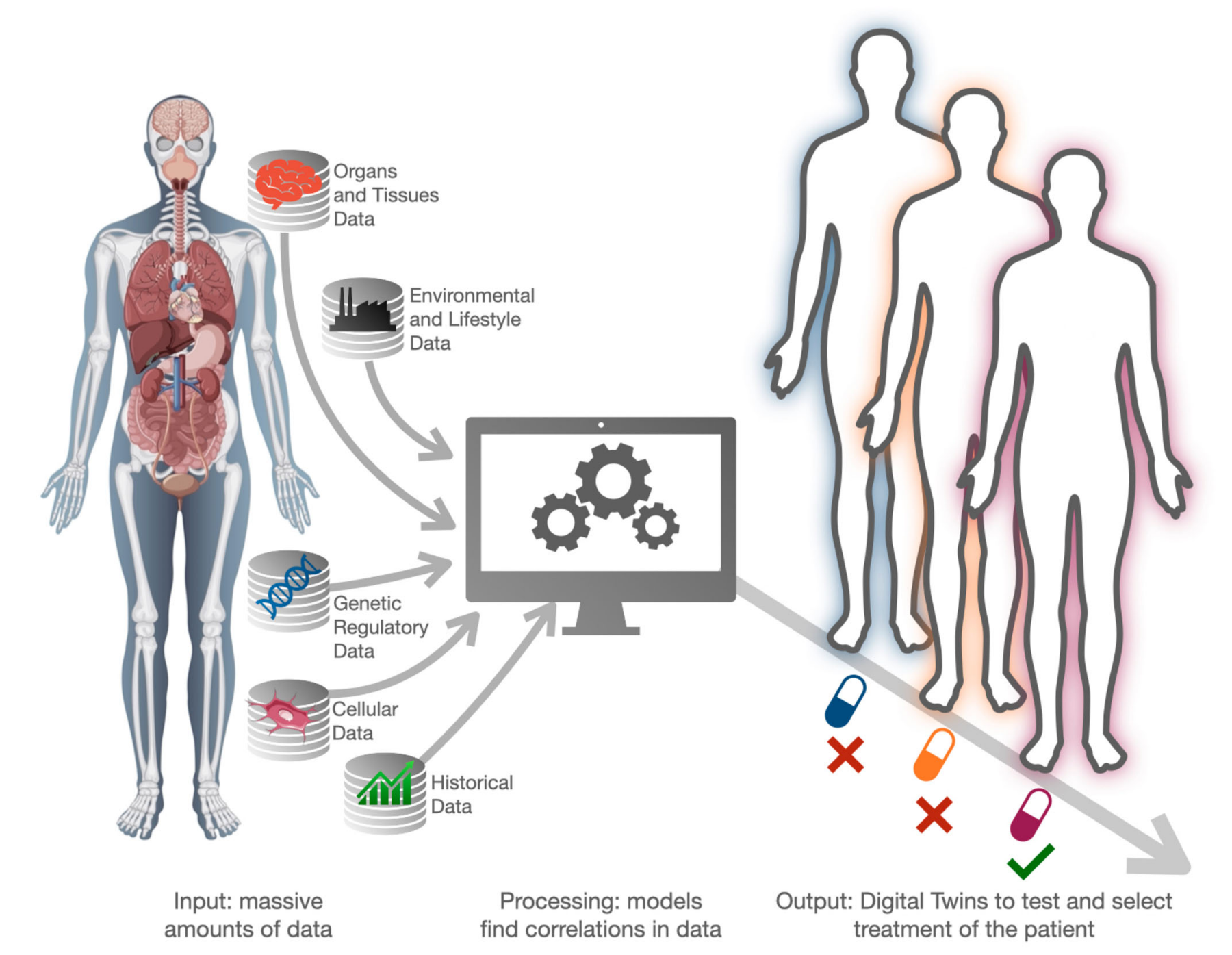
【complex system science 4 precision medicine】
we can now extract large-scale human behavior data of bio-medical relevance from social media, mobile devices, and electronic health records, includingnewpatient-stratification principles and unknown disease correlations
如今,我们能够从社交媒体、移动设备和电子健康记录中提取与生物医学相关的大规模人类行为数据,包括新的患者分层原则和未知的疾病关联。
—— Challenges and opportunities for digital twins in precision medicine from a complex systems perspective 从复杂系统视角看数字孪生在精准医学中的挑战与机遇 DOI:10.1038/s41746-024-01402-3
引文:
Hoffman, J. M., Flynn, A. J., Juskewitch, J. E. & Freimuth, R. R.Biomedical data science and informatics challenges to implementing pharmacogenomics with electronic health records. Annu. Rev. Biomed. Data Sci. 3, 289–314 (2020).
