负载均衡式在线OJ项目复盘
文章目录
- 1. 项目简介
- 2. 项目模块设计
- 2.1 项目结构框架
- 2.2 oj_server模块设计
- 2.1.1 Model模块
- 2.1.1.1 文件版本
- 2.1.1.2 mysql版本
- 2.1.2 View模块
- 2.1.3 Control模块设计
- 2.1.3.1 LoadBalance模块
- 2.1.3.2 Control中Judge逻辑
- 2.1.4 oj_server.cc
- 2.3 compile_server模块设计
- 2.3.1 compile
- 2.3.2 run
- 2.3.3 compile_and_run
- 2.3.4 compile_server.cc
- 3. 前端交互
- 3.1 ACE编辑器
- 3.2 代码提示和补全
- 3.3 代码提交功能
- 3.4 显示运行结果
- 4. 项目总结
- 4.1 项目的模块化设计
- 4.2 技术亮点
- 5. 项目发布:顶层Makefile
1. 项目简介
本项目实现一个个人在线OJ网站平台,通过前后端交互,将用户的代码提交给后台编译运行服务,并将结果返回,达到在线OJ的效果。
以下是项目效果展示:
2. 项目模块设计
2.1 项目结构框架
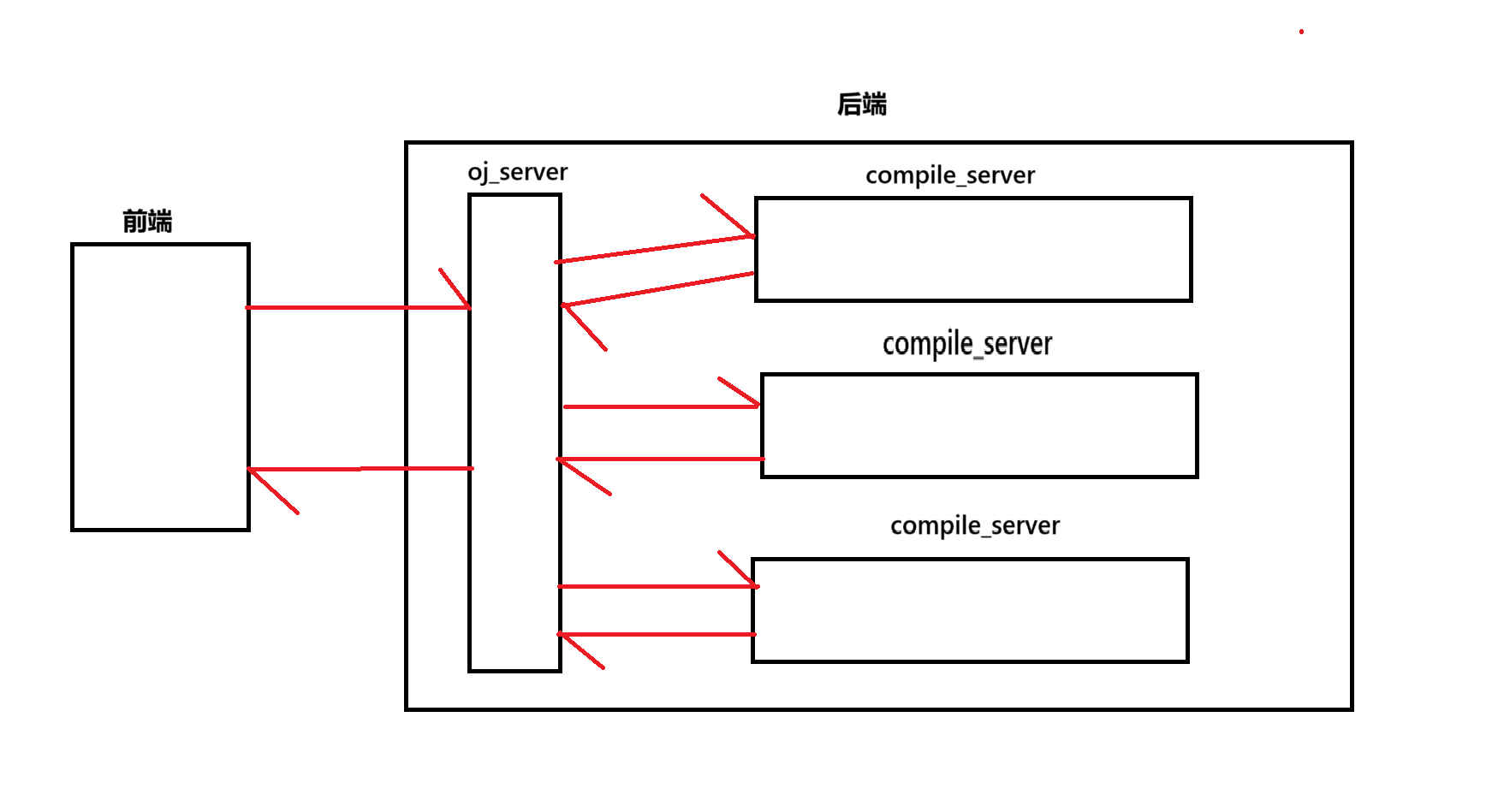
项目分为两个重要组成部分:oj_server处在一个中间地位,实现功能路由,通过不同的功能路由,实现前端网页的返回以及判题功能的实现;compile_server模块,则是更加后台的代码编译运行服务,是整个OJ判题功能的核心,该模块与oj_server进行交互,oj_server前后端交互获得用户提交代码后,交由该模块进行判题。
对于一个在线OJ判题的项目,oj_server主要起到一个勾连前后的作用,而compile_server则是判题功能核心,一般来说,compile_server的工作量会远远大于oj_server。因此,在设计整个项目结构时,我们使用一个oj_server进行前后端交互,而构建多个compile_server用于负载均衡,以提高判题效率。
2.2 oj_server模块设计
需求决定设计。对于oj_server模块,我们希望它完成什么作用呢?
