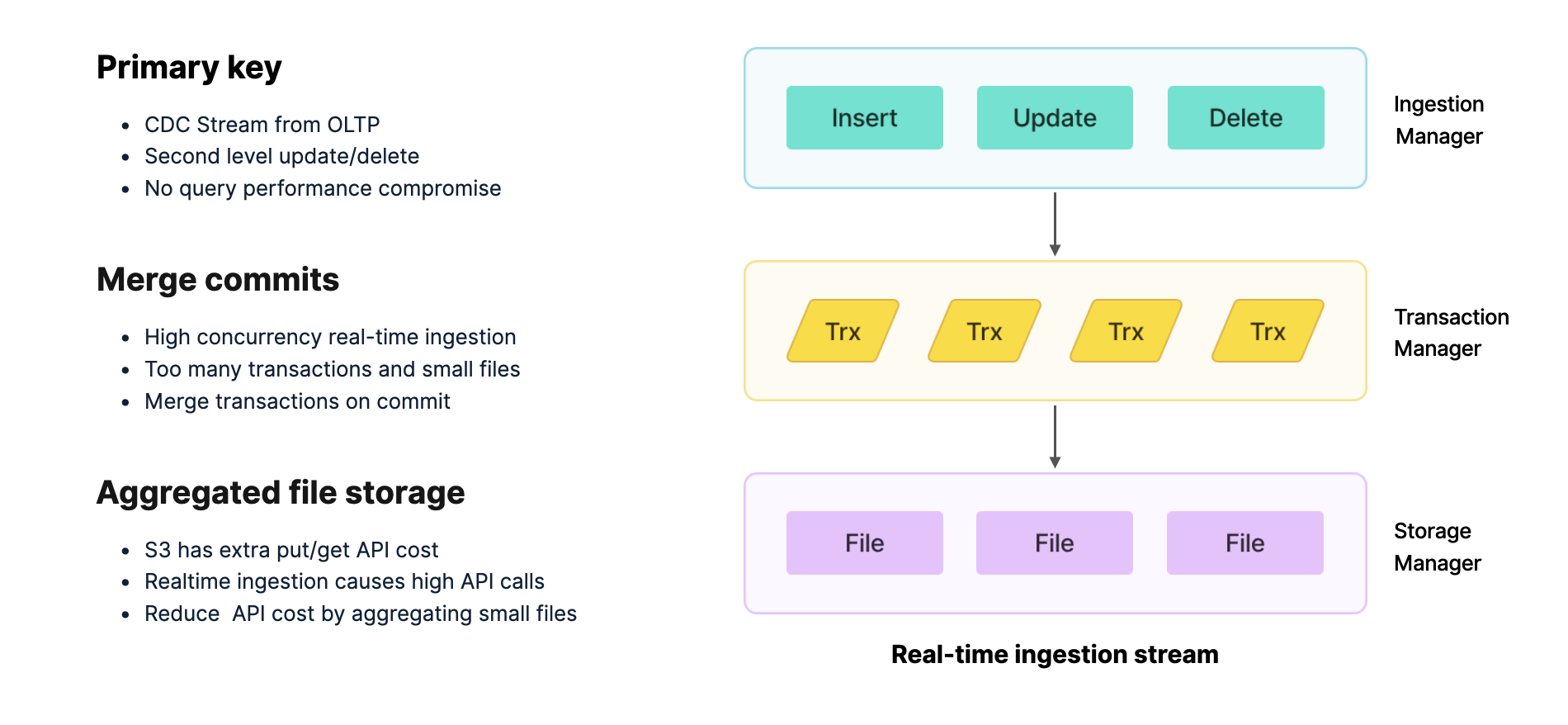
在存算分离架构下,StarRocks 针对实时分析的数据写入链路进行了深入优化。从最上层的 Pipeline 集成(支持 Insert、Update、Delete),到请求接收、事务管理,再到底层存储的全过程,每一环节都面临实时场景的挑战。
-
实时分析的主要数据流来自上游 OLTP 数据库,涉及 Insert、Update、Delete 操作。StarRocks 在内核层面通过组件化模型,能够直接支持 CDC 流式数据同步,将 OLTP 的变更无缝导入。
-
实时场景往往伴随高并发写入,这会给引擎带来巨大压力。为此,StarRocks 采用 Merge Commits 机制,在事务提交时对小事务进行合并,从而降低系统开销并提升整体写入性能。
-
在存算分离架构中,数据存储依赖 S3 对象存储。对象存储在频繁读写时会产生额外的 API 调用成本。StarRocks 的优化策略是将大量小的事务文件、日志文件与数据文件合并后再提交,从而减少 API 调用次数,显著降低存储成本。
自 3.0 版本发布以来,已有大量用户从存算一体升级至存算分离架构,并在成本上获得了显著优化。随着上述机制的持续演进,实时分析的成本优势将进一步扩大。
极速查询,持续突破
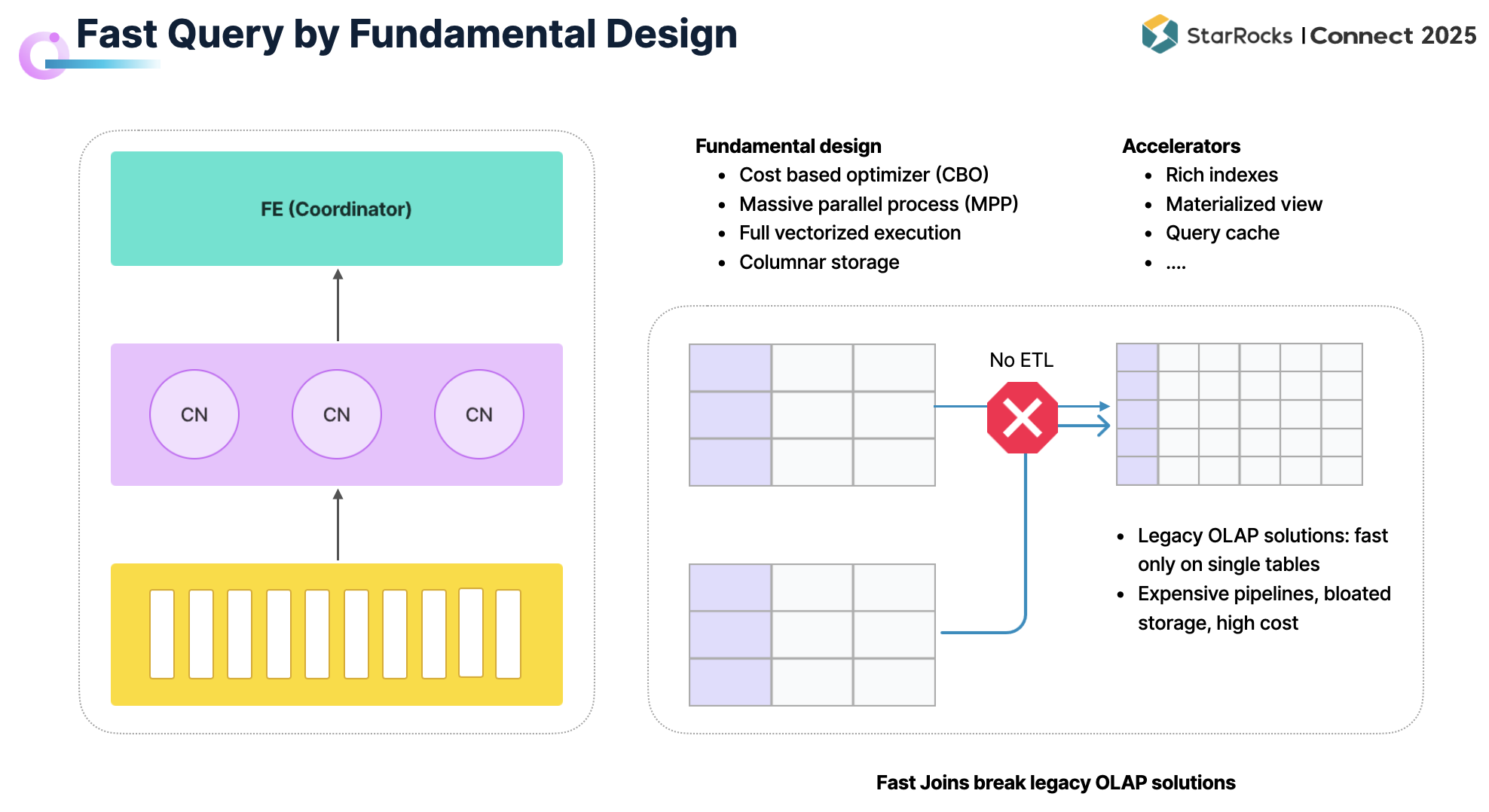
在众多应用场景中,查询延时往往是最核心的指标之一。StarRocks 之所以能够在查询性能上保持优势,主要体现在以下三个方面:
-
StarRocks 从设计之初便面向高速查询进行优化。自底层到执行层,形成了完整的性能支撑链路:包括基于 CBO 的优化器、分布式 MPP 架构、全面向量化的执行引擎,以及高效的列式存储。
在此基础上,StarRocks 提供了丰富的加速机制:从 Bloom Filter、Bitmap 等索引,到最新引入的文本索引与向量索引,以适配不同场景需求;透明物化视图可在通用场景下显著提升查询效率;再加上 Query Cache 等技术手段,使得 StarRocks 能够持续保障低延时的查询性能。