生物医学数据科学与信息学在电子健康记录中实施药物基因组学的挑战。
https://doi.org/10.1146/annurev-biodatasci-020320-093614
本文系统梳理药物基因组学在电子健康记录(EHR)中落地应用的现状、挑战与前景:其一,临床决策支持(CDS)与离散、可计算的基因结果是发挥药物基因组学改善用药安全与疗效潜力的关键,而当前在信息标准、知识管理与EHR能力上的不一致严重限制了可扩展性;其二,CPIC、PharmGKB、PharmVar、HL7 FHIR、GA4GH 等资源与标准正在弥补差距,先锋机构(范德堡、梅奥、圣犹大、U-PGx 等)的实践为预检多基因、主动/被动CDS、表型映射与告警治理提供了可借鉴范式;其三,面向未来,需要以生物医学信息学与数据科学融合为引擎,推进自动化基因解读、可共享可计算的知识库、超越“单基因–单药”的综合推荐、可验证的预测分析与学习型健康体系,同时将经验外溢至输血医学、肿瘤学和微生物学等领域。
Jensen, P. B., Jensen, L. J. & Brunak, S. Mining electronic health records: towards better research applications and clinical care. Nat. Rev. Genet. 13, 395–405 (2012).
电子健康记录挖掘:迈向更优的研究应用与临床诊疗
Mining electronic health records: towards better research applications and clinical care | Nature Reviews Genetics
本文围绕利用电子健康记录(EHR)促进科研与临床实践改进的关键议题展开:一是从政策推动、标准化与互操作性建设,到结构化与叙述性文本并存的数据采集与自然语言处理(NLP)技术演进,EHR 为循证医学、临床决策支持和健康信息化带来显著效益;二是通过大规模数据挖掘与多组学整合(基因组学、药物基因组学、微生物组学),EHR 支撑疾病关联发现、队列分层、药物警戒、PheWAS/GWAS 等研究,推进精准与P4医学;三是隐私保护、同意机制与去标识化的法律伦理挑战与再识别风险并存,需在数据共享与个体权益之间取得平衡,以确保可持续的科研与临床转化。
关键要点
- EHR 被视为缩短临床实践与证据之间“推断鸿沟”的关键基础设施,能提升质量并潜在降低成本。
- 互操作性依赖语义标准与临床模型(如SNOMED CT、UMLS、ICD、RxNorm/RxTerms、详细临床模型)。
- 临床文本的结构化与叙述性记录存在张力,NLP(如MetaMap、cTAKES)在信息抽取、编码与决策支持中居核心地位。
- 大规模EHR数据挖掘可发现疾病共病与表型网络,支持患者分层与时间序列疾病轨迹建模。
共病与表型网络:文献明确指出,利用结构化与非结构化(经 NLP 编码)的 EHR/登记数据,可用列联表与不均衡共现(disproportionality)测度,系统量化任意两种疾病在大队列中的共病强度,进而构建“共病网络”(comorbidity networks)(见 p.5–6,FIG. 2a;以及 Medicare 数据示例与网络化研究引用42,58)
患者分层(stratification):通过患者的“特征向量”(包含诊断、用药、实验室与人口学等多模态特征)进行聚类、语义相似度度量等无监督方法,可将人群划分为特征相近的亚群,用于风险分层、预后评估与临床试验入组(p.6–7,FIG. 2c;60,61)
疾病轨迹与时间序列:纵向健康数据的时序挖掘仍相对早期,但已开始用网络方法在大规模理赔/EHR 数据中发掘疾病进展的方向性与轨迹(p.6–7:directionality、trajectory;42,58),并提到对短周期生理数据(如血糖时间序列)已有多种分析方法(59)。隐马尔可夫模型等序列模型被用于刻画疾病发展路径(文献示例:HMM 研究57)