oj_server模块是一个功能路由,提供以下功能:
- 用户请求首页,返回首页
- 用户请求题目列表,返回题目列表
- 用户请求具体题目界面,返回具体题目界面,在该界面中提供在线OJ功能
- 用户编写代码后,提交进行判题功能,并为用户返回判题结果
可以看到oj_server模块的功能路由中,涉及与前端的交互,要向前端返回各种html网页,同时又与后端相关,因为本质给前端返回的内容,都是数据,很多都需要从磁盘上加载,特别是具体的题目,以文件形式存储在磁盘中。
对于这种同时涉及后端与前端的模块,我们采用MVC模式——M代表Model,用于后端数据提取;V代表View,使用后端数据,渲染将返回给前端的html文件;C代表Control,用以综合调用MV两个模块,涉及两个模块的具体调用逻辑和差错处理等等。
接下来,我们具体聊聊oj_server如何使用MVC设计。
2.1.1 Model模块
对于Model模块,可以有两种方式实现:数据存储在文件中或数据存储在数据库中。
2.1.1.1 文件版本
首先,我们要明确model模块需要获取的数据有哪些,哪些数据是需要预先加载的,哪些数据不必预先加载。
首先,一个在线OJ平台,题库中的所有题目应该预先加载,这样用户实际请求时,就不必进行磁盘级IO,而是直接从内存中提取数据,能够提高效率。
一般来说,不用担心内存不够的情况,因为即便是一个成熟的在线OJ平台,题目也不过几千道,一个题目的具体内容本身都是文本数据,不会太大,一台服务器中的内存应是完全够用的。
对于具体的网页内容,由于View模块使用Ctemplate库进行模板渲染缘故,采用访问时加载方式进行。
既然要预加载题目,所以必须先描述,再组织。
用一个成员变量对外开放的类Question来存储题目信息,在Model模块中,使用哈希结构进行组织,以便访问特定题目时,实现O(1)查找。
由于是预先加载数据,根据RAII风格的设计理念,在Model类的构造中,就加载所有题目的信息,即设计一个LoadQuestionList的接口在构造中调用。
那么,Model类还需对外提供哪些接口呢?
Model类中存储所有题目数据,通过该类,要能够获得所有题目信息,也要能够获得一道题目信息,因此对外提供GetAllQuestions和GetOneQuestion的接口。
获取所有题目,用于构建题目列表;获取一道题目,则用于构建具体题目页面。
2.1.1.2 mysql版本
mysql版本和文件版本本质是一样的,加载所有题目,一个从文件中读取,一个通过mysql客户端的相关接口从相应数据库中读取,此处不再赘述。
2.1.2 View模块
View模块完成前端相关网页内容的处理,是直接与返回的前端内容相关联的模块。
View模块中,有可以直接读取内容返回给前端的html网页,也有需经过渲染处理再返回给前端的html网页——比如说,题目列表界面,展示的一道道题目信息,格式相同,但具体内容不同;又比如,具体题目,排版都是相同的,只不过题目信息不同。
所以,View模块提供三个接口,一个是GetHomePage获取首页,一个是AllExpandHtml获取题目列表页,另一个则是OneExpandHtml获取具体题目页。
那么如何利用Model模块中提取的数据渲染呢?