值得一提的是,StarRocks 天生对多表 Join 进行了优化,能够在复杂查询中保持高效。这大幅降低了数据工程师的建模负担,不再需要通过构建大宽表来规避 Join,避免了由此带来的数据膨胀与存储成本增加。
-
仅有坚实的设计基础还不够,StarRocks 在过去几年中持续进行性能优化,确保查询能力不断提升。
-
在优化器层面:通过 Join Reorder、表达式下推,以及针对数据热点和分布不均情况的优化策略,显著提升了查询效率。
-
在执行层面:通过改进 Shuffle 策略、引入 Runtime Filter 等机制,使执行调度更加高效,从而进一步增强执行性能。
这些优化累计已达数百项,使得 StarRocks 在查询性能上持续进步。以 TPC-DS 1TB 测试为例,从 2.0 到 3.0,再到即将发布的 4.0,StarRocks 的性能指标一直保持稳定提升。
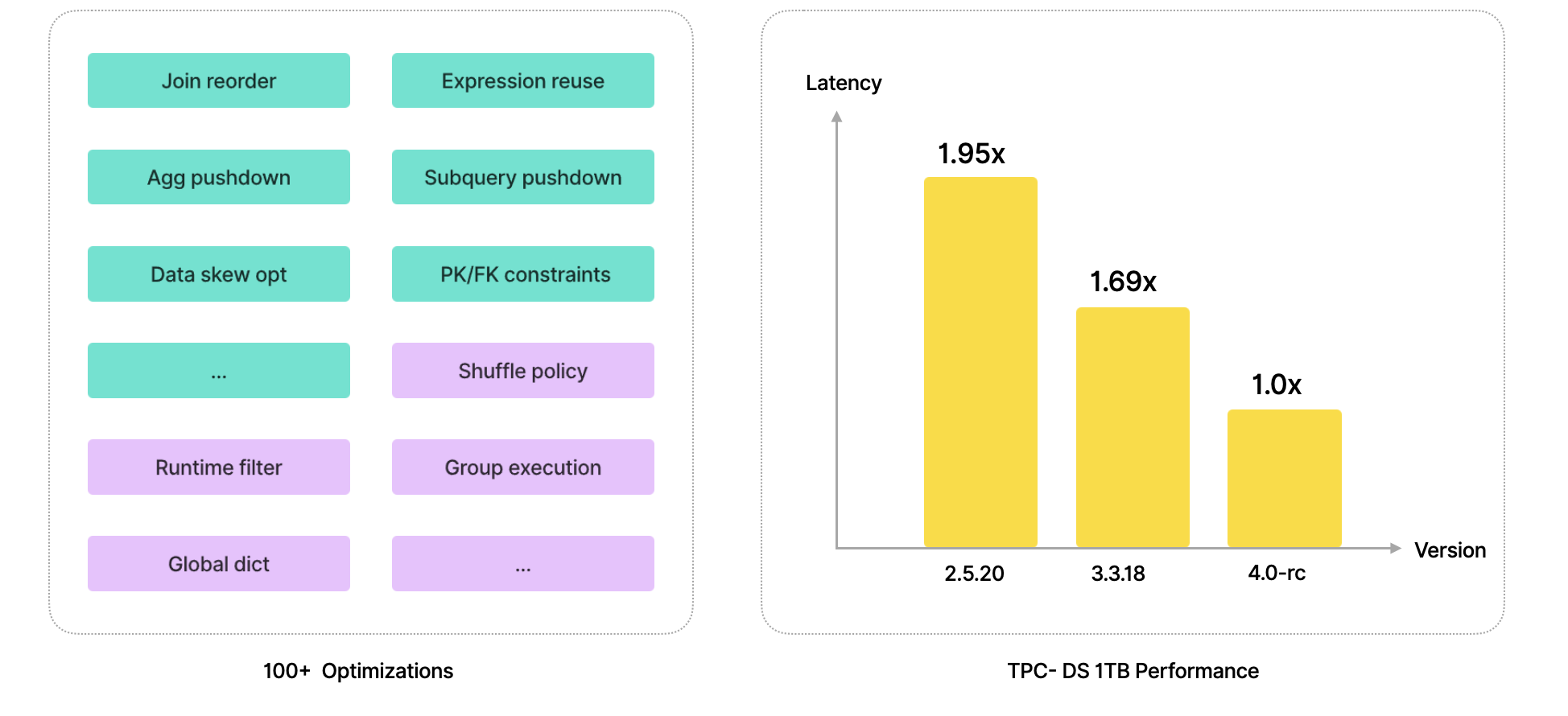
-
有了坚实的基础与持续迭代,数据库产品仍不能仅停留在 Benchmark 的成绩上,更关键的是要在真实业务场景中同样展现稳定而优异的表现。
在真实场景下,StarRocks 面临的挑战与 Benchmark 存在显著差异:
-
数据类型:Benchmark 多为结构化数据,而在实际业务中,半结构化数据更加普遍。
-
数据状态:Benchmark 通常基于静态数据集,而真实场景中的数据则在持续变化。
-
系统环境:Benchmark 默认节点稳定,而在生产环境中,节点升降级、重启、甚至 crash 都是常态。
正是面向这些差异化挑战,StarRocks 才能在真实业务链路中(从数据集成到数据分析)持续保证稳定的查询性能。
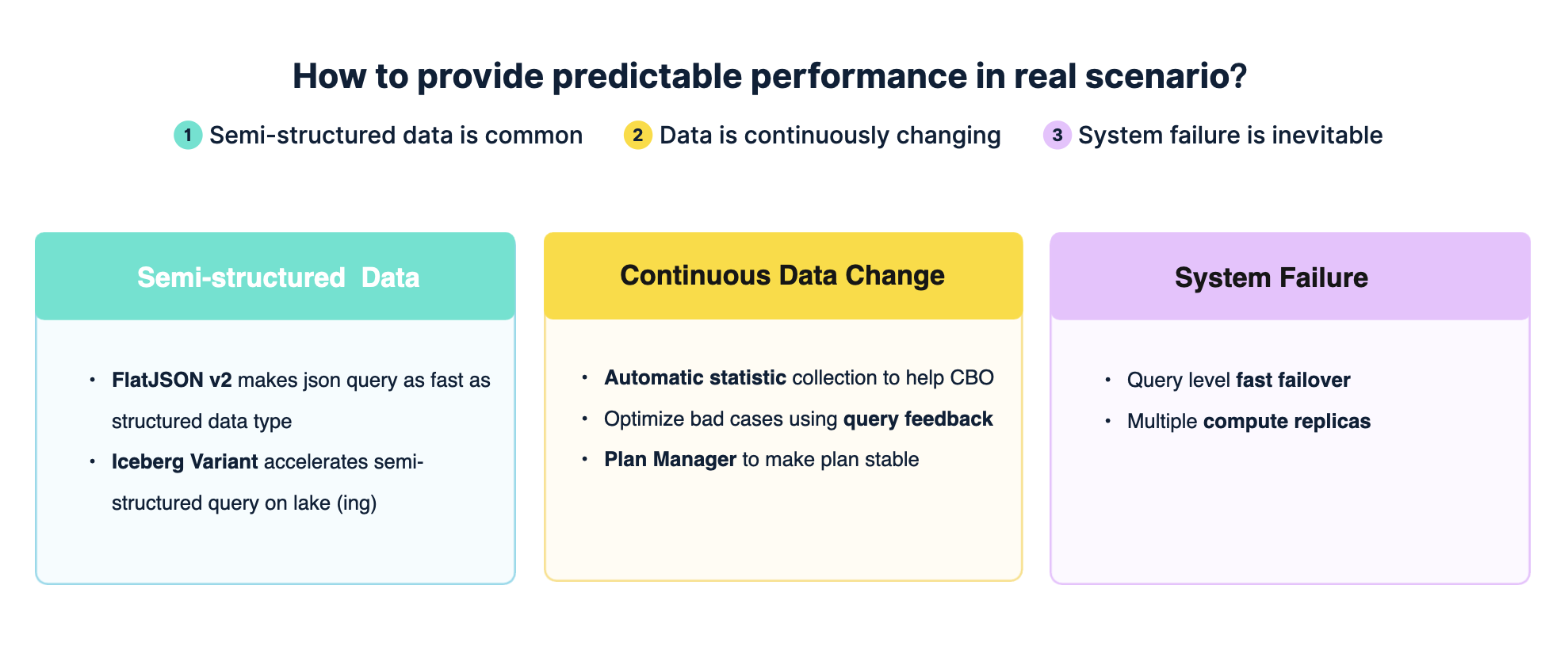
那么,StarRocks 如何在真实场景下同样保持高效与稳定的查询性能呢?主要体现在以下几个方面:
-
半结构化数据支持,StarRocks 原生引擎已支持 FlatJSON 功能,可以自动将 FlatJSON 数据“斩平”,在半结构化数据的分析性能上实现超过 10 倍的提升。该能力自 3.0 版本引入后,在 4.0 中已迭代至第二代(V2),性能进一步优化。对于存储在数据湖中的数据,当前 Iceberg 社区已在 Parquet 上提出 Variant 标准来支持半结构化数据,StarRocks 也在持续增强对 Variant 查询的能力。
-
在实际场景中,数据往往处于不断变化之中。为此,StarRocks 提供多层机制:
-
自动收集数据变化后的最新统计信息,以帮助 CBO 做出更优的执行决策。但考虑到实时收集的成本,仍可能存在部分性能不佳的查询情况。
-
Query Feedback:通过查询反馈机制,在执行完成后分析计划是否合理,如不合理则进行调整,逐步优化查询效果。
-
Plan Manager:通过计划管理器将查询与执行计划绑定,即使在数据变化、节点升降级等情况下,也能保持查询计划稳定,从而保障性能的一致性。
-
系统故障:在真实生产环境中,版本升级、节点重启、弹性扩容等情况时常发生。针对这些挑战,StarRocks 借助存算分离架构,配合快速 Failover 机制,一旦检测到节点故障,即可迅速完成任务调度,由其他节点接管,最大限度地减少对业务的影响。
此外,StarRocks 还支持多计算副本机制。当某一计算副本出现故障时,其他副本能够立即接管服务,从而进一步提升系统在故障场景下的稳定性与可靠性。
Lakehouse 架构下的极速价值交付
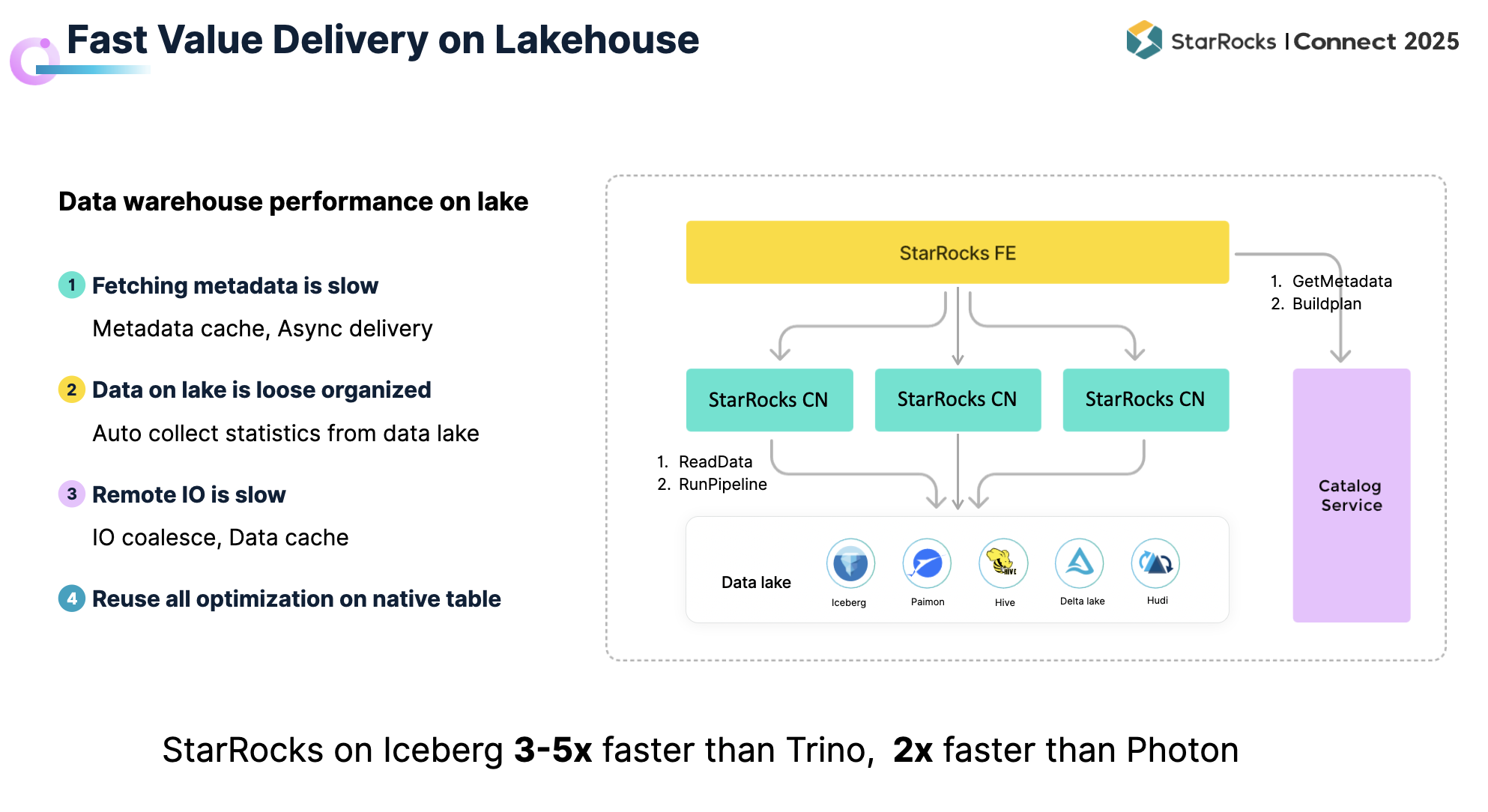
前文已从架构基础、持续迭代以及真实场景等角度阐述了 StarRocks 在高性能查询上的优化。结合 Lakehouse 的发展趋势,越来越多的数据被统一存储在数据湖中。此时,新的问题出现了:StarRocks 能否将其强大的分析引擎能力应用于湖上数据? 答案是肯定的。过去几年中,StarRocks 持续优化湖上数据的分析性能,使用户能够在数据湖中直接完成分析并快速交付价值。