- 将EHR与生物样本库和基因数据联用(eMERGE、i2b2)可开展GWAS与PheWAS,稳健复现基因-表型关联。
平台与网络:i2b2 与 eMERGE 是文中重点介绍的 EHR–DNA 联合研究平台/网络(表 1;p.7;63–66)。其核心是:用去标识化、可查询的 EHR 构建高精度表型;将表型与生物样本库/基因数据联接,实现快速、大规模的病例-对照构建与遗传学研究。Vanderbilt BioVU 采用“临床留样+去标识化 EHR”并以“opt-out”模式取得研究授权(p.7;75),显著提高样本与基因数据的可复用性(p.7)。
- 药物安全与药物再利用研究受益于EHR与文本挖掘,主动药物警戒可揭示药物-不良事件关联。
主动药物警戒的动因与方法:传统自发报告系统对不良事件(ADE)严重“低报”(underreporting)(p.6;44)。文献指出,直接挖掘 EHR 中的处方、实验室与文本(NLP 抽取 ADE 与上下文)可做“主动、计算机化药物警戒”(active computerized pharmacovigilance)(p.6;45)。使用不均衡分析(disproportionality)等统计方法检测药物–ADE 信号,跨国数据池化(如 EU-ADR 项目)可显著增强检出力与外部效度(p.6;46)。
文本挖掘/NLP 的关键作用:文献给出经典实例:用 NLP+统计从海量临床文本中识别药物–ADE 相关性(p.10;45)。同时也用于识别“超适应症用药”“药物相互作用”等(p.6;47)。代表性工具与任务包括 MetaMap、cTAKES、MedLEE、MedEx 等,支持从自由文本中提取用药细节、症状、否定/家族史状态等高价值特征(p.4–5,Box 1;27–31, 106–110)。
- 基于网络与系统生物学的方法把临床表型与分子网络相联,助力精准与P4医学转型。
从单基因到系统层面的转变:多数表型受多基因/通路影响。系统生物学通过蛋白复合体、通路与基因网络分析,将遗传关联与分子机制对齐,解释表型的时间维度与器官/发育阶段差异(p.8;82,83)。“网络医学”利用基因–疾病映射与蛋白互作网络,解释疾病聚类与共病的分子基础:共病程度与遗传重叠程度正相关(p.8;85,86)。
将 EHR 共病/表型网络与分子网络结合:路径:先用 EHR 发现疾病相关性/共病(第1点的网络/方向性),再将这些疾病映射到其已知的基因/蛋白,检验网络层面的重叠与富集,从而提出可检验的机制假说(p.8–9;40,85,86)。随着全基因组测序成本下降,个体层级变异将
能纳入“表型特异网络模型”,为临床决策与个体化治疗提供可计算证据(p.8–9;87–89)。
向精准与 P4 医学过渡:文献引用 Hood 等人提出的 P4 医学(Predictive、Preventive、Personalized、Participatory),强调系统生物学与新技术将推动临床从被动反应到主动预测与参与(p.9;88,89)。关键是把“细粒度 EHR 表型(含共病、轨迹)”与“多组学网络”统一到同一分析空间,使基因变异效应能“精确映射”到表型谱(p.9:需要以 EHR 为核心来细化表型空间,并与多组学对齐)。
Correia, R. B., Wood, I. B., Bollen, J. & Rocha, L. M. Mining social media data for biomedical signals and health-related behavior. Annu. Rev. Biomed. data Sci. 3, 433–458 (2020).
