flash attention利用GPU众核加速注意力计算
目前大量的LLM运行在GPU平台上,并基于flash attention优化响应速度。
这里参考Nvidia CUDA,学习和探索flash attention2的运行机制。
首先,介绍GPU并行架构,然后,说明如何将flash attention的任务映射到GPU。
1 gpu and cuda
GPU是目前运行LLM的主力设备,配置数万量级的并发处理单元。
CUDA是Nvidia为基于GPU的高性能计算开发的编程框架。
1.1 gpu cores
GPU并发处理单元,通常意义上分为SP(Streaming Processor)和SM(Streaming MultiProcessor)。
SP是最基本的处理单元,目前被叫做CUDA core。
SM,由多个SP组成,GPU架构不同SM包含的SP数量不同,如Pascal一个SM有128个SP。
SM还包括特殊运算单元(SFU),共享存储(shared memoery)、寄存器文件(Register File)以及调度器(Warp Scheduler)。寄存器和共享存储是速度达40TB/s的稀缺资源,限制每个SM中可以并发至下的活跃Warps的数量(Warp是CUDA中以SIMT方式并发执行的线程集合)。

1.2 thread-warp-block-grid
CUDA将GPU抽象为Grid、Block和Thread三个主要层次。
thread,一个CUDA并行程序由多个thread执行,thread是CUDA最基本的程序执行单元。
warp,一个warp通常包含32个thread,每个warp中的thread可以同时执行相同的指令,实现SIMT(单指令多线程)并行。warp是SM中最小的调度单位(the smallest scheduling unit on an SM),一个SM可以同时处理多个warp。
thread block,一个thread block可以包含多个warp,同一个block中的thread可以同步,也可以通过shared memory进行通信。thread block是GPU一次执行的最小单位。
grid,由多个thread block组成的二维或三维数组。grid的大小取决于计算任务的规模和thread block的大小,通常根据计算任务的特点和GPU性能来进行调整。
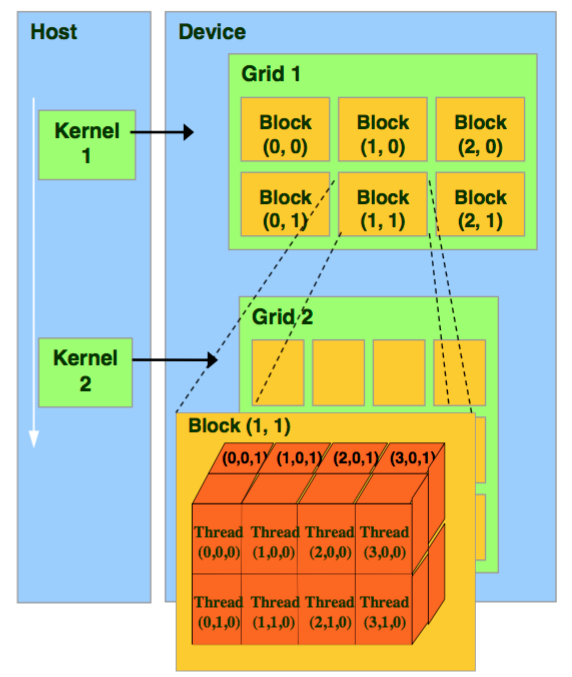
1.3 cuda on gpu
SM采用的是Single-Instruction Multiple-Thread(SIMT,单指令多线程)架构,warp是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
一个kernel被执行时,grid中的thread block被分配到SM上,大量thread可能被分到不同的SM上,但是一个线程块的thread只能在一个SM上调度,一个SM一般可以跑多个block。每个thread拥有自己的程序计数器和状态寄存器,并且可以使用不同的数据来执行指令,从而实现并行计算,这就是所谓的Single Instruction Multiple Thread。
