深度解析:vLLM PD分离KV cache传递机制全解析
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI算法学习视频及资料,尽在聚客AI学院。
KV Cache传递是vLLM实现PD(Prefill-Decode)分离的核心技术之一,其性能与稳定性直接关系到整个推理系统的效率。本文将系统探讨KV Cache传递过程中的关键问题。

ps:建议在进入正文前,大家对KV Cache的工作原理有一个基本的理解,如果不清楚的粉丝朋友,可以看看我之前整理的技术文档:《小白也能看懂的LLMs中的KV Cache,视觉解析》
一、KV Cache传递的常见问题
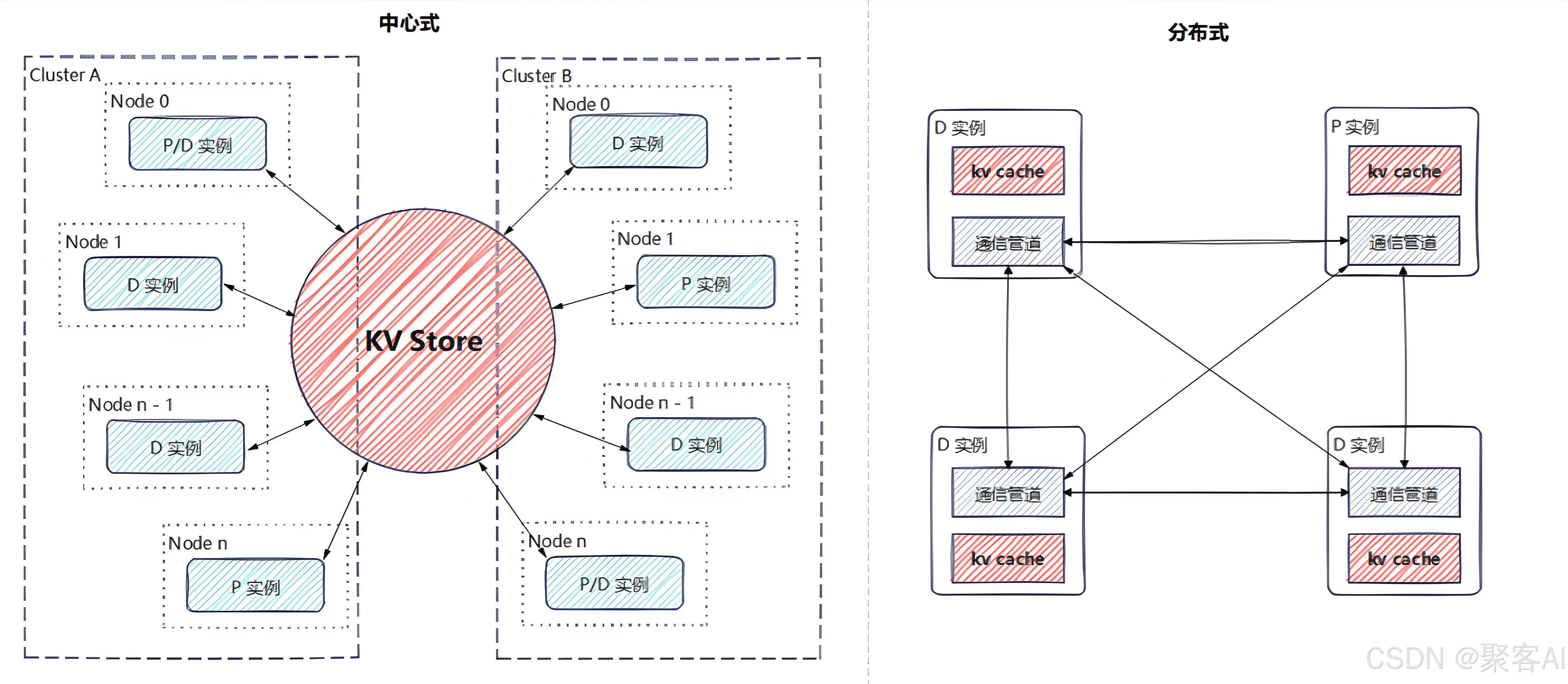
1.1 传递方式:中心存储与分布式架构
KV Cache的传递主要有两种典型方案:中心存储和分布式(P2P) 模式。
- 中心存储:通过统一的KV Store管理所有设备的KV值,提供增、删、查及传递功能。优势在于可扩展性强、支持异构存储介质、易于实现计算重用,但性能可能受中心节点设计影响,系统维护复杂度较高。