基于社交媒体数据挖掘的生物医学信号与健康相关行为研究
https://doi.org/10.1146/annurev-biodatasci-030320-040844
本文综述了利用社交媒体数据挖掘生物医学信号与健康相关行为的最新进展,重点涵盖两大成熟方向:药物警戒(特别是不良反应与药物相互作用的早期信号)与心理健康相关的情绪/情感分析;同时展示了社交媒体在疫情监测、灾害健康风险、毒品滥用、性与生殖健康、去污名化等领域的创新应用。文章强调社交媒体作为大规模、纵向、近实时的“微观”和“宏观”观察工具,可与EHR、搜索、传感与出行数据等融合以增强预测与干预能力,但也系统讨论了抽样与算法偏差、语言与情境歧义、隐私与再现性等限制,并呼吁改进数据可获得性与方法学以支撑可解释、可验证的健康模型与精准干预。
关键要点
- 社交媒体提供大规模、纵向、人群与个体层面的行为数据,已成为生物医学与公共卫生研究的重要“现实世界数据”来源。
- 药物警戒方面,社交媒体可提前发现不良反应(ADR)与药物相互作用(DDI)信号,弥补FAERS与EHR等传统报告的漏报与偏差。
传统与不足:监管侧重 FAERS 等自发报告,但存在漏报、低估严重度、就诊时点“反应性”记录等问题(p.3–4)。
社交媒体增益与案例:搜索日志+FAERS 组合,ADR 检测准确率提升约 19%(White et al., 2014)(p.4)。Twitter 上糖皮质激素治疗讨论显示失眠、体重增加更常见,而严重不良反应讨论相对更少,揭示“患者关注点/生活质量影响”与官方数据库差异(p.4, 20, 45, 52)。比对 EHR 与社媒:阿司匹林/阿托伐他汀在 EHR 常见 ADR 与社媒担忧基本一致,但社媒发现 EHR 中较少的低血糖等“被忽略信号”(p.4, 48, 64)。
进展与生态:自 2015 年起 SMM4H 等共享任务推动 ADR 提及识别、术语抽取与标准化,形成方法与语料社区(p.4–5, 71–72)。早期多在健康论坛(DailyStrength、MedHelp、Yahoo Groups)验证社媒可作上市后监测工具(p.5, 73–82)。
- 将网络讨论与搜索日志、临床数据库结合,可显著提升ADR检测准确率,并更好反映患者对生活质量影响的主观体验。
典型融合路径:FAERS+搜索日志:提升 ADR 识别性能(p.4, 63)。社媒+EHR:对齐高频 ADR,同时发掘数据库稀有但社媒常见的反应(p.4, 64)。社媒+出版物/知识库:以 DrugBank/文献为金标准或证据交叉验证(p.6–7, 13, 99)。
主观体验优势:社媒更充分反映“生活质量影响”的诉求,如“失眠”“体重增加”“焦虑”等易被临床低估的症状(p.4, 52–53)。
- 面向语言不一致性与俗语表达,词嵌入(如Word2vec)、主题模型与序列标注(如CRF、ADRMine)等方法有效提升ADR抽取性能。
语言不一致挑战:不同平台、群体、疾病与文体(短推/长帖)导致术语变化与口语化(p.5–6, 71)。
方法工具箱:主题模型与分布式语义:SVD/主题模型、Word2vec 聚类同义或相关表达,构建高质量词表(p.6, 89–95)。序列标注+嵌入:ADRMine 用 CRF+词嵌入特征在 Twitter/DailyStrength 上显著提升 ADR 提及抽取(p.6, 96)。估计 ADR 发生率:Word2vec 提升多平台(Twitter、Reddit、LiveJournal)精神科药物 ADR 率估计,与 SIDER 对比一致性更好(p.6, 97–98)。
约束:深度方法依赖大规模标注或弱标注语料,更适于高频药物/ADR(p.6)
- 情感/情绪分析借助词典(LIWC、ANEW、LabMT、VADER等)与机器学习,已可在群体与个体层面预测抑郁等心理健康风险并捕捉临界转变早期预警。
多词典与谱方法结合大规模社媒时序,已在群体与个体层面实现抑郁等心理健康风险的早期识别与提示(p.8–11)
理论与信号框架:心理系统可发生“临界转变”(Critical Transitions),在抑郁等发作前出现“临界减速”特征(自相关、方差升高)(p.8, 110–111)。社媒提供高分辨率、长时间序列的自我表露与行为特征,可在个体/群体层面追踪情绪维度(p.8)。
工具与证据:词典与分类器:LIWC、ANEW、LabMT、VADER、GPOMS、SentiWordNet 等(p.9–11, 28)。预测与区分:社媒指标可预测抑郁发生,并区分 PTSD、抑郁、双相、季节性情感障碍等(p.11, 22–23, 33–34, 149–150)。机制与干预:Twitter“情绪标注”行为(I feel...)可在分钟级显著减弱负面情绪,提示可用于情绪调节干预(p.8–9, 14, Fig.2)。特征工程:用 SVD 提取“特征情绪”(eigenmoods)以剥离常规语言基线,定位与健康行为相关的情绪成分(p.9–10, 19–20)。
