LLMs之ThinkingModel:DeepSeek-V3.1的简介、安装和使用方法、案例应用之详细攻略
LLMs之ThinkingModel:DeepSeek-V3.1的简介、安装和使用方法、案例应用之详细攻略
目录
DeepSeek-V3.1的简介
1、DeepSeek-V3.1 的核心特点
(1)、混合思考模式 (Hybrid thinking mode)
(2)、更智能的工具调用 (Smarter tool calling)
(3)、更高的思考效率 (Higher thinking efficiency)
(4)、卓越的性能评测
(5)、专门的代理格式支持
2、模型性能
DeepSeek-V3.1的安装和使用方法
2、使用方法
(1)、使用示例 (Python Transformers)
(2)、聊天模板 (Chat Template) 详解
非思考模式 (Non-Thinking):
思考模式 (Thinking):
工具调用模式 (ToolCall):
DeepSeek-V3.1的案例应用
(1)、通用对话与内容创作
(2)、复杂问题解决与数学推理
(3)、与外部工具集成的自动化工作流
(4)、智能搜索与研究代理
(5)、高级软件开发助手
DeepSeek-V3.1的简介
2025年8月21日,DeepSeek团队发布DeepSeek-V3.1,并于9月22日更新。DeepSeek-V3.1 是一个混合模式的大型语言模型,它创新地在同一个模型中同时支持“思考模式”(Thinking Mode)和“非思考模式”(Non-Thinking Mode)。作为前一个版本的升级,它在多个方面都取得了显著进步。该模型是在 DeepSeek-V3.1-Base 的基础上进行后训练(post-trained)得到的。
其基础模型 DeepSeek-V3.1-Base 遵循了原始 DeepSeek-V3 技术报告中概述的方法,通过两阶段的长上下文扩展方法构建。开发团队通过收集额外的长文档,大幅扩展了两个训练阶段的数据量:32K 上下文扩展阶段的数据量增加了10倍,达到 6300 亿个 token;而 128K 上下文扩展阶段的数据量增加了3.3倍,达到 2090 亿个 token。
此外,DeepSeek-V3.1 在模型权重和激活值上均采用了 UE8M0 FP8 尺度数据格式进行训练,以确保与微缩放(microscaling)数据格式的兼容性。