- 分布式传递:各个实例独立管理存储,通过点对点通信完成数据传输。优势是延迟低、架构清晰,但扩展性和稳定性较差。
两种方式也可混合使用。当前主流推理框架(如Mooncake、Dynamo)更倾向于中心存储方案,将传输复杂性封装在系统内部。
常见的存储与传输介质包括:
| 存储介质 | 传输通道 | 特点 |
|---|---|---|
| 显存(HBM) | NVLink/HCCS | 速度最快,容量小 |
| 显存 | RDMA(RoCE/IB) | 经PCIe传输,速度次之 |
| 内存 | RDMA(NIC) | 容量中等,速度中等 |
| 内存 | PCIe/TCP | 需经CPU处理,速度较低 |
| 本地磁盘 | PCIe/TCP | 容量大,速度慢 |
| 远端云存储 | TCP | 容量最大,速度最低(跨地域) |
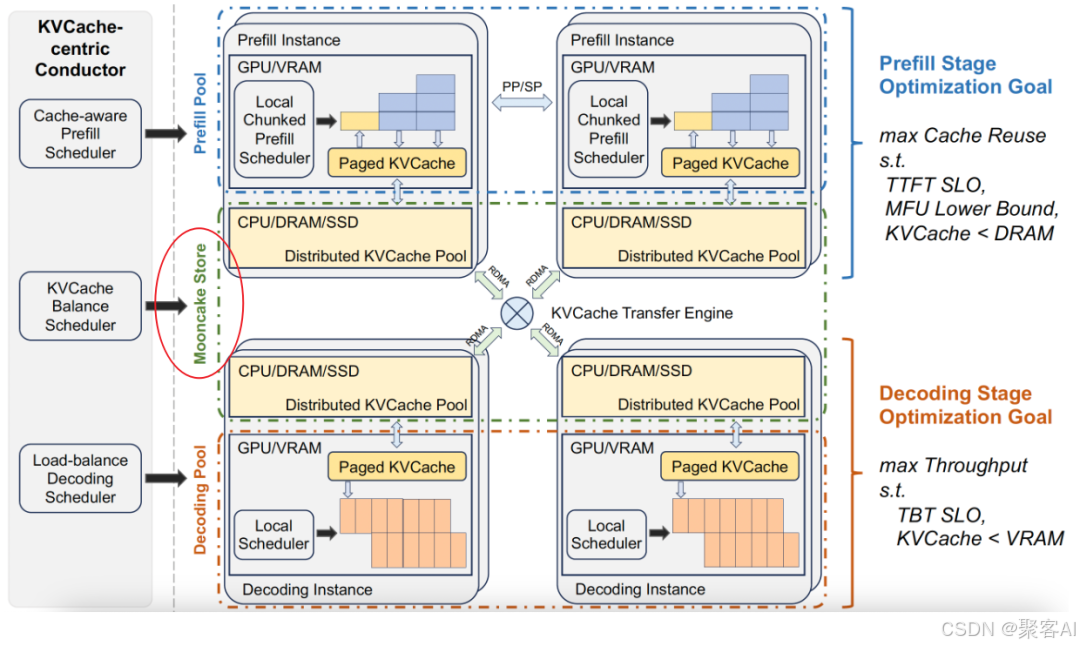
