Transformer原理学习(4)注意力机制
一、有哪些注意力机制?
Transformer 里其实只有一种公式:Scaled Dot-Product Attention。
不同名字只是使用方式不同:
| 名称 | Q 来源 | K/V 来源 | 应用位置 |
|---|---|---|---|
| Self-Attention | 输入序列自身 | 输入序列自身 | Encoder / Decoder |
| Masked Self-Attention | 输入序列自身 | 输入序列自身(带mask) | Decoder |
| Cross-Attention | Decoder | Encoder | Decoder |
| Multi-Head Attention | 拆分多个头 | 拆分多个头 | Encoder & Decoder |
二、缩放点积注意力
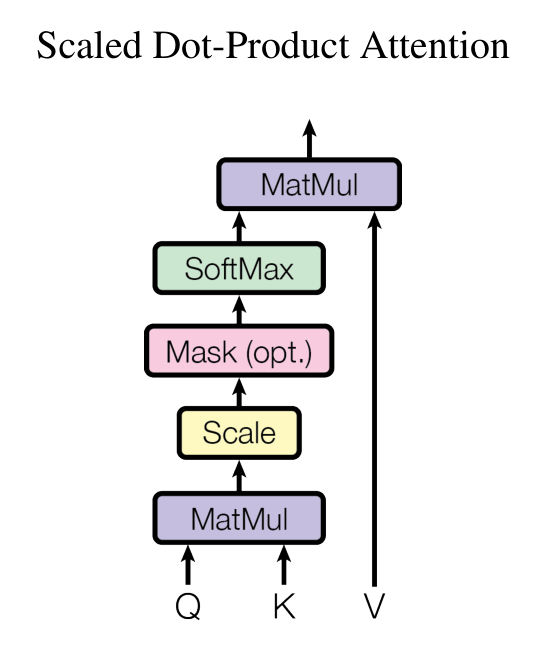
1. 核心公式
在论文 Attention is All You Need 中,注意力机制定义为:
Attention(Q,K,V)=softmax (QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
2. 各部分含义
- Q(Query,查询):表示“我要找什么信息”。
- K(Key,键):表示“我拥有什么信息”。
- V(Value,值):表示“具体的信息内容”。
三者都是由输入向量通过线性变换得到的。
3. 计算步骤
-
点积 (Dot Product)
-
计算 Query 和 Key 的相似度:
QKT QK^T QKT
-
每个元素表示“一个 Query 和一个 Key 的相关性”。
-
-
缩放 (Scaling)
- 除以 dk\sqrt{d_k}dk (Key 的维度)。
- 原因:防止数值过大,导致 softmax 梯度过小、训练不稳定。
-
归一化 (Softmax)
-
将相关性转化为概率分布:
α=softmax (QKTdk) \alpha = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}}\right) α=softmax(dkQKT)
-
表示“Query 对所有 Key 的注意力权重”。
-
-
加权求和 (Weighted Sum)
-
用权重去加权 Value:
Attention(Q,K,V)=αV \text{Attention}(Q,K,V) = \alpha V Attention(Q,K,V)=αV
-
得到最终的注意力表示。
-
4. 举个例子
句子:「那天雨很大,他等了很久,水汽打湿了衣服,也没有等到她。」
如果我们在做自注意力:
- Query = “他”
- Key/Value = 整个句子
计算后:
- “等了很久” 对 “他” 的相关性很高 → 权重大
- “雨很大” 也可能有关系(解释等待的背景) → 权重适中
- “她” 也有关联(他等的人是谁) → 权重大
- “水汽打湿了衣服” 可能关联小 → 权重低
最终,“他”的向量会融合这些上下文信息。
5. 作用总结
- 点积 → 计算相关性
- 缩放 → 保持数值稳定
- softmax → 转概率分布
- 加权求和 → 聚合信息
三、多头注意力
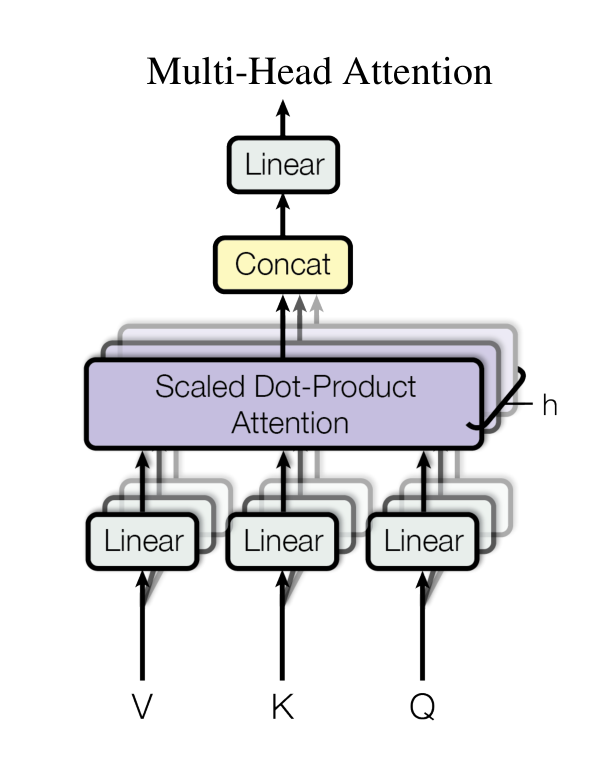
1. 为什么需要多头注意力?
