在 C# .NETCore 中使用 MongoDB(第 2 部分):使用过滤子句检索文档
在上一篇中,我们了解了一些驱动程序的基础知识以及如何将文档插入到集合中。在本系列的这一部分中,我们将学习如何从数据库中检索文档。
在 C# .NETCore 中使用 MongoDB(第 1 部分):驱动程序基础知识和插入文档:
https://blog.csdn.net/hefeng_aspnet/article/details/150556600
在 C# .NETCore 中使用 MongoDB(第 2 部分):使用过滤子句检索文档:
https://blog.csdn.net/hefeng_aspnet/article/details/150557025
在 C# .NETCore 中使用 MongoDB(第 3 部分):跳过、排序、限制和投影:
https://blog.csdn.net/hefeng_aspnet/article/details/150557338

如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。
任何文档都属于一个集合,因此所有 CRUD 操作都只作用于一个集合。要从集合中检索文档,我们可以使用Find、FindSync和FindAsync函数。
FindSync 和 FindAsync
FindSync和FindAsync都包含两个重载函数,每个函数包含三个参数。FindSync和FindAsync有点类似,只是FindSync是同步的,并且会阻塞直到调用完成。FindSync返回 ,IAsyncCursorwhileFindAsync返回 的任务IAsyncCursor。
什么是 IAsyncCursor
MongoDB 分批返回查询结果,并且批次大小不会超过 BSON 文档的最大大小。从 3.2 版开始,BSON 文档的最大大小为 16 MB。最大文档大小有助于确保单个文档不会使用过多的 RAM,或者在传输过程中占用过多的带宽。将文档添加到集合时也适用此限制,但为了存储更大的文档,MongoDB 已提供 GridFS API。对于大多数查询,第一批返回 101 个文档或刚好超过 1 MB 的文档,后续批次将为 4MB。可以覆盖默认批次大小,我们可以通过设置BatchSize的属性从驱动程序中执行此操作FindOptions,该属性作为第二个参数传递给任何 find 方法。所以基本上,游标是指向查询结果集的指针。
默认情况下,服务器会在游标闲置 10 分钟后或客户端耗尽游标时自动关闭游标。要覆盖此行为,您可以noTimeout在查询中使用类的 usingNoCursorTimeout属性指定标志FindOptions。但是,您应该手动关闭游标或耗尽游标。
驱动程序中IAsyncCursor的 代表一个异步游标。要访问文档,我们需要手动迭代游标。
检索文档
让我们构建第一个读取查询,以获取students数据库中集合中的所有文档。MainAsync使用以下内容更新该方法:
static async Task MainAsync()
{
var client = new MongoClient();
IMongoDatabase db = client.GetDatabase("school");
var collection = db.GetCollection<BsonDocument>("students");
using (IAsyncCursor<BsonDocument> cursor = await collection.FindAsync(new BsonDocument()))
{
while (await cursor.MoveNextAsync())
{
IEnumerable<BsonDocument> batch = cursor.Current;
foreach (BsonDocument document in batch)
{
Console.WriteLine(document);
Console.WriteLine();
}
}
}
}
任何 find 方法的第一个重载都需要 3 个参数;一个FilterDefinition用于定义查询过滤器的参数,一个用于FindOptions指定查询选项(例如游标超时、批量大小等)的可选参数,以及一个可选的cancellationToken。
在上面的代码中,我们通过向BsonDocument方法传递一个空值来指定一个空的过滤器定义。另一种写法是使用FilterDefinition<BsonDocument>.Empty来指示一个空的过滤器。使用空过滤器,我们基本上是在告诉它返回一个集合中的所有文档。之后,我们迭代游标以批量获取文档(MoveNextAsync在 while 循环中),并调用cursor.Current来获取当前批次中的文档,然后将其打印出来。
运行上面的代码应该会给我们提供该集合中已有的所有文档
