PostgreSQL 全表 count 优化实践:从 SeqScan 痛点分析到 heapam 改进与性能突破
❝本文整理自 IvorySQL 2025 生态大会暨 PostgreSQL 高峰论坛的演讲分享,演讲嘉宾:权宗亮。
本文主要包括以下三部分:
SeqScan 现状
heapam 改进
全表计数
SeqScan 现状
我们使用了一个稍宽的 SeqScan 表,包含约 10-20 个字段,记录数达 1,000 万。填充因子约为 50%,生成的数据总计 2.63 GB,占用约 34.5 万块磁盘空间,大致如此。
以下是其尺寸详情:

其执行计划较为简单,包括两个主要操作:一是全表扫描,二是对全表进行 count(*)。
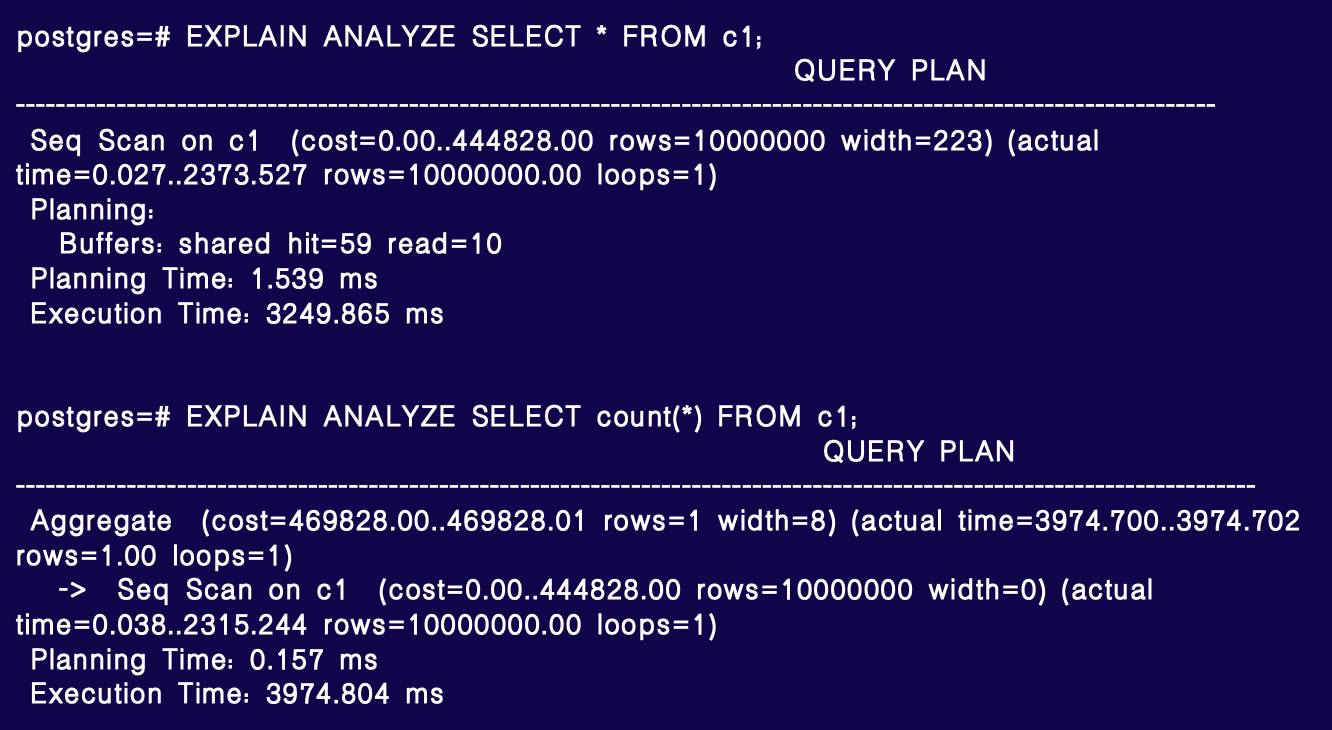
全表扫描的顺序扫描耗时约 2.4 秒,是主要的开销,其余时间可忽略,可能是数据传输开销。
对于 count(*),总耗时约 4 秒,其中顺序扫描(SeqScan) 2.3 秒,占用了大部分时间。
目前来看,这种方式看似不常规,正常情况下较少使用。但在实际场景中,一旦文档中提及相关内容,用户就可能尝试使用。
我们有一位客户,其表包含数千万条记录,业务设计要求每隔一段时间进行全表计数,以统计新增记录数。客户未透露具体业务逻辑,且不愿调整设计。在某些商业数据库(如国产数据库迁移场景)中,客户常提出类似需求,强调现有方案高效(如“某某产品很快”),并要求我们的数据库支持。若试图协商,他们通常以竞争产品为基准,认为我们需跟进。类似情况普遍存在,处理起来颇费周折。
