MySQL笔记9
一、SQL编程
1.存储过程
(1)概念
存储过程(Stored Procedure)是一组为完成特定功能的SQL语句集合。它将常用且复杂的SQL语句预先编写,以指定名称存储在数据库中,且经过MySQL的编译解析、执行优化。使用时只需按名称调用即可。
简单来说,存储过程是功能强大的SQL语句集,可实现复杂逻辑功能,类似于Java语言中的“方法”,是SQL语言层面的代码封装与重用。
存储过程和函数的区别:
对比项 | 存储过程 | 函数 |
返回值 | 无返回值 | 必须有返回值 |
参数类型 | 支持IN、OUT、INOUT类型 | 仅支持IN类型 |
(2)优点
复用性:创建后可在程序中反复调用,无需重复编写SQL语句;库表结构更改时,仅需修改数据库中的存储过程,不影响应用程序源代码。
灵活性:可通过流程控制语句编写,支持定义变量,能完成复杂条件查询和繁琐运算,比普通SQL语句更具代码编写的自由度。
省资源:存储在MySQL中,客户端调用时仅需传输调用语句和参数,无需传输大段SQL,降低网络负载。
高性能:多次执行后会将SQL编译为机器码驻留在线程缓冲区,后续调用直接执行机器码,无需再次编译,提升系统效率和性能。
安全性:可针对不同存储过程设置执行用户权限,例如仅允许root、admin执行清空表等特殊操作;且对客户端而言是黑盒,减小SQL暴露风险。
(3)缺点
CPU开销大:若存储过程包含大量逻辑运算,会使MySQL服务器CPU飙升,影响正常业务执行,甚至导致MySQL线上抖动。因为MySQL更擅长数据存储和检索,而非计算性任务。
内存占用高:为提升执行效率,MySQL会将频繁调用的存储过程机器码放入连接的线程私有区,大量连接频繁调用时会导致内存占用率大幅上升。
维护性差:一方面复杂的存储过程对普通后端开发人员来说难以理解,其语法类似于新语言,与常用开发语言跨度大;另一方面MySQL存储过程不支持Debug调试,出现Bug时需“人肉排查”,逐步拆解存储过程来定位问题。
(4)创建和调用
定义:
delimiter 自定义结束符号
create procedure 储存名([IN | OUT | INOUT]参数名 类型...)
begin
SQL语句 ;
end 自定义结束符号//
delimiter
调用:
call 存储过程名(实参列表)
# 注1:自定义符号可以用除了分号的符号,一般用$$ 或 //
# 注2:存储过程的参数形式:
IN 输入参数
OUT 输出参数
INOUT 输入输出参数
SHOW PROCEDURE STATUS; # 查看当前数据库中的所有存储过程。
