VideollaMA 3论文阅读

1.摘要
background
近年来,多模态大语言模型(MLLM)在图像理解方面取得了显著进展。然而,要将这种智能扩展到视频领域则更具挑战性。这主要是因为视频引入了复杂的时序维度,并且高质量、大规模的视频-文本标注数据集相比图文数据更难获取、质量也更低。现有的视频MLLM通常受限于此。因此,本文旨在解决如何有效构建一个同时精通图像和视频理解的、更先进的多模态基础模型的问题。
innovation
本文的核心设计哲学是“以视觉为中心 (vision-centric)”,这个理念体现在训练范式和框架设计两个方面。
1.视觉为中心的训练范式:不同于以往工作依赖海量视频数据,本文认为高质量的图文数据是实现卓越图像和视频理解的共同关键。因此,模型训练的前三个阶段都聚焦于利用大规模、高质量的图文数据来构建强大的通用视觉理解能力,在此基础上,最后一个阶段再专注于视频能力的提升。这样做的好处是充分利用了更容易获取且质量更高的图文数据,为视频理解打下了坚实的基础,这与那些早期就大量依赖视频数据的工作形成了鲜明对比。
2.视觉为中心的框架设计:
任意分辨率视觉令牌化 (Any-resolution Vision Tokenization, AVT):通过引入旋转位置编码(RoPE)替换传统ViT中的固定位置编码,使视觉编码器能够处理任意分辨率和宽高比的图像输入,从而捕捉更细粒度的视觉细节,减少信息损失。
差分帧剪枝器 (Differential Frame Pruner, DiffFP):针对视频中相邻帧之间信息冗余的问题,该模块通过计算相邻帧对应图像块的相似度,剪枝掉冗余的视觉令牌。这使得视频的表示更紧凑、更精确,并显著节省了计算资源。
2. 方法 Method
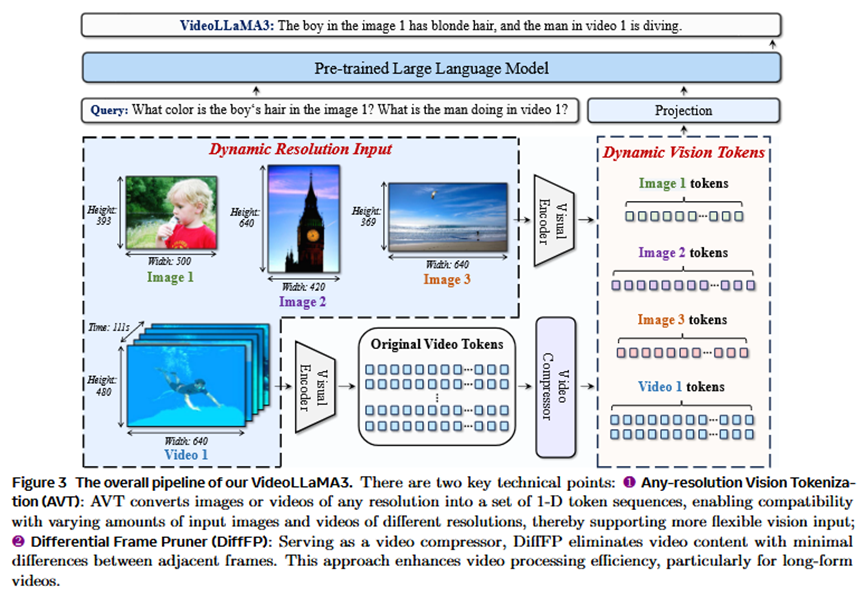
本文提出的VideoLLaMA 3模型,其整体流程(Pipeline)是“先通过大规模图文数据预训练,再通过视频数据微调”的四阶段训练范式。
模型由四个核心部分组成:一个视觉编码器(基于SigLIP初始化)、一个视频压缩器(即差分帧剪枝器DiffFP)、一个投影器(简单的MLP)和一个大语言模型(Qwen2.5系列)。
训练分为四个阶段:
1.视觉编码器适配 (Vision Encoder Adaptation)
目标:使视觉编码器能处理动态分辨率的图像,并将其特征与LLM对齐。
做法:冻结LLM,仅训练视觉编码器和投影器。使用海量的场景图像、文档和文本图像数据。
输入:各种分辨率的图像。
输出:一个能生成可变数量视觉令牌、适应不同图像尺寸的视觉编码器。
2.视觉-语言对齐 (Vision-Language Alignment)
目标:向模型注入丰富的多模态知识。
做法:解冻模型的所有参数(编码器、投影器、LLM),在覆盖场景、文档、图表等多种类型的高质量、精细描述的图文数据上进行联合训练。
输入:详细的图文对数据。
输出:一个具备基础多模态理解能力的模型。
3.多任务微调 (Multi-task Fine-tuning)
目标:提升模型的指令遵循能力,并初步建立视频理解能力。
做法:使用图文和视频的指令微调数据(Instruction SFT data)进行训练。在这一阶段开始引入视频数据,并应用**差分帧剪枝器(DiffFP)**来高效处理视频。
输入:包含图像和视频的指令问答数据。
输出:一个能理解复杂指令并具备初步视频分析能力的模型。
4.以视频为中心的微调 (Video-centric Fine-tuning)
目标:将模型打造成一个视频理解的“专家”。
做法:解冻所有参数,主要使用大规模、高质量的视频指令数据(包括通用视频、流媒体视频、时序定位视频等)进行微调。同时加入少量图文和纯文本数据以防止“灾难性遗忘”。
输入:以视频-文本数据为主,少量图文数据为辅。
输出:最终的VideoLLaMA 3模型。
3. 实验 Experimental Results
实验数据集
图像评测:涵盖四大类,包括1) 文档/图表/场景文本理解 (DocVQA, ChartQA, OCRBench), 2) 数学推理 (MathVista), 3) 多图理解 (MMMU), 4) 通用知识问答 (RealWorldQA, GQA, MME)。
视频评测:涵盖三大类,包括1) 通用视频理解 (VideoMME, MVBench), 2) 长视频理解 (MLVU, LongVideoBench), 3) 时序推理 (TempCompass, NextQA)。
实验结论
实验目的:全面评估VideoLLaMA 3在图像和视频理解任务上的性能,并与当前最先进的模型进行对比。
图像任务结论:无论是在2B还是7B规模上,VideoLLaMA 3在绝大多数图像基准测试中都取得了SOTA(State-of-the-Art)或极具竞争力的结果,尤其在OCR、数学推理和通用知识问答方面表现突出,超越了Qwen2-VL、InternVL2.5等强基线模型。
视频任务结论:模型同样展现了强大的视频理解能力。在通用视频问答、长视频理解和时序推理等多个核心维度上,均取得了SOTA性能,证明了其“视觉为中心”训练范式的有效性。
消融实验:为了验证视觉编码器的选择,论文对比了CLIP、DFN和SigLIP三个预训练模型。结果表明,SigLIP在各项任务中,尤其是在需要细粒度理解的文档问答(DocVQA)上,表现最优。这为选择SigLIP作为基础编码器提供了充分依据。
4. 总结 Conclusion
VideoLLaMA 3是一个在图像和视频理解方面均达到SOTA水平的强大基础模型。其成功的核心在于创新的“以视觉为中心”方法论:首先利用海量、优质的图文数据构建一个极其稳固的通用视觉理解地基,然后在此之上高效地扩展出顶尖的视频理解能力。这种策略巧妙地绕开了行业内视频数据稀疏且质量不高的普遍痛点。