我们采用第三方库,ctemplate。
这个库可以对一个html模板文件进行渲染,即将相应内容单个或循环式地替换进html模板文件中。以下介绍其如何使用:
OneExpandHtml实现:
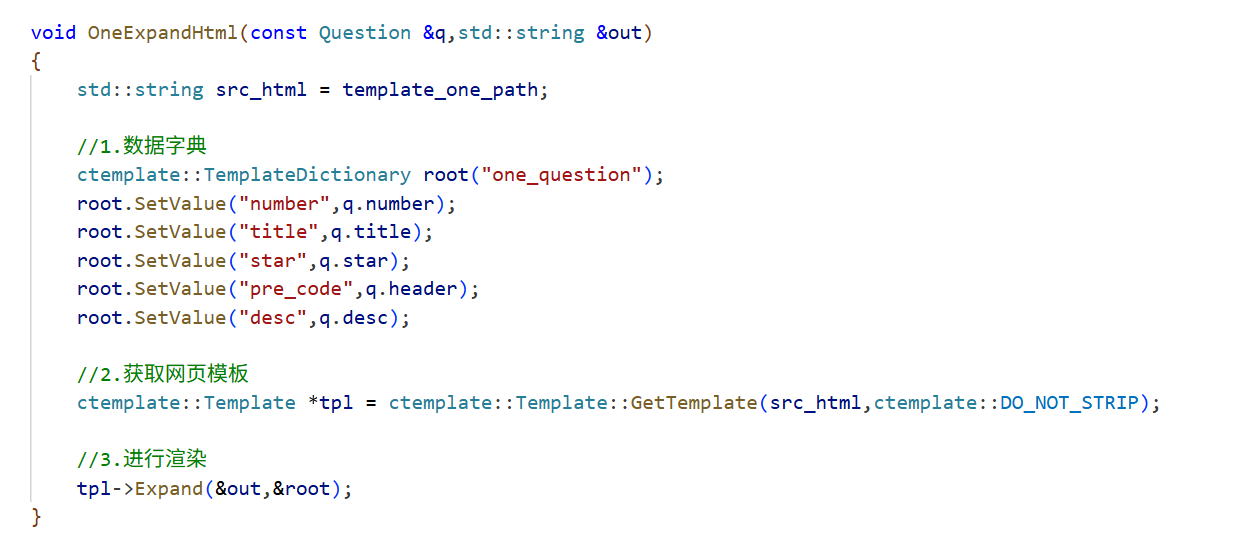

第一张图是View模块代码,第二张图是相关html网页代码。
使用Ctemplate库进行html模板替换:
- 构建一个数据字典,使用ctemplate::TemplateDictionary。为这个数据字典,通过SetValue,设置一系列KV值。
- 获取
html模板。通过GetTemplate接口读取html模板网页内容到内存中,使用一个Template类型的指针进行管理。 - 进行模板数据替换。现在有一系列KV值,又有相应的html模板文件内容(内存中数据,不会影响磁盘文件),通过
Expand接口,将html模板文件中用双重花括号括起来的键值,用数据字典中相应的value值进行替换,并将替换后的结果,由传入参数中的string带出。
AllExpandHtml实现:
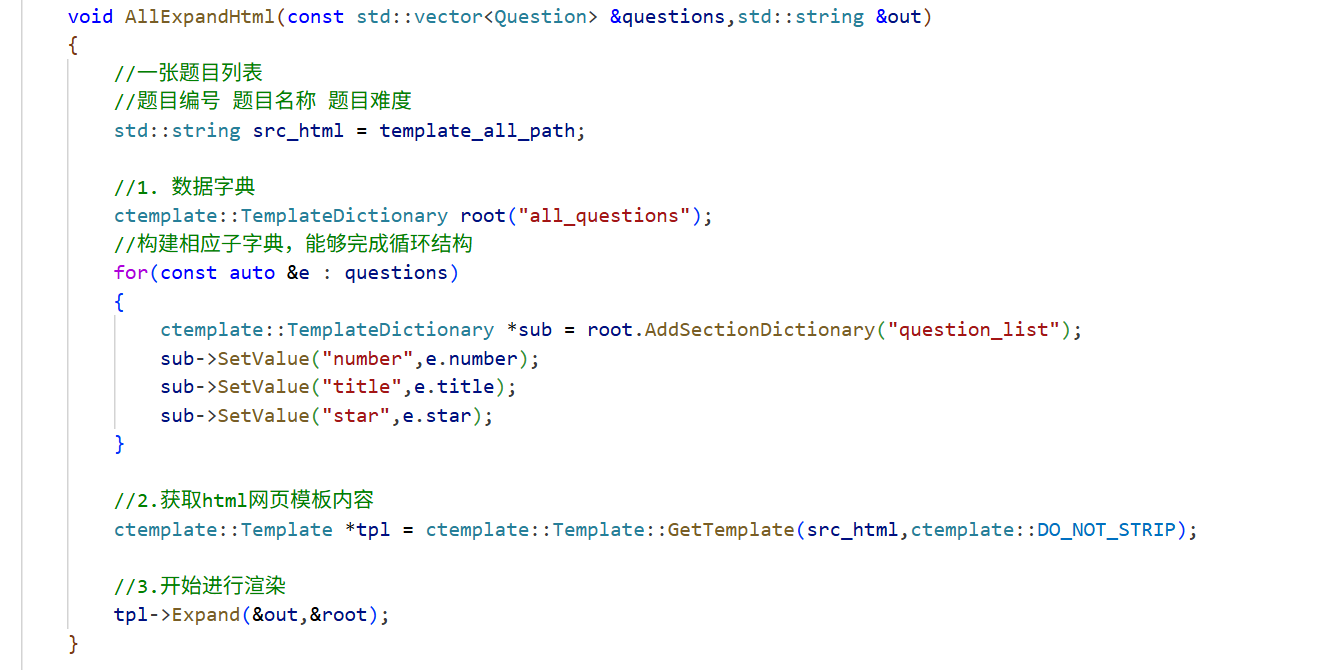

题目列表html网页模板的替换,步骤与OneExpandHtml基本相同,只不过其中替换引入了循环替换。
循环替换要求根数据字典构建相应的子数据字典,每个子数据字典中分别构建相应的KV值,以进行循环替换。
循环替换时,html模板中,依旧是是双重花括号中的内容替换,但因为循环替换,得将整个需要替换的模板内容放入到ctemplate能识别的循环结构中:
{{#question_list}}{{/question_list}}
上述question_list不是随意命名,而是与子数据字典名称相同。
2.1.3 Control模块设计
Control模块,顾名思义,是用来综合控制Model和View模块执行逻辑,以实现不同功能。
Control模块设计时,设计一个Control类,其中包含Model和View类的具体对象,对外提供获取首页,获取题目列表,获取具体题目,以及判题功能的四个接口。 这样,外部仅需创建一个Control类对象,即可实现功能路由。
获取首页,获取题目列表和具体题目,本质就是调用Model获取相关数据,再利用数据通过View进行渲染,然后用一个string串存储渲染后结果,此处不多做赘述。
我们重点来谈一谈Judge,即判题功能实现。
判题功能,本质就是将代码通过网络传输到编译运行服务相关机器上运行,然后再接收判题结果。
看着很简单,但其中存在两个难点:
- 判题功能首先肯定通过传入参数拿到用户代码,但是用户代码能够直接交给编译运行服务吗?
