Pytorch框架笔记
微积分
对于一个多元函数,我们将其输入简化为一个一个向量。

说明:
对于所有A∈Rm×n\mathbf{A} \in \mathbb{R}^{m \times n}A∈Rm×n,都有∇xAx=A⊤\nabla_{\mathbf{x}} \mathbf{A} \mathbf{x} = \mathbf{A}^\top∇xAx=A⊤
Ax\mathbf{A} \mathbf{x}Ax是一个向量,而对于向量的求导是一个矩阵(因为这里向量的每个维度上都是一个多元函数),经过简单计算可以知道正好为A⊤\mathbf{A}^\topA⊤.
对于所有A∈Rn×n\mathbf{A} \in \mathbb{R}^{n \times n}A∈Rn×n,都有∇xx⊤Ax=(A+A⊤)x\nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} \mathbf{x} = (\mathbf{A} + \mathbf{A}^\top)\mathbf{x}∇xx⊤Ax=(A+A⊤)x

∇x∥x∥2=∇xx⊤x=2x\nabla_{\mathbf{x}} \|\mathbf{x} \|^2 = \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{x} = 2\mathbf{x}∇x∥x∥2=∇xx⊤x=2x
在上面这个公式中将E\mathbf{E}E带入A\mathbf{A}A,即可得到这个这个式子。
自动微分
为张量建立梯度
由上面数学推导可知,标量函数对一个向量求导的结果就是它的梯度。梯度的形状和这个用来求导的向量的形状是一样的。
深度学习框架为了存贮自动微分的结果,会为用于求导的张量(一维的话是向量)开辟一个同样的大小的内存空间
from mxnet import autograd, np, npxnpx.set_np()x = np.arange(4.0)# 通过调用attach_grad来为一个张量的梯度分配内存
x.attach_grad()
# 在计算关于x的梯度后,将能够通过'grad'属性访问它,它的值被初始化为0
x.grad
上述代码就是为张量分配了一个梯度。
为被求导函数建立计算图
现在的深度学习框架一般使用反向传播的方法计算梯度。而使用到的工具就是计算图。
框架会为被求导的函数构造一个计算图。
# 把代码放到autograd.record内,以建立计算图
with autograd.record():y = 2 * np.dot(x, x)
y
计算图的作用如下:

当需要求梯度时,程序就从后往前遍历计算图:

图的结点时操作,边是数据。程序会根据操作类型进行求导。
比如上图中遇到的第一个操作是乘法,就会保留c和d的因子。然后继续跟着图的反向传播继续链式求导。
最终会将结果保存在梯度当中。
非标量函数求梯度
比如向量函数,矩阵函数。
向量函数:

计算分离
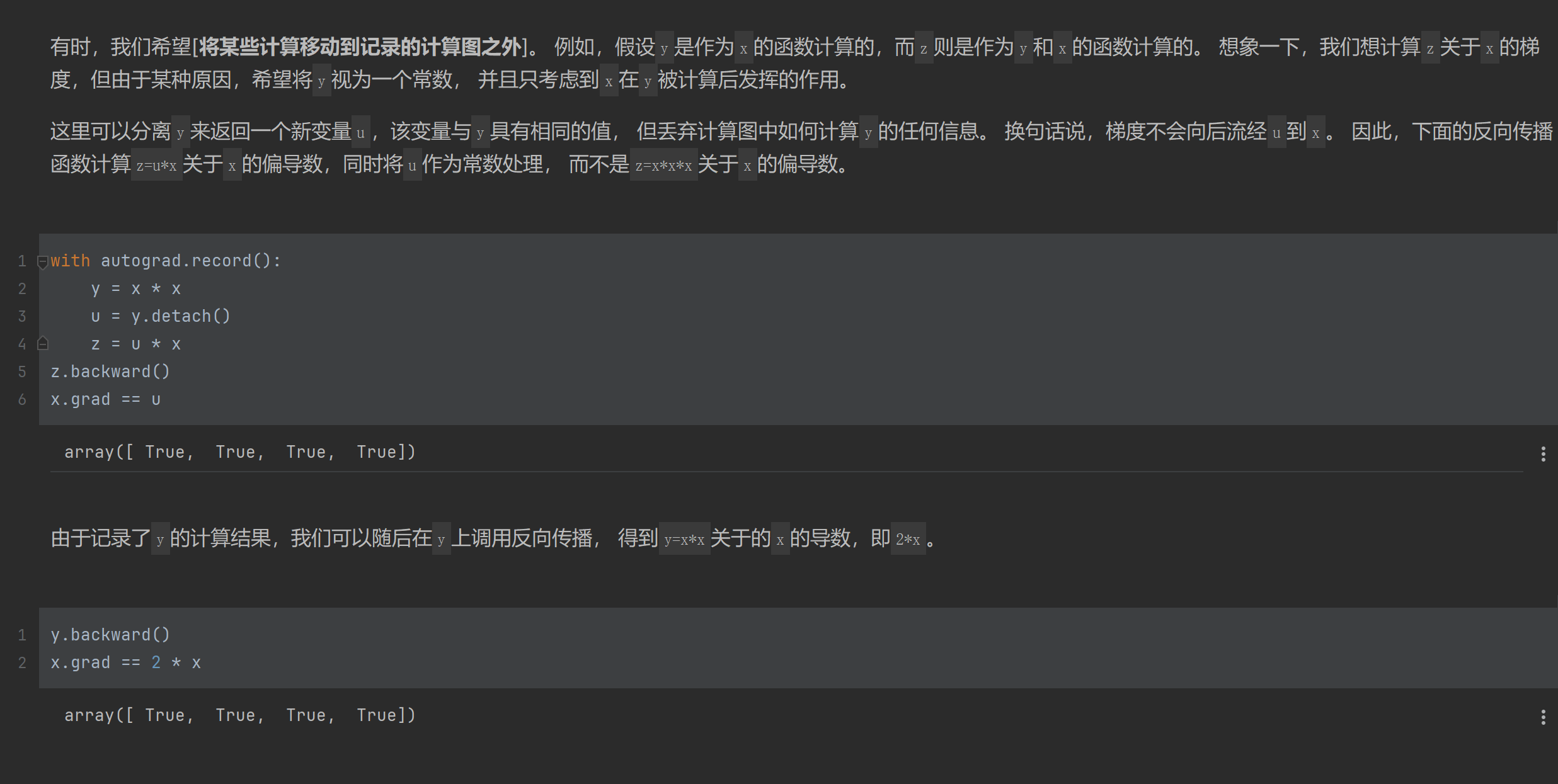
对于被求导的函数,可以将其部分作为一个整体冻结,求导的时候只作为一个常数。
Python控制流的梯度计算
在框架中,不仅能对数学上的函数做自动微分,还能对变成中的函数(python控制流如条件和循环)做自动微分。

这里构造了一个分段线性的函数,这不是个连续的函数,其每一段都是y = kx,但不同的区间中k不一样。
由此可以像最后这样表达来验证求导是不是有效的。
框架查询
查函数和类
import torchprint(dir(torch.distributions))
函数和类的用法
help(torch.ones)