{ "_id" : ObjectId("58469c732adc9f5370e50c9c"), "FirstName" : "Gregor", "LastName" : "Felix", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Physics", "Biology"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9d"), "FirstName" : "Machiko", "LastName" : "Elkberg", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Spanish"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9e"), "FirstName" : "Julie", "LastName" : "Sandal", "Class" : "JSS 1", "Age" : 25, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9f"), "FirstName" : "Peter", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
{ "_id" : ObjectId("58469c732adc9f5370e50ca0"), "FirstName" : "James", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
我们可以看到它与上一篇文章中添加的文档类似,但多了一个属性_id。所有集合都在此字段上拥有唯一的主索引,如果您在创建文档时未提供该属性,MongoDB 会默认提供一个。它的类型为ObjectId,并在 Bson 规范中定义。
为了演示FindOptions,我将添加一个选项,将批次大小限制为 2,然后在控制台中显示我们正在循环的批次。使用以下内容更新您的代码
FilterDefinition<BsonDocument> filter = FilterDefinition<BsonDocument>.Empty;
FindOptions<BsonDocument> options = new FindOptions<BsonDocument>
{
BatchSize = 2,
NoCursorTimeout = false
};
using (IAsyncCursor<BsonDocument> cursor = await collection.FindAsync(filter, options))
{
var batch = 0;
while (await cursor.MoveNextAsync())
{
IEnumerable<BsonDocument> documents = cursor.Current;
batch++;
Console.WriteLine($"Batch: {batch}");
foreach (BsonDocument document in documents)
{
Console.WriteLine(document);
Console.WriteLine();
}
}
Console.WriteLine($"Total Batch: { batch}");
}
并运行得到以下结果:
Batch: 1
{ "_id" : ObjectId("58469c732adc9f5370e50c9c"), "FirstName" : "Gregor", "LastName" : "Felix", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Physics", "Biology"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9d"), "FirstName" : "Machiko", "LastName" : "Elkberg", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Spanish"] }
Batch: 2
{ "_id" : ObjectId("58469c732adc9f5370e50c9e"), "FirstName" : "Julie", "LastName" : "Sandal", "Class" : "JSS 1", "Age" : 25, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9f"), "FirstName" : "Peter", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
Batch: 3
{ "_id" : ObjectId("58469c732adc9f5370e50ca0"), "FirstName" : "James", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
Total Batch: 3
我们也可以用更简洁、更干净的方式编写代码,通过调用ToListAsync或ForEachAsync从游标中获取所有文档并将其放入内存。有一些扩展方法IAsyncCursor可以执行此操作。以下是一些代码片段:
collection.FindSync(filter).ToList();
await collection.FindSync(filter).ToListAsync();
await collection.FindSync(filter).ForEachAsync(doc => Console.WriteLine());
collection.FindSync(filter).FirstOrDefault();
collection.FindSync(filter).FirstOrDefault();
await collection.FindSync(filter).FirstOrDefaultAsync();