SHOW PROCEDURE STATUS WHERE db = '库名' AND NAME = '过程名'; # 查看指定库中的某个存储过程。
SHOW CREATE PROCEDURE 存储过程名; # 查看某个存储过程的源码。
DROP PROCEDURE 存储过程名; # 删除某个存储过程。
注:
在MySQL的存储过程中,DELIMITER 的作用是改变执行语句的分隔符。
在MySQL中,DELIMITER 是用于指定命令是否结束的符号,默认情况下是分号;。
但在编写存储过程、函数或其他SQL代码块时,可能会遇到需要在一行或多行中编写包含分号的语句,而默认的分号作为语句结束符会导致MySQL在遇到分号时立即执行语句,而不是等待整个代码块输入完成后再执行。为了解决这个问题,可以使用 DELIMITER 命令来更改默认的分隔符,例如将分隔符更改为 // 或 $$ 这样MySQL就会将 // 或 $$ 之后的分号视为代码块的结束,而不是单个语句的结束。
这种做法在定义存储过程、函数或其他数据库对象时特别有用,因为它允许开发者在一个代码块中编写多个语句,而不需要为每个语句后都加上分号。当代码块编写完成后,可以通过将 DELIMITER 命令设置回默认的分号来恢复正常的语句执行方式。
例如,在创建存储过程之前,可能会使用 DELIMITER // 命令将分隔符更改为 // ,然后在存储过程的定义中使用多个包含分号的语句。当存储过程定义完成后,使用 DELIMITER 命令将分隔符恢复为默认的分号,以便后续可以正常执行单个SQL语句。
这种机制使得在编写复杂的数据库对象时更加灵活和方便,避免了因为语句中包含分号而导致的不必要的执行错误。
示例:
使用存储过程,插入多条数据:
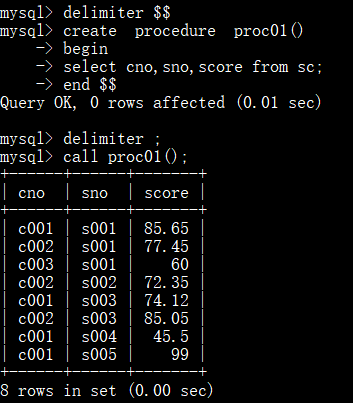
删除存储过程:
drop procedure 过程名;
![]()
(5)参数传递
IN:表示传入的参数, 可以传入数值或者变量,即使传入变量,并不会更改变量的值,可以内部更改,仅仅作用在函数范围内。
示例:
创建p1存储过程,实现批量向表中插入指定数量的“数字+MD5加密值”数据
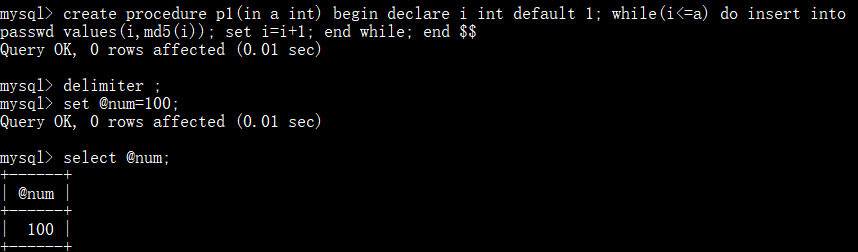
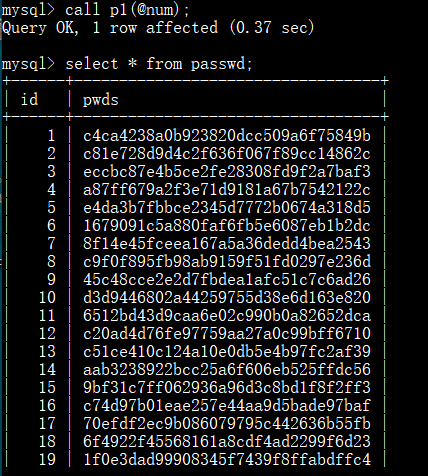
out:表示从存储过程内部传值给调用者,in的反向传递
示例:
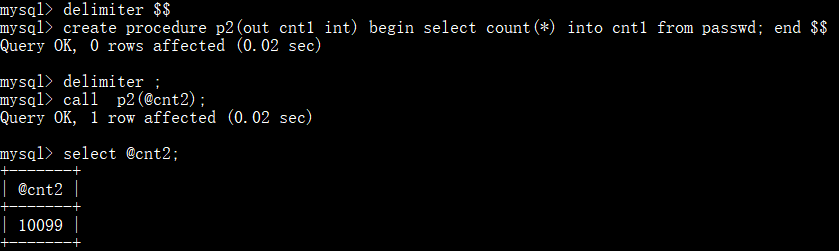
in+out 的综合使用
示例:
先建好一个数据库及两张表:
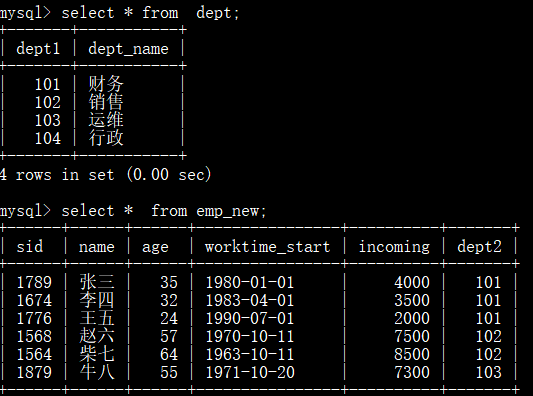
统计指定部门的员工数:
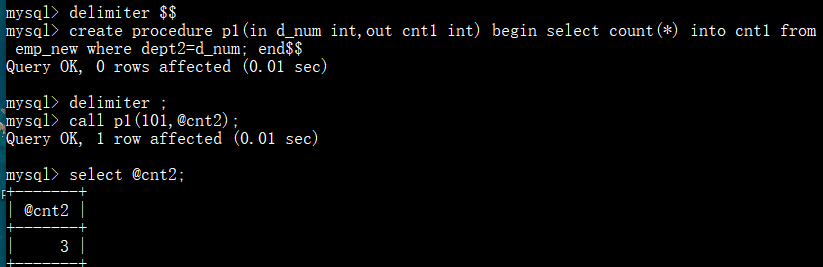
统计指定部门工资超过5000的总人数:
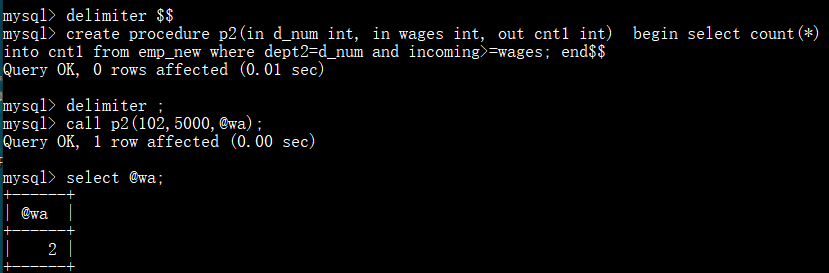
inout:
示例:
当变量 p1 不为 null 结果加1,否则直接赋值为100:
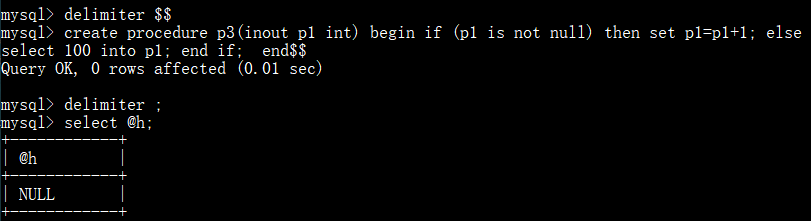
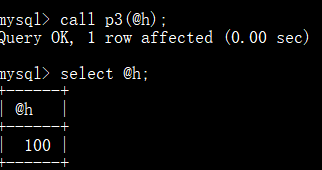
当变量 p1 为 null 直接赋值为100,否则结果加1:
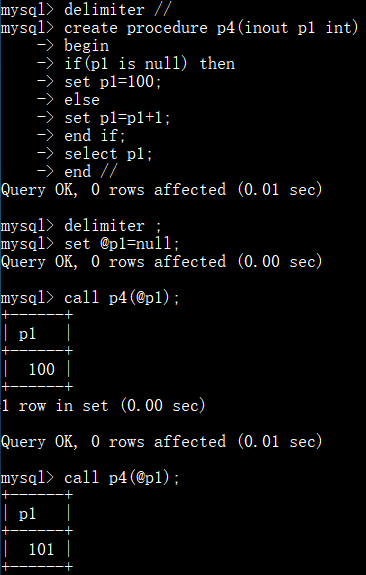
总结:
in :输入参数,意思说你的参数要传到存储过程的过程里面去,在存储过程中修改该参数的值不能被返回
out :输出参数:该值可在存储过程内部被改变,并向外输出
inout :输入输出参数,既能输入一个值又能传出来一个值
(6)应用场景
使用限制:
存储过程维护难度大,拓展性和移植性差,多数开发规范(如《阿里开发手册》)强制禁止使用。
推荐使用场景:
批量插入测试数据:相比Java的for循环批量插入,存储过程无需频繁传递、解析SQL,效率显著更高。
数据批处理:例如将一张表的数据清洗、迁移到另一张表时,适合用存储过程处理。
复杂业务逻辑实现:当单条SQL无法完成,且需要多步骤逻辑(或长SQL组合)时,可编写存储过程供客户端调用。
2.流程控制
(1)if判断
IF语句包含多个条件判断,根据结果为TRUE、FALSE执行语句,与编程语言中的if、else if、else语法类似,其语法格式如下:
if 条件判断 then
-- 分支操作.....;
else if 条件判断 then
-- 分支操作.....
else
-- 分支操作.....;
end if;
示例:
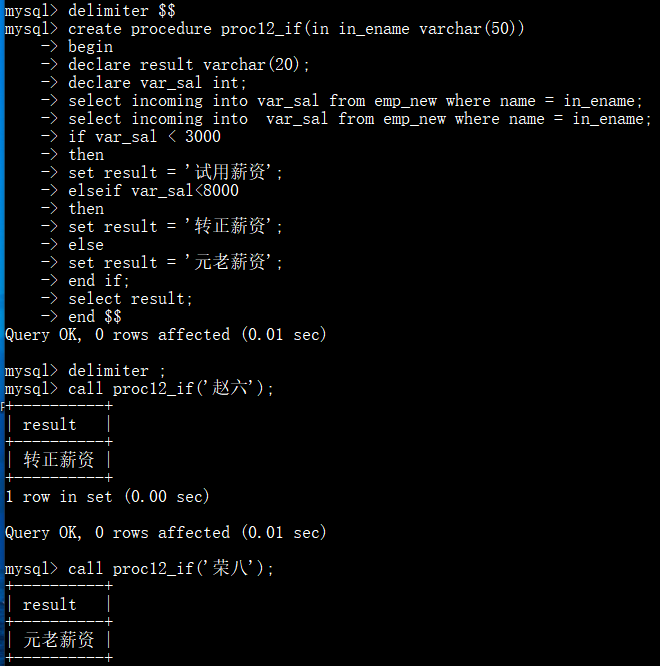
定义一个判断年龄的存储过程:
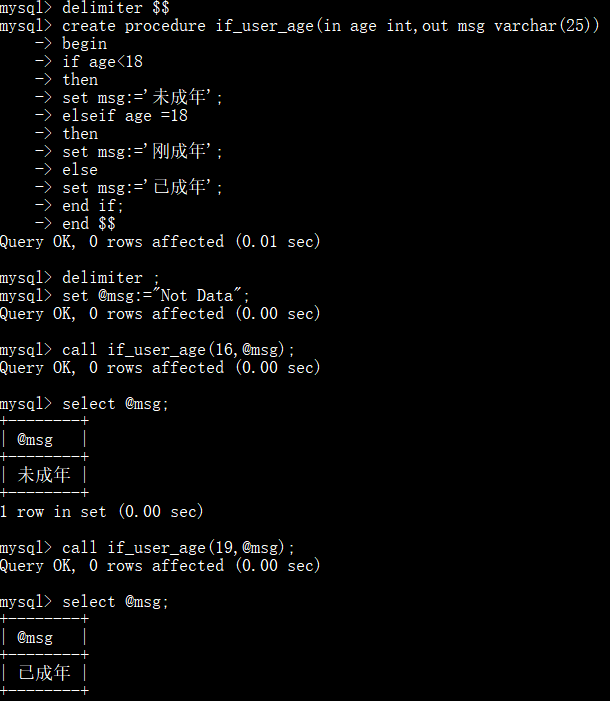
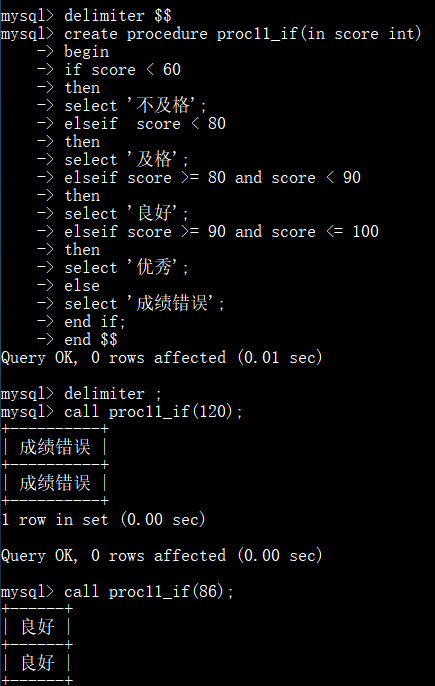
输入学生的成绩,来判断成绩的级别:
输入员工的名字,判断工资的情况:
(2)case判断
case是另一个条件判断的语句,类似于C编程语言中的switch语法,其语法格式如下:
语法1:
case 变量
when 值1 then
-- 分支操作1....