- 编译运行服务机器有很多台,我怎么知道要传给哪台,即如何做好负载均衡选择。
第一个问题:用户代码能直接交给编译运行服务吗?
不是所有的用户代码都可以直接交给编译运行服务,IO型的可以,因为是完整程序;但接口型不行,还需拼接具体的测试用例代码,即包含main函数的代码——这个工作是需要在judge中完成的。
第二个问题:负载均衡如何实现?
负载均衡本质是编译运行服务的选择,但选择前,首先要知道有哪些可以选,即要知道有哪些机器,并且将这些机器管理起来——先描述,再组织。
我们通过设计一个成员变量暴露给外部的machine类,来描述一个编译运行服务,同时引入LoadBalance,即负载均衡类,对所有的编译运行服务进行管理,以实现负载均衡。
2.1.3.1 LoadBalance模块
LoadBalance模块该如何设计?
管理所有机器,使用一个vector<Machine>实现,而对于每一个机器,可能是上线,也可能是离线,因此还需要两个vector,一个online和一个offline。
实际管理时,根据RAII风格,在LoadBalance类的构造中,需要加载所有机器的信息,如何实现——可以写一个记录有所有机器信息的配置文件,LoadBalance模块中加载机器,本质就是读取配置文件,获取机器所对应的ip和端口。
以下具体说明如何加载机器:



第一张图表示需加载的三台机器的IP和PORT。加载机器时,就是从文件中按行读取每行内容,然后对每行内容根据分隔符进行切分。
字符串根据分隔符切分,无论是使用C接口strtok,还是说使用C++中的find+substr都是可以的,此处我们使用boost库中提供的字符串切分接口,如图三所示。
boost::split(target,str,boost::is_any_of(sep),boost::algorithm::token_compress_on)
target:表示存储切分后得到多个字符串的容器,要求元素支持由string进行构造,并且支持push_back操作。str:待切分字符串is_any_of(sep):本质与strtok中的第二个参数类似,表示分隔符串中的任意一个字符都可以作为分隔符。boost::algorithm::token_compress_on:表示允许空串压缩。意思即如果存在两个分隔符紧挨的情况,会进行压缩,不会将空串存储到target中。
这样就提取到所有机器信息,并存储到相应容器中。默认从配置文件中加载时,默认所有机器是上线的,所以还需将机器使用online管理,但是无需再使用Machine,可以直接用vector<Machine>中的下标代指指定机器。之后所有机器的上线与下线,都是对online和offline中的机器下标id做管理,vector<Machine>无需更改。
特别说明,上述仅仅是加载机器配置信息,并进行管理,实际编译运行服务的上线,需要手动运行起相应程序。
有了所有机器信息后,即可进行负载均衡式选择。
负载均衡策略如何?
使用负载因子,轮询式,随机数式等等都是负载均衡策略。本项目中,我们采用负载因子实现负载均衡。
在Machine中,引入load作为负载因子,初始值为0,并提供对负载因子增减和重置的接口。由于多线程并发,一台机器的负载因子,多个线程可能会同时更改,因此必须引入互斥锁,一台机器,一个互斥锁。在进行任何负载因子修改时,必须加锁保护。
LoadBalance模块负载均衡SmartChoice策略:遍历online中的所有机器,找到load因子最小的机器,通过输出型参数,带出相关机器信息。
LoadBalance由于进行Machine管理,所以还需提供Online_Machine和Offline_Machine的接口。
无论是负载均衡,还是上下线机器,是否存在并发问题呢?答案是肯定的。因此负载均衡模块中,必须提供一把锁,用于保证上述行为在多线程中的互斥。
所以,保证多线程安全,出现了两类锁,一类是LoadBalance中的一把锁,另一类是一台机器的锁。
我们必须明确,进行负载均衡选择时,可能存在另一个线程即将对机器的负载因子做出改变。但是二者是不冲突的,负载均衡选择选择的是那个时刻负载因子最小机器,至于未来如何,并不关心,也无法关心。
2.1.3.2 Control中Judge逻辑
oj_server的control中的judge,输入型参数是用户提交的代码,输出型参数是用户提交代码的运行结果。
首先,要完成的是用户代码的拼接工作。之后,是负载均衡式选择。
选定某台机器后,便向指定机器发起http请求,然后接收应答。对于http请求的发起和应答,不再自己从基础开始造轮子,而是使用httplib中的接口。
httplib为我们封装好网络通信的相关服务,而且设计为Header-Only模式的,仅需包含头文件便可直接使用,无需额外引入库文件。
但是,机器可能会出现离线情况,请求负载最低的机器一定会成功吗?