节律与环境:昼夜与季节节律的群体情绪模式与 LIWC 指标、皮质醇节律相关(p.10, 125, 144)。
- 社交媒体信号与其他数据融合在疫情预警(流感、霍乱、寨卡、HIV)、灾害健康风险、空气污染危害预测等方面取得实证成效。
传染病与公共卫生:流感、霍乱、寨卡、HIV 等的追踪与短期预测,常通过关键字/表情符号、总体情绪与 CDC 指标对齐(p.2, 12, 24–26, 36–37, 154)。Zika:搜索+Twitter+新闻联合,较官方提前最多约 3 周预测病例(p.12, 25)。
灾害与风险沟通:社媒+传感数据预测次日雾霾健康危害;权威应急账号可降低焦虑与谣言传播(p.12, 152–153)。
空气污染与环境健康:与物理传感器融合的危害预测展示了多模态可行性(p.12, 152)。
- 对阿片类等处方药滥用与酒精/非法药物的监测显示与官方统计高度相关,深度学习可用于复吸风险预测。
监测一致性与预测:处方阿片类滥用的地理活动与官方估计高度相关(Twitter)(p.7, 104)。Reddit 上可用深度学习预测阿片复吸风险(p.7, 105)。
多物质覆盖:酒精、可卡因、大麻、管制药物等多品类在不同平台上的滥用讨论已被量化与内容分析(p.7, 100–103)。
匿名论坛价值:匿名健康论坛(如 buprenorphine)揭示合并使用非法药物的风险与趋势,利于质性归纳与早期警示(p.7, 107)。
- 社交媒体研究面临抽样偏差(便利样本、用户结构差异)、平台算法与接口变动、情感操纵与讽刺歧义、机器人账户干扰等方法学挑战。
附:DDI/ADR 网络与可视化的一体化范式
Instagram 上 500 万+贴文,7000 用户,围绕 7 类抗抑郁药建立“药物–症状–天然产物”异质网络,借助 SyMPToM Web 工具追踪个体与群体 ADR/DDI 与亚群体特征(如银屑病、进食障碍)(p.6–7, 13–14)。网络动机学+逻辑回归用于 DDI 链接预测,在 DrugBank 上验证(p.6–7, 99)。
Steinhubl, S. R., Muse, E. D. & Topol, E. J. The emerging field of mobile health. Sci. Transl. Med. 7, 283rv3–283rv3 (2015).
移动健康的新兴领域
移动计算能力与移动互联的激增为移动医疗(mHealth)奠定了基础:智能手机连接的可穿戴传感器、即时诊断设备及医疗级成像在实时数据与自动化临床决策支持工具的加持下,有望跨越地域限制,重塑临床研究与医疗服务并深化对生理变异性的理解。然而,将 mHealth 融入临床仍面临高质量证据不足、以及资金、监管与安全等多重障碍。当前,领域内正展开系统性评估以厘清这些技术的真实能力与价值,推动其规范化与规模化应用。
Sánchez-Valle, J. et al. Prevalence and differences in the co-administration of drugs known to interact: an analysis of three distinct and large populations. BMC Med. 22, 166 (2024).
已知相互作用药物的联合用药流行率及差异分析:基于三个独立大规模人群的研究
本研究基于三大人群(巴西布卢梅瑙、西班牙加泰罗尼亚、美国印第安纳波利斯,合计近600万人、最长11年EHR数据)系统比较已知药物相互作用(DDI)的合用流行程度、年龄与性别差异及其驱动因素。结果显示:随年龄增长,多药共用与DDI流行率均显著上升,且老年群体的DDI发生率高于控制同龄药物种类与合用数量的随机“空模型”预测,提示多病共存与治疗路径使DDI风险“劣于随机”;女性在多数年龄段尤其是15–49岁DDI风险更高(与激素/避孕药、苯二氮卓类、质子泵抑制剂相关),而在印第安纳波利斯50岁以上男性DDI更高由心血管相关组合所致。以奥美拉唑为例的替代模拟表明,优先开具无相互作用的替代PPI可在加泰罗尼亚将总体DDI减少约20–23%,提示存在可操作的处方干预空间。
Dolley, S. Big data’s role in precision public health. Front. Public Health 6, 297813 (2018).