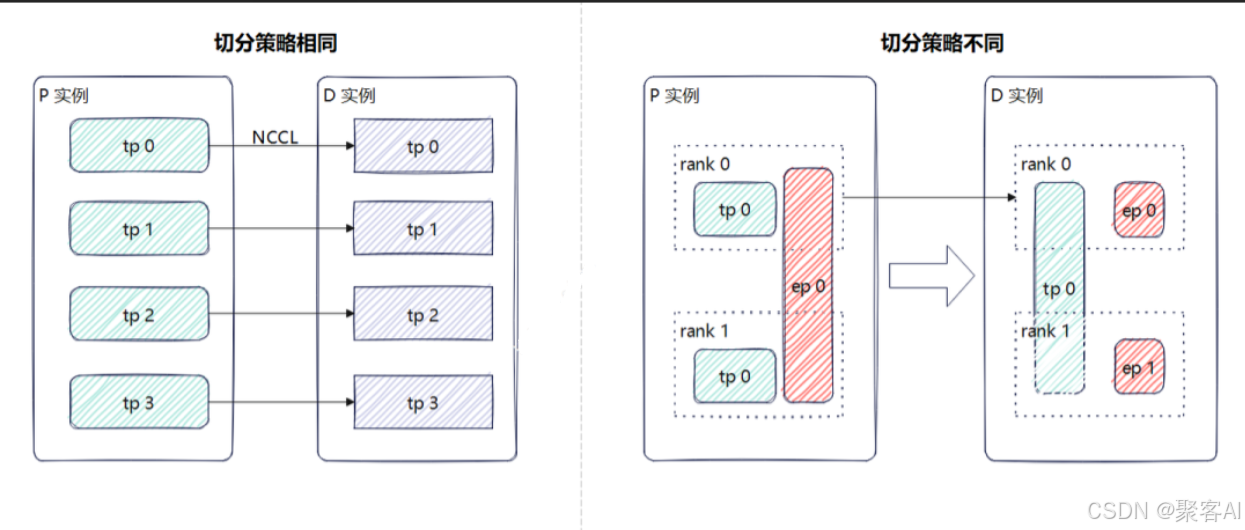
1.2 模型并行下的传递挑战
当模型采用TP、PP等并行策略时,KV Cache可能分散在不同设备上。若Prefill实例和Decode实例的并行策略不一致,则无法直接进行Rank间一对一传输。
例如,Prefill使用TP4+EP1,而Decode使用TP1+PP2+EP4,此时需采用“聚合-传输-分发”策略,如借助TP组内Rank0汇聚数据再发送。这种方式难以充分利用高速互联链路(如NVLink)。若传输Block尺寸过小,虽可避免聚合,但可能引发多Rank争抢同一数据源,导致阻塞和效率下降。
1.3 双向传输:不仅限于P到D
在支持Prefix Cache的系统中,Decode实例已计算的KV Block也可能被Prefill实例复用。因此,KV Cache传输并非单向的从P到D,同样存在D到P的反向传输需求。
vLLM的V1版本设计中,Decode实例可先本地查找匹配的KV Block,未命中时再向Prefill实例请求,避免重复计算和传输。