所以,必须进行差错处理。如果请求机器挂掉了,就执行机器离线逻辑,然后循环式地继续执行负载均衡选择+http过程,直到所有机器都挂掉了,才跳出循环。
下面是,Judge中负载均衡选择主机,并发起http请求和接收应答的代码:

2.1.4 oj_server.cc
整个oj_server模块,MVC的实现,全部采用hpp的方式,最终仅包含一个源文件——在该源文件中,包含控制模块,即可实现完整的功能路由。
功能路由本质就是接收http请求,根据实际http请求方式以及请求资源路径的不同,进而实现执行不同的功能模块,本质就是执行不同回调。

由于oj_server本身的模块化设计,oj_server.cc源文件中的功能路由,实现非常简单。
根据实际的http请求方法和uri,执行不同回调,回调中调用控制模块的相应功能接口,传入相应参数,通过输出型参数带回结果后,http应答设置相应body内容,以及body的文本格式和编码方式即可。
2.3 compile_server模块设计
compile_server模块是执行判题功能的核心模块。
对于这个模块,可以直接拿到用于编译运行的代码,因此核心功能就两个:compile 和 run。
因此,该模块设计时,分成三块:compile,run和compile_run。
compile_run就是综合控制compile和run两个部分,同时进行差错处理,有点类似control模块。
2.3.1 compile
在compile模块中,我们只关心编译工作,即认为编译的所有准备工作已经完成。
编译服务,实质就是进行进程替换:先fork子进程,然后在子进程中进程替换;父进程中进程等待,同时可以通过可执行文件是否存在,来判断编译是否成功。
实际编译时,如果发生编译错误,我们希望拿到这个错误信息,并返回给用户,而编译时错误信息默认是向标准输出打印,因此还需进行重定向,将相应错误信息输出到指定编译错误文件中,方便后续读取。
2.3.2 run
在run模块中,我们只关心运行工作,认为此时可执行文件已经存在。
运行服务,本质也是进程替换。
实际运行过程中,对于运行程序的标准输出,标准输入,标准错误,需要全部进行重定向,以便之后处理。
程序实际运行过程中,可能正常运行完毕,也可能因某些错误而被信号异常终止,这些信息都可以在父进程中,通过waitpid中的参数status得到。这个参数需要通过run进一步返回给上层,以便将程序实际运行成功与否相关信息返回给用户。
run模块就完成了吗?
在实际OJ平台中,还存在程序运行超时以及内存使用超出限制等情况。这些本质都是OJ平台后端对可执行程序的限制——这些限制对于算法题是必须的,同时也是对本身后台服务与机器的保护。
那么如何限制程序的CPU时间和可占用memory呢?通过setrlimit系统调用实现。
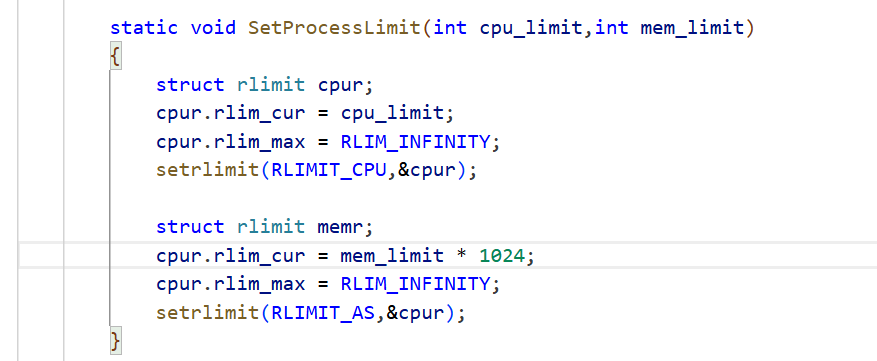


setrlimit重点是struct rlimit这个结构。有两个限制:一个软限制,一个硬限制。软限制本质是实际限制,普通进程允许在实际硬限制范围内调整软限制,但不允许将硬限制调高,硬限制是用来限制软限制的。
如果要设置CPU运行时间,使用RLIMIT_CPU;设置虚拟内存使用,使用RLIMIT_AS。
2.3.3 compile_and_run
这个模块对整个编译运行进行逻辑控制,同时与oj_server中的control进行网络交互。
compile_and_run中,已经包含编译运行的具体逻辑,也已经拿到相应代码,如何组织呢?
