如何筛选并下载高质量Landsat影像:
0. 前言
Landsat是十分常用的卫星遥感数据,然而想要获取长时序云量较少的高质量遥感影像并不是非常方便。笔者结合已有知识和一些新的思考,提供一个比较高效的筛选方式,希望能够对有需求和感兴趣的伙伴们提供一个相对合理的解决方案,同时这也是笔者个人科研过程的一个记录。
本文中主要借助的方法和工具包括:
(1)方法:下载Landsat影像的快试图+人工目视解译
(2)工具:通过官方渠道“美国国家地质调查局USGS(https://earthexplorer.usgs.gov/)”下载Landsat遥感影像;浏览器插件“Web Scraper”用于批量获取快试图下载链接;电脑软件“IDM”批量下载快试图;保障正常访问的科学上网工具
1. 一个寻常的下载Landsat影像的流程
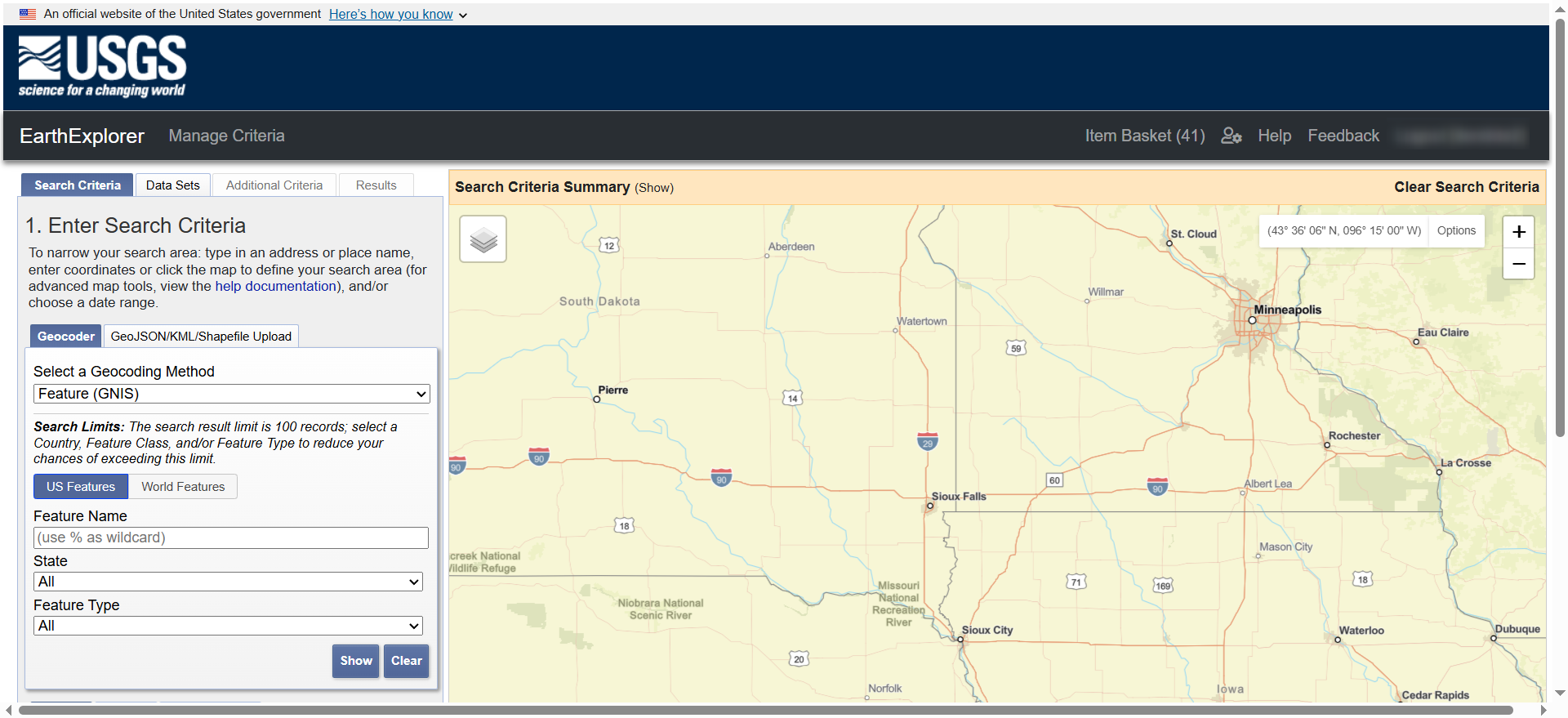
(1)首先访问USGS(https://earthexplorer.usgs.gov/),一般无需科学上网环境,考虑网络稳定性和时间段的问题还是建议代理一下网络。访问网址得到下图所示界面:
