后端笔记之MyBatis 通过 collection 标签实现树形结构自动递归查询
简单来说就是:MyBatis 会自动帮你一层层查父子节点,最终在内存中拼出完整的树,无需手动写循环组装。
核心逻辑:“有子节点就查,无子节点就停”
递归查询的终止条件是:当 selectOtherList 执行后返回空结果(即当前节点没有子节点),此时不再继续向下查询。
举例查询次数拆解:
主查询 selectTreeData:查询 1 次(获取一级节点 id=1);
第一次递归:对 id=1 调用 selectOtherList,查询 1 次(获取二级节点 id=2);
第二次递归:对 id=2 调用 selectOtherList,查询 1 次(获取三级节点 id=3);
第三次递归:对 id=3 调用 selectOtherList,返回空结果,终止递归。
如果调用selectTreeData 方法,核心是以 level=1 为起点,通过递归查询自动关联所有子层级节点,最终返回的是包含完整层级关系的树形数据,而非仅 level=1 的节点。这也是 MyBatis 这种配置实现树形查询的核心价值。
原始代码
用例子拆解全过程:
假设数据库表 a_student 中的数据是一棵三级树:
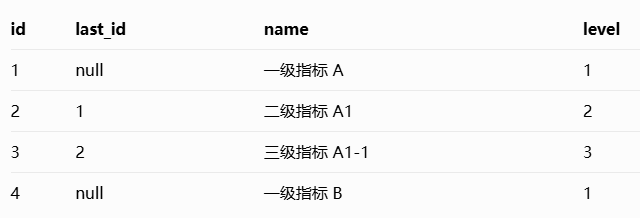
1. 核心配置:
要实现自动递归,需要在 MyBatis 映射文件中定义一个包含 collection 标签的 resultMap,例如:
<!-- 定义树形结果映射 -->
<resultMap id="studentTreeResultMap" type="org.jit.sose.entity.test.Student"><!-- 映射基础字段(id、name、lastId等) --><id property="id" column="id"/><result property="name" column="name"/><result property="lastId" column="last_id"/><!-- 其他字段映射... --><!-- 关键:通过collection自动查询子节点 --><collectionproperty="childList" <!-- 对应实体类中的childList属性 -->ofType="org.jit.sose.entity.assessment.Student" <!-- 子节点类型 -->select="selectOtherList" <!-- 查询子节点的方法ID -->column="id" <!-- 传递当前节点的id作为子节点的lastId参数 -->/>
</resultMap><!-- 主查询:获取一级指标(level=1) -->
<select id="selectTreeData" resultMap="studentTreeResultMap">SELECT id, last_id, name, level FROM a_studentWHERE level = 1 AND state = 'A' AND plan_id = #{planId}
</select><!-- 子查询:根据父节点id查询子节点(last_id=父id) -->
<select id="selectOtherList" resultMap="studentTreeResultMap" parameterType="int">SELECT id, last_id, name, level FROM a_studentWHERE last_id = #{id} AND state = 'A'
</select>
2. 执行流程(自动递归查询):
第一步:执行主查询 selectTreeData
作用:查询所有一级指标(level=1,last_id=null)。
结果:得到 id=1(一级指标 A)和 id=4(一级指标 B)两个对象,此时它们的 childList 暂时为空。
第二步:MyBatis 自动触发子查询 selectOtherList(第一次递归)
对主查询结果中的每个一级指标,MyBatis 会读取其 id(如 id=1),作为参数调用 selectOtherList。
selectOtherList 的逻辑:查询 last_id=1 的记录(即一级指标 A 的子节点)。
结果:查询到 id=2(二级指标 A1),MyBatis 会将这个节点存入一级指标 A 的 childList 中。
第三步:递归查询更深层级(第二次递归)
由于 selectOtherList 的 resultMap 也是 studentTreeResultMap(自身),MyBatis 会对刚查询到的二级指标 A1(id=2)再次触发 selectOtherList。
此时参数是 id=2,查询 last_id=2 的记录,得到 id=3(三级指标 A1-1)。
结果:将三级指标 A1-1 存入二级指标 A1 的 childList 中。
第四步:终止递归
当查询 selectOtherList 时,如果没有符合条件的记录(例如三级指标 A1-1 没有子节点,last_id=3 无结果),递归终止。
对一级指标 B(id=4)执行同样逻辑:如果它没有子节点,childList 会保持空集合。
3. 最终内存中的树形结构
经过上述递归查询,childList 会自动填充所有子节点,形成完整的树:
List<Student> result = [// 一级指标AStudent(id=1,name="一级指标A",lastId=null,childList=[ // 二级子节点Student(id=2,name="二级指标A1",lastId=1,childList=[ // 三级子节点Student(id=3,name="三级指标A1-1",lastId=2,childList=[] // 无更深层级)])]),// 一级指标B(无子女)Student(id=4,name="一级指标B",lastId=null,childList=[])
]
@Data