然而,与本地表相比,数据湖场景也带来了一些独特挑战:
-
元数据存储在远端,访问延时较高。
-
数据组织松散:大量入湖数据缺乏良好组织,数据质量参差不齐,统计信息不足。
-
I/O 链路较长:从湖中读取数据的过程远比本地复杂,性能压力显著。
针对这些问题,StarRocks 采取了多方面的优化措施:
-
在元数据访问方面,引入缓存机制以加速获取,同时在获取元数据的过程中即可启动调度,将任务下发至计算节点,从而减轻调度节点压力并加快整体执行速度。
-
在数据组织与统计信息方面,StarRocks 支持在数据湖上自动收集统计信息,供 CBO参考,从而生成更优的执行计划。
-
在 I/O 层面,StarRocks 通过相邻 I/O 合并机制以及 Data Cache,大幅减少 I/O 次数和延时。借助这些优化,StarRocks 在数据湖上的分析性能已接近 Native Table 的水平。
与其他湖仓引擎相比,StarRocks 在 Iceberg 上的查询性能约为 Trino 的 3–5 倍,是 Photon 的两倍以上,能够满足绝大多数数据湖分析场景的需求。
然而,数据湖不仅涉及查询,更是未来的整体趋势。当前,许多大型企业已在积极推进数据湖建设,但对于中型和小型企业而言,构建数据湖仍存在显著挑战:需要搭建完整的 Pipeline,还要承担数据写入与治理的复杂工作,其门槛远高于使用 StarRocks Native Table。
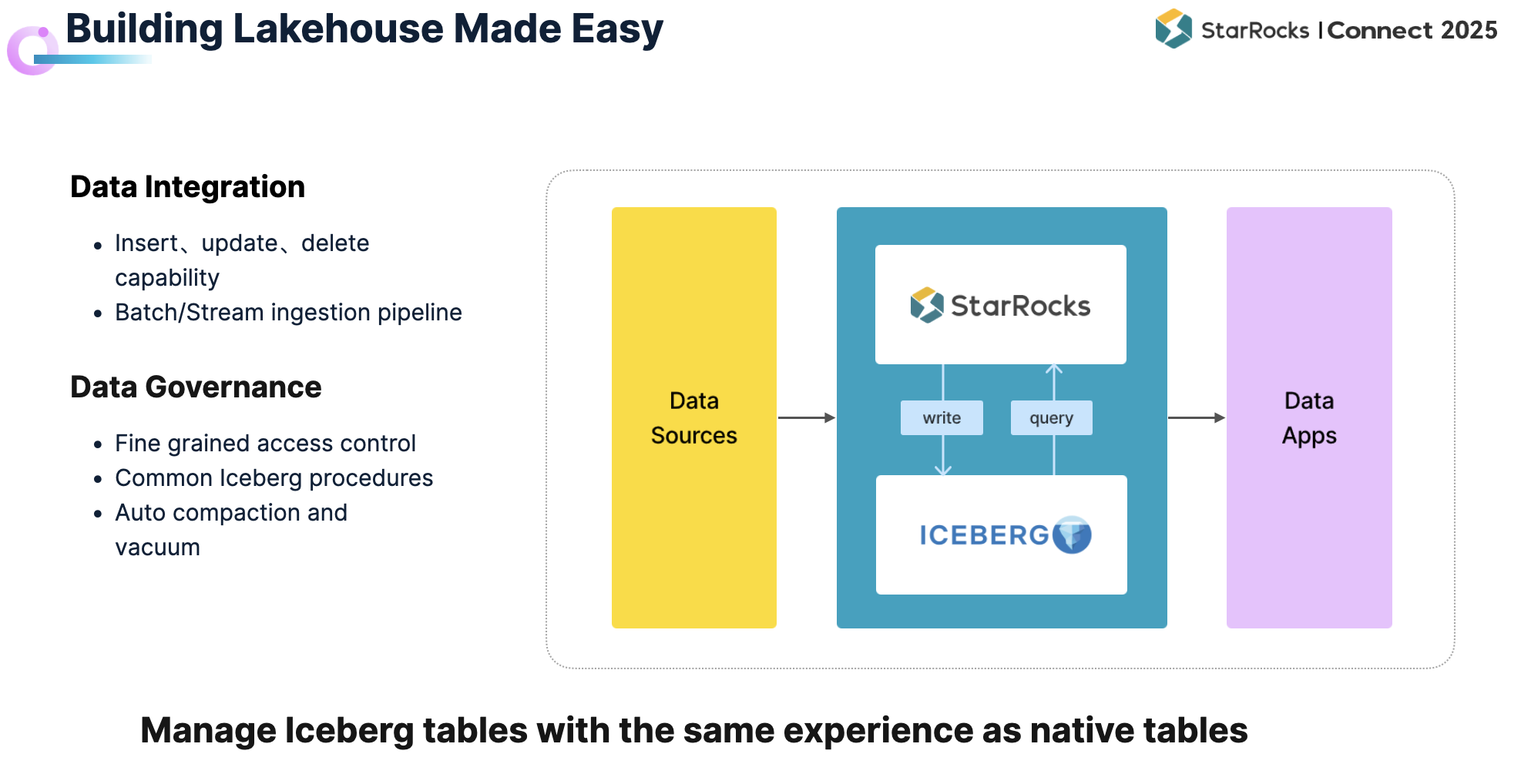
为此,StarRocks 正在持续提升数据湖构建能力,主要体现在以下两个方面:
-
数据集成
-
支持在数据湖上直接对 Iceberg Format 执行 Insert、Update、Delete 操作。
-
打通批流一体的写入链路,支持从对象存储和 Kafka 流直接导入数据至 Iceberg,大幅简化数据接入流程。