如果没有账号,可查看链接文章(https://blog.csdn.net/weixin_41512747/article/details/107565535),注册USGS账号并登录
(2)假设我们的期望是获取“长江口区域2025年8月所有Landsat8和Landsat9影像(即L1B级数据以自己做大气校正)”。这句话当中包含的信息有:一、研究区域:长江口;二、目标数据时间:2025年8月1日至2025年8月31日;三、影像数据集:Landsat8和Landsat9(目前在轨的两个)。
按照顺序,首先需要让USGS网站知道我们想要“哪个研究区域”的卫星数据。如下图所示,上传研究区域的.geojson文件或者.shp文件皆可。此处以上传.geojson为例,上传结束后,左侧显示研究区经纬度范围,地图自动跳转至研究区并显示.geojson文件确定的范围
|
|
|
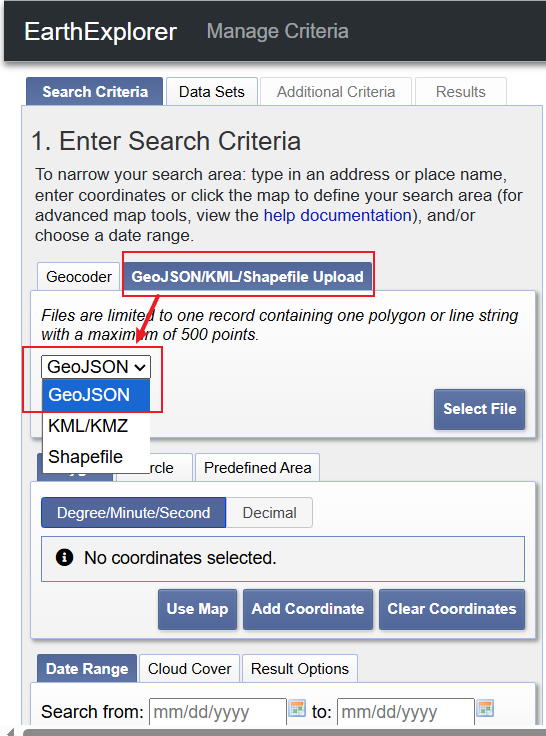
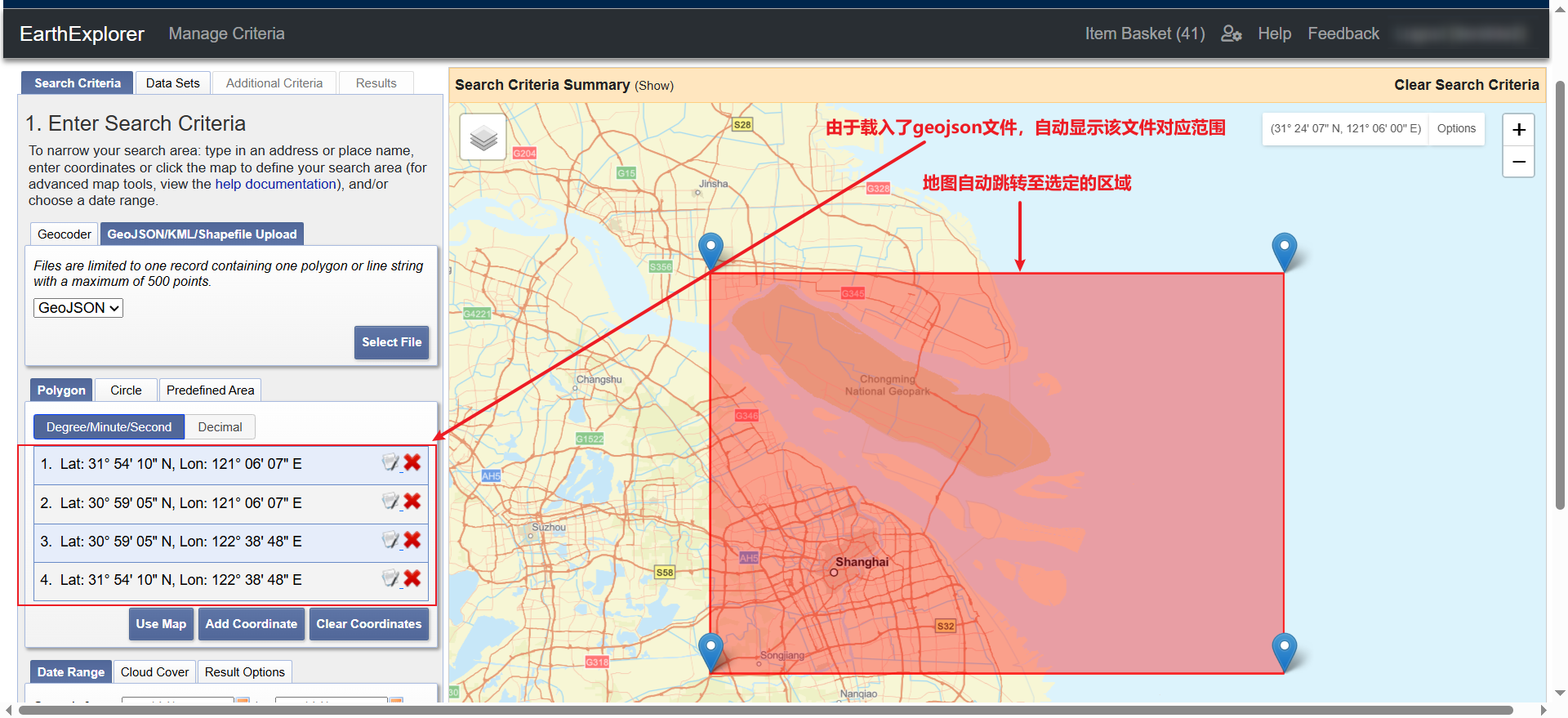