when 值2 then
-- 分支操作2....
.....
else
-- 分支操作n....
end case;
语法2:
case
when 条件判断1 then
-- 分支操作1....
when 条件判断2 then
-- 分支操作2....
.....
else
-- 分支操作n....
end case;
示例:
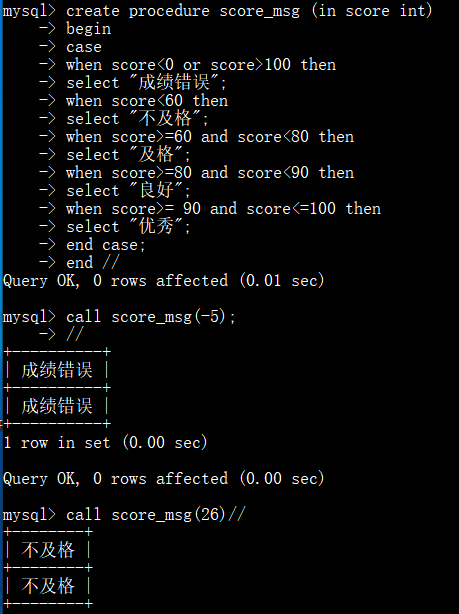
输入学生的成绩,来判断成绩的级别:
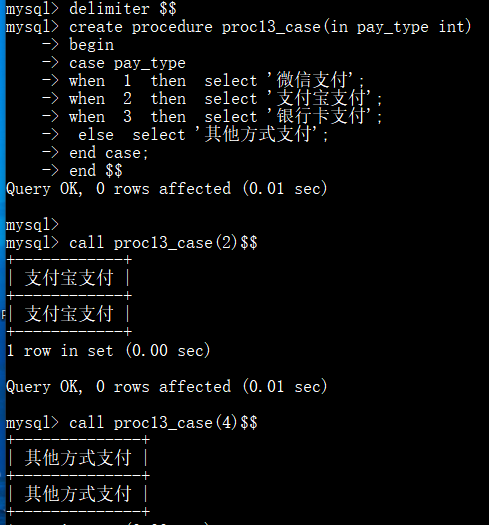
选择支付方式:
(3)循环
概述:循环是一段在程序中只出现一次,但可能会连续运行多次的代码。循环中的代码会运行特定的次数,或者是运行到特定条件成立时结束循环
类型:
while
repeat
loop
循环控制:
leave (离开)类似于 break,跳出,结束当前所在的循环
iterate(迭代)类似于 continue,继续,结束本次循环,继续下一次
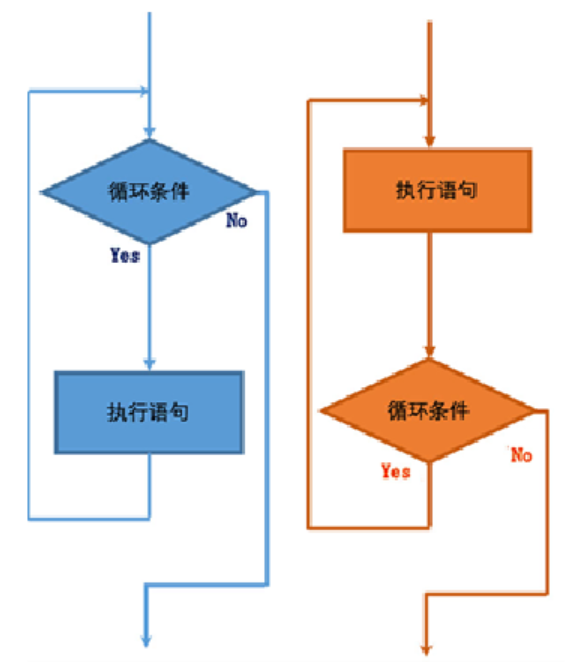
while循环
格式:
[标签:]while 循环条件 do
循环体;
end while[标签];
iterate 迭代、继续
leave 打断
示例:
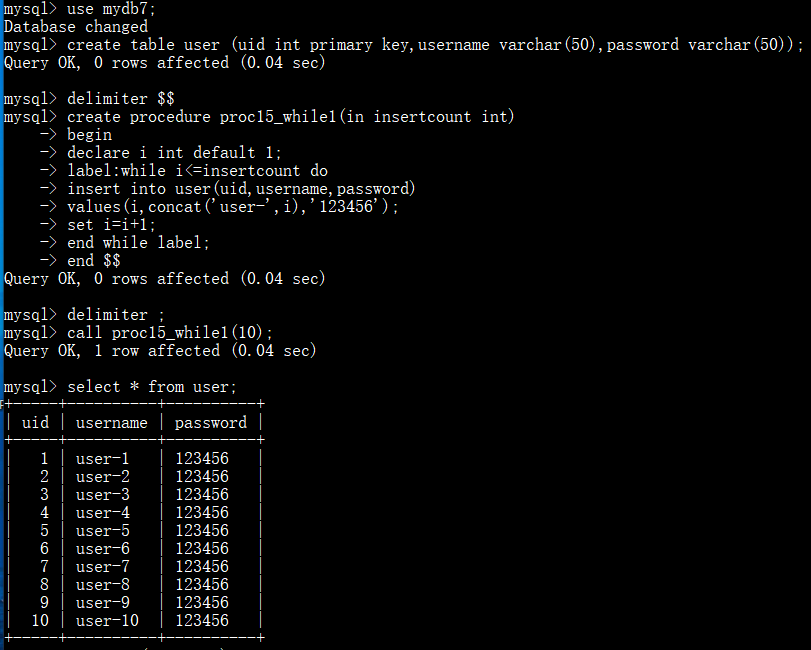
存储过程-while(当型循环),先判断条件,再执行循环体。批量插入用户数据:
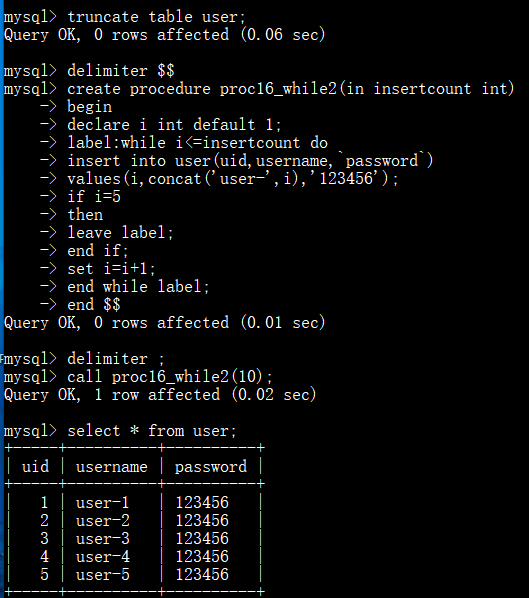
存储过程-while + leave(跳出整个循环),限制插入数据条数:
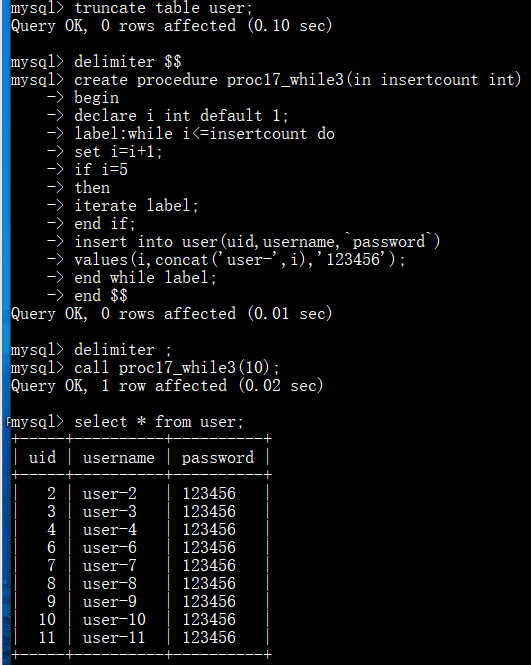
存储过程-while+iterate(跳过当前循环),去掉第五条数据:
repeat循环
格式:
[标签:]repeat
循环体;
until 条件表达式 #条件不成立继续循环,条件成立打断循环
end repeat [标签];
示例:
存储过程-循环控制-repeat (直到型循环),先执行循环体,再判断终止条件:
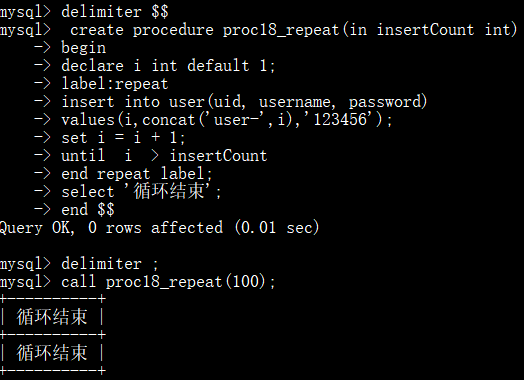
loop循环
格式:
[标签:] loop
循环体;
if 条件表达式
then