大数据在精准公共卫生中的角色
本文件探讨了大数据在精准公共卫生中的作用,强调其在疾病监测、风险预测、治疗干预和疾病理解方面的影响。通过运用大数据技术,公共卫生工作者可以更有效地追踪疾病传播,实施针对性的公共卫生措施,并通过数据整合实现个性化医疗。这些动态的发展带来了对数据质量、隐私和伦理问题的新挑战,同时也提供了提高公共健康响应能力的机遇。
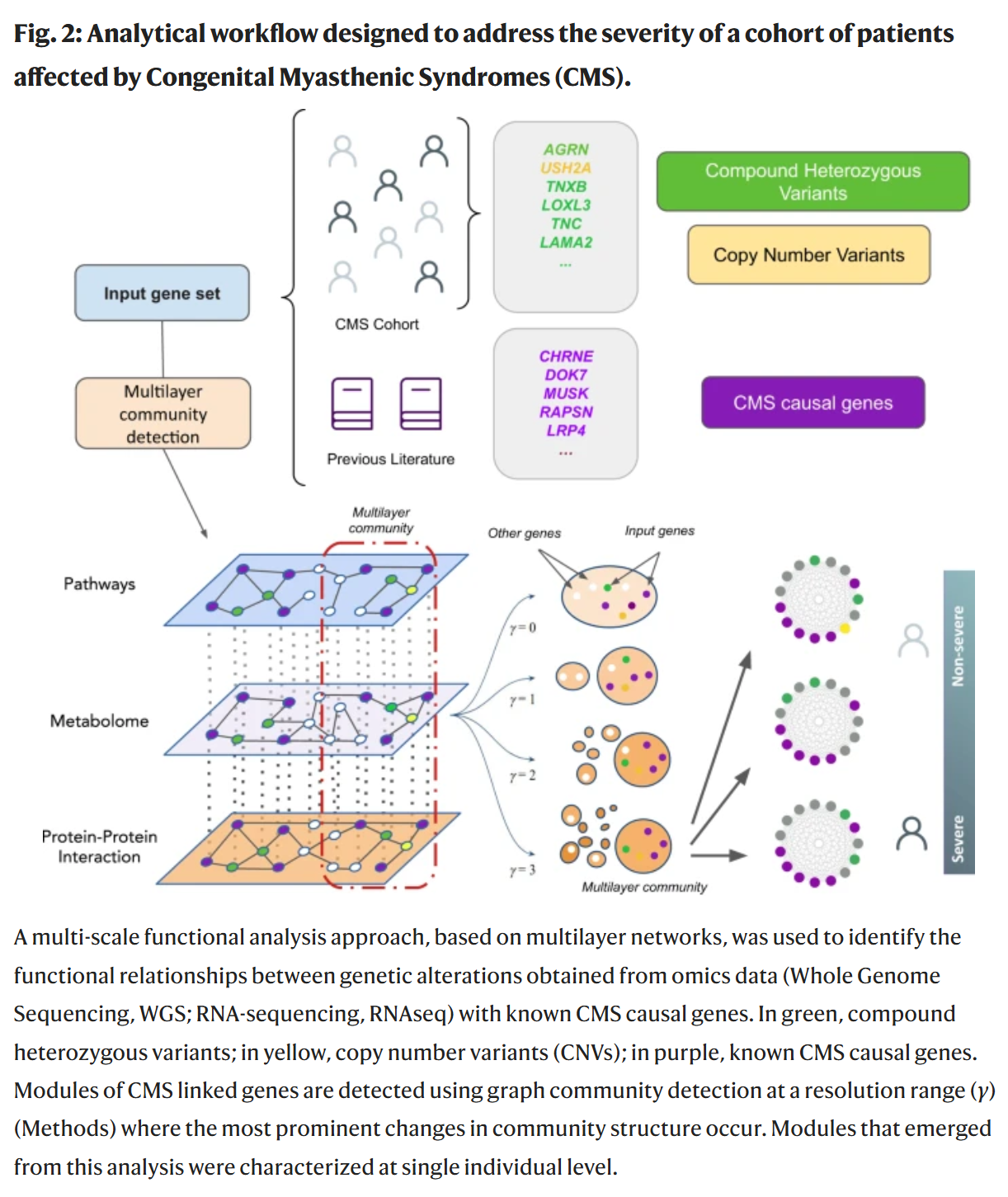
Núñez-Carpintero, I. et al. Rare disease research workflow using multilayer networks elucidates the molecular determinants of severity in congenital myasthenic syndromes. Nat. Commun. 15,
1227 (2024).基于多层网络的罕见病研究框架揭示先天性肌无力综合征严重程度的分子决定因素
本研究通过多层网络分析,探讨了导致先天性重肌无力综合症(CMS)患者病情严重程度的分子决定因素。这项研究揭示了在蛋白质-蛋白质和信号通路层面上主要的相互关系,认为CMS的严重程度与神经肌肉接头(NMJ)中的特定分子功能损害相关,涉及不同类别和定位的基因,例如细胞外基质(ECM)成分及后突触AChR聚集调节因子。此外,个体化基因诊断可能帮助为每位患者选择合适的药物治疗。