-
数据治理
-
提供统一的访问控制,规范谁可以访问数据湖中的数据及其方式。
-
针对 Iceberg 数据提供一系列治理能力,以提升数据质量和查询效率。
-
在治理的基础上进一步实现自动化,让用户无需手动维护,便可像使用 StarRocks Native Table 一样,将数据直接导入并服务于线上业务。
Pinterest: 基于 StarRocks 存算分离的实时洞察
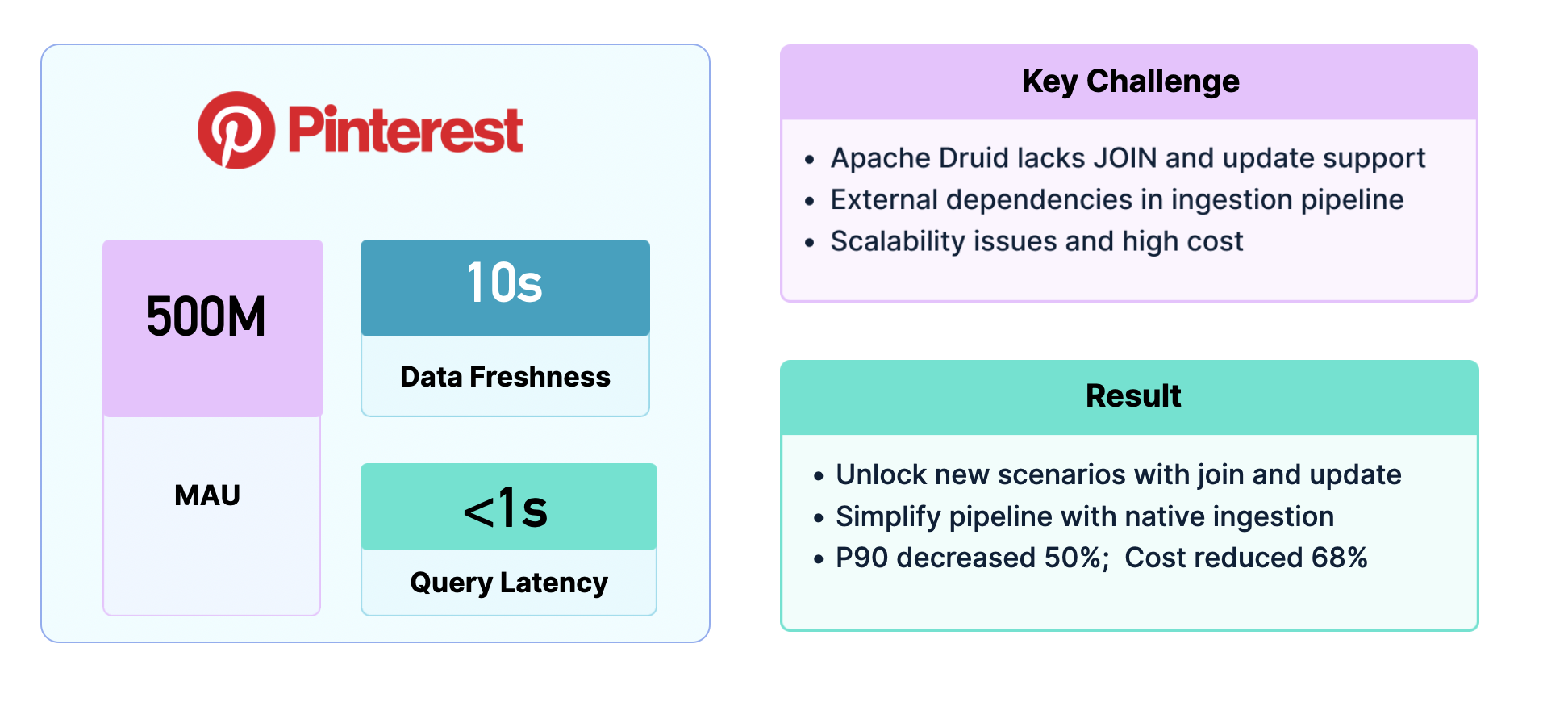
北美兴趣社交的领军企业 Pinterest,其广告平台面临极高的实时分析挑战:月活跃用户超过 5 亿,对数据新鲜度要求需在 10 秒以内,查询延时则需小于 1 秒。此前,Pinterest 使用 Druid,但由于在多表 Join 与 Update 支持上的限制,不得不依赖复杂的 Pipeline 构建大宽表,既增加了开发复杂度,也带来了稳定性和高成本的问题。
升级至 StarRocks 后,Pinterest 的广告平台效率显著提升:借助实时更新与多表 Join 能力,数据可直接导入并分析,无需复杂的 Pipeline。实际效果显示,P90 延时下降 50%,计算与存储成本降低 68%,整体运行成本仅为原来的三分之一。
Fanatics: Iceberg x StarRocks
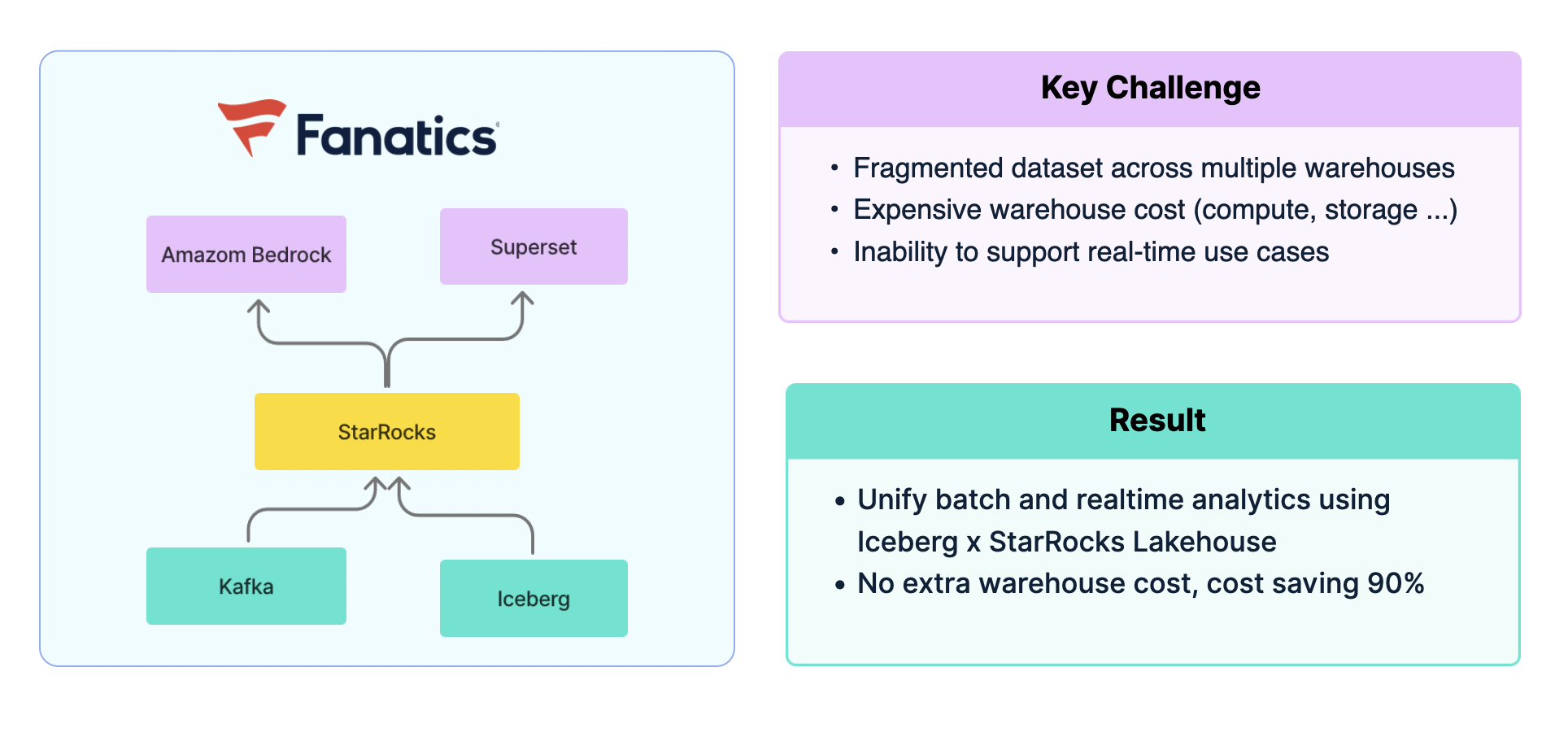
北美知名体育电商平台 Fanatics,其数据全部统一存储在 Iceberg 中。但在分析时,需要将数据导入 Redshift、Flink、Druid 等不同系统以支撑各类场景。这种方式不仅造成数据孤岛,难以关联,还带来了高昂的计算与存储成本,且难以满足实时分析需求。
引入 StarRocks 后,Fanatics 构建了统一的湖仓架构:Iceberg 数据在离线场景中可由 StarRocks 直接查询,实时数据则通过 Kafka 导入 StarRocks 即刻分析,并能在同一引擎中实现跨场景关联,支持 BI 与 AI 应用。最终,Fanatics 成功统一了公司数据平台的技术栈,整体成本下降 90%。