一个SP可以执行一个thread,一个SM中的SP会被分成几个warp,由warp scheduler负责调度。warp中所有thread在同一周期执行相同的指令,尽管这些thread执行同一程序地址,但可能产生不同的行为,比如分支结构。一个SM同时并发的warp是有限的,由于资源限制,SM要为每个block分配共享内存,也要为每个warp中的thread分配独立的寄存器,所以SM的配置会影响其所支持的block和warp并发数量。
GPU有大量的threads用于执行kernel。这些thread组成了thread block,接着这些blocks被调度在SMs上运行。在每个thread block中,threads被组成了warps(32个threads为一组)。一个warp内的threads可以通过快速shuffle指令进行通信或者合作执行矩阵乘法。在每个thread block内部,warps可以通过读取/写入共享内存进行通信。每个kernel从HBM加载数据到寄存器和SRAM中,然后运行计算,最后将结果写回HBM中。
以下是cuda kernel示例,是运行在SP上的thread的程序。
__global__ void sum(float *a)
{int idx = blockDim.x*blockIdx.x+threadIdx.x;float val = a[idx];__shared__ float shared_mem[8];for (int offset = 16; offset > 0; offset /= 2) {val += __shfl_down_sync(0xffffffff, val, offset); }if(threadIdx.x%32==0) {shared_mem[threadIdx.x>>5]=val;}__syncthreads();if (threadIdx.x<=8) {val=shared_mem[threadIdx.x];val += __shfl_down_sync(0xffffffff, val, 4); val += __shfl_down_sync(0xffffffff, val, 2); val += __shfl_down_sync(0xffffffff, val, 1);if (threadIdx.x==0) {a[0]=val;}}
}调用kernel示例
func = mod.get_function("sum") # Obtain kernel
func(a_gpu, block=(256,1,1)) # Execute kernel with a single block of specified size2 flash attention
之前介绍了flash attention的计算过程和算法
https://blog.csdn.net/liliang199/article/details/151965572
这里从GPU并行计算角度,分析flash attention和flash attention2如何加速attention计算。
2.1 线程块并行
FlashAttention在batch和heads维度上并行化transformer中的注意力计算。
一般情况下,一个线程块(thread block)对应一个注意力头(attentijon head),所以一次运行需要的线程块数量为batch_size * head_num。
线程块是GPU一次并行执行的基础单位,每个线程块都需要调度到一个SM运行。所以当线程块数量很大时,GPU的SM资源就可以得到充分的利用。比如A100有108个SM,所以当batch_size * head_num很大,比如100时,所有的SM都可以得到充分的利用。