单个 Scaled Dot-Product Attention 在每次计算时,只能学习一种相关性模式。
-
比如 Query=“他”:
- 可能更关注“她”(他在等谁),
- 也可能关注“雨很大”(环境背景),
- 也可能关注“等了很久”(行为状态)。
但如果只有一个头,模型会压缩成一个加权分布,无法同时捕捉多种语义关系 → 信息丢失。
2. 多头注意力的核心思想
- 不是只用一个 Q/K/V,而是并行生成多个 Q/K/V,每组叫做一个“头(head)”。
- 每个头在不同的 低维空间 中学习相关性模式。
- 多个头的结果拼接起来,再线性变换 → 得到更丰富的上下文表示。
公式:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,…,headh)WO
其中:
headi=Attention(QWiQ,KWiK,VWiV) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
3. 多头是怎么解决问题的?
-
多视角建模
-
每个头学到的关注点不一样:有的看短程依赖,有的看长程依赖。
-
举例:句子“那天雨很大,他等了很久,水汽打湿了衣服,也没有等到她。”
- 头1:关注“他 ↔ 她”(人际关系)
- 头2:关注“他 ↔ 雨很大”(环境背景)
- 头3:关注“他 ↔ 等了很久”(动作/状态)
-
-
信息多样化
- 单头可能学到的是一种模糊加权。
- 多头能在不同子空间里并行学习语义,减少遗漏。
-
提升模型表达能力
- 让 Transformer 在相同参数规模下,能更好地表达复杂关系。
4. 举例类比
你可以把 多头注意力 想成:
- 一个问题交给多个专家(头),每个专家专注于不同角度。
- 最后把各个专家的意见拼在一起,形成更完整的结论。
5. 总结一句话
- 问题:单个注意力只能捕捉一种关系,信息不够全面。
- 解决:并行多个注意力头,在不同子空间学习不同关系。
- 结果:模型更强、更稳定,能捕捉丰富的语义依赖。
四、掩码自注意力
1. 背景:为什么需要掩码?
Transformer 里有两种主要的任务场景:
- 编码器(Encoder):输入序列是已知的(比如一句话),可以双向看上下文。
- 解码器(Decoder):要一边生成一边预测下一个词,比如机器翻译 → 当前时刻只能依赖过去的词,不能偷看未来的词。
如果不加限制,解码器的自注意力会“看到”未来词 → 信息泄露(data leakage)。
2. 什么是掩码自注意力?
就是在 自注意力(Self-Attention) 的计算中,人为屏蔽掉未来位置的注意力权重。
公式还是:
Attention(Q,K,V)=softmax (QKTdk+M)V \text{Attention}(Q,K,V) = \text{softmax}\!\left(\frac{QK^T}{\sqrt{d_k}} + M \right)V Attention(Q,K,V)=softmax(dkQKT+M)V
其中:
- MMM 是 mask 矩阵
- 对于未来位置,M=−∞M = -\inftyM=−∞,softmax 后得到 0 权重
- 只允许当前位置关注自己和之前的词
3. 如何解决问题?
- 问题:在解码时,如果能看到未来词,就相当于“作弊”。
- 解决:通过 Mask,把未来词的相关性强制变成 0 → 保证自回归(auto-regressive)生成。
- 效果:模型只能根据历史信息生成下一个词,符合真实生成场景。
4. 举例说明
句子:「我爱吃苹果」
如果我们在训练解码器预测:
- 预测“爱”时,只能看到“我”
- 预测“吃”时,只能看到“我 爱”
- 预测“苹果”时,只能看到“我 爱 吃”
👉 如果没加 Mask,预测“爱”时可能提前看到“吃苹果”,就等于提前知道答案。
5. 总结一句话
- 掩码自注意力是自注意力的变体,用于解码器。
- 目的:防止模型看到未来词,保证自回归生成的正确性。
- 做法:在 softmax 前把未来位置权重屏蔽掉(置为 -∞)。
五、交叉注意力
1. 背景:为什么需要交叉注意力?
Transformer 的 解码器 需要结合:
- 自己已生成的内容(通过自注意力得到)
- 输入序列的上下文(来自编码器)
如果解码器只依赖自身 → 就像闭门造车,无法利用源语言/输入的语义信息。
👉 所以,需要一种机制让解码器在生成时 查询编码器的输出。
2. 什么是交叉注意力?
交叉注意力的输入:
- Q(Query) 来自 解码器当前层的隐藏状态(已生成内容的表示)
- K(Key)、V(Value) 来自 编码器的输出(输入序列的语义表示)
公式:
Attention(Qdecoder,Kencoder,Vencoder) \text{Attention}(Q_{\text{decoder}}, K_{\text{encoder}}, V_{\text{encoder}}) Attention(Qdecoder,Kencoder,Vencoder)
即:解码器用自己的 Query 去 对齐编码器的输出,找到相关信息,然后取回来。
3. 它解决了什么问题?
-
问题:解码器不知道该生成什么样的内容,需要和输入保持对应关系(比如翻译“我爱苹果” → “I love apples”)。
-
解决:交叉注意力让解码器在生成每个 token 时,能动态聚焦输入序列的不同部分。
- 生成 “I” → 关注输入的 “我”
- 生成 “love” → 关注输入的 “爱”
- 生成 “apples” → 关注输入的 “苹果”
4. 举例说明
源句子(编码器输入):「那天雨很大」
目标句子(解码器输出):“It rained heavily that day”
- 当解码器生成 “It” 时,Query 来自 “It” 的上下文,Key/Value 来自编码器 → 可能最关注 “那天”
- 当生成 “rained” 时 → 关注 “雨很大”
- 当生成 “heavily” 时 → 关注 “很大”
- 当生成 “that day” 时 → 关注 “那天”
这样,生成过程保持了 输入输出的对齐关系。
5. 总结一句话
- 交叉注意力 = 解码器的 Query + 编码器的 Key/Value
- 目的:让解码器在生成时利用输入序列的信息
- 解决问题:实现输入与输出的动态对齐,避免解码器“瞎编”