从代码角度来看,这看起来简洁明了,但它的作用是强制所有文档驻留在内存中。在某些情况下,这可能并不理想,而当查询结果很大时,游标会很有帮助,我们可以通过调用MoveNextAsync或来移动游标MoveNext。
寻找
此方法与其对应方法类似,只是它返回一个IFindFluent接口。这是一个流畅的接口,它为我们提供了诸如Count、Skip 、Sort 和Limit等操作的简单语法(稍后会详细介绍)。IFindFluent我们还可以从中返回一个游标(通过在其上调用ToCursor或ToCursorAsync)或一个列表(通过调用ToList或)。使用以下代码,我们可以获取所有文档,并使用方法ToListAsync将它们打印到控制台。Find
await collection.Find(FilterDefinition<BsonDocument>.Empty)
.ForEachAsync(doc => Console.WriteLine(doc));
结果
{ "_id" : ObjectId("58469c732adc9f5370e50c9c"), "FirstName" : "Gregor", "LastName" : "Felix", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Physics", "Biology"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9d"), "FirstName" : "Machiko", "LastName" : "Elkberg", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Spanish"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9e"), "FirstName" : "Julie", "LastName" : "Sandal", "Class" : "JSS 1", "Age" : 25, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9f"), "FirstName" : "Peter", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
{ "_id" : ObjectId("58469c732adc9f5370e50ca0"), "FirstName" : "James", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
查找特定文档
大多数情况下,我们并不想检索所有文档,而是指定一个过滤器,返回与该过滤器匹配的文档。现在让我们看看如何在查询中指定过滤器。
使用 BsonDocument 或字符串
我们可以定义一个 BsonDocument 作为过滤器,查询将查找与文档中定义的字段匹配的文档。将以下代码添加到您的方法中并运行它以检索姓名为“Peter”的学生。
var filter = new BsonDocument("FirstName", "Peter");
await collection.Find(filter)
.ForEachAsync(document => Console.WriteLine(document));
我们只得到一份文件
{ "_id" : ObjectId("58469c732adc9f5370e50c9f"), "FirstName" : "Peter", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
你可能会有点困惑,因为这些方法接受一个,FilterDefinition但我们传入的是一个 BsonDocument 对象,它却没有报错。这是因为它会被隐式转换,我们也可以从字符串中执行此操作。要使用字符串,我们需要定义一个有效的 JSON 字符串来指定过滤器。我们可以使用下面的代码对字符串执行相同的操作,并且仍然会得到相同的结果:
var filter = "{ FirstName: 'Peter'}";
await collection.Find(filter)
.ForEachAsync(document => Console.WriteLine(document));
我们还可以指定比较运算符或逻辑运算符。例如,获取年龄为 23 岁的学生。我们可以按如下方式构建查询:
var filter = new BsonDocument("Age", new BsonDocument("$eq", 23));
或使用字符串
var filter = "{ Age: {'$eq': 23}}";
我们所做的就是为运算符添加一个标识符,在本例中是$eq。查看此页面以获取运算符列表及其功能。让我们用上面的代码之一运行我们的代码,看看它会返回年龄为 23 岁的学生。
{ "_id" : ObjectId("58469c732adc9f5370e50c9c"), "FirstName" : "Gregor", "LastName" : "Felix", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Physics", "Biology"] }