补充说明,对于一般的下载任务而言,通过手动在USGS提供的地图上绘制研究区多边形同样能过实现上述效果,但一个代表研究区的.geojson(或者.shp)文件在科学研究的其他环节中也是十分重要的。通过“geojson网站(https://geojson.io/)”可以绘制并下载自己研究区的geojoson文件,详细可参考链接(https://mp.weixin.qq.com/s/8vWCMYy_pkwauVkwZd3rYQ)
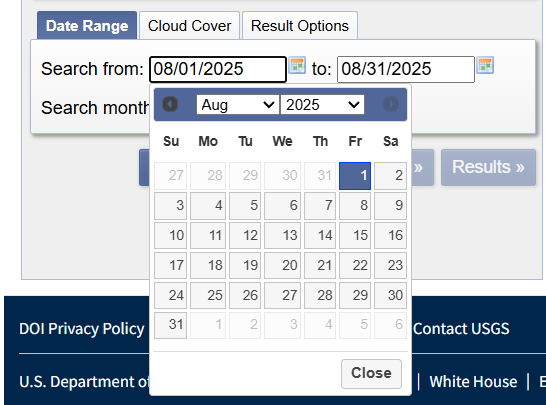
(3)在底部选项卡“Date Range”的“Search from”当中,输入时间范围信息即可,如下述左图,注意这里日期的表记方法为“月/日/年”。
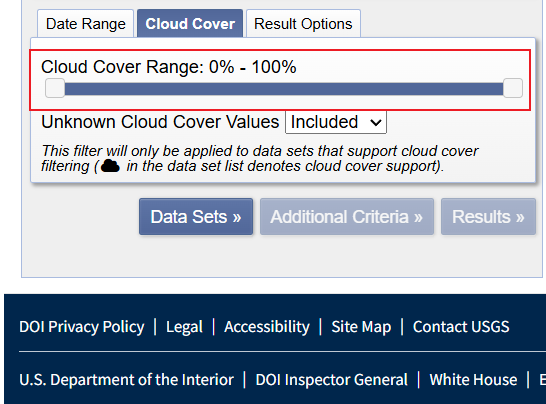
值得一提的是,虽然底部选项卡的“Cloud Cover”提供了确定“影像当中云量覆盖”的选项,这种方法会粗暴的按照云量的百分比筛选影像,但假使一幅多云的影像中我们感兴趣的区域恰好没有被云彩覆盖,使用这种筛选方式便很容易漏掉有效影像。为规避此,本文此处保持默认
|
|
|
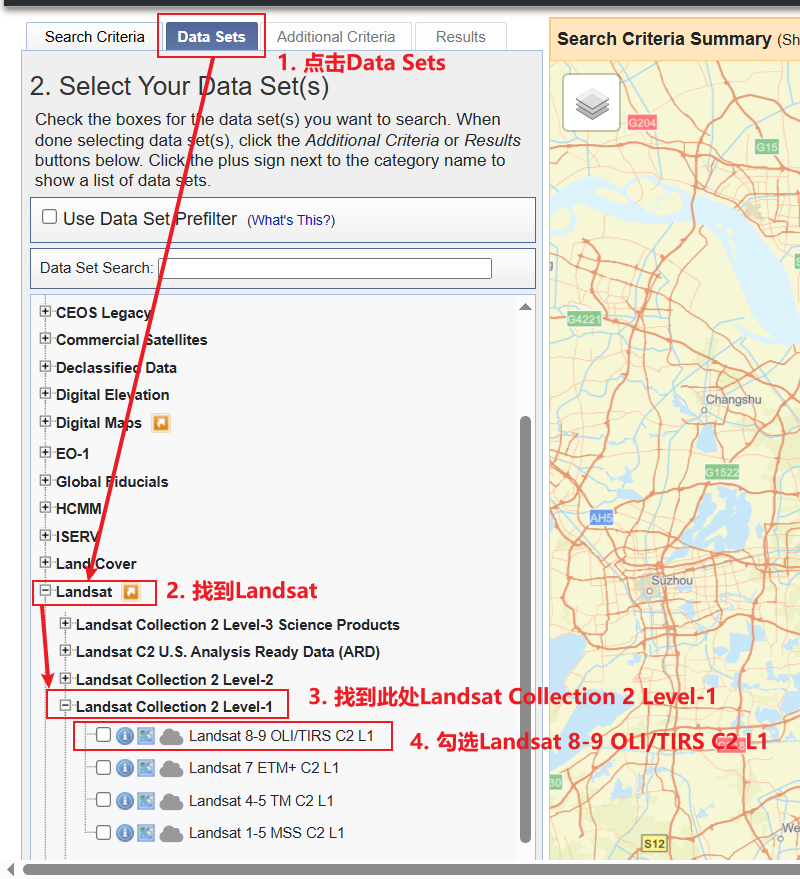