leave [标签];
end if;
end loop;
存储过程-循环控制-loop(无条件循环),需结合 leave 或 iterate 来控制循环的始终。灵活性最高,适用于自定义循环终止逻辑的场景:
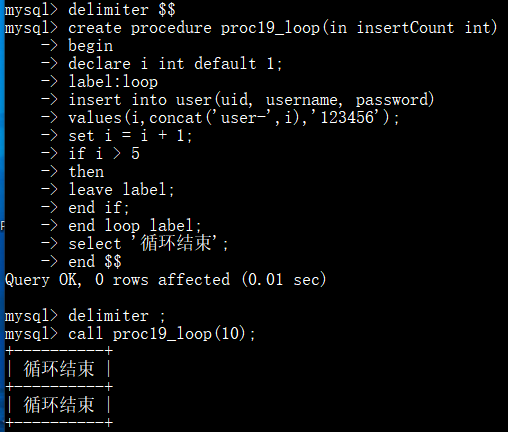
3.触发器
(1)简介
定义:特殊的存储过程,由表的 insert 、 delete 、 update 操作事件自动触发执行,无需手动调用。
作用:用于加强数据完整性约束、实现业务规则(例如学生表新增记录时自动更新学生总数,保证数据一致性)
(2)创建触发器
创建只有一个执行语句的触发器:
create trigger 触发器名 before|after 触发事件
on 表名 for each row
执行语句;
创建有多个执行语句的触发器:
create trigger 触发器名 before|after 触发事件
on 表名 for each row
begin
执行语句列表
end;
说明:
<触发器名称> :最多64个字符,它和MySQL中其他对象的命名方式一样
{ before | after } :触发器时机
{ insert | update | delete } :触发的事件
on <表名称> :标识建立触发器的表名,即在哪张表上建立触发器
for each row :触发器的执行间隔,通知触发器每隔一行执行一次动作,而不是对整个表执行一次
<触发器程序体> :要触发的SQL语句,可用顺序,判断,循环等语句实现一般程序需要的逻辑功能
注:
每个触发器创建后,必然是附着在一张表上的,因为在创建触发器的时候必须要指定表名,它会监控这张表上发生的事件。
示例:
建库建表并插入数据:
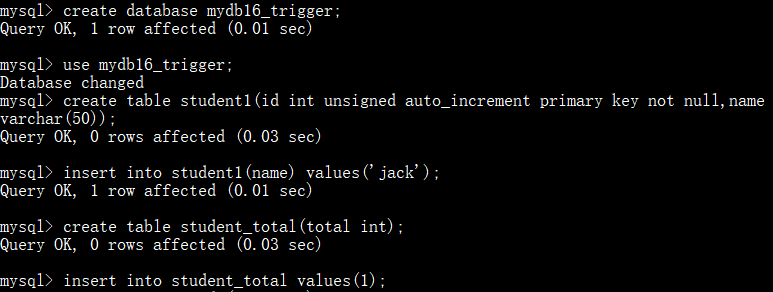
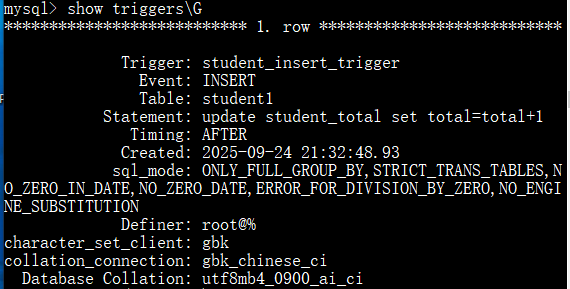
创建触发器student_insert_trigger并测试:
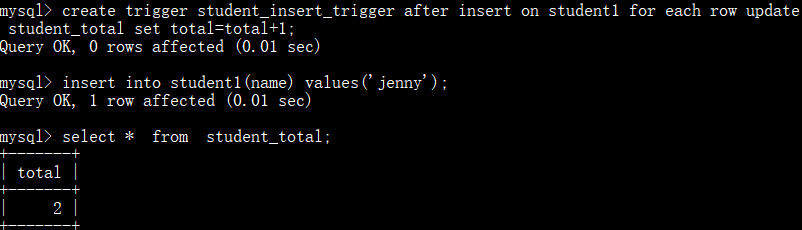
查看触发器:
通过SHOW TRIGGERS语句查看:
通过系统表triggers查看:
use information_schema;
select * from triggers\G;