1.4 传输与计算的带宽争抢
根据传输时机,可分为两种场景:
- 整体计算传输:Prefill阶段完全结束后统一传输KV Cache。通常不会与计算争抢带宽,但若传输速度慢于计算速度,下一个计算请求可能被迫等待。
- 分层/分Block传输:每计算完一个单位立即异步传输,可减少串行延迟,但若模型计算本身已占满带宽,则两者会产生竞争。
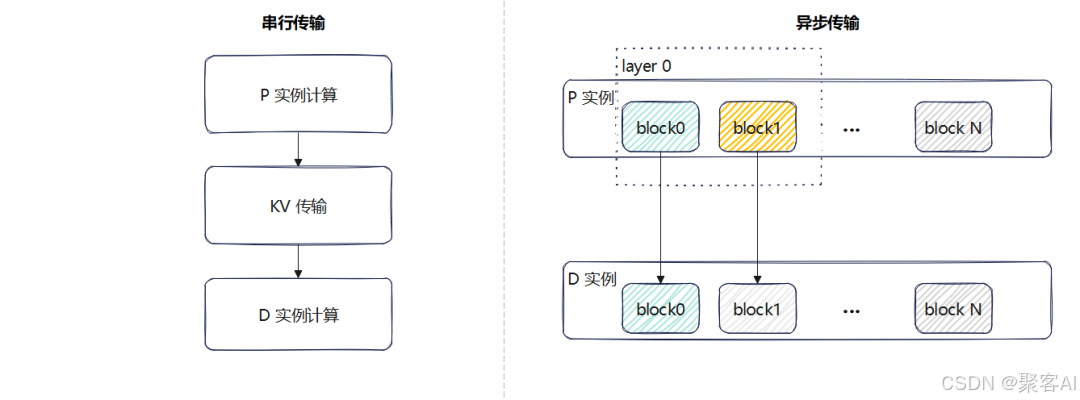
二、vLLM的实现方案
vLLM目前提供两套KV Transfer实现:V0(稳定版)和V1(开发版,变动较大)。以下基于0.8.5版本分析其架构与接口。
2.1 V0版本:生产者-消费者模式
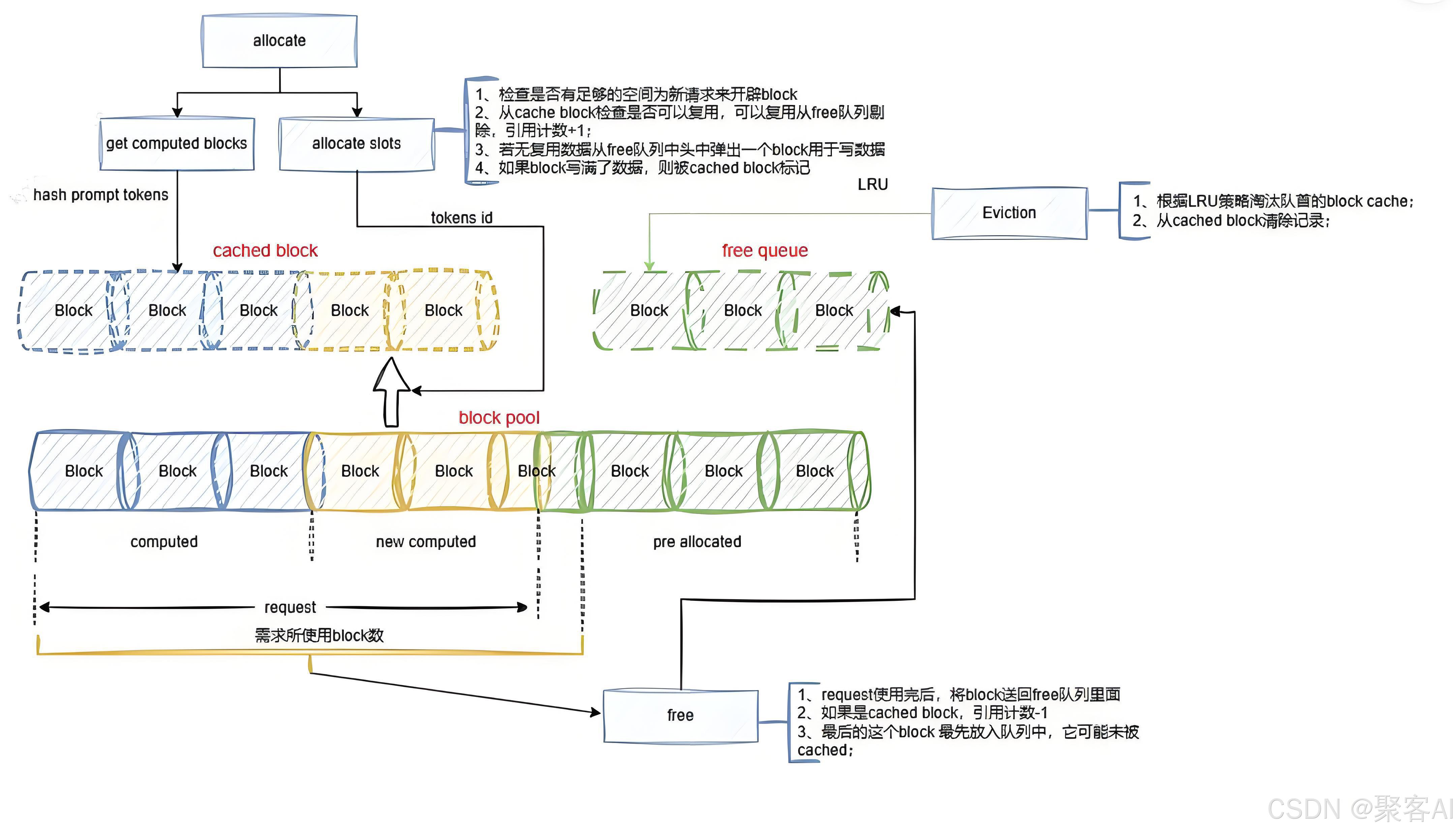
V0采用典型的Connector模式,由Lookup Buffer、Pipe和Connector协调器组成。
- Connector:负责对外接口,初始化时通过工厂类(KVConnectorFactory)根据配置选择具体实现,如PyNcclConnector、MooncakeStoreConnector等。