对于 PostgreSQL(Pg),数千万条记录在当前架构下压力较大。客户采用火山模型逐次 next 计数,count 操作中未利用索引或优化,纯靠顺序扫描(SeqScan),效率较低。相比之下,某商业产品(暂不具名)经长期对比测试,同样为 SeqScan,但性能高出约 2.3-2.4 倍。例如,Pg 耗时 2.3 秒,而该产品仅需 1 秒,测试在同一机器、相同配置下进行。该商业产品确实优秀,具备 Pg 尚未完全实现或优化的特性,这点无可否认。我们将继续努力改进。
heapam 改进
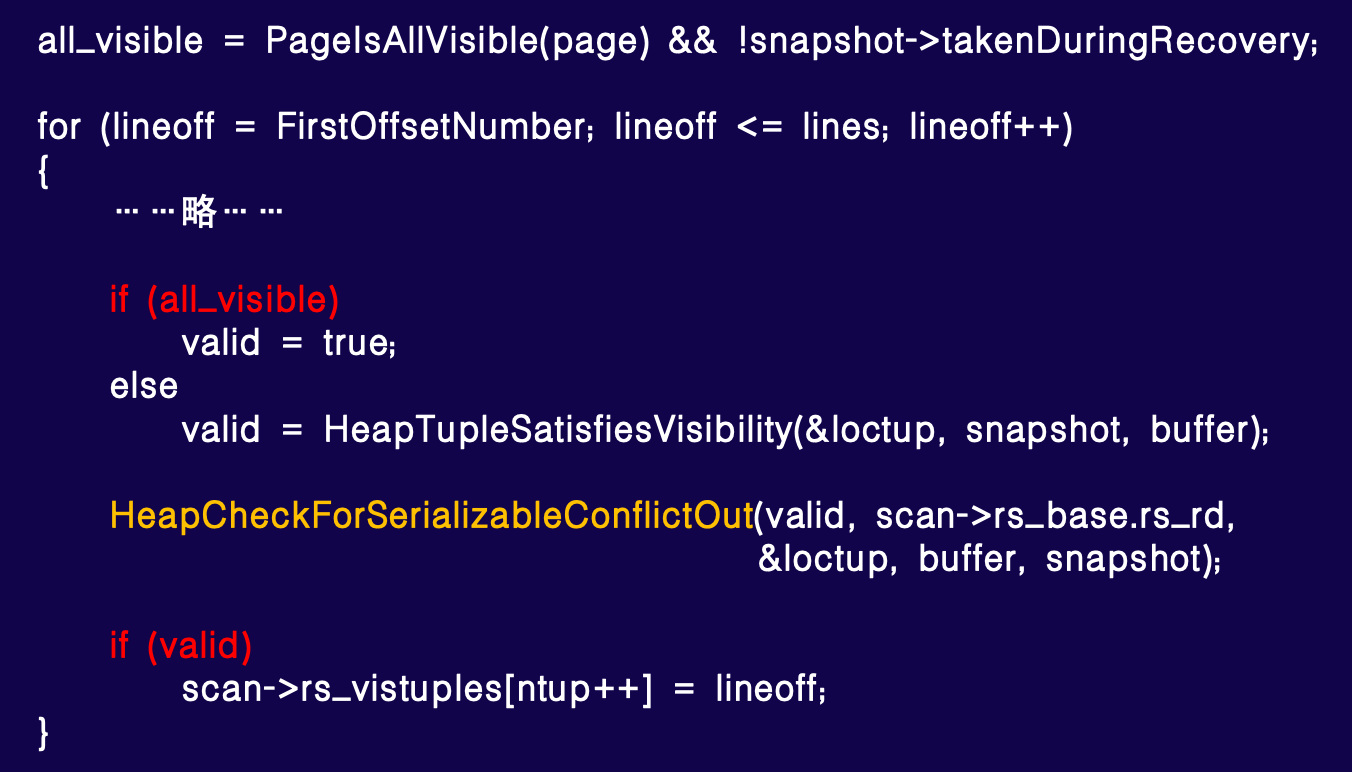
这是 PostgreSQL (Pg) 的一段代码,用于扫描一个数据块时,首先检查块首的 VM (visibility map) 是否标记为全可见,且通常不发生在恢复过程中。因此,在大多数情况下,如果表的 all_visible 比例较高或改动影响较小,代码可能跳到此处,相关逻辑基本无用。
我们通过英特尔 VTune 等性能分析工具深入分析这段代码,发现部分开销无必要。常规情况下的 HeapTupleSatisfiesVisibility 检查(标红部分)以及底部的序列化冲突检查 HeapCheckForSerializableConflictOut(标黄部分),在 all_visible 为真时,多余且耗时。标红的两个条件判断及后续函数调用(如序列化事务检查),在默认或一般场景下几乎不使用,因此开销可忽略。

发现这一问题后,我向社区提交了一个补丁(Commit a97bbe1f,Reduce branches in heapgetpage()'s per-tuple loop;),但因晚了约两个月,期间另一位开发者已提交了类似补丁。应用该补丁后,成功消除了这两块冗余逻辑。
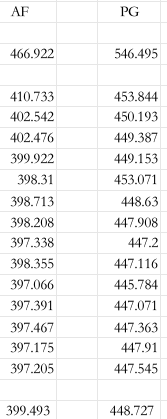