select * from triggers where trigger_name='student_insert_trigger'\G
通过DROP TRIGGERS语句删除触发器:
drop trigger [数据库名] 触发器名;
(3)NEW与OLD
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
| 触发器类型 | NEW与OLD的使用 |
| INSERT 型触发器 | NEW 表示将要或者已经新增的数据 |
| UPDATE 型触发器 | OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的数据 |
使用方法:NEW.columnName (columnName为相应数据表某一列名)
示例:
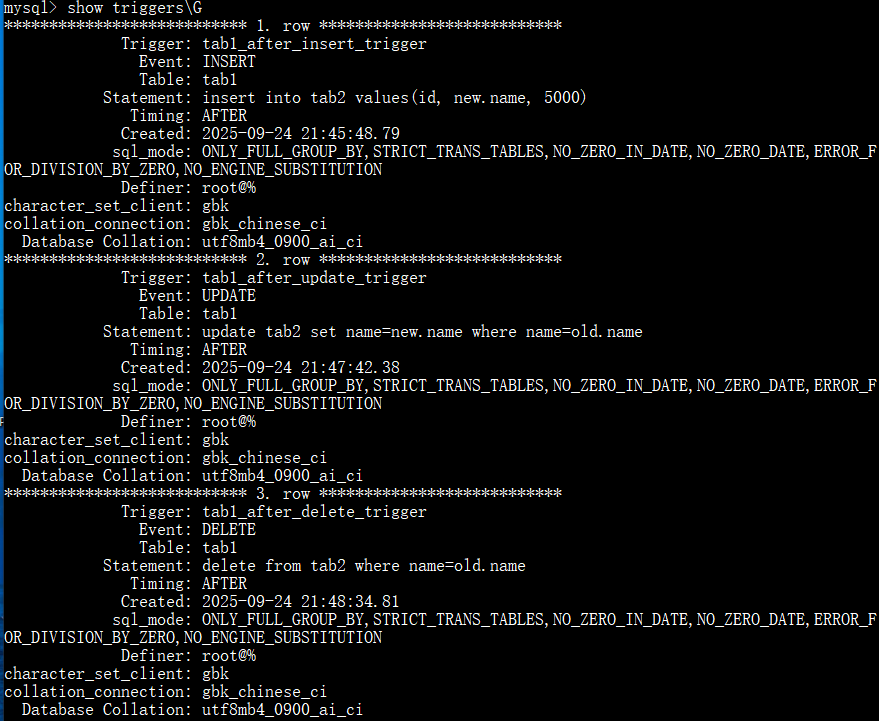
创建表tab1和tab2:

创建触发器 tab1_after_insert_trigger,当tab1增加记录后,自动增加到tab2:

创建触发器 tab1_after_update_trigger ,当tab1更新后,自动更新tab2:

创建tab1_after_delete_trigger触发器,ab1表删除记录后,自动将tab2表中对应记录删除:

查看触发器:
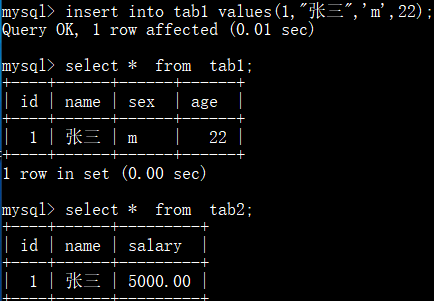
测试:
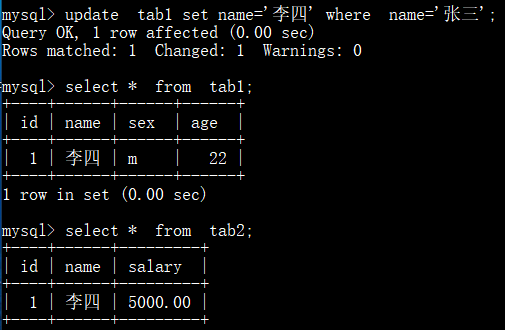
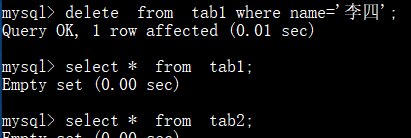
注:
MYSQL中触发器中不能对==本表==进行 insert ,update ,delete 操作,以免递归循环触发
尽量少使用触发器,假设触发器触发每次执行1s,insert table 500条数据,那么就需要触发500次触发器,光是触发器执行的时间就花费了500s,而insert 500条数据一共是1s,那么这个insert的效率就非常低了。
触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
4.存储函数
(1)简介
概念:用于计算并返回一个值,可将常用计算或功能封装为函数,与存储过程类似但有明显区别。