- Lookup Buffer:构建FIFO队列缓冲数据,提供insert(生产者调用)和drop_select(消费者调用)接口。
- Pipe:实际数据传输通道,支持发送和接收Tensor,提供如PyNcclPipe等具体实现。
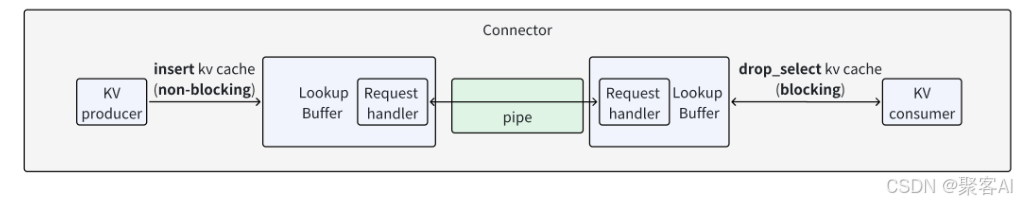
传输基本流程为:Prefill实例计算完成后,将KV数据插入Buffer;消费者发送input_tokens和ROI(Region of Interest)标志,生产者返回对应Key、Value及Hidden状态。
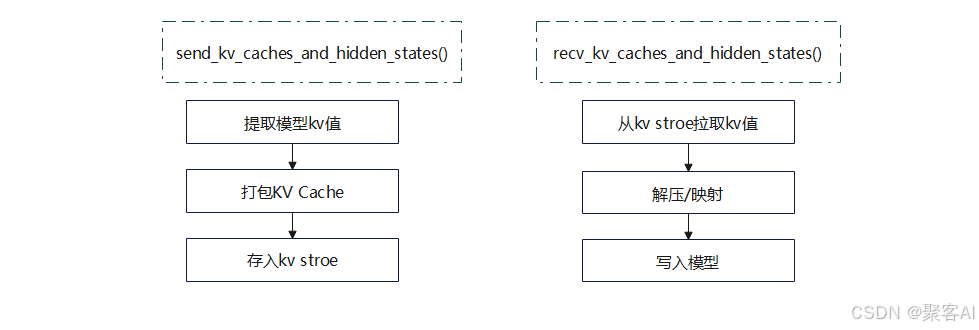
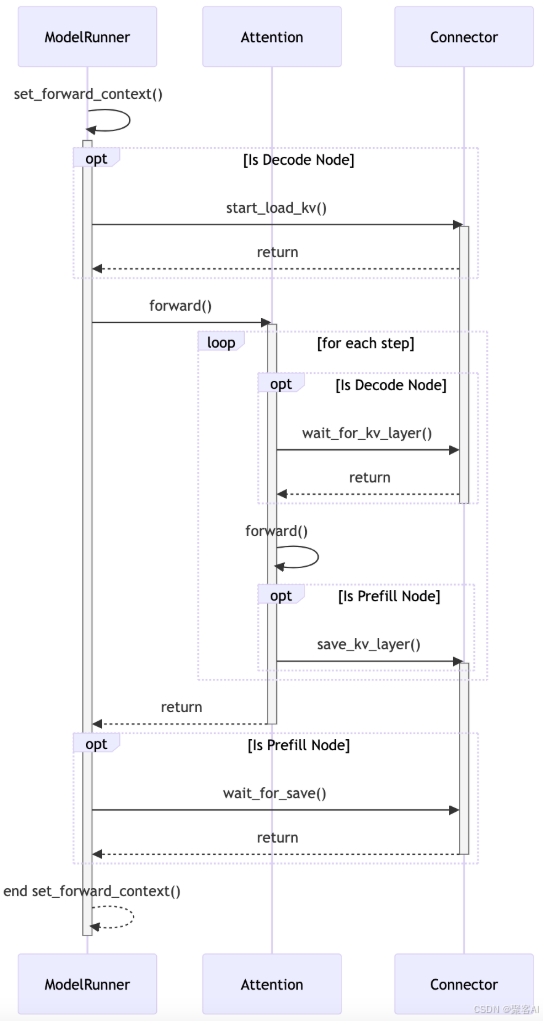
2.2 V1版本:调度器与Worker协同