具体组织流程如下:
- 首先,将获得的代码写入代码源文件中,用于之后的编译,如果这步失败,跳转到错误处理逻辑。
- 执行编译服务,得到实际可执行文件,编译成功,继续执行,否则跳转错误处理。
- 执行运行服务,实际运行,可能失败,可能成功,通过
run模块中的返回值进行具体判断。
上述存在多种错误,因此可以统一进行错误处理。上述不同错误中,可以使用status进行记录,方便之后统一错误处理。
status记录情况,可分四类:代码编译错误,用户代码有问题;代码运行错误,用户代码问题;自身相关服务代码出问题,不想暴露给用户,返回未知错误;代码编译运行一切正常。
统一差错处理中,根据不同的status值,返回不同的描述。
2.3.4 compile_server.cc
与oj_server模块中相同,其余文件都是hpp文件,只包含一个源文件,其中包含compile_and_run即可,使用httplib完成功能路由。
3. 前端交互
关于首页和题目列表界面,就是返回一个html,没有前后端交互。但是具体题目界面,存在交互。
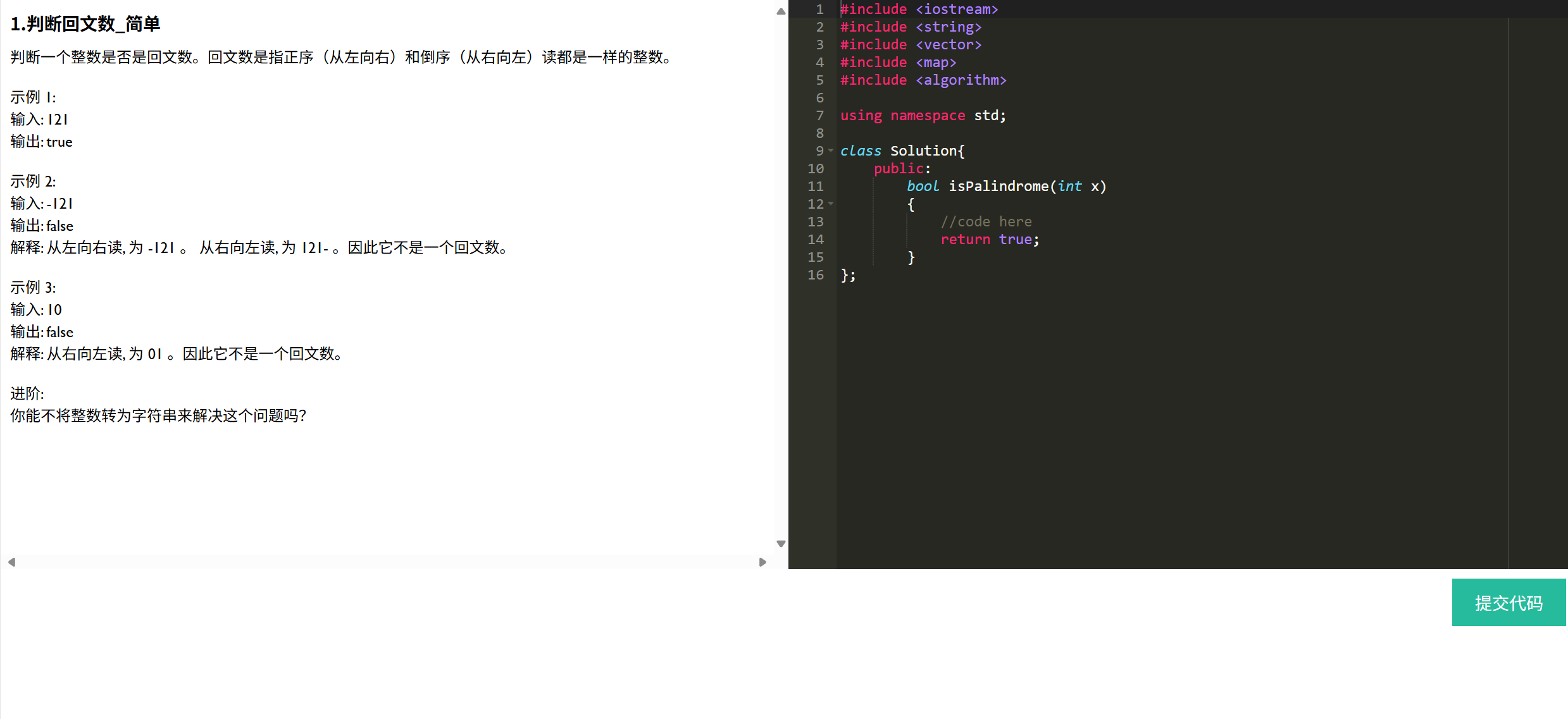
关于前端,想谈的有三点:右侧这个编辑区域是什么,编辑区域中的代码提示和补全功能如何实现,以及用户代码如何提交给后端。
3.1 ACE编辑器
右侧编辑区域,是一个ACE编辑器,属于前端资源,本质就是用前端脚本语言javascript写成,然后由浏览器解析渲染完成的。
ACE编辑器本质已有线程js脚本代码,通过CDN方式,即内容网络分发,部署在各个服务器上。因此,我们无需在自身html中增添这部分,直接使用CDN方式交由浏览器解析,而后引入即可。
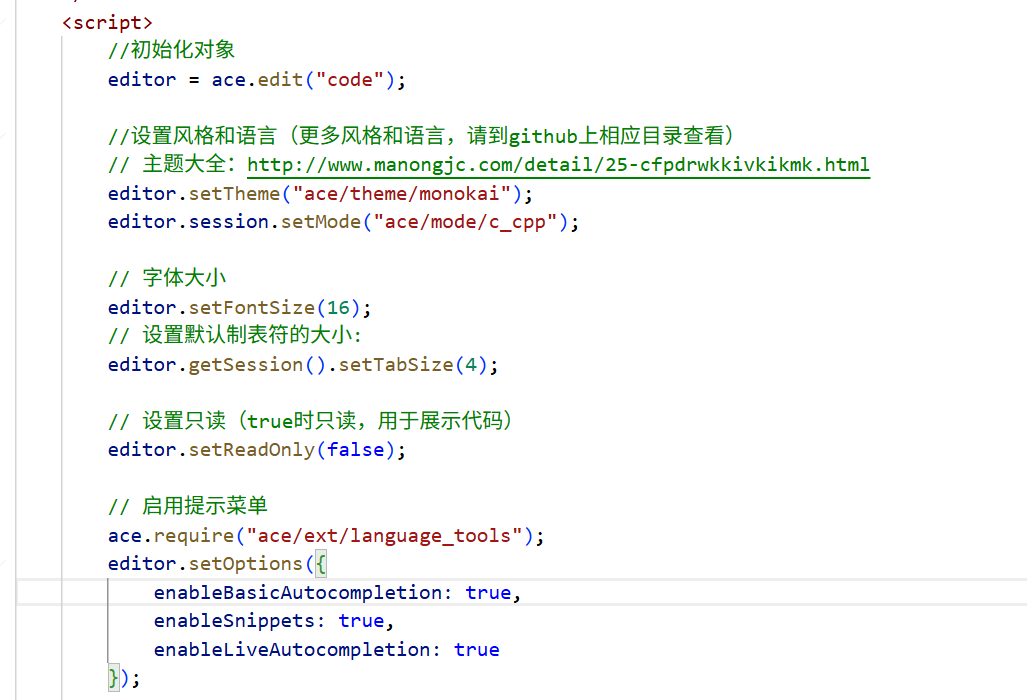
3.2 代码提示和补全
ACE编辑器自身具备一定的代码提示和补全功能,不过需要额外使用CDN引入ACE编辑器的扩展模块ext-language-tools。
引入ACE编辑器及其扩展模块CDN后,通过脚本语言,进行相关设置,即可给用户提供代码编辑功能。
3.3 代码提交功能
代码提交功能,在前端涉及如何与后端进行交互。
核心就是,用户的代码在ACE编辑器中写好了,如何将用户的这些代码发送给通过http发送给后端,再从后端接收应答。