DeepSeek 在 2025 年8月后,连续发布了两个关键版本,标志着模型从功能拓展到稳定优化的阶段演进。2025/08/21 发布的 DeepSeek V3.1 首次引入 Think / Non-Think 双推理模式,结合 128K 长上下文、Anthropic API 格式支持以及严格函数调用(Beta),显著增强了多步推理与工具调用能力,并通过持续预训练(840B tokens)扩展了上下文处理范围;同时在 SWE 与 Terminal-Bench 等任务中表现提升,奠定了 “Agent 时代” 的基础。随后,2025/09/22 的 DeepSeek V3.1-Terminus 更新 在 V3.1 的架构上针对用户反馈进行改进,重点解决语言一致性(减少中英文混杂与随机字符),并强化 Code Agent 与 Search Agent 的表现,整体输出在稳定性与可靠性上更进一步。目前该版本已在 App、Web 与 API 全面上线,并开放开源权重。
- 2025/08/21 → V3.1:引入 Think / Non-Think 双模式,API 支持扩展,Agent 能力显著增强,是进入“Agent 时代”的起点。
- 2025/09/22 → V3.1-Terminus:在 V3.1 基础上进行用户反馈优化,重点解决语言一致性和稳定性,同时增强 Code Agent 和 Search Agent。
Hugging Face地址:https://huggingface.co/deepseek-ai/DeepSeek-V3.1
1、DeepSeek-V3.1 的核心特点
(1)、混合思考模式 (Hybrid thinking mode)
模型最大的特点是仅通过更改聊天模板(Chat Template),就能在用于快速响应的“非思考模式”和用于复杂推理的“思考模式”之间切换,兼具效率与深度。
(2)、更智能的工具调用 (Smarter tool calling)
通过后训练优化,模型在使用工具(Tool Usage)和执行代理任务(Agent Tasks)方面的性能得到了显著提升。
(3)、更高的思考效率 (Higher thinking efficiency)
在“思考模式”下(DeepSeek-V3.1-Think),模型的回答质量与之前的 DeepSeek-R1-0528 模型相当,但响应速度更快。
(4)、卓越的性能评测
模型在通用、代码、数学和代理等多个领域的基准测试中表现出色,以下是部分评测结果摘要:
>> 通用能力 (General): 在 MMLU-Redux 上达到 93.7% 的准确率,在 GPQA-Diamond 上达到 80.1% 的 Pass@1。
>> 代码能力 (Code): 在 LiveCodeBench (Pass@1) 上取得了 74.8% 的高分,在 Aider-Polyglot 上准确率达到 76.3%。
>> 代码代理 (Code Agent): 在 SWE Verified (Agent mode) 测试中,性能达到 66.0%,远超前代模型。