V1版本中,Prefill和Decode角色可互换,传输方向为双向。核心特点是引入Scheduler Connector和Worker Connector,通过元数据(KVConnectorMetadata)协调传输任务。
- Scheduler Connector:运行于Scheduler线程,负责判断是否需加载远端KV、更新Block状态、生成传输元数据。
- Worker Connector:运行于Worker线程,根据元数据执行实际的数据加载和存储。
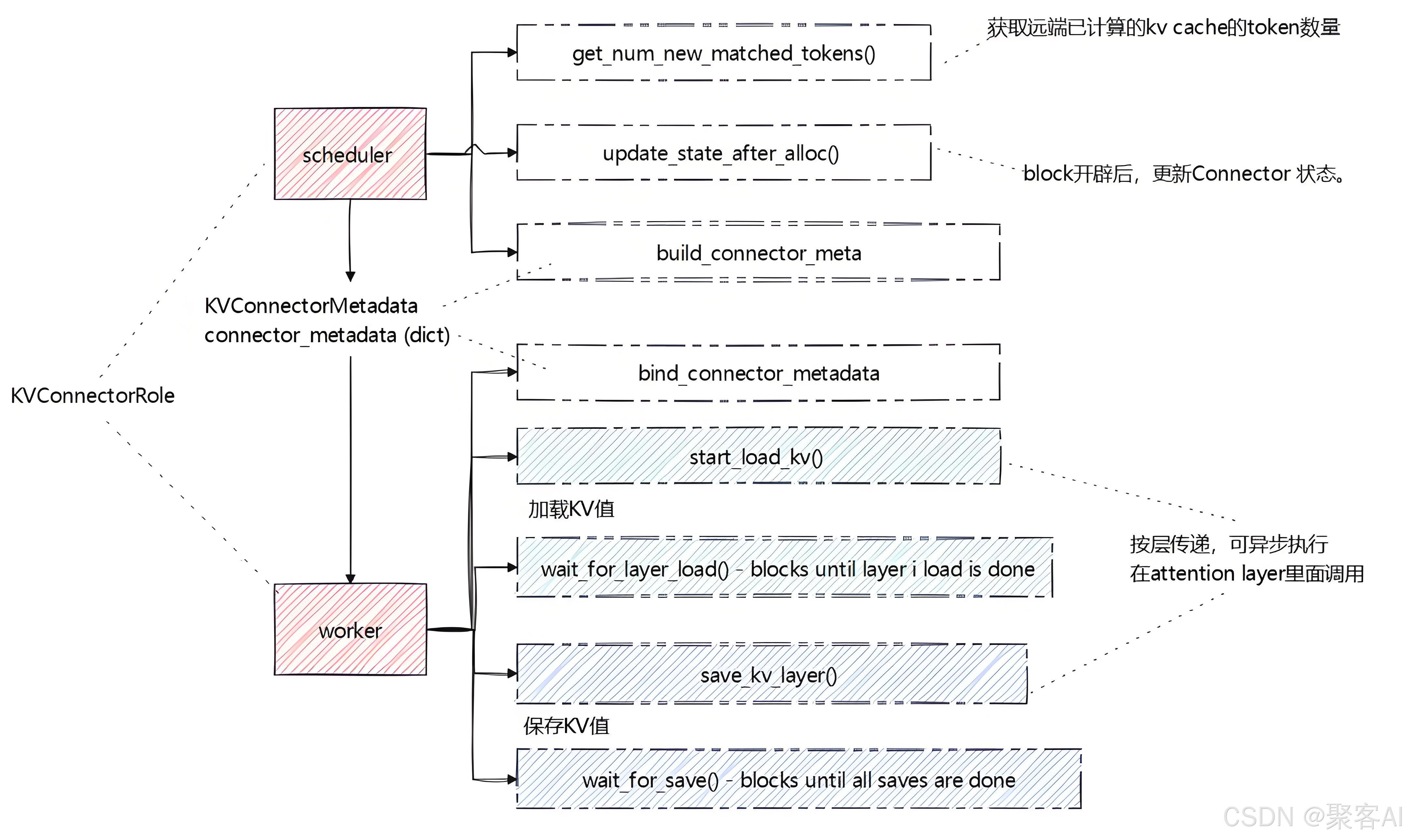
关键接口包括:
start_load_kv/wait_for_layer_load:消费者异步加载KV数据。save_kv_layer/wait_for_save:生产者存储KV数据。build_connector_meta:Scheduler生成传输计划。
传输过程可实现计算与通信的重叠,提升整体效率。
三、演进方向与开放问题
3.1 控制信号传输机制
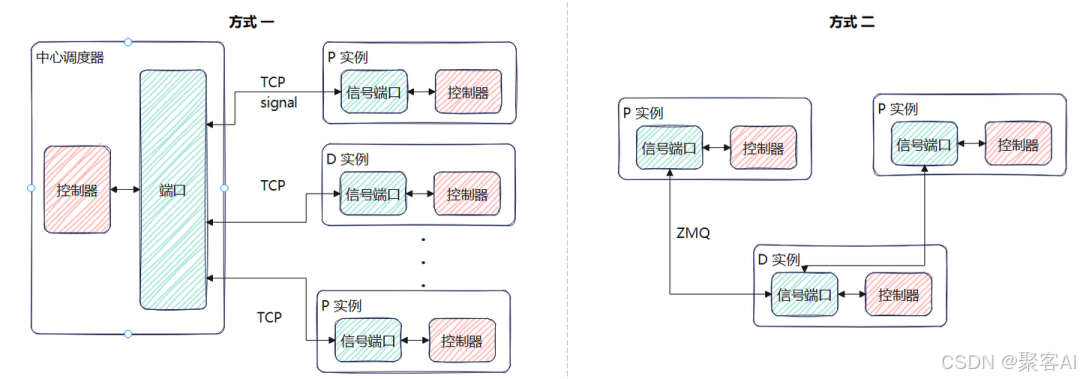
PD实例间需协调执行状态,如KV准备完成、释放本地缓存等。控制信号传输有两种方式:
- 直连:P与D间直接建立控制信道,延迟低但需自行处理可靠性。
- 经中心调度器:所有控制信令经调度器转发,实现简单但可能成为瓶颈。
需重点考虑信号丢失的处理,如重传机制或超时释放策略。
3.2 Scheduler轻量化设计
V1版本中Scheduler需处理KV传输状态,如等待远端KV、更新块映射等,逻辑日益复杂。未来应考虑将部分功能下放至Worker,保持Scheduler轻量高效。
3.3 可靠性保障机制
当前vLLM尚未全面考虑传输故障容错。未来需设计重传、重计算及一致性机制,确保部分传输失败时系统仍能正常完成推理。
四、笔者总结
KV Cache传递是PD分离架构的关键组件,其设计需综合考虑传输方式、并行策略、双向复用与带宽竞争等问题。vLLM通过V0/V1两套方案提供了基础实现,但在调度器轻量化、控制信号可靠性与传输容错等方面仍有优化空间。未来可结合中心存储与分布式优势,构建高效、稳定且可扩展的KV Cache传输系统。好了,今天的分享就到这里,点个小红心,我们下期见。