(4)上述步骤完成后点击顶部选项卡的“Data Sets”,按照下左图所示选择对应的Landsat影像数据,考虑到我们要自行大气校正,所以选择Level 1数据;如果打算直接利用Landsat的SR/Rrs数据,应该选择Level 2;而此处的Collection代表Landsat官方发布的产品集,Collection1已过时且被弃用,Collection2能够全面替代Collection1。
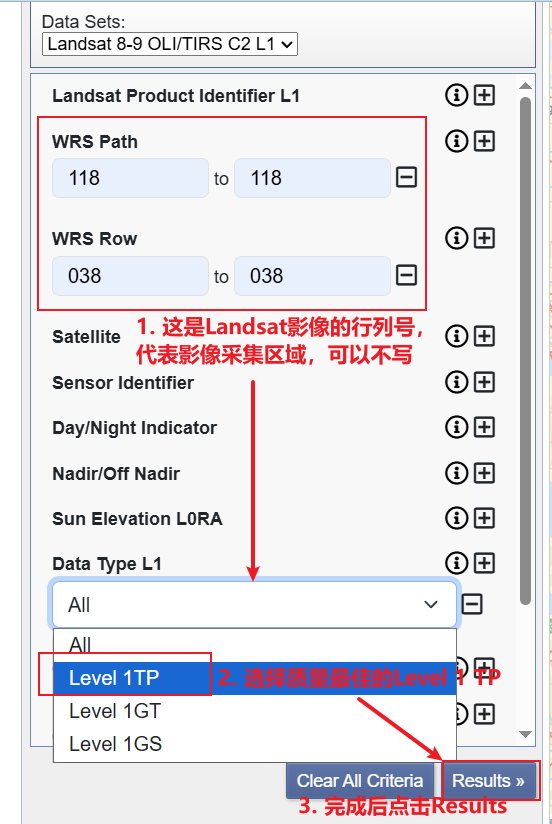
完成之后点击顶部/底部的“Additional Criteria”选项卡/按键,如下右图所示,在“WRS Path/WRS Row”当中代表Landsat影像采集区域的行列号(可以不写),并在下方“Data Type L1”当中选择“Level 1TP”,“TP”的数据质量要高于“GT”和“GS”。完成后点击底部按钮“Results”
|
|
|
(5)在“Search Results”当中查看当前筛选结果。2025年8月在长江口研究区当中一共有4幅影像。通常在面积相对较小的区域,Landsat8和Landsat9一个月影像总和大致在3~6幅。