与存储过程的区别:
返回值:存储函数有且仅有一个返回值;存储过程可多个或无返回值。
参数:存储函数仅支持输入参数(无 in 关键字);存储过程支持 in 、 out 、 inout 参数。
功能限制:存储函数不能使用 insert 、 update 、 delete 、 create 等语句,仅完成查询类工作;存储过程可实现复杂业务逻辑。
调用关系:存储过程可调用存储函数,函数不能调用存储过程。
调用方式:存储过程通过 call 独立执行;函数可作为查询语句的一部分调用。
函数特性声明(二进制日志开启时):需明确声明特性以保证复制/恢复一致性,如 DETERMINISTIC (相同输入返回相同输出)、 NO SQL (无SQL语句)、 READS SQL DATA (仅读取数据)。
解决办法:
方法一:修改函数定义
在创建函数时,为函数添加相应的特性声明。例如,若函数是确定性的,就可以添加 DETERMINISTIC 关键字,如:
-- 创建一个简单的函数并添加 DETERMINISTIC 声明
DELIMITER //
CREATE FUNCTION add_numbers(a INT, b INT)
RETURNS INT
DETERMINISTIC
BEGIN
RETURN a + b;
END //
DELIMITER ;
方法二:修改 log_bin_trust_function_creators 变量
可以通过设置 log_bin_trust_function_creators 变量来允许创建未声明特性的函数。不过要注意,这种做法安全性较低。如:
临时修改:在当前会话中临时修改该变量:
SET GLOBAL log_bin_trust_function_creators = 1;
永久修改:要永久修改,需要编辑 MySQL 配置文件(通常是 my.cnf 或者 my.ini),在 [mysqld] 部分添加或修改以下行:
plaintext
log_bin_trust_function_creators = 1
修改完成后,重启 MySQL 服务。
(2)创建和调用
创建存储函数
在MySQL中,创建存储函数使用 create function 关键字,其基本形式如下:
create function func_name ([param_name type[,...]])
