Spark核心技术解析:从RDD到Dataset的演进与实践
摘要:
本文全面解析Spark的核心技术体系,从基础概念到高级特性,详细介绍了RDD、DataFrame和Dataset三种数据抽象的演进关系、核心特性及适用场景。通过对比表格和代码示例,帮助读者深入理解Spark的编程模型与执行机制,掌握大数据处理的最佳实践。
一、基本概念与架构
1.1 Spark核心概念
Spark是一个快速、通用的大数据处理引擎。Spark从根本上解决了传统MapReduce框架的I/O瓶颈问题,通过创新的内存计算模型将大数据处理性能提升了一个数量级。
核心特性对比分析:
| 特性 | Spark | MapReduce |
| 计算模型 | 内存迭代计算 | 磁盘批处理 |
| 延迟 | 毫秒级 | 分钟级 |
| API丰富度 | 多范式(批/流/图/ML) | 仅批处理 |
| 容错机制 | 血统+检查点 | 数据副本 |
1.2 整体架构概述
Spark采用主从架构,主要包含以下组件(架构层次维度):
- Driver:应用程序入口,负责解析代码、生成执行计划
- Executor:实际执行任务的进程
- Cluster Manager:资源调度器(如YARN、Mesos)
- DAG Scheduler:将逻辑执行计划转换为物理执行计划
1.3 核心组件介绍
Spark生态系统包含五大核心组件(功能模块维度),构成了完整的大数据解决方案栈:
| 组件 | 功能 |
| Spark Core | 基础引擎,包含任务调度、内存管理等功能 |
| Spark SQL | 结构化数据处理 |
| Spark Streaming | 微批流式处理 |
| MLlib | 机器学习库 |
| GraphX | 图计算库 |
二、编程模型与API
2.1 数据抽象演进史
2.1.1 RDD (Resilient Distributed Dataset)
- 核心概述:RDD是Spark最核心的数据抽象,表示一个不可变的、可并行操作的数据集。它具备以下核心特性:
- 弹性(Resilient):自动从节点故障中恢复
- 分布式(Distributed):数据分布在集群的多个节点上
- 数据集(Dataset):数据以分区(Partition)形式组织
- 不可变(Immutable):一旦创建,内容不可修改
2. 五大特性
- 分区(Partitioning):将海量数据分成多份,每个分区对应一个Task线程执行计算
- 只读(Read-only):RDD中的数据不可直接修改,修改会生成新的RDD
- 依赖(Lineage):通过血统关系实现容错
- 缓存(Persistence):支持内存/磁盘持久化
- 检查点(Checkpoint):定期保存RDD状态
3. 弹性体现
- 存储弹性:数据可缓存在内存中,内存不足时换出到磁盘
- 计算弹性:通过DAG Lineage判断宽窄依赖,选择性存储中间结果
- 容错弹性:通过血统关系恢复丢失的分区
2.1.2 DataFrame
核心概述:DataFrame基于RDD的更高层抽象,是 Spark SQL 模块中的核心数据结构,它是一个分布式数据集合,以命名列的方式组织数据,类似于关系型数据库中的表。
核心特性:
- 结构化数据:具有明确的行列结构
- 不可变性:创建后内容不可修改
- 分布式处理:数据自动分区在集群节点上
- 优化执行:通过Catalyst优化器进行查询优化
- 多语言支持:支持Python、Java、Scala和R
2.1.3 Dataset
核心概述:Dataset 是 Spark 1.6 版本引入的API,它结合了RDD的强大功能和DataFrame的优化执行能力,提供了类型安全的编程接口。
核心特性:
- 类型安全:编译时类型检查
- 高性能:借助Tungsten优化执行
- 多语言支持:支持Java和Scala
- 结构化处理:结合了DataFrame的查询优化能力
- 函数式编程:保留了RDD的转换操作特性
2.1.4 Dataset、DataFrame、RDD 关系
- 共同点
