GPU微架构演进分析--从SIMT到Scalar-Vector-Tensor计算的混合配比与调度
全文总结和结论如下(参见后面的Page11):
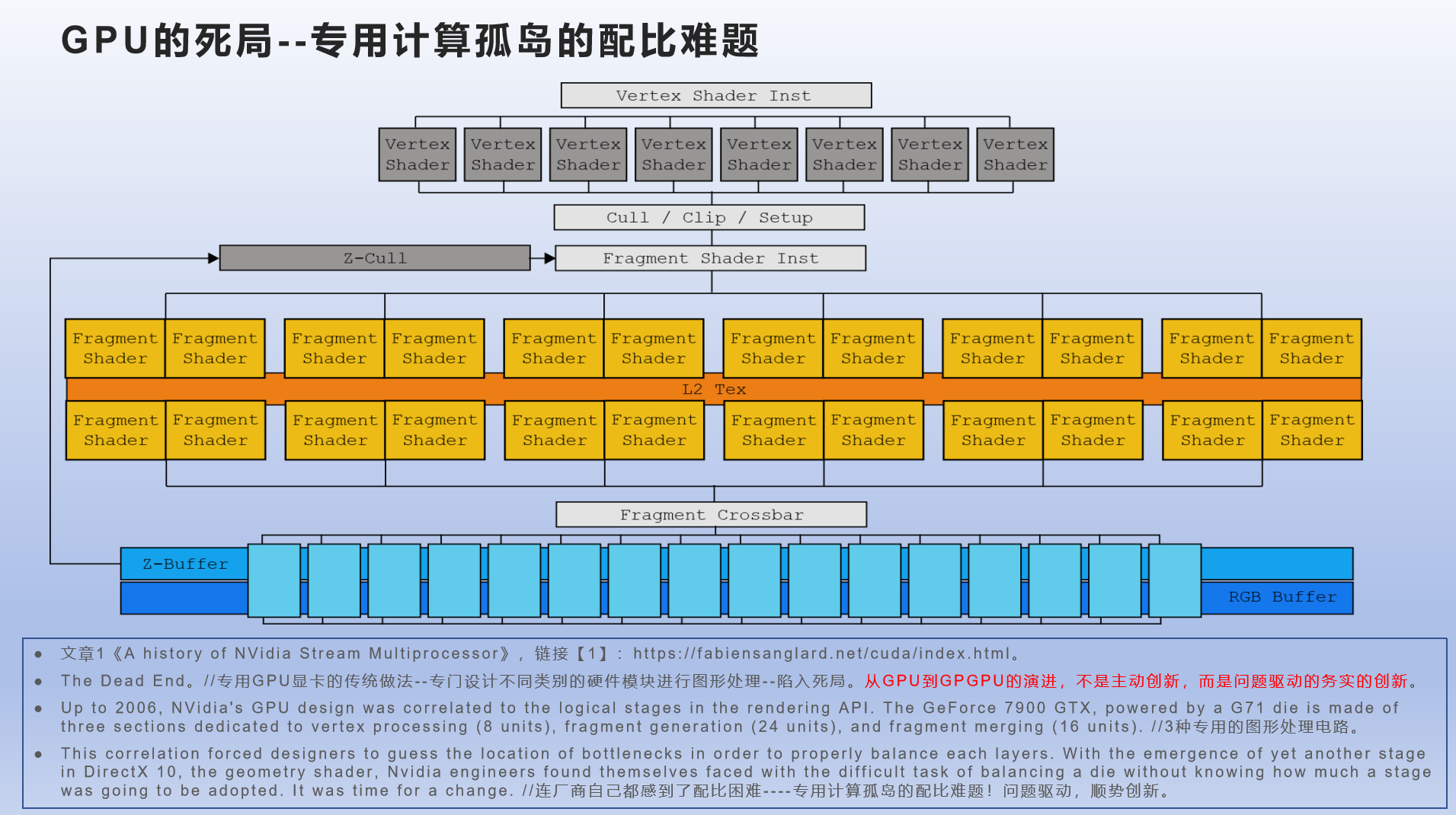
传统的图形处理(GPU):将3D图形表示数据(物体和光源等3D场景数据),转换为平面显示器所需要的2D像素数据,需要经过一系列的专用计算。
----以传统的GeForce 7900显卡(G71 GPU Die)为例,包含了Vertex Processing、Fragment Generation、Fragment Merging三种主要的处理电路。
----在提升图形处理能力时,如何对这三类电路模块的数量进行【配比】,成了一个难题----多种专用(不可编程)计算模块的资源配比问题。
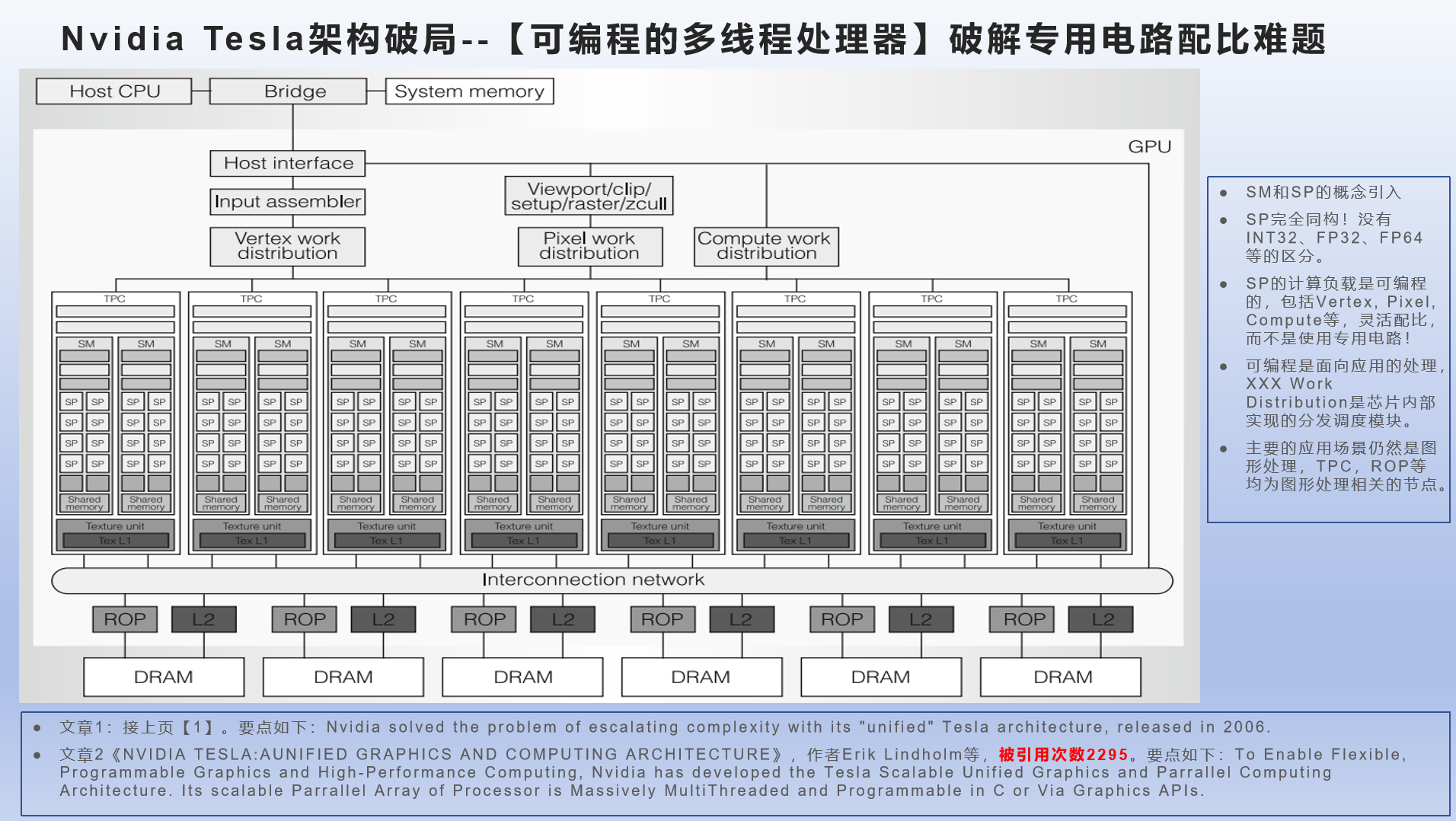
统一图形和计算架构:Tesla架构采用了【可编程多线程】处理器作为【统一】的{图形+计算}单元,破解上述多种专用计算模块的资源配比问题,谓之GPGPU。
----SM和SP的概念。其中SP={INT/ALU + Float/FPU},通过编程让他们跑Vertex、Fragment等不同的程序(工作负载)。
----Vertex Distribution,Pixel Distribution, Compute Distribution,负责将不同类别的工作负载分发到SP处理器上,这和超标量CPU的Dispatch/Issue其实很像。
CUDA计算架构:Nvidia Fermi架构-- 引入CUDA将【图形】vs【计算】的天平向右边倾斜
GPGPU = These early efforts that used graphics APIs for general purpose computing were known as GPGPU programs.