returns type
[characteristic ...]
begin
routine_body
end;
参数说明:
func_name :存储函数的名称。
param_name type:可选项,指定存储函数的参数。type参数用于指定存储函数的参数类型,该类型可以是MySQL数据库中所有支持的类型。
returns type:指定返回值的类型。
characteristic:可选项,指定存储函数的特性。
routine_body:SQL代码内容。
调用存储函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法基本相同
用户自定义的存储函数与MySQL内部函数性质相同。
区别在于,存储函数是用户自定义的。而内部函数由MySQL自带。其语法结构如下:select func_name([parameter[,…]]);
示例:
无参数存储函数:
信任子程序的创建者,否则可能报错,执行一次即可

创建存储函数-没有输输入参数
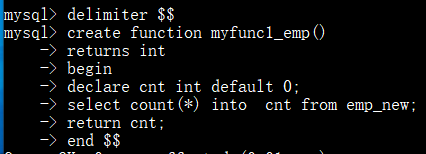
调用存储函数
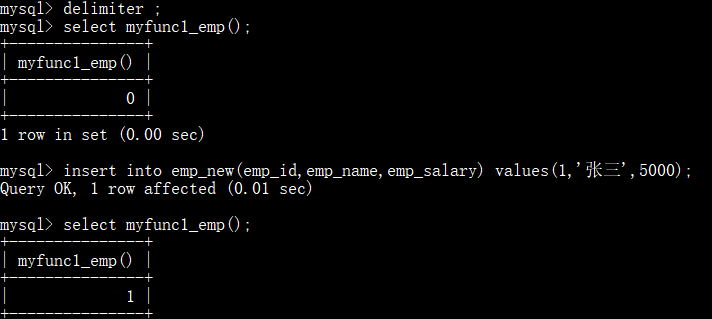
有参数存储函数:
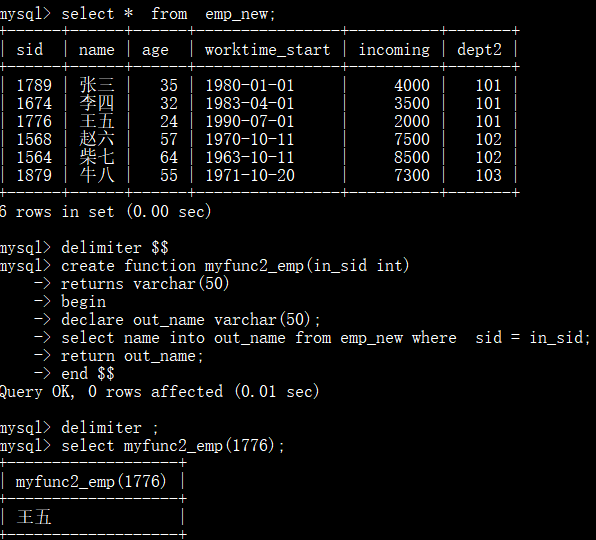
两者区别
| 对比项 | 无参数存储函数 | 有参数存储函数 |
| 参数传递 | 不需要接收外部输入参数 | 可接收一个或多个输入参数,用于动态调整函数逻辑 |
| 功能灵活性 | 功能固定,仅针对固定逻辑执行计算(如示例中固定统计表记录数) | 功能更灵活,可根据不同参数执行不同逻辑(例如根据参数筛选特定数据后统计) |
| 应用场景 | 适用于逻辑固定、无需外部输入的计算场景(如固定表的记录统计、固定公式计算) | 适用于需要根据外部条件动态计算的场景(如根据用户输入的部门ID统计该部门员工数) |
(3)删除存储函数
MySQL中使用 drop function 语句来删除存储函数。
drop function 存储函数名
示例:

show procedure status;(用于查看当前数据库中所有存储过程的状态信息,包括名称、创建时间、修改时间等)
select ROUTINE_TYPE,ROUTINE_NAME from ROUTINES where ROUTINE_SCHEMA='day02'\G(从系统表 ROUTINES 中查询 day02 数据库下的存储例程(包括存储过程和函数),其中 ROUTINE_TYPE 表示是存储过程还是函数, ROUTINE_NAME 是其名称。 \G 用于将结果按行垂直显示,便于阅读)