这个前后端交互功能实现,可以通过javascript脚本语言和ajax(一种前端与后端进行异步通信,可以实现网页部分更新的技术) 实现,但是直接写原生的js脚本语言过于复杂,因此引入jQuery库。
jQuery库本身是js语言中提供的库,已经为我们用js语言写好了各种功能接口,相比原生js,使用更为简单。
同样通过CDN方式引入jQuery库。
使用jQuery库,目的明确:提交代码,获取代码执行结果。


首先,为提交代码的按钮设置点击后的触发函数oneclick=submit()
在submit函数中,从ACE编辑器中获得用户编辑代码,通过class与id,将相应的number拿出,进而构建出所访问服务器服务的url。
然后通过ajax构建httprequest,并发送给相应的后台服务器,如果成功拿到httpresponse,即状态码为2XX的情况,就会走sucess逻辑,进行一个function的调用,其中函数的传入参数为data,表示实际http response中,正文body的内容。
3.4 显示运行结果
上述逻辑走完,已经完成用户代码提交以及运行结果的返回,之后便是如何显示运行结果。
显示运行结果,我们采用ajax技术,对网页进行部分更新,而非整体刷新,这样用户的体验会更好。
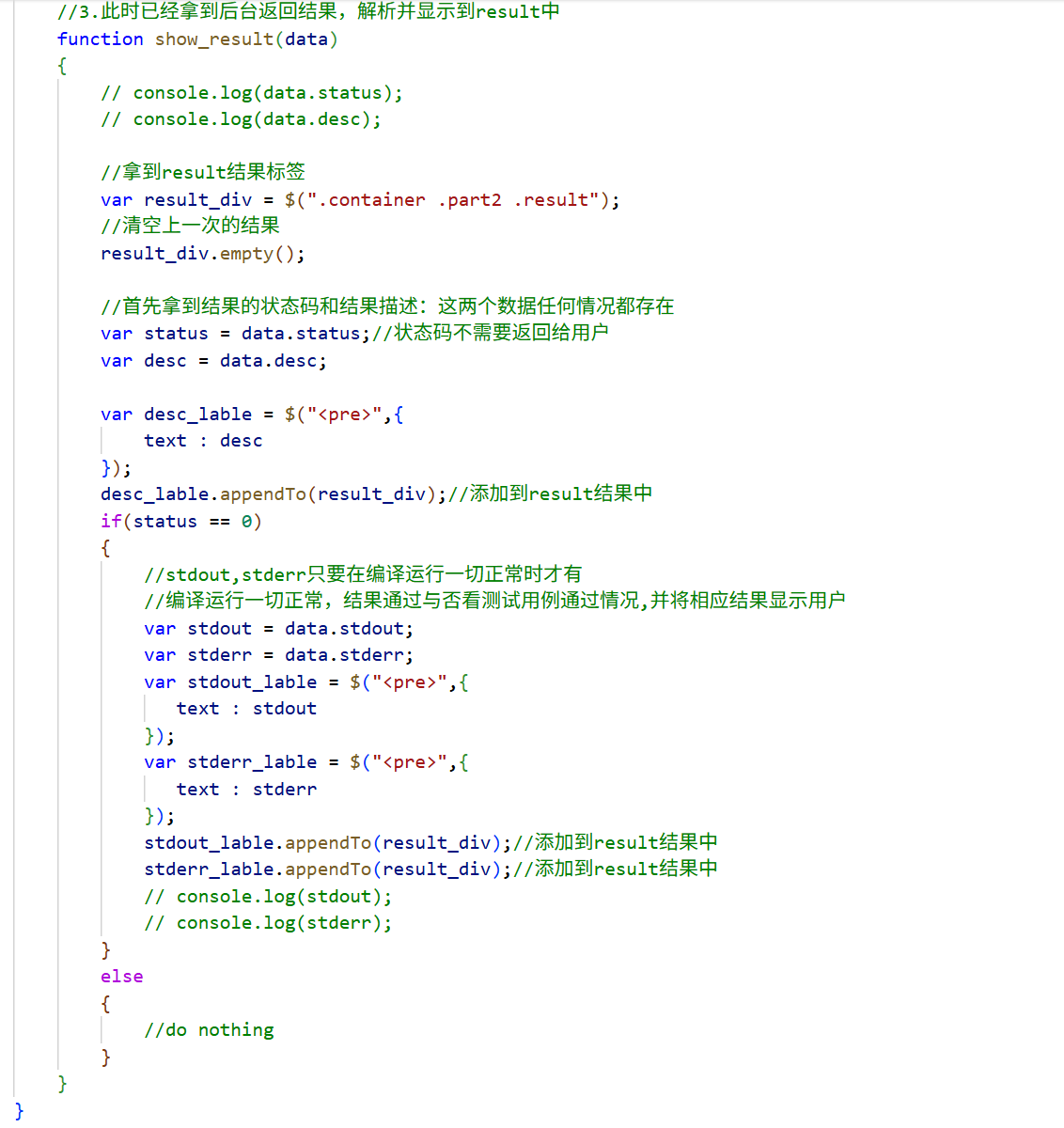
首先,通过class属性,拿到result所属的具体隔离区块,即div标签区域。
再通过data中的内容,即httpresponse的正文部分,将status和desc拿出,再根据status的值,决定是否取出stdout和stderr(与后端设计相关,只有成功编译运行,status为0,才会添加stdout和stderr内容)。
取出所有结果后,统一以pre标签的形式,将相应内容添加到result所属的隔离区块中进行显示。相应内容本身就是最终要显示的内容,因此标明text,表示使用纯文本插入,不用再做html解析,也不用担心编码问题——因为data中的内容本身就已经是按约定编码方式解析之后的内容,当作纯文本插入,无需再做解析。