这是我当时进行的测试。AF 代表优化后的版本,PG 为原始版本。测试结果显示,平均耗时从原先约 450 毫秒降至 400 毫秒,优化幅度显著。
不过,随着新技术引入,当时的提升效果跟现在比并不大。但在当时测试中,确实取得了明显改善。测试使用了一个包含 1,000 万条记录的表,通过跳过无关数据逐步扫描,减少其他干扰,最终得出此结果。
从结构上看,每次处理时并非直接提取数据,而是根据可见性记录每个 block 或配置中哪些项(item)可见。这些记录(如 item pointers)会先保存下来,再根据元组(tuple)位置逐一提取。此处可能有优化空间,若批量解压元组,或许能提升效率。目前的逻辑是返回后再次解压元组,依赖 item pointers 跳转至具体位置,再进行解压操作。尤其在 count 操作中,众所周知这些步骤本无必要,因此优化潜力较大。但受限于当前框架,改动难度较高,改进空间受限。
全表计数
在 PostgreSQL (Pg) 中,可见性视图位图(Visibility Map)是众所周知的功能,包含两个标志位:ALL_VISIBLE 和 ALL_FROZEN。当设置 ALL_VISIBLE 时,块头(Page Header)中会同时标记一个 PD_ALL_VISIBLE 标志。这样,可通过位图读取块的全可见性,也可直接从块头确认。
若块标记为全可见,则可跳过先前逻辑,提前计算。因为一旦 ALL_VISIBLE 被设置,若块变为不可见,该标志会被清除。因此,全可见状态表明块相对稳定,至少在一段时间内未被修改。

因此,我们采用了一个相对简单的方法,在页面头部新增了一个字段,并在设置 pd_upper 时计算其值。