- 分布式计算:都是Spark中的分布式数据集,支持集群环境下的并行处理
- 惰性求值:都采用惰性执行机制,只有在遇到action操作时才会真正执行计算
- 容错机制:都具备基于血统(lineage)的容错能力
- SQL优化:都可以通过Spark SQL引擎进行查询优化
2. 主要区别
RDD、DataFrame与Dataset核心差异
| 特性维度 | RDD | DataFrame | Dataset |
| 类型安全 | 是 | 否 | 是 |
| 优化执行 | 无 | Catalyst优化 | Catalyst优化 |
| 结构化数据 | 否 | 是 | 是 |
| API风格 | 函数式 | SQL风格 | 混合风格(函数式+面向对象) |
| 语言支持 | 多语言(Java/Scala/Python等) | 多语言 | 主要支持Java/Scala |
| 适用场景 | 非结构化数据处理、精细控制 | SQL查询、结构化数据分析 | 类型安全的复杂数据处理 |
与Spark组件的关系(API类型与组件归属)
| API类型 | 所属组件 | 核心特点 | 典型应用场景 |
| RDD | Spark Core | 低级API、无schema、类型不安全 | 非结构化数据处理、需要精细控制时 |
| DataFrame | Spark SQL | 结构化数据、有schema、类型不安全 | SQL查询、结构化数据分析 |
| Dataset | Spark SQL | 结构化数据、类型安全、面向对象 | 类型安全的复杂数据处理 |
2.2 核心API介绍
Spark API遵循函数式编程范式:
转换操作(Transformations):
- 窄依赖:map、filter等
- 宽依赖:groupByKey、join等
动作操作(Actions):
- 触发计算:collect、count等
- 输出操作:saveAsTextFile等
控制操作:
- persist/cache:持久化策略
- checkpoint:切断血统链
- broadcast:变量广播
2.3 编程范式对比
// RDD示例(低级API)
val rdd = sc.textFile("hdfs://data.log").flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)// DataFrame示例(声明式API)
val df = spark.read.json("data.json")
df.groupBy("department").avg("salary")// Dataset示例(类型安全)
case class Employee(name: String, salary: Double)
val ds = df.as[Employee]
ds.filter(_.salary > 10000)三、执行引擎与运行架构
3.1 执行流程
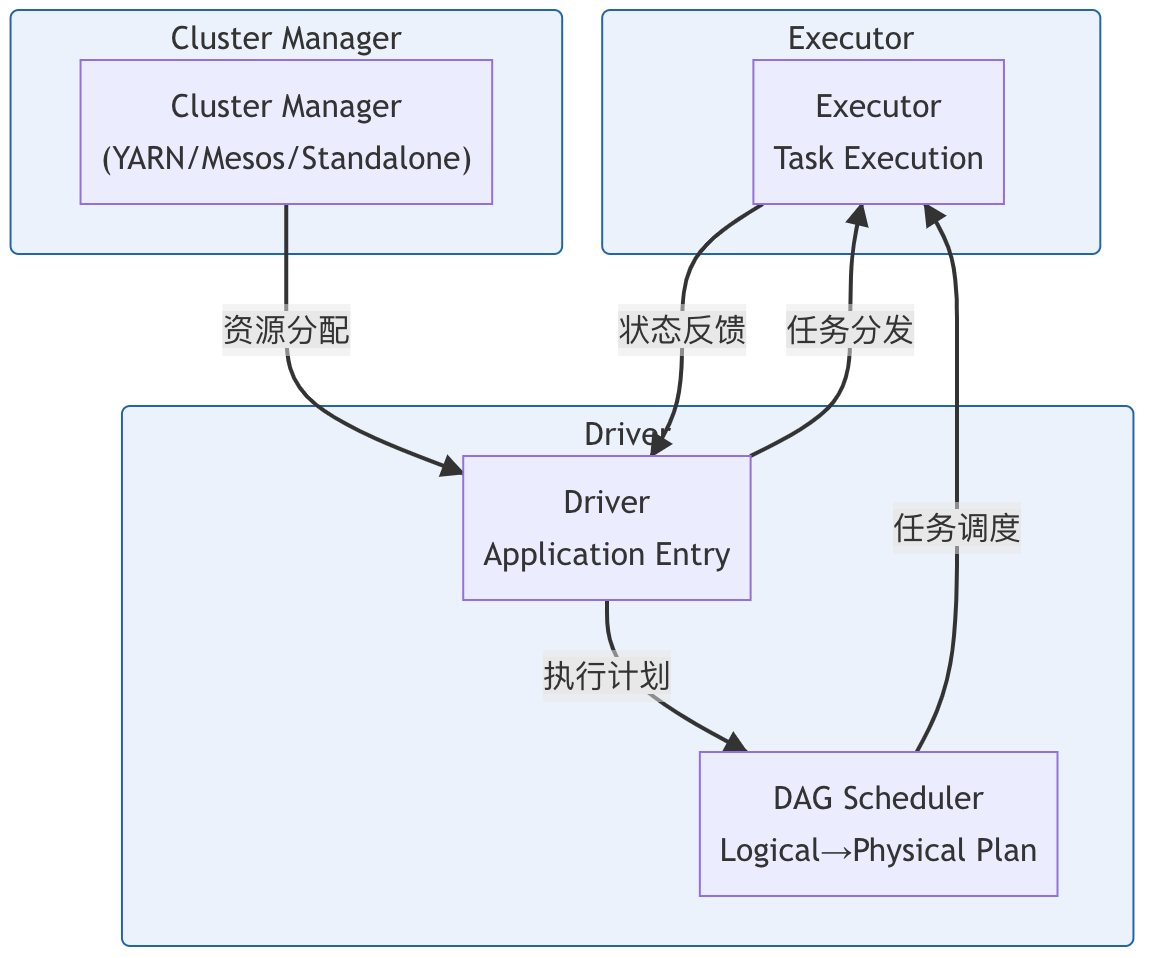
交互流程:
- 提交阶段:用户通过spark-submit提交应用到Driver
- 初始化阶段:Driver程序解析代码构建DAG
- 调度阶段:DAGScheduler划分Stage,TaskScheduler分配Task到Executor
- 执行阶段:Executor执行具体Task
- 结果回收:Driver收集计算结果
3.2 任务调度
3.2.1 概述
Spark采用DAG调度器,具有以下特点:
- 将作业划分为多个Stage
- 每个Stage包含多个Task
- 支持宽依赖和窄依赖
3.2.2 DAG调度原理
阶段划分算法:
- 从最终RDD反向遍历依赖链
- 遇到宽依赖即划分Stage边界
- 生成最优任务调度计划
调度优化策略:
- 阶段流水线执行(Pipelining)
- 推测执行(Speculative Execution)
- 动态资源分配(DRA)
3.3 内存管理
Spark使用堆外内存和堆内内存两种方式:
- 堆外内存:用于存储序列化数据