这样,我们就通过ajax技术实现了在result显示区域的网页部分更新。而由于是部分更新,所以每次show_result前,都需要清空result区块中的内容,因为后续内容的插入方式是append,即追加。
4. 项目总结
4.1 项目的模块化设计
整个OJ项目的模块化与解耦工作完成较好:公共模块comm提供util.hpp和log.hpp, oj_server模块采用MVC设计模式, compile_server模块也合理将compile与run解耦,并使用compile_run进行综合控制。
模块化与解耦带来的好处是方方面面的:不仅仅使得整个项目的结构更加清晰,实现每个具体模块也更加简单,因为每个模块在一定程度上仅需要考虑做好本模块的工作即可,当然出错时Debug也更加方便了。
以网络传输中的序列化和反序列化为例。在本项目中,其方式使用的json串。
在用户提交代码的交互中,前端由浏览器形成json串,发送给oj_server模块,该模块中将json串反序列化后,添加额外题目信息后,再序列化发送给后台编译运行服务。
编译运行模块再反序列化拿到相应信息后,完成编译运行后,再将结果序列化为json串,继续返回,直至返回至前端,反序列化解析出结果并显示。
4.2 技术亮点
本项目以MVC结构设计oj_server模块,Model中提供文件和数据库两种加载数据的方式,同时使用boost库中字符串切割函数进行文件数据提取,View中,使用ctemplate库进行html渲染,Control模块中,对于后台编译运行服务,负载均衡式选择。
前端与后端,以及后端各个模块间的网络通信,使用httplib第三方库实现,网络通信中的序列化与反序列化工作借助第三方json库实现。
前端用户代码的提交中,通过CDN引入ACE,ext-language-tools实现代码的在线编辑功能,同时引入jQuery,借助ajax技术,实现前后端异步通信,完成用户代码提交,以及以网页部分更新方式实现代码运行结果显示。
5. 项目发布:顶层Makefile
项目完成后,完善ReadMe.md 文件,并实现顶层Makefile,用于项目发布,再将整个完整项目开源到gitee或github上。
该OJ项目gitee链接如下,欢迎读者们参考,如果感到有所帮助,可以star收藏一下:负载均衡式在线OJ