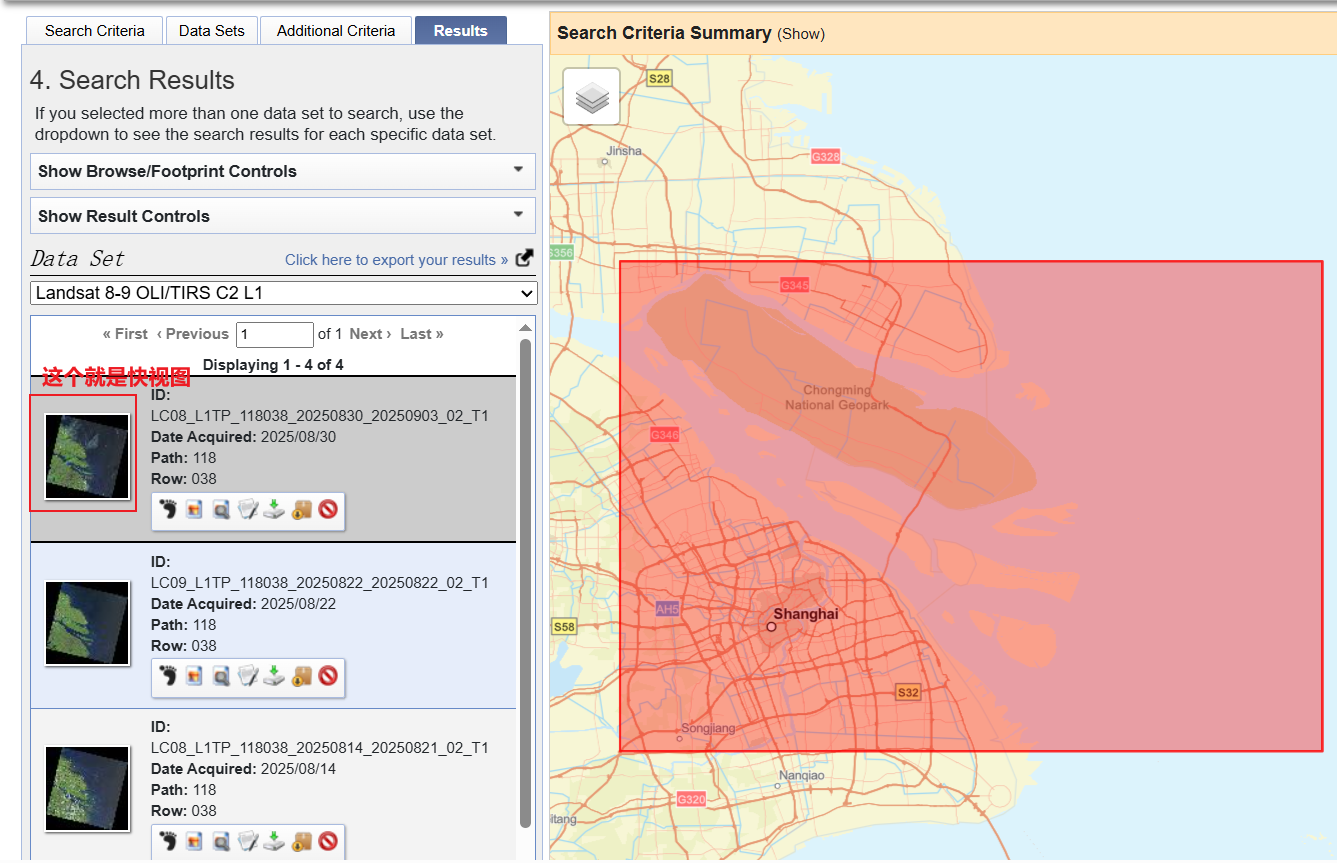
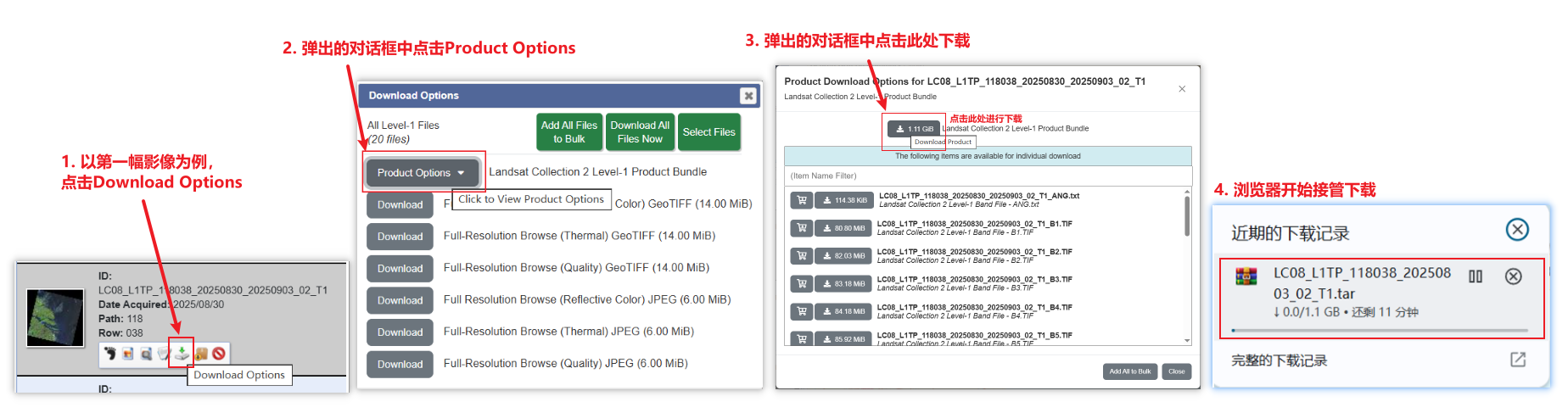
以第一幅影像为例的下载方式入下图所示,这里对新手友好的记录了下载方式。至此,一幅Landsat影像便可以下载啦
2. 通过目视识别快试图筛选所需影像
寻常的Landsat影像的下载网上已具备大量可行性好、操作友好的方法,然而在面对长时序、例如需要获取一个地区连续10年或以上Landsat影像时,面对大量的影像时进行逐个下载便不再快捷。
由于影像质量的好与坏是一个主观的判断,难以采用统一的指标量化。而通过人工目视观察快视图、以判断这幅影像是否是满足自己需要,便成为了一种可行的手段。基于这种想法,如果我们能批量下载一个地区10年所有的快试图,即可相对快速的筛选
(1)科学上网环境下,使用Chrome浏览器,访问“Chrome网上应用店(https://chromewebstore.google.com/search/Web%20Scraper?hl=zh-CN)”。顶部搜索栏搜索“Web Scraper”并安装