- 堆内内存:用于存储反序列化数据
3.4 容错机制
Spark通过以下方式实现容错:
- RDD的血统(Lineage)机制
- 检查点(Checkpoint)机制
- 任务重试机制
血统(Lineage)机制恢复流程:
- 记录每个RDD的生成方式
- 丢失分区时重新计算
- 检查点作为恢复点
检查点(Checkpoint)机制最佳实践:
- 对长血缘链RDD设置检查点
- 优先使用HDFS等可靠存储
- 与persist配合使用
四、作业提交与执行
4.1 提交方式
Spark支持多种提交方式:
| 提交方式 | 描述 |
| spark-submit CLI | 通过命令行工具提交Spark作业 |
| YARN Cluster/Client模式 | 在YARN集群上运行Spark作业,支持Cluster和Client两种部署模式 |
| Standalone模式 | 使用Spark自带的独立集群管理器 |
| Mesos/Kubernetes | 通过Mesos或Kubernetes集群管理器运行Spark作业 |
4.2 资源分配
Spark资源分配是集群计算中的关键环节,主要涉及以下核心概念:
- 动态资源分配(DRA):允许Spark根据工作负载自动调整Executor数量,优化集群资源利用率
- 静态分配:在提交任务时固定设置Executor数量,适用于负载稳定的场景
- 关键参数:
- executor数量
- 每个executor的CPU core数
- 每个executor的内存大小
4.3 执行计划优化
Catalyst优化器
Catalyst优化器是Spark SQL的核心组件,采用基于规则和成本的优化策略,将SQL查询转换为高效的物理执行计划。其优化流程分为四个关键阶段
- 逻辑计划分析
- 逻辑优化(常量折叠/谓词下推)
- 物理计划生成
- 代码生成
AQE(自适应查询执行)
AQE是Spark 2.0引入的动态优化机制,在运行时根据统计信息调整执行计划,包含三大核心功能:
- 动态合并小分区
- 运行时Join策略调整
- 自动倾斜处理
总结:
- Catalyst优化器:适用于静态查询优化,通过多阶段转换生成高效执行计划
- AQE机制:针对动态负载变化,在运行时自适应调整执行策略
- 适用场景:AQE特别适合数据分布不均匀、负载波动大的生产环境
五、监控与调优
5.1 作业监控
Spark提供多种监控方式:
| 监控方式 | 功能描述 | 主要特点 |
| Web UI | 提供实时作业监控界面,展示作业执行状态、任务进度、资源使用情况等 | 直观可视化界面,支持查看Stage/Task详情、DAG图、Executor状态等实时信息 |
| Metrics系统 | 通过指标收集器暴露应用程序和集群的度量数据 | 支持Prometheus等监控系统集成,提供细粒度的性能指标采集和长期趋势分析 |
| Spark History Server | 提供已完成作业的历史记录和统计分析界面 | 支持多作业对比分析,可查看已完成作业的完整执行日志和资源使用历史记录 |
5.2 性能调优
| 调优策略 | 适用场景 |
| 合理设置分区数 | 数据分布不均、并行度不足或过高、存在数据倾斜问题 |
| 启用动态分配 | 资源利用率低、负载波动大、多租户共享环境 |
| 使用广播变量 | 小数据集重复传输、Join操作优化、减少内存压力 |
| 数据序列化优化 | 序列化性能瓶颈、Shuffle数据传输效率低 |
| AQE优化 | 数据分布不均匀、统计信息不准确、运行时需要动态调整 |
| 资源隔离 | 多任务竞争资源、CPU/内存使用冲突 |
5.3 常见问题排查
常见问题及解决方法:
- Executor崩溃:检查内存设置
- 任务执行缓慢:检查数据倾斜
- 调度延迟:检查资源竞争
结语
本文全面介绍了Spark的核心技术体系,从基本概念到高级特性,帮助读者系统掌握Spark的工作原理和最佳实践。Spark作为大数据处理的事实标准,其强大的功能和灵活的架构使其成为大数据工程师的必备技能。
扩展阅读
- Flink核心知识体系与项目实践