2.2 长序列并行
长序列输入,由于HBM限制,通常会减小batch size和head数量,可能导致SM资源利用率下降。
FlashAttention-2针对长序列输入,在序列长度维度进行并行化,一方面提升了计算速度,另一方面有助于提高GPU占用率。
2 3 warp并行
线程块运行的基础调度单位是warp。
FlashAttention算法有两个循环,K、V在外循环,Q在内循环,在一次内循环中,参考flash计算过程,不可能遍历所有的K和V,所以内循环结束时,l、m和o在scale后写会HBM,内循环开启钱再次从HBM读入shared memory,效率较低。
FlashAttention-2将Q移到了外循环,K、V移到了内循环,由于改进了算法使得warps之间不再需要相互通信去处理,所以外循环可以放在不同的thread block上,这样每个thread就会更轻量级,可以更有效的利用GPU的大量SM并发运行计算。
如下所示,flash attention在不同的warp之间分配工作,通常每个thread block中分配4或8个warp,如下图所示。
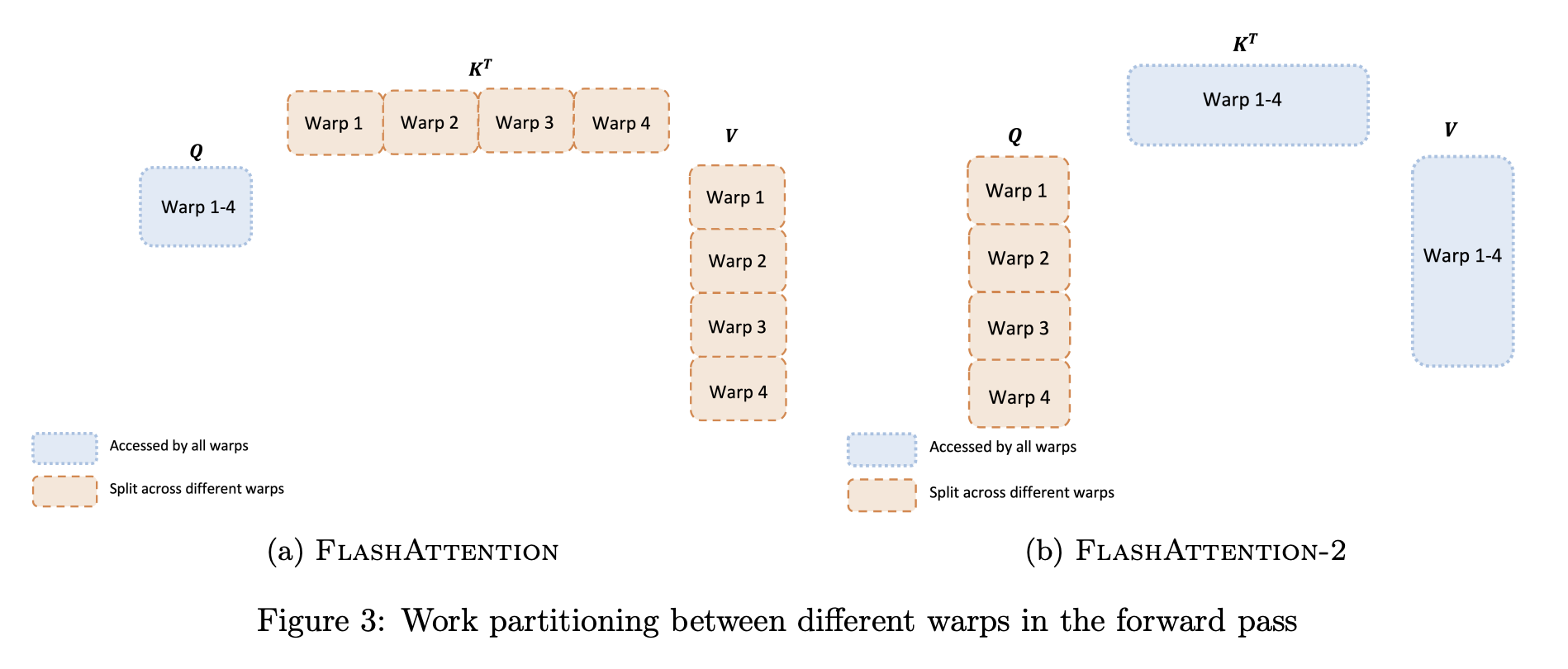
2.4 flashattention解读
外循环对K、V在输入序列N上遍历,内循环对Q在输入序列N上遍历。
对于每个block,FlashAttention将K和V分别分为4个warp,并且所有warp都可以访问Q。K的warp乘以Q得到S的一部分Sij,然后Sij经过局部softmax后还需要乘以V的一部分得到Oi。
然而,每次外循环j++都需要更新一遍Oi(上一次Oi先rescale再加上当前值),这导致每个warp需要从HBM频繁读Qi和写Oi以累加最后结果,这种方式低效的。以下是flash attention示例。

2.5 flashattention2解读
flashattention-2将Q移到了外循环,K、V移到了内循环,并将Q分为4个warp,所有warp都可以访问K和V。之前flashattention内循环i++会导致Oi变换,需要读取和写入HBM,现在内循环j++处理的都是Oi,在整个内循环跑完之前,oi可以一直存储在shared memory上,不需要写入HBM。以下是flashattention2算法。

reference
---
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
https://arxiv.org/pdf/2307.08691
CUDA Tutorial – Blocks and grids
https://blog.damavis.com/en/cuda-tutorial-blocks-and-grids/
flash attention2 计算过程的探索和学习
https://blog.csdn.net/liliang199/article/details/151965572
FlashAttention2详解(性能比FlashAttention提升200%)
https://zhuanlan.zhihu.com/p/645376942
CS 179: GPU Computing
https://courses.cms.caltech.edu/cs179/2021_lectures/cs179_2021_lec02.pdf