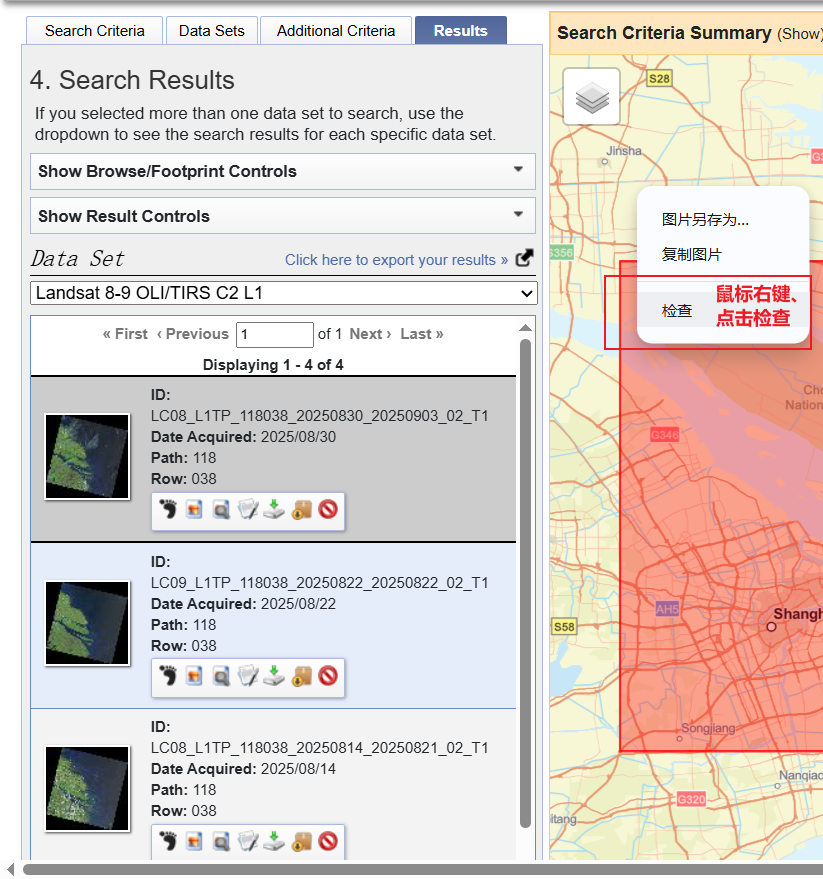
(2)返回USGS检索页面(该界面应当位于Chrome浏览器当中),此处仍以2025年8月的4幅影像及其快试图为例,在地图任意区域鼠标右键点击检查,弹出底部框中点击“Web Scraper”。Web Scraper是一个网络爬虫,功能强大,详细学习可参考B站其他up主发布的视频(https://www.bilibili.com/video/BV1LJ411t7Gi)
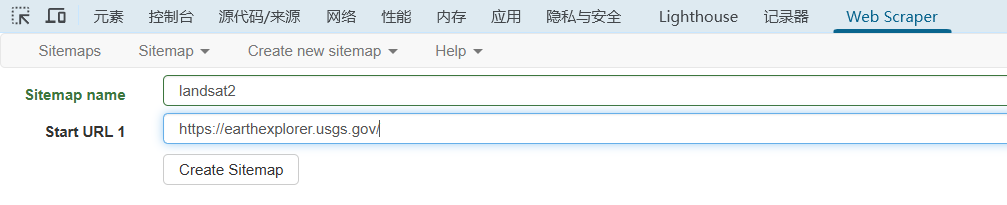
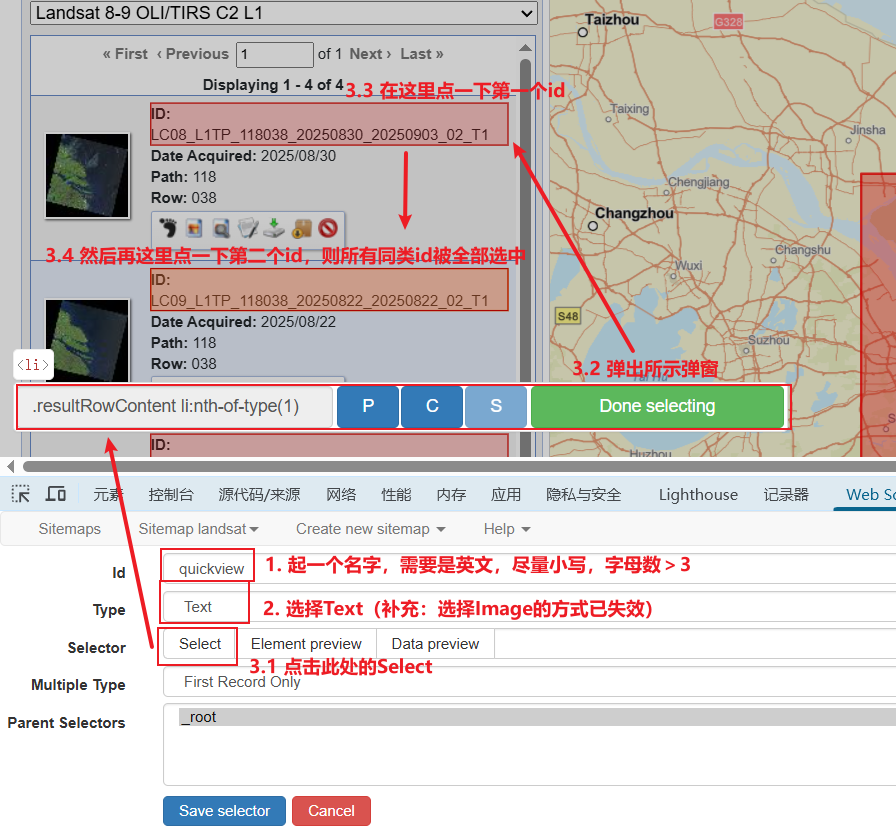
(3)在“Web Scraper”的“Create new sitemap”选择“Create Sitemap”。“Sitemap name”填写任意数量(需要大于3)的小写字母,以作为名称;在“Start URL 1”当中输入https://earthexplorer.usgs.gov/,即当前所在网站的地址,随后点击“Create Sitemap”。在当前显示页面点击“Add new selector”