>> 数学能力 (Math): 在 AIME 2024 (Pass@1) 上达到 93.1%,在 HMMT 2025 (Pass@1) 上达到 84.2%,展示了强大的数学推理能力。
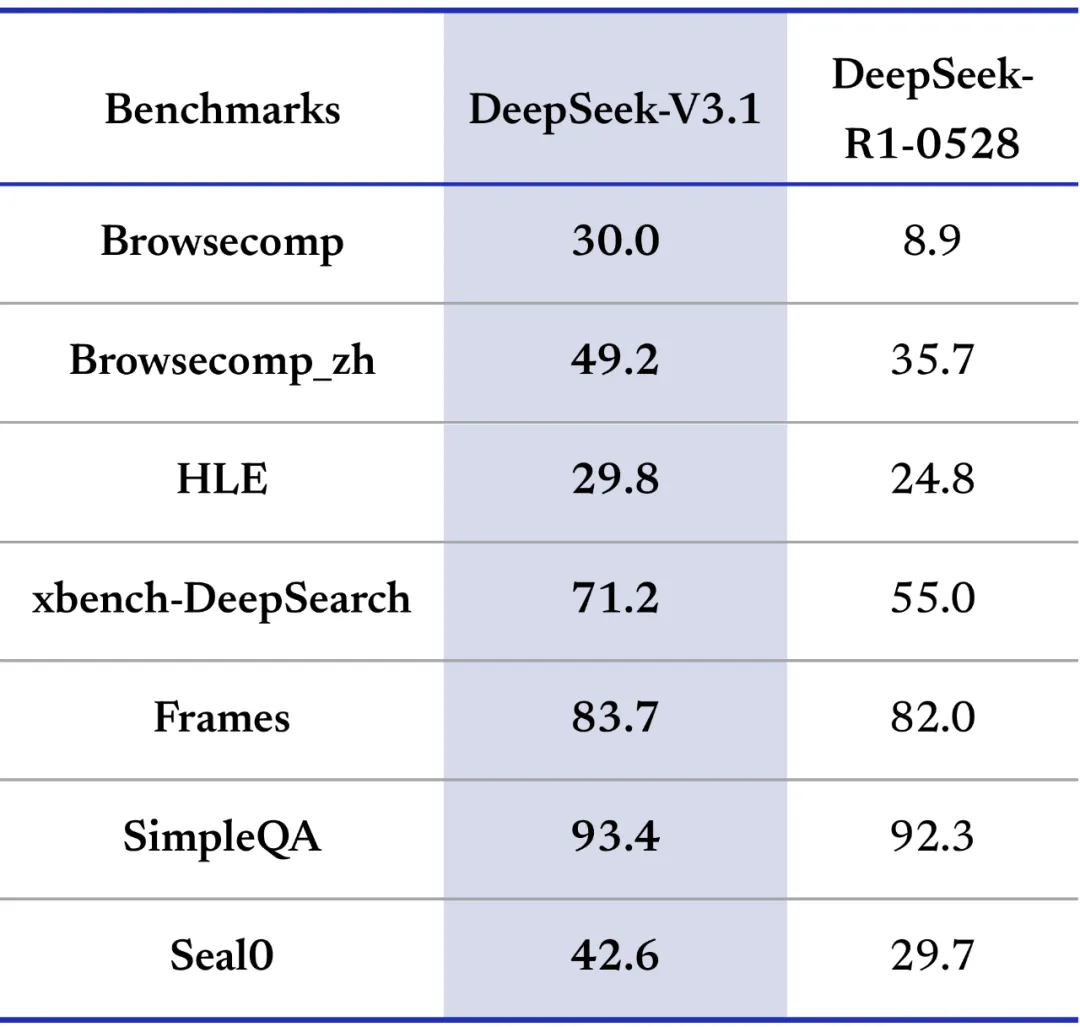
>> 搜索代理 (Search Agent): 在 BrowseComp 基准测试中得分 30.0,在中文对应的 BrowseComp_zh 中得分 49.2,显示了其强大的信息检索和整合能力。
(5)、专门的代理格式支持
>> 代码代理 (Code-Agent): 支持多种代码代理框架,并提供了标准的工具调用格式供用户创建自己的代码代理。
>> 搜索代理 (Search-Agent): 在思考模式下设计了特定的格式来支持搜索工具的调用,使其能够通过多轮工具调用来回答需要外部或最新信息的复杂问题。
2、模型性能
DeepSeek-V3.1:在基础推理、代码工程和长文本处理方面表现优异,是一个全面均衡的高性能模型
>> 基准测试全面领先
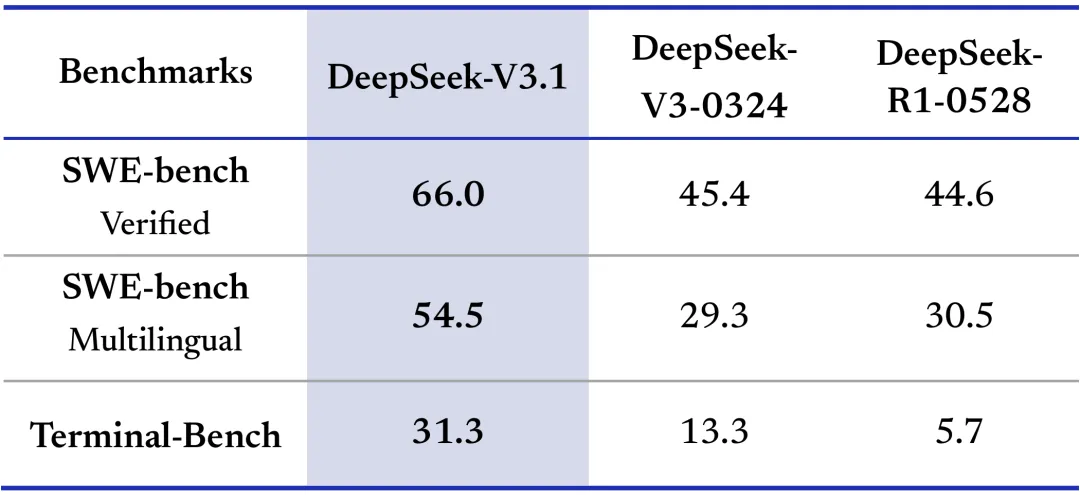
- SWE-bench(软件工程任务):V3.1的Verified得分(66.0)、Multilingual得分(54.5)均大幅高于DeepSeek-V3-0324和R1-0528
- Terminal-Bench(终端操作任务):V3.1以31.3分远超其他模型
- 通用与专业领域:在Browsecomp、xbench-DeepSearch等测试中,V3.1普遍取得更高分数,体现了跨场景的综合能力
>> 长文本生成效率突出:
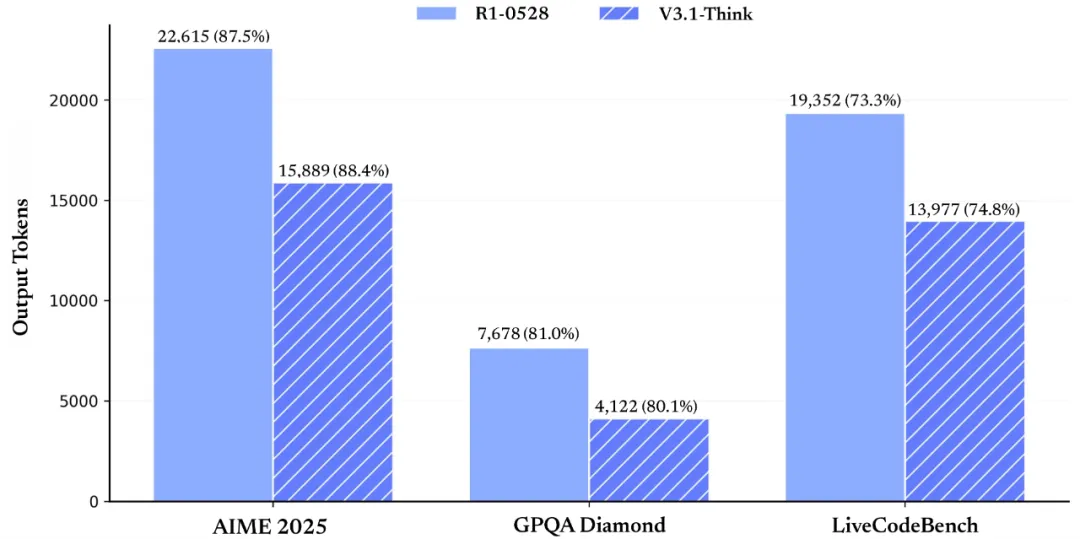
- 在AIME 2025、GPQA Diamond、LiveCodeBench等长文本任务中,V3.1-Think表现出色;
- 输出token占比(如88.4%、80.1%等)显示其能在高效生成的同时保持较高完成度
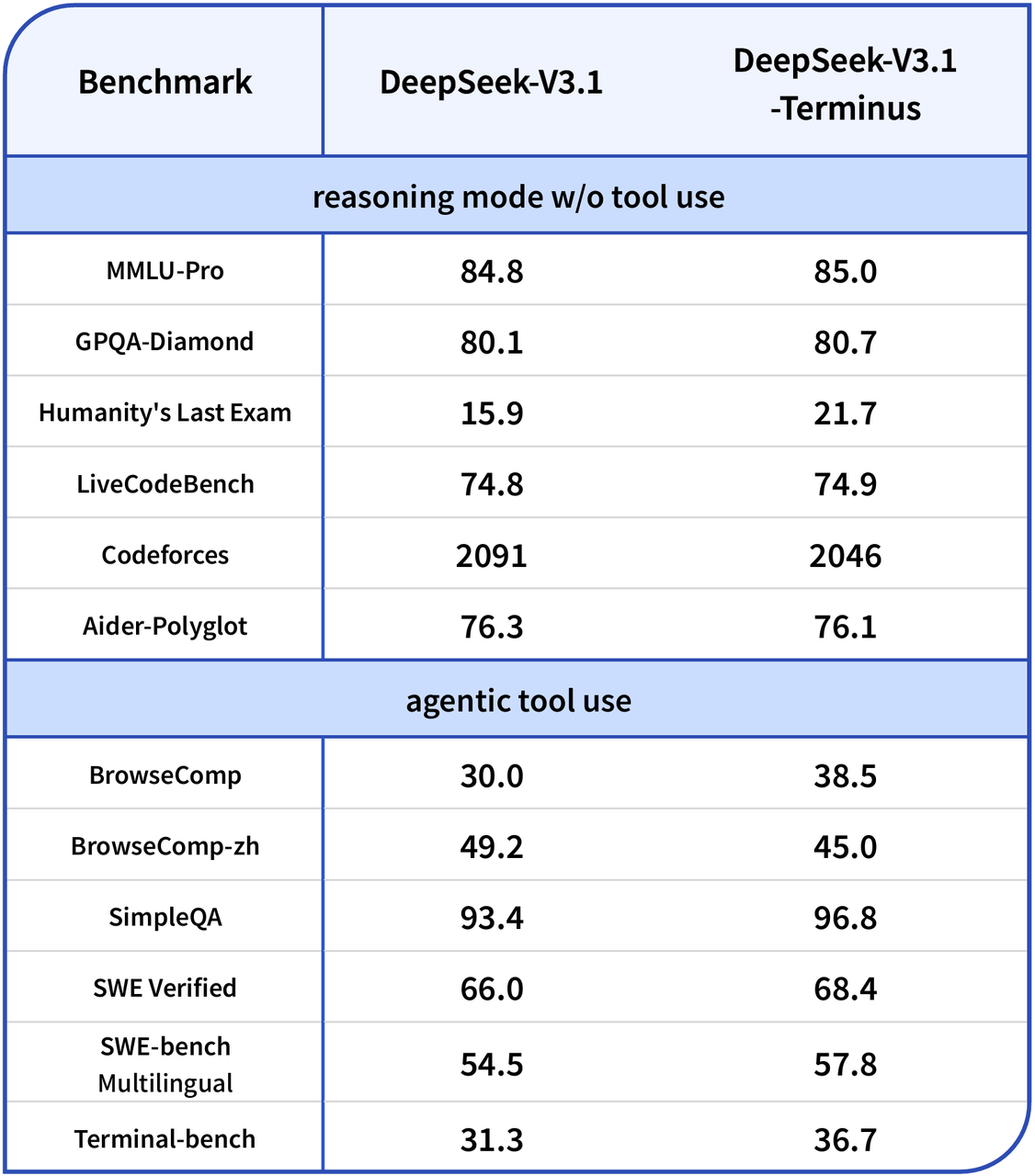
DeepSeek-V3.1-Terminus:在V3.1基础上进一步强化了工具协同能力和复杂问题解决能力,更适合需要实际应用和多工具协作的场景,是面向实际应用的升级版本
>> 复杂知识推理能力显著增强
- 跨学科知识整合:Humanity’s Last Exam得分从15.9提升至21.7(提升5.8分),在哲学、科学、历史等跨学科复杂知识处理方面表现突出
- 基础推理稳定提升:MMLU-Pro(84.8→85.0)、GPQA-Diamond(80.1→80.7)等基础推理能力均有小幅但稳定的提升