NVIDIA introduced two key technologies—the G80 unified graphics and compute architecture and CUDA. We called this new way of GPU programming “GPU Computing”— a clear separation from the early “GPGPU” model of programming.
【定制】【统一】【定制】的螺旋:从Tesla的统一图形和计算(Unified Graphics and Computing Architecture)开始,新一轮【定制】计算就已经开始了!
----Fermi引入SFU,Kepler引入DP Unit,Turing引入Tensor和RT Core。这些新引入的单元都不属于Core(CUDA Core)的范围。
----从Tuning(RTX2080)和Volta(V100)开始,不再用CUDA Core的概念而是把ALU和FPU与FP64和TensorCore四种【异质】计算单元并列地平铺开来。
----SIMT的概念也不再那么明显了,因为传统的SIMT的概念 = CUDA Cores的细粒度并行,而CUDA Core = 可(通过指令)编程的标量运算{INT+FP32}模块。
【AI狂飙突进】:从Tuning(RTX2080)和Volta(V100)开始,引入Tensor Core开始,工作负载从图形处理为主/计算加速为辅,转变为AI计算的狂飙突进。
----就SM的微架构而言,相对V100来说已经没有太大的变化了,仍然是把INT、FP32、FP64、Tensor Cores这四种【异质】计算单元并列地平铺开来!
----演进方向1:增加稀疏化处理能力(Sparsity)。增加INT2等低精度处理能力。这两个方面都可以认为是低精度处理能力(稀疏化就是把一些小的值用0来代替和近似)。
----演进方向2:多芯片的互联的NVLink的演进。NVLink不是Ampere(A100)才有的,但它是面向大规模AI训练/推理的集群计算的关键,因此在V100/A100/H100快速演进。