接下来的优化重点是改进优化器,在路径选择时根据表的 all_visible 比例判断最优路径。若表非全可见,逐块访问效率较低,走索引可能更优。因此,需让优化器了解全表扫描(Seq Scan)的成本可基于 all_visible 比例降低。优化器获取数据后,Aggregate(agg)通过 next 操作在 Advanced 阶段统计,但当前执行器需改进,使其直接获取块数量,而非逐条挖掘数据。即使块全可见,若不优化,传统逻辑仍需循环处理 item pointers(物理位置指针,指向磁盘存储位置),提取元组再交给聚合引擎,效率不高。若跳过这些,直接利用 all_visible,可显著提升性能。
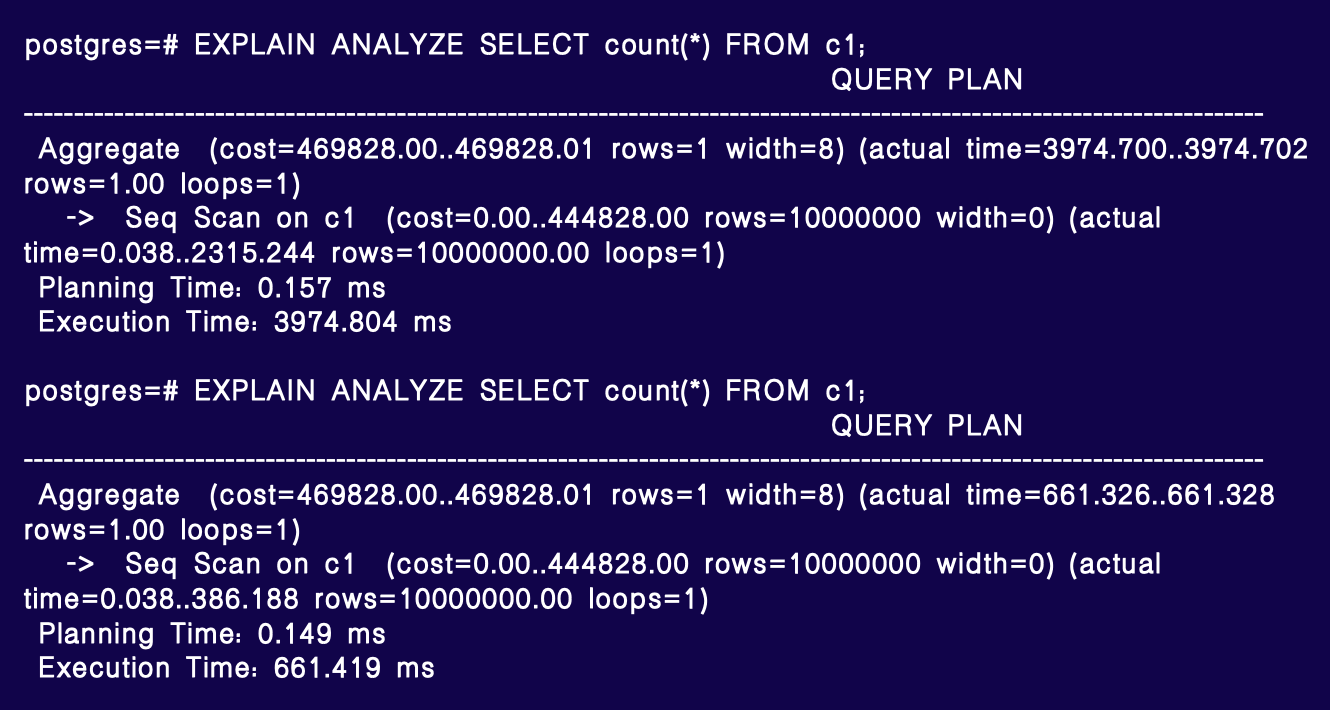
此改动目前不够优雅,优化器调整尚符合框架,但执行器改动较为生硬。不过,总算解决了用户问题。以 SELECT count(*) 为例,原始耗时约 4 秒,优化后在全可见理想状态下降至约 661 毫秒(约 1/6),极端情况下可达 10 倍提升,视缓存命中率而定。缓存命中率低时,优化效果更明显。
此改进针对 count 操作简单实用,旨在缓解用户频繁对千万级表执行 count,大幅减轻 PostgreSQL 压力。
总结
本文围绕 PostgreSQL 全表 count 这一核心场景,从现状分析、技术改进到落地效果展开了完整梳理。
尽管当前执行器改动仍有优化空间(如批量解压元组的框架限制),但这些实践已切实解决了用户在千万级数据表计数中的核心诉求。未来随着 PostgreSQL 底层框架的进一步迭代,全表 count 的效率仍有提升潜力,而本次从业务痛点出发、基于代码层与特性层的双重优化思路,也为后续类似性能问题的解决提供了可参考的实践路径。