杭州网站建设 网络服务简单代码制作
将PDF文件和扫描图像等非结构化文档转换为结构化或半结构化格式是人工智能的关键部分。然而,由于PDF的复杂性和PDF解析任务的复杂性,这一过程显得神秘莫测。
在RAG(Retrieval-Augmented Generation)基建之PDF解析的“魔法”与“陷阱”中,我们介绍了PDF解析的主要任务,对现有方法进行了分类,并简要介绍了每种方法。RAG基建之PDF解析的“无OCR”魔法之旅中介绍了端到端方法。
本篇咱们来聊聊PDF解析的“流水线”大冒险!想象一下,PDF文件就像一座神秘的迷宫,里面藏着各种文字、表格、公式和图片。我们的任务就是把这些乱七八糟的东西整理得井井有条,变成结构化的数据。听起来是不是有点像在迷宫里找宝藏?
基于流水线的方法将PDF解析任务视为一系列模型或算法的流水线,如下所示。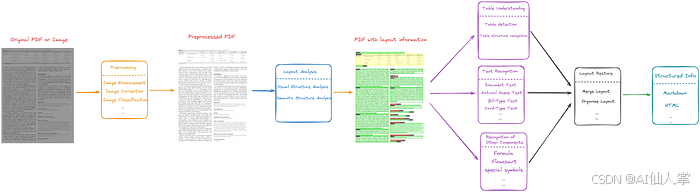
基于流水线的方法可以分为以下五个步骤:
- 预处理原始PDF文件:修复模糊或倾斜等问题。此步骤包括图像增强、图像方向校正等。
- 进行布局分析:主要包括视觉结构分析和语义结构分析。前者识别文档的结构并勾勒出相似区域,后者为这些区域标注特定的文档类型,如文本、标题、列表、表格、图表等。此步骤还涉及分析页面的阅读顺序。
- 分别处理布局分析中识别的不同区域:此过程包括理解表格、识别文本以及识别公式、流程图和特殊符号等其他组件。
- 整合之前的结果:恢复页面结构。
- 输出结构化或半结构化信息:如Markdown、JSON或HTML。
PDF解析的“流水线”方法四大天王:
-
- Marker:轻量级“宝藏猎人”
Marker是个轻量级的工具,速度快得像闪电侠,但它也有点小毛病。比如,它不太擅长处理表格,尤其是表格标题,简直像是迷路的小羊羔。不过,它对付公式倒是有一套,尤其是那些复杂的数学公式,Marker能用Texify模型把它们变成漂亮的LaTeX格式。可惜的是,它只懂英语,日语和印地语对它来说就像外星语。
- Marker:轻量级“宝藏猎人”
-
- Papermage:科学文档的“多面手”
Papermage是个专门对付科学文档的“多面手”。它不仅能把文档拆分成各种元素(文字、图表、表格等),还能灵活处理跨页、跨列的复杂内容。它的设计非常模块化,开发者可以轻松添加新功能,就像给乐高积木加新零件一样简单。不过,它目前还没有并行处理的能力,解析速度有点慢,像是在用老式打字机敲代码。
- Papermage:科学文档的“多面手”
-
- Unstructured:全能型“迷宫大师”
Unstructured是个全能型选手,布局分析做得非常细致。它不仅能识别文字和表格,还能处理复杂的文档结构。它的自定义能力也很强,开发者可以根据需要调整中间结果,就像在迷宫里随时调整路线一样灵活。不过,它在公式识别上表现一般,像是迷宫里的一块“绊脚石”。
- Unstructured:全能型“迷宫大师”
接下来,本文将讨论几种具有代表性的基于流水线的PDF解析框架,并分享从中获得的见解。
文章目录
- Marker
- 整体流程
- 从Marker中获得的见解
- Marker的缺点
- PaperMage
- 组件
- 基础数据类
- 整体流程和代码分析
- 句子分割
- 布局结构分析
- 逻辑结构分析
- 关于Papermage的见解和讨论
- Unstructured
- 关于布局分析
- 关于自定义
- 关于表格检测和识别
- 关于公式检测和识别
- MinerU:基于管道的开源文档解析框架
- MinerU 工作流程:
- MinerU所使用的主要模型和算法
- 评论
- 结论
Marker
Marker 是一个用于深度学习模型的流水线。它能够将PDF、EPUB和MOBI文档转换为Markdown格式。
整体流程
Marker的整体流程分为以下四个步骤:

步骤1:使用PyMuPDF和OCR将页面划分为块并提取文本。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......doc = pymupdf.open(fname, filetype=filetype)if filetype != "pdf":conv = doc.convert_to_pdf()doc = pymupdf.open("pdf", conv)blocks, toc, ocr_stats = get_text_blocks(doc,tess_lang,spell_lang,max_pages=max_pages,parallel=int(parallel_factor * settings.OCR_PARALLEL_WORKERS))
步骤2:使用布局分割器对块进行分类,并使用列检测器对块进行排序。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 从列表中解包模型texify_model, layoutlm_model, order_model, edit_model = model_lstblock_types = detect_document_block_types(doc,blocks,layoutlm_model,batch_size=int(settings.LAYOUT_BATCH_SIZE * parallel_factor))# 查找页眉和页脚bad_span_ids = filter_header_footer(blocks)out_meta["block_stats"] = {"header_footer": len(bad_span_ids)}annotate_spans(blocks, block_types)# 如果设置了调试标志,则转储调试数据dump_bbox_debug_data(doc, blocks)blocks = order_blocks(doc,blocks,order_model,batch_size=int(settings.ORDERER_BATCH_SIZE * parallel_factor))......