【评论思考】:SIMT是大量Scalar运算单元(所谓CUDA Core或者SP流处理器)的调度模型,{Scalar+Vector+Tensor}已然成为4AI大算力的新计算范式 。
----Scalar+Vector+Tensor组成层次化运算单元类别范式后,各类资源配比和调度成为Higher Level的问题,而SIMT则成为Lower Level的问题(Scalar运算调度)。
----SIMT的问题重要性降级为Lower Level,和SIMT孪生的CUDA如何成为“护城河”?RISC-V的计算架构演进创新或许真有新机会!?
Page0:GPU微架构演进分析--从SIMT调度到Scalar-Vector-Tensor的混合调度

Page1:传统GPU的死局--专用计算孤岛的配比难题
Page2:Nvidia Tesla架构破局--【可编程的多线程处理器】破解专用电路配比难题
Page3:Nvidia Fermi架构--引入CUDA将【图形】vs【计算】的天平向右倾斜

Page4:Tesla-Fermi-Kepler-Maxwell-Pascal-Turing演变:Kepler

Page5:Tesla-Fermi-Kepler-Maxwell-Pascal-Tuning演变:Maxwell

Page6:Tesla-Fermi-Kepler-Maxwell-Pascal-Tuning演变:Pascal

Page7:Tesla-Fermi-Kepler-Maxwell-Pascal-Turing演变:Turing

Page8:AI专用V100-A100-H100演变:V100

Page9:AI专用V100-A100-H100演变:A100

Page10:AI专用V100-A100-H100演变:H100

Page11:总结和评论

---<End> of 《GPU微架构演进分析-从SIMT到Scalar-Vector-Tensor的混合调度(V0.1)》---