淘宝闪购: Paimon x StarRocks
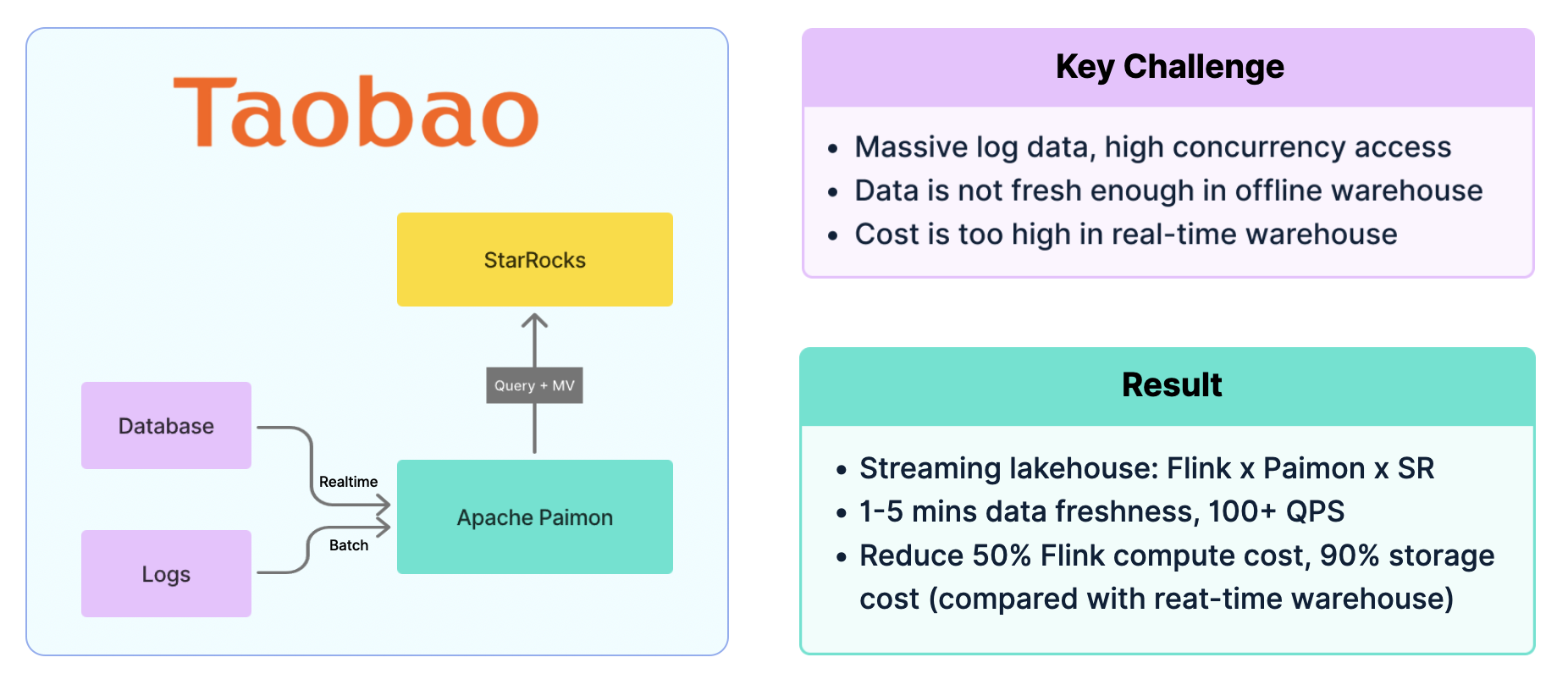
在淘宝闪购的海量交易场景中,每日上亿订单产生庞大的日志数据,对数据系统提出了极高挑战。离线数仓虽然成本低,但只能提供天级或小时级的新鲜度,无法满足业务需求;实时数仓则因高昂的存储与计算成本难以大规模推广。
淘宝闪购最终采用 Flink + Paimon + StarRocks 的实时湖仓架构。数据由 Flink 实时处理后写入 Apache Paimon,再通过 StarRocks 提供实时分析。该方案实现了 1–5 分钟 的数据新鲜度,支撑上百级别的高并发复杂查询。与此同时,Flink 计算成本降低 50%,存储由本地切换至对象存储后,整体成本下降 90%,系统性能与性价比得到显著提升。
淘宝闪购实时分析黑科技:StarRocks + Paimon撑起秋天第一波奶茶自由
连接 AI Agent(未来)
面向未来,StarRocks 正在积极探索如何更好地服务 AI Agent,将数据分析能力与 Agent 场景高效衔接。随着各行各业不断加速 AI 赋能,StarRocks 立足于数据系统的核心优势,持续拓展并构建面向 AI 的新能力,以满足用户在智能化转型中的迫切需求。
在此背景下,我们做了一个面向数据建模优化的 Demo(因整体视频时长限制,此处不单独展示,完整演示可在下方视频回放中查看)。社区用户在建模时经常面临分区、分桶与排序等关键抉择;一旦建模合理,后续分析效率将显著提升,但这通常需要对 StarRocks 架构有较深入的理解。Demo 的使用方式是:将若干建表语句与查询语句输入,一键触发优化;短时间后输出由 AI 推荐的建表语句。这些推荐在多个真实业务场景中已验证具有实用价值。