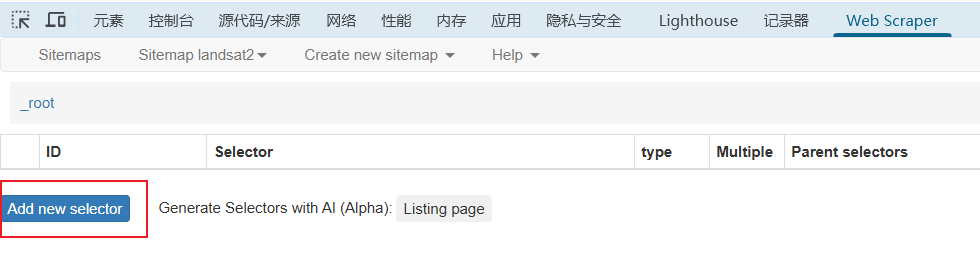
(4)如图所示,在下面窗口中id填入任意英文单词;Type选择Text(注:选择Image的方法已经失效)。而后点击Select,此后在Landsat影像的检索界面依次点击“第一个id”和“第二个id”,这样所有检索出来的id就都被“捕捉”了。“捕捉”完成后,点击绿色的“Done Selecting”。此后,按照第二张图所示切换“Multiple Type”,然后点击“Data Preview”
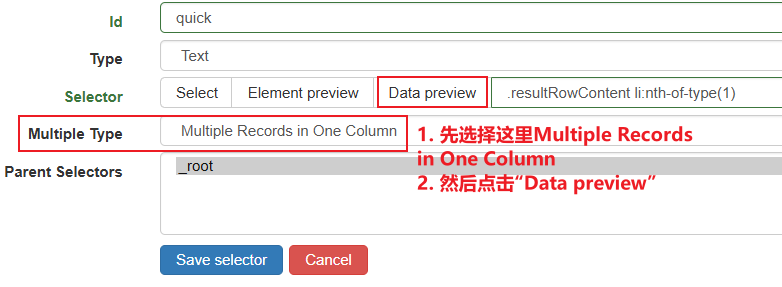
在“Data Preview”可以见到所有被“捕获的”影像id

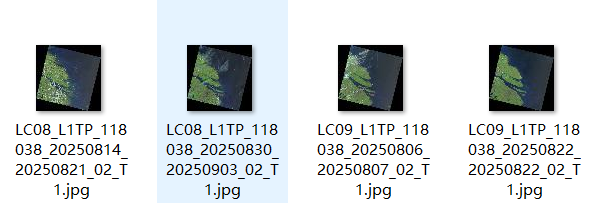
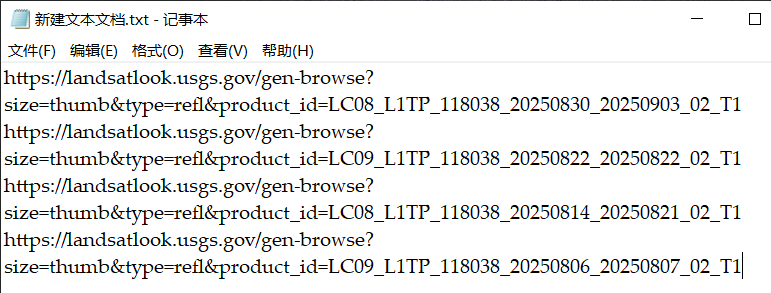
(5)一个Landsat影像快试图的下载链接如:(https://landsatlook.usgs.gov/gen-browse?size=thumb&type=refl&product_id=LC08_L1TP_118038_20250830_20250903_02_T1)。