步骤3:过滤页眉和页脚,修复代码和表格块,并应用Texify模型处理公式。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 修复代码块code_block_count = identify_code_blocks(blocks)out_meta["block_stats"]["code"] = code_block_countindent_blocks(blocks)# 修复表格块merge_table_blocks(blocks)table_count = create_new_tables(blocks)out_meta["block_stats"]["table"] = table_countfor page in blocks:for block in page.blocks:block.filter_spans(bad_span_ids)block.filter_bad_span_types()filtered, eq_stats = replace_equations(doc,blocks,block_types,texify_model,batch_size=int(settings.TEXIFY_BATCH_SIZE * parallel_factor))out_meta["block_stats"]["equations"] = eq_stats......
步骤4:使用编辑器模型对文本进行后处理。对应代码如下:
def convert_single_pdf(fname: str,model_lst: List,max_pages=None,metadata: Optional[Dict]=None,parallel_factor: int = 1
) -> Tuple[str, Dict]:......# 复制以避免更改原始数据merged_lines = merge_spans(filtered)text_blocks = merge_lines(merged_lines, filtered)text_blocks = filter_common_titles(text_blocks)full_text = get_full_text(text_blocks)# 处理空块的连接full_text = re.sub(r'\n{3,}', '\n\n', full_text)full_text = re.sub(r'(\n\s){3,}', '\n\n', full_text)# 将项目符号字符替换为 -full_text = replace_bullets(full_text)# 使用编辑器模型对文本进行后处理full_text, edit_stats = edit_full_text(full_text,edit_model,batch_size=settings.EDITOR_BATCH_SIZE * parallel_factor)out_meta["postprocess_stats"] = {"edit": edit_stats}return full_text, out_meta
从Marker中获得的见解
到目前为止,我们已经介绍了Marker的整体流程。现在,让我们讨论从Marker中获得的见解。
见解1:布局分析可以分为多个子任务。第一个子任务涉及调用PyMuPDF API获取页面块。
def ocr_entire_page(page, lang: str, spellchecker: Optional[SpellChecker] = None) -> List[Block]:if settings.OCR_ENGINE == "tesseract":return ocr_entire_page_tess(page, lang, spellchecker)elif settings.OCR_ENGINE == "ocrmypdf":return ocr_entire_page_ocrmp(page, lang, spellchecker)else:raise ValueError(f"未知的OCR引擎 {settings.OCR_ENGINE}")def ocr_entire_page_tess(page, lang: str, spellchecker: Optional[SpellChecker] = None) -> List[Block]:try:full_tp = page.get_textpage_ocr(flags=settings.TEXT_FLAGS, dpi=settings.OCR_DPI, full=True, language=lang)blocks = page.get_text("dict", sort=True, flags=settings.TEXT_FLAGS