需要说明的是,大模型的原始能力虽强,但直接 one-shot 输入(如直接给出 DDL、查询与 Profile)往往会得到准确率不高、甚至夹杂错误的信息。因此,在面向真实业务时,不能仅停留在 Benchmark 或“看上去有道理”的答案层面,而必须直面上述不确定性,确保最终结果可用、可控。
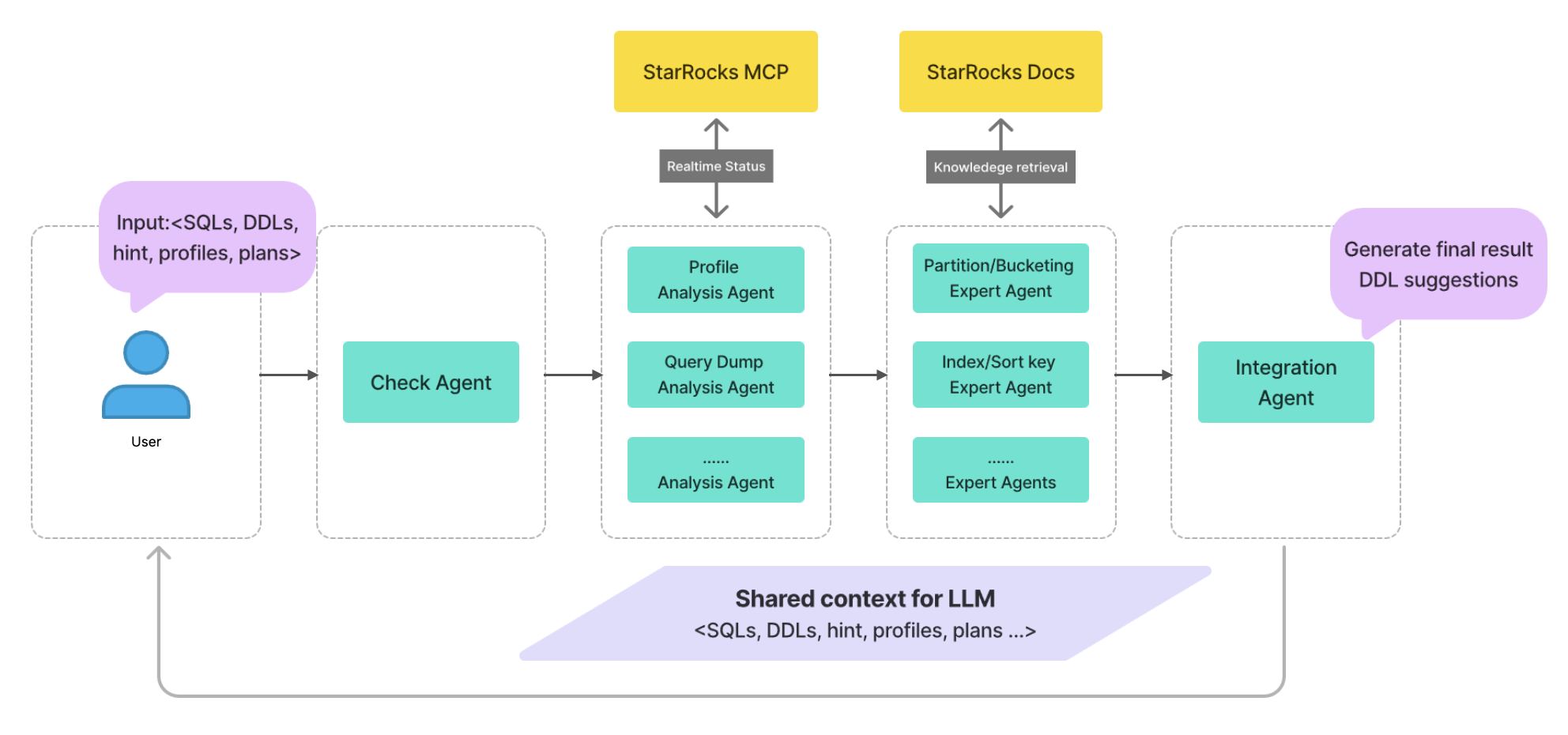
为解决上述问题,把建表优化与 Profile 分析拆解为可控的细粒度任务,并通过 Multi-Agent 协作完成整体链路,实现建表优化。
具体流程如下:
-
用户可直接从 StarRocks 系统拉取,或手动输入所需上下文信息,包括建表语句、查询语句以及(可选的)Profile。
-
首先对上下文进行有效性与一致性校验;若输入本身存在错误或矛盾,及时拦截并返回问题点,避免“错题入场”。
-
在分析阶段,按模块将任务拆分给多个 Agent(对应不同分析视角),逐一完成各自分析并输出阶段性结论,这些结论会沉淀为后续步骤的共享上下文。
-
基于前述分析结论,由负责分区、分桶、排序 Key 等方向的专家型 Agent 给出针对性的建模优化建议。
-
汇聚各专家 Agent 的建议,形成可执行的建表示例与配置要点;在此基础上,按建议完成建表即可。
除整条 Multi-Agent 链路外,依托 StarRocks 的 MCP Server,可与 Agent 进行实时的上下文交互。同时,Agent 需要获取 StarRocks 最新文档作为参考,以辅助其决策与分析。
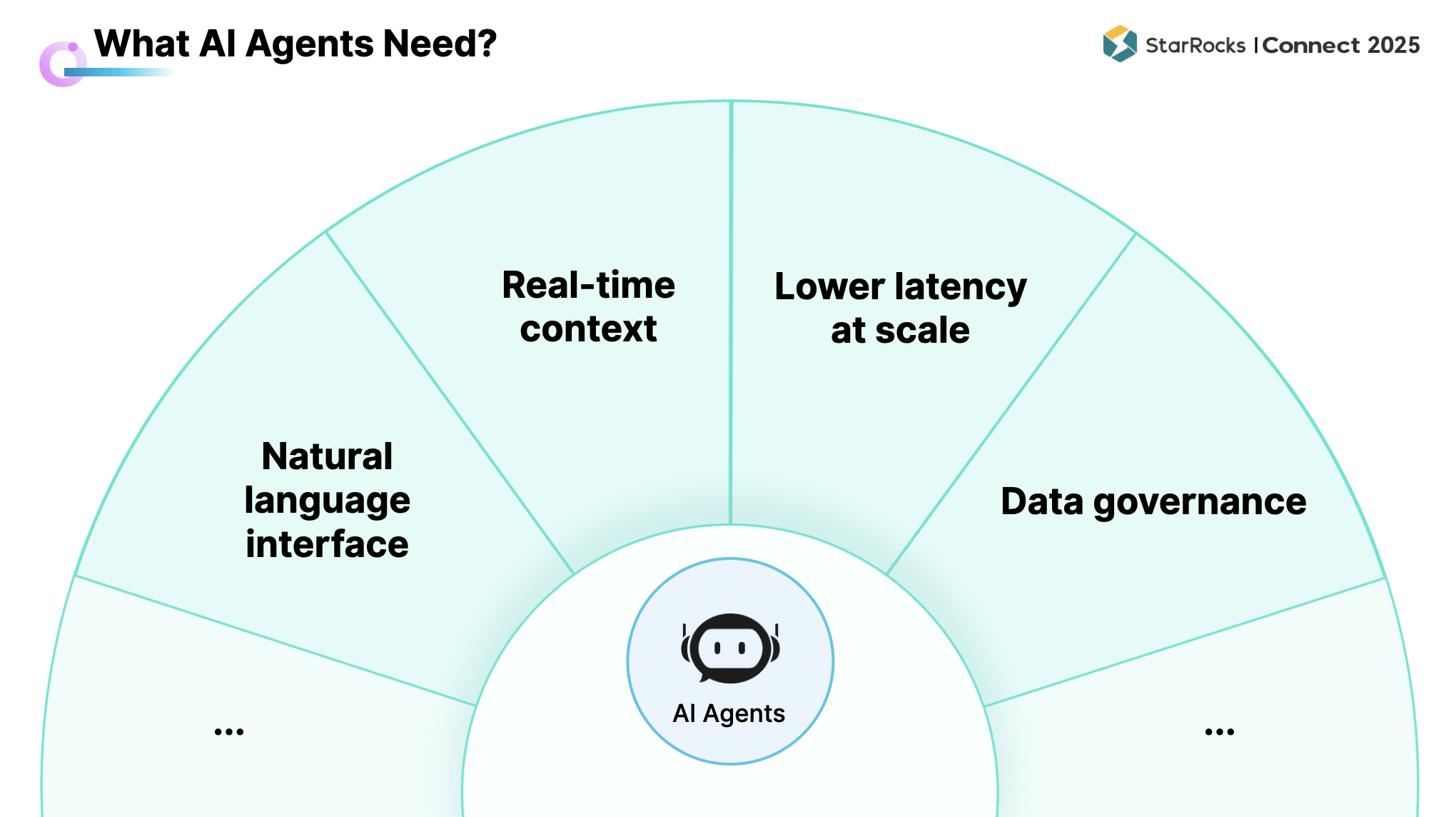
基于上述实践,可归纳出对底层数据分析系统的共性要求:
-
自然语言接口支持,需要提供可用的自然语言入口:可通过 MCP Server 暴露接口,或自建语义层(如 Text-to-SQL)以支持文本查询。
-
Agent 的结论高度依赖实时信息,系统需可用以获取实时运行状态、实时文档等上下文,并将其纳入推理与决策流程。
-
多个 Agent 往往以多轮、密集方式与系统交互,该模式不同于人工分析:
需要足够低的查询延时以支撑多轮对话与快速迭代;
需要足够高的并发能力以容纳多 Agent 同时访问与协同。
-
数据质量与治理能力,若底层数据质量不足,Agent 的最终表现将受限。因此,数据治理是对数据系统的核心要求之一。
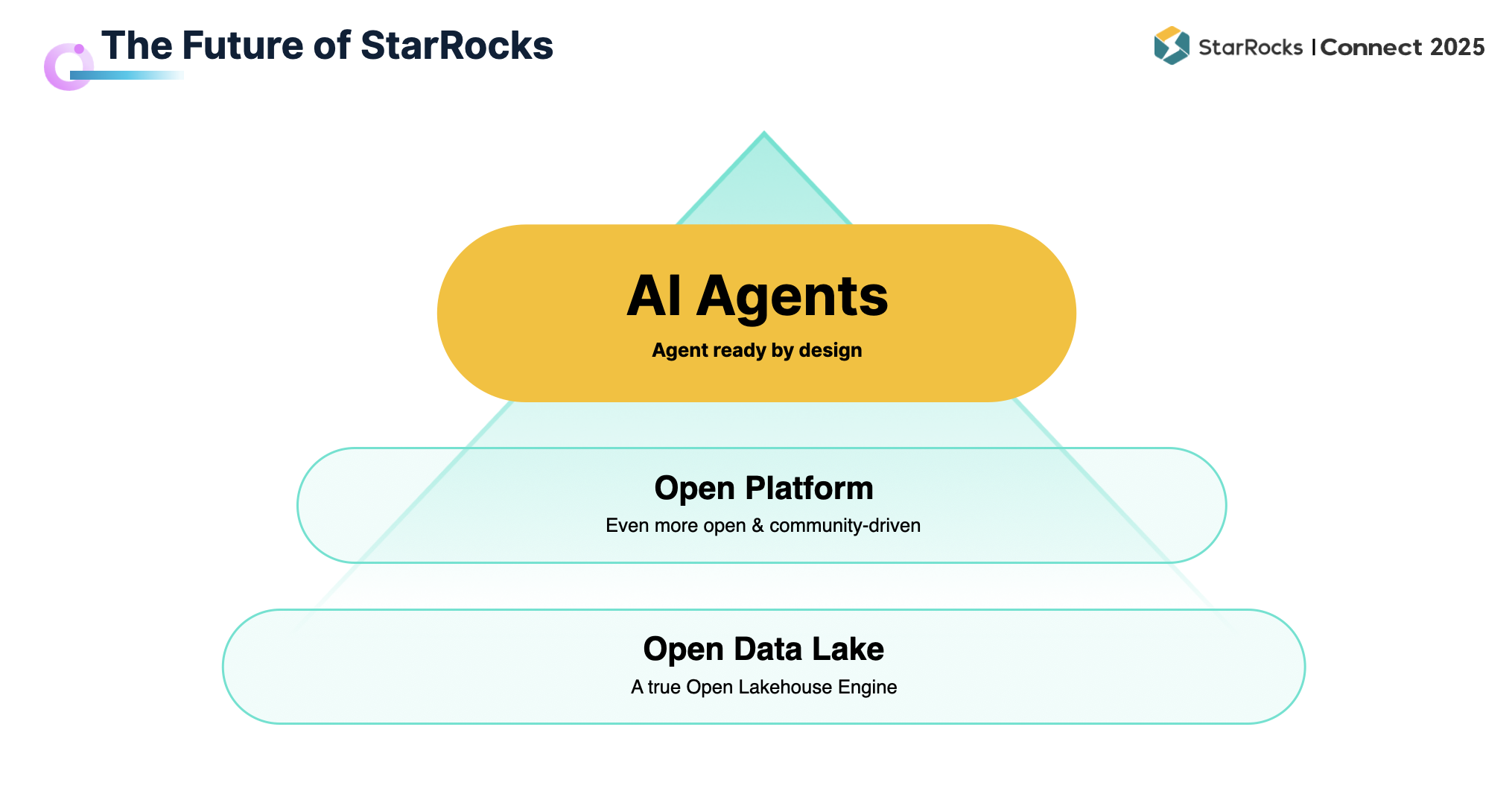
综合前文所述,StarRocks 在许多方面已具备明显优势,并在其他环节持续补充与完善。未来,我们希望将 StarRocks 打造成真正 “AI Agent Ready” 的系统。
从发展思路来看(如上图所示),最底层是 StarRocks 已经具备的 Lakehouse 基础能力,能够提供实时、高并发的数据分析;最顶层则是 AI Agent,代表未来 “AI is everything” 的世界,一切业务场景都将与 Agent 交互。如何将两者结合,是留给我们的重大挑战。
解决路径在于中间的 Open Platform 层。核心思路是保持足够的开放性:开放社区、开源系统,并与更广泛的开放生态对接,覆盖包括 BI、AI 在内的多样化数据分析场景。通过这一平台化的开放连接,StarRocks 将与生态伙伴一道,为 AI Agent 构建更完善的数据分析环境。
One More Thing
自 2023 年起,StarRocks 存算分离架构已在社区广泛应用,数百位用户积极投入实践。基于开源 StarRocks,许多厂商也构建了企业级功能。例如, StarRocks 企业级 Multi-warehouse 能力,不少社区用户反馈,这一功能将显著简化和加速不同场景的构建。
因此,我们正式宣布:StarOS Multi-warehouse 企业级能力将于 2025 年底前全面开源。我们希望通过开源技术,帮助更多企业释放数据价值,创造更大的业务成果。
StarRocks:Connect Data Analytics with the World
PPT获取链接:https://forum.mirrorship.cn/t/topic/20074