{ "_id" : ObjectId("58469c732adc9f5370e50c9d"), "FirstName" : "Machiko", "LastName" : "Elkberg", "Class" : "JSS 3", "Age" : 23, "Subjects" : ["English", "Mathematics", "Spanish"] }
使用 FilterDefinitionBuilder
您可以使用FilterDefinitionBuilder,它是 的构建器FilterDefinition。它提供了一套方法来构建查询,而Lt是其中之一,它指定了小于比较。因此,我们可以使用 定义一个过滤器,FilterDefinitionBuilder如下所示:
var filter = new FilterDefinitionBuilder<BsonDocument>().Lt("age", 25);
或者使用接受 LINQ 表达式的重载方法:
var filter = new FilterDefinitionBuilder<Student>().Lt( student => student.Age, 25);
另外,您可以使用静态Builders类来构建过滤器定义,并且此类还具有用于构建其他内容的静态辅助方法,例如投影定义、排序定义和其他一些内容。
var filter = Builders<BsonDocument>.Filter.Lt("age", 25);
var filter = Builders<Student>.Filter.Lt(student => student.Age, 25);
驱动程序还为过滤器定义重载了 3 个运算符。分别是and (&)、or (|)和not (!)运算符。例如,我们想要获取年龄小于 25 岁且名字为 Peter 的学生,我们可以使用构建器助手和&重载运算符构建此类查询,如下所示
var builder = Builders<BsonDocument>.Filter;
var filter = builder.Lt("Age", 40) & builder.Eq("FirstName", "Peter");
从而运行并获取单个文档
{ "_id" : ObjectId("58469c732adc9f5370e50c9f"), "FirstName" : "Peter", "LastName" : "Cyborg", "Class" : "JSS 1", "Age" : 39, "Subjects" : ["English", "Mathematics", "Physics", "Chemistry"] }
LINQ 表达式
我们还没有讨论的最后一部分是这些方法的重载,它们接受一个 LINQ 表达式作为参数。当我们拥有一个强类型对象时,我们可以使用 LINQ 表达式构建一个过滤查询。假设我们想要获取年龄小于 25 岁且名字不是 Peter 的学生,并打印出他们的名字和姓氏。我们使用以下代码来实现:
var collection = db.GetCollection<Student>("students");
await collection.Find(student => student.Age < 25 && student.FirstName != "Peter")
.ForEachAsync(student => Console.WriteLine(student.FirstName + " " + student.LastName));
我们将集合类型更改为Student并运行以下代码,控制台上出现错误:
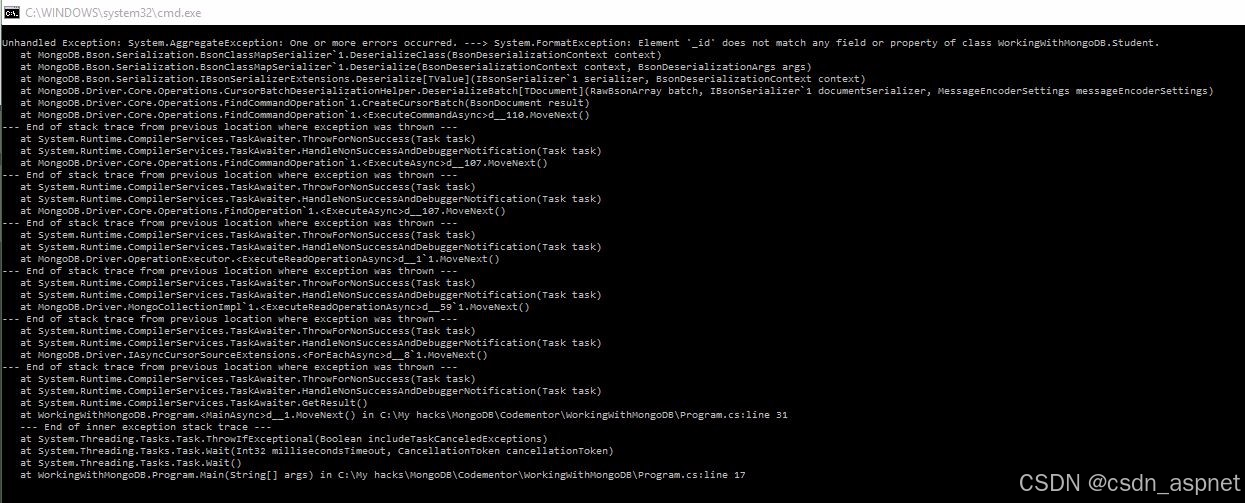
错误描述为“元素 ' id'与Student类型的任何字段或属性都不匹配” ,这是因为无法将_id数据库中的字段映射到 Student 类型的任何属性。这条错误信息在我们创建文档时自动添加。让我们通过添加一个在 MongoDB.Bson 包中定义的Student类型的属性来更新类型。ObjectId
class Student
{
public ObjectId Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public string Class { get; set; }
public int Age { get; set; }
public IEnumerable<string> Subjects { get; set; }
}
修改代码,也打印出ID并运行:
await collection.Find(student => student.Age < 25 && student.FirstName != "Peter")
.ForEachAsync(student => Console.WriteLine($"Id: {student.Id}, FirstName: {student.FirstName}, LastName: {student.LastName}"));
结果:
Id: 58469c732adc9f5370e50c9c, FirstName: Gregor, LastName: Felix
Id: 58469c732adc9f5370e50c9d, FirstName: Machiko, LastName: Elkberg
它确实有效。所以大多数情况下,你会想要使用表达式树语法来构建查询。有时,你想要更精细的查询,也可以使用其他方法。
在下一个教程中,我们将了解如何进行投影、排序、跳过、限制和排序。
如果您喜欢此文章,请收藏、点赞、评论,谢谢,祝您快乐每一天。