其中https://landsatlook.usgs.gov/gen-browse?size=thumb&type=refl&product_id=固定不变;而“LC08_L1TP_118038_20250830_20250903_02_T1”为影像id。在上个步骤中,由于我们已经获取了所有影像的id,因此把“固定不变”的部分和“每个id”拼接起来即可,这个操作可以借助Excel快速实现。把所有的“完整快视图下载路径”拼接好后,复制到一个文本文档(新建文本文档.txt)格式当中备用,如下图所示:
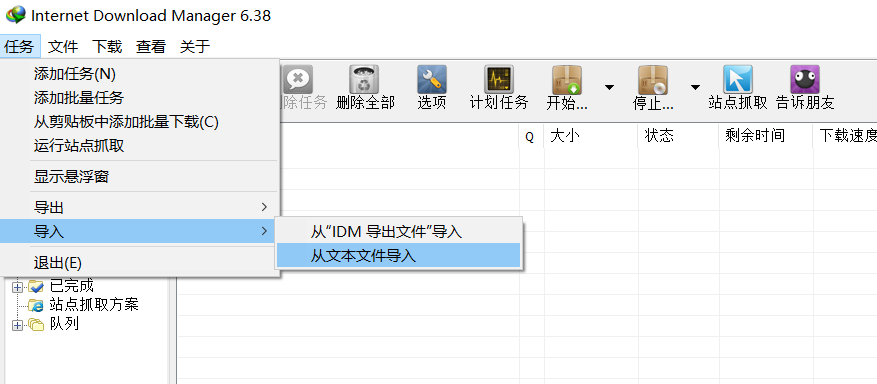
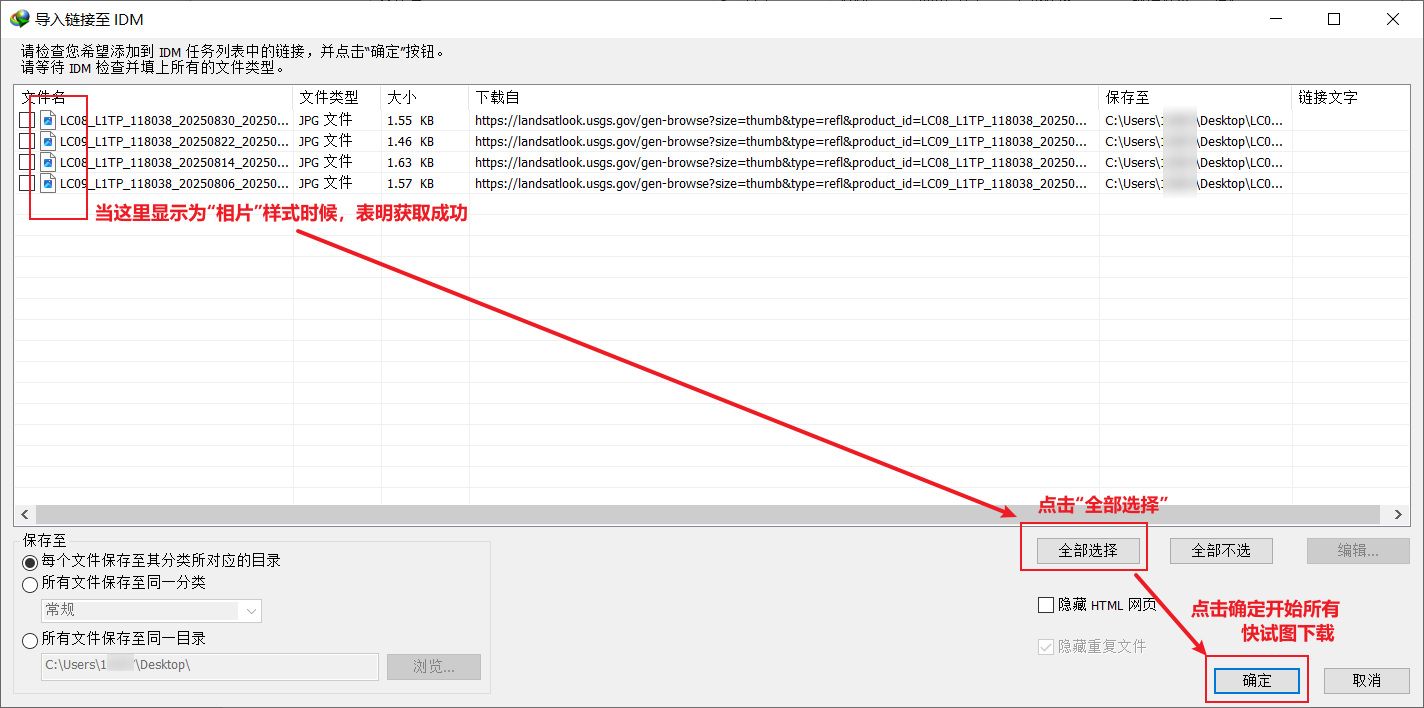
(6)调用IDM进行下载:启动IDM,依次点选“任务—导入—从文本文件导入”,选择“新建文本文档.txt”后弹出一个对话框,当所有链接的最左端显示是“相片”的样式时说明识别成功了,右下角依次点选“全部选择—确定”即可开始下载
(7)如下图所示所有快视图已经下载完毕。对那些快视图观察良好的,在USGS网站上下载即可