public class Student{private Integer id;private String name;private Integer level;// 等级:级别(1/2/3)private Integer lastId; // 上级ID:用于建立指标层级关系List<Indicator> childList;/*** 树节点设置不能选定*/private Boolean disabled;private Integer seq; // 序号: 用于排序
}
核心总结
(1)自动递归:通过 collection 标签的 select 属性,MyBatis 会以当前节点 id 为参数,自动调用子查询,层层嵌套查询子节点。
(2)无需手动组装:省去了在 Service 层写循环拼接 childList 的代码,MyBatis 直接在内存中完成树形结构的组装。
(3)childList 的作用:作为树形结构的载体,最终序列化 JSON 时自然体现父子层级关系。
这种方式的优点是配置简单,适合层级不深的树形结构;缺点是可能产生多次数据库查询(每层一次),层级过深时性能会受影响。
[{"id": 1,"name": "一级指标A","lastId": null,"childList": [{"id": 2,"name": "二级指标A1","lastId": 1,"childList": [{"id": 3,"name": "三级指标A1-1","lastId": 2,"childList": []}]}]},{"id": 4,"name": "一级指标B","lastId": null,"childList": []}
]
优化代码
<sql id="Base_Column_List" >id, last_id, name, level,seq
</sql>
<resultMap id="studentTreeResultMap" type="org.jit.sose.entity.test.Student"><collection property="childList" column="{lastId=id}" ofType="org.jit.sose.entity.test.Student"select="selectOtherList"></collection>
</resultMap><!-- 结果映射:使用 studentTreeResultMap,意味着查询到的每个一级节点都会触发 <collection> 配置,自动查询其子节点 -->
<select id="selectTreeData" resultMap="studentTreeResultMap" parameterType="java.lang.Integer">SELECT<include refid="Base_Column_List" />FROM a_studentWHERE state='A'AND level = 1 order by seq <!-- 按排序号升序排列 -->
</select><!-- 由于其结果映射也是 studentTreeResultMap,因此查询到的每个子节点会再次触发 <collection> 配置,继续查询它的子节点(即 “孙子节点”),以此类推,直到没有更深层级的节点 -->
<select id="selectOtherList" resultMap="studentTreeResultMap" parameterType="org.jit.sose.entity.test.Student">SELECT<include refid="Base_Column_List" />FROM a_studentWHERE state='A'AND last_id=#{lastId,jdbcType=INTEGER} <!-- 按父节点 ID 查询子节点 -->order by seq
</select>
这两段代码都是 MyBatis 中用于查询树形结构的配置,但在子节点查询参数传递、结果映射复用、查询逻辑细节等方面存在差异,具体区别如下:
1. collection 标签的参数传递方式不同
第一段代码:
<collection property="childList" ofType="org.jit.sose.entity.assessment.Student" select="selectOtherList" column="id" <!-- 传递当前节点的id作为参数 -->
/>
column=“id” 表示:将当前节点的 id 字段作为参数,传递给子查询 selectOtherList。
子查询接收参数时直接用 #{id}(因为参数是单个值 id):
<select id="selectOtherList" parameterType="int">WHERE last_id = #{id} <!-- 直接使用id作为参数 -->
</select>
第二段代码:
<collection property="childList" <!-- 对应 Student 类的 childList 属性(子节点列表) -->column="{lastId=id}" <!-- 传递当前节点的 id 作为子查询的 lastId 参数 -->ofType="org.jit.sose.entity.test.Student" <!-- 子节点类型为 Student -->select="selectOtherList" <!-- 子查询的 ID(用于查询当前节点的子节点) -->/>
column=“{lastId=id}” 表示:将当前节点的 id 字段封装成键值对 {lastId: id} 传递给子查询。
子查询接收参数时需要用 #{lastId}(与键名对应):
<select id="selectOtherList" parameterType="org.jit.sose.entity.test.Student">WHERE last_id=#{lastId,jdbcType=INTEGER} <!-- 使用lastId作为参数 -->
</select>
核心差异:参数传递方式不同,第一段是 “单值传递”,第二段是 “命名参数传递”(更灵活,支持多参数)。
2. resultMap 的复用与递归逻辑不同
第一段代码:
主查询 selectTreeData和子查询 selectOtherList 共用同一个 resultMap=“studentTreeResultMap”。
由于 studentTreeResultMap中包含 collection 标签,子查询的结果会再次触发 collection 配置,实现自动递归查询(无需手动控制层级,直到没有子节点为止)。
第二段代码:
主查询和子查询共用 resultMap=“studentTreeResultMap”,该 resultMap 同样包含 collection 标签,理论上也能递归,但参数传递是命名参数(lastId),与第一段的单值参数逻辑不同。
此外,第二段明确指定了 parameterType=“org.jit.sose.entity.test.Student”(子查询接收一个对象参数),而第一段子查询的 parameterType=“int”(接收单个整数)。
核心差异:参数类型和传递逻辑不同,但递归原理一致(均通过 collection 标签实现多层级查询)。
3. 查询字段的定义方式不同
第一段代码:
主查询和子查询的字段是直接写在 SQL 中的(SELECT id, last_id, name, level …),硬编码在 <select> 标签内。
第二段代码:
通过 <sql id="Base_Column_List"> 定义了公共字段片段(id, last_id, name, level, seq),并在查询中用 <include refid="Base_Column_List" /> 引用。
好处是:如果需要修改查询字段,只需修改 Base_Column_List 片段,无需修改所有 SQL,复用性更高。
核心差异:第二段使用了 SQL 片段复用,第一段是硬编码字段。
4. 子查询的 parameterType 不同
第一段代码:子查询 selectOtherList 的 parameterType=“int”,表示接收一个整数参数(当前节点的 id)。
第二段代码:子查询 selectOtherList 的 parameterType=“org.jit.sose.entity.test.Student”,表示接收一个 Student对象参数(通过对象的 lastId 属性取值)。
核心差异:参数类型不同,第一段是基本类型,第二段是对象类型(更适合多参数场景)。
总结:核心区别对比表

实际效果差异
(1)两段代码最终都能查询出树形结构(通过 childList 体现父子关系)。
(2)第二段代码的 SQL 片段复用更符合代码规范,维护性更好。
(3)第二段的命名参数传递({lastId=id})支持传递多个参数(例如 column=“{lastId=id, planId=planId}”),灵活性更高,而第一段仅支持单参数。
(4)若字段需要扩展(如新增字段),第二段只需修改 Base_Column_List,第一段需逐个修改 SQL,因此第二段更优。
selectTreeData与selectOtherList使用场景
调用 selectOtherList 与调用 selectTreeData 的结果有本质区别,核心差异在于查询的起点和返回的树形结构范围,具体区别如下:
1. 查询起点不同
selectTreeData:以 level=1 的一级节点为起点(根节点),查询条件明确限制 level = 1,因此返回的是完整的树形结构(从一级节点开始,包含所有子层级)。
selectOtherList:没有固定的起点,需要传入一个 lastId 参数(父节点 ID),查询条件是 last_id = #{lastId},因此返回的是以 lastId 对应节点为父节点的子节点树(即从某个节点的子节点开始,包含其所有后代)。
2. 返回结果的范围不同
假设数据库中存在如下树形结构(state=‘A’):
level=1(id=1)
└── level=2(id=2,last_id=1)└── level=3(id=3,last_id=2)
level=1(id=4)
(1)调用 selectTreeData 的结果:
返回以 level=1 为根的完整树,包含所有一级节点及其后代:
[{"id": 1,"level": 1,"childList": [{"id": 2,"level": 2,"childList": [{"id": 3,"level": 3,"childList": []}]}]},{"id": 4,"level": 1,"childList": []}
]
(2)调用 selectOtherList(lastId=1) 的结果:
传入 lastId=1(即父节点为 id=1),返回以 id=1 的子节点为起点的树(仅包含 id=1 的后代,不包含 id=1 本身和其他一级节点):
[{"id": 2,"level": 2,"childList": [{"id": 3,"level": 3,"childList": []}]}
]
(3)调用 selectOtherList(lastId=2) 的结果:
传入 lastId=2,返回以 id=2 的子节点为起点的树(仅包含 id=2 的后代):
[{"id": 3,"level": 3,"childList": []}
]
(4)调用 selectOtherList(lastId=null) 的结果:
传入 lastId=null,查询 last_id=null 的节点(通常是一级节点),但返回的是这些一级节点的子树(不包含一级节点本身,仅包含它们的后代):
[{"id": 2, // 一级节点id=1的子节点"level": 2,"childList": [{"id": 3, ...}]}
]
3. 使用场景不同
selectTreeData:用于查询 “完整的树形结构”,适合在页面初始化时展示整个树(如左侧导航树、完整组织架构)。
selectOtherList:用于查询 “某个节点的子树”,适合动态加载场景(如点击某个节点后,仅加载其下的子节点,减少初始加载数据量)。
总结:核心区别表

简单说:selectTreeData 查 “全树”,selectOtherList 查 “某节点的子树”,两者是整体与局部的关系。