>> 工具协同效率大幅提升
- 网页浏览能力:BrowseComp得分从30.0提升至38.5(提升8.5分),网页信息检索和处理能力显著增强
- 终端操作优化:Terminal-bench得分从31.3提升至36.7(提升5.4分),系统操作和命令执行能力明显改善
- 问答准确性提升:SimpleQA得分从93.4提升至96.8(提升3.4分),问答质量大幅提高
- 多语言工程能力:SWE-bench Multilingual从54.5提升至57.8(提升3.3分),多语言编程和工程任务处理能力优化
DeepSeek-V3.1的安装和使用方法
1、安装
模型下载信息
模型名称: DeepSeek-V3.1
总参数量: 6710亿 (671B)
激活参数量: 370亿 (37B)
上下文长度: 128K
下载渠道: HuggingFace, ModelScope
2、使用方法
本地运行
DeepSeek-V3.1 的模型结构与 DeepSeek-V3 相同。因此,用户可以参考 DeepSeek-V3 的代码仓库获取关于如何在本地运行该模型的详细信息。
运行建议:
mlp.gate.e_score_correction_bias 参数应以 FP32 精度加载和计算。
确保 FP8 格式的模型权重和激活值使用 UE8M0 尺度格式。
(1)、使用示例 (Python Transformers)
可以通过 transformers 库轻松调用模型。核心在于使用 apply_chat_template 方法,并通过 thinking 参数来控制模式。
python
查看全部
{"role": "user", "content": "1+1=?"}
]
# 生成“思考模式”的提示
# 注意末尾的 <think> 标志
thinking_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
thinking=True, # 启用思考模式
add_generation_prompt=True
)
print(thinking_prompt)
# 输出: '<|begin of sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end of sentence|><|User|>1+1=?<|Assistant|><think>'
# 生成“非思考模式”的提示
# 注意末尾的 </think> 标志
non_thinking_prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
thinking=False, # 禁用思考模式
add_generation_prompt=True
)
print(non_thinking_prompt)
# 输出: '<|begin of sentence|>You are a helpful assistant<|User|>Who are you?<|Assistant|></think>I am DeepSeek<|end of sentence|><|User|>1+1=?<|Assistant|></think>'
(2)、聊天模板 (Chat Template) 详解
非思考模式 (Non-Thinking):
格式: 在助手的回答部分前加上一个空的思考标签 </think>。
示例: <|User|>{query}<|Assistant|></think>
作用: 指示模型进行快速、直接的回答。
思考模式 (Thinking):
格式: 在助手的回答部分前加上思考标签 <think>。
示例: <|User|>{query}<|Assistant|><think>
作用: 指示模型进行深入的、一步一步的推理,然后再生成最终答案。
工具调用模式 (ToolCall):
在非思考模式下支持,需要提供工具描述。
格式: 模型会生成特定格式的调用指令,如:<|tool calls begin|><|tool call begin|>{tool_name}<|tool sep|>{arguments}<|tool call end|><|tool calls end|>。
DeepSeek-V3.1的案例应用
根据模型的特点和评测表现,DeepSeek-V3.1 可广泛应用于以下场景:
(1)、通用对话与内容创作
在“非思考模式”下,模型可以快速响应,胜任客服、聊天机器人、文案生成等多种通用任务。
(2)、复杂问题解决与数学推理
凭借其强大的“思考模式”和在 AIME、HMMT 等数学竞赛基准上的优异表现,该模型非常适合用于科学研究、工程计算和高难度的数学问题求解。
(3)、与外部工具集成的自动化工作流
强大的工具调用能力使其可以作为自动化工作流的核心大脑,通过调用外部 API 或工具来完成预订、查询数据库、控制智能家居等复杂任务。
(4)、智能搜索与研究代理
其“搜索代理”模式专门为需要访问最新外部信息的复杂问题而设计。它可以利用搜索引擎,过滤网页内容,并结合其 128K 的长上下文窗口来提供全面、准确的答案,适用于研究、市场分析和报告撰写等场景。
(5)、高级软件开发助手
模型在 LiveCodeBench、Codeforces 和 SWE-bench 上的高分证明了其在代码生成、理解、调试和跨语言编程方面的强大能力。可以作为高级编程助手,或在“代码代理”模式下自主完成软件开发任务。