Linux 孤儿进程与进程的优先级和切换和调度
一.孤儿进程
1.概念引入
孤儿进程,简单来说就是在它自己的任务执行完之前,父进程先挂掉,它就变成了孤儿进程。孤儿进程貌似变成了“无人看管的状态”。
2.实践证明
我们用下面的代码模拟孤儿进程产生的过程。
#include<stdio.h>2 #include<sys/types.h>3 #include<unistd.h>4 int main(){5 pid_t id=fork();6 if(id==0)7 {8 //child9 while(1){10 11 printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());12 sleep(1);13 }14 }15 else{16 //father17 int count=5;18 while(count--){19 printf("我是一个父进程,pid:%d,ppid:%d\n",getpid(),getppid());20 sleep(1);21 }22 }23 return 0; 24 }
生成可执行程序之后,我们用指令查看进程状态。
ps ajx | grep myprocess
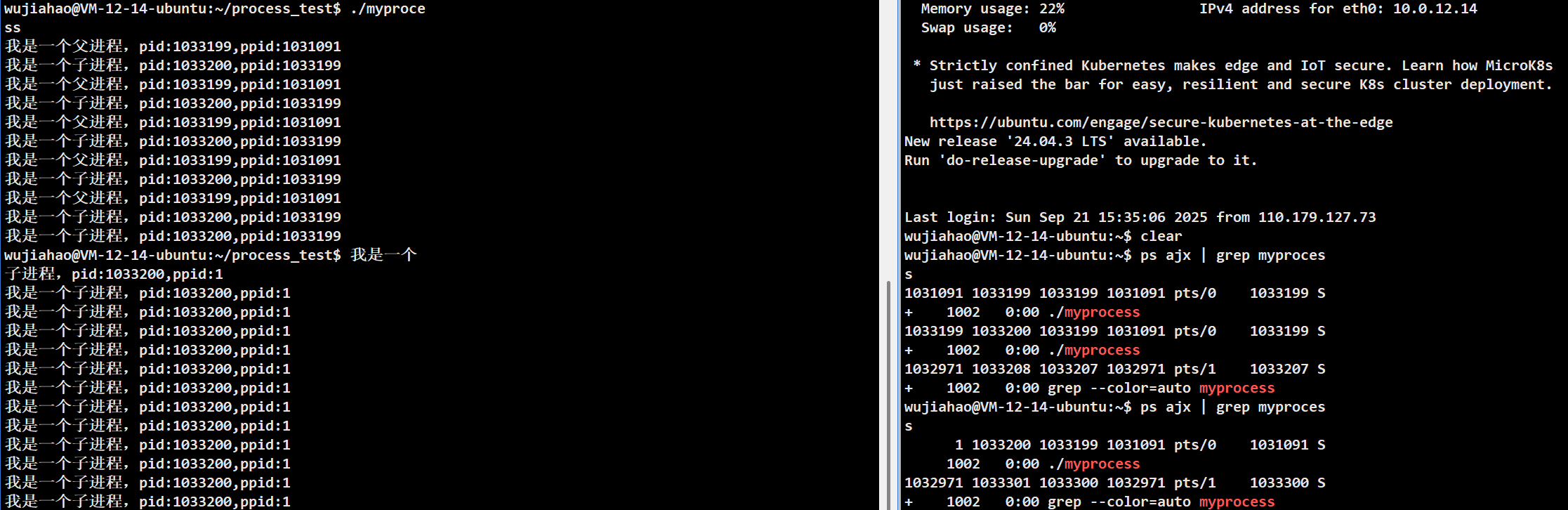
可以看到,父进程确实先退出了,到后面只有子进程在一直执行。
此时我们发现一个有趣的情况:这时的子进程用Ctrl+c是杀不掉的。那是因为:此时子进程变成了孤儿进程,自动会把当前的可执行程序切换到后台执行,我们需要用指令kill -9才能把这个子进程杀掉。

父进程退出后,子进程不能称为没有父进程的子进程,它会被1号进程领养,这个子进程就叫孤儿进程。
那么1号进程是谁?systemd(可以看作操作系统)。由它创建bash进程。
为什么要领养?我们需要回答它的反面问题。如果不领养会怎样?
子进程进入僵尸状态?无人回收。
那一个进程的父进程为什么推出后不会孤儿也不会僵尸?因为由bash创建,会被bash回收。
二.进程的优先级和切换和调度
1.进程优先级
我们将从三个方面讲解这个问题。
是什么:什么是优先级?
为什么:为什么要设计优先级?
怎么办:如何设计优先级?
1.排队的本质:确认优先级,自己什么时候能打到饭(得到某种资源的先后顺序)。
2.高峰期的时候才需要排队。也就是说,目标资源稀缺时,进程优先级才有意义。很多进程都在竞争有限的cpu资源。
优先级和权限:优先级决定的是能得到这个资源,不过是先后问题;权限决定的是是否能得到这个资源。
3.优先级,就是一种数字。是task_struct中的属性。数字值越低,优先级越高。
现代计算机操作系统:基于时间片的分时操作系统。时间片:这里只做简单比喻,只给30秒打饭。这类的操作系统需要考虑公平性。
示例:我们修改上面的代码,让父子进程一直跑。
#include<stdio.h>2 #include<sys/types.h>3 #include<unistd.h>4 int main(){5 pid_t id=fork();6 if(id==0)7 {8 //child9 while(1){10 11 printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());12 sleep(1);13 }14 }15 else{16 //father17 while(1){18 printf("我是一个父进程,pid:%d,ppid:%d\n",getpid(),getppid());19 sleep(1);20 }21 } 22 return 0;23 }
生成可执行程序,并查看进程状态。
ps -al|head -1 && ps -al|grep myprocess

我们需要关注一些特别的进程属性。
1.UID:user Identify,标识一个用户的唯一身份。在Linux文件系统中我就可以看到UID,只不过平时都向用户展示用户名。
wujiahao@VM-12-14-ubuntu:~/process_test$ ls -ln
total 28
-rw-rw-r-- 1 1002 1003 77 Sep 20 20:32 Makefile
-rwxrwxr-x 1 1002 1003 17664 Sep 21 15:54 myprocess
-rw-rw-r-- 1 1002 1003 450 Sep 21 15:52 myprocess.c
tips:我们(用户)在用指令访问文件时,本质上是一个创建了一个进程访问。一个进程启动时,就会被UID标识,同样的文件也会标识UID。在执行操作时对比两者值即可实现权限管理。
可以说,Linux中一切皆文件,Linux中的而一切访问资源方式都是由进程访问,进程就是用户的化身。
2.PRI和Ni:上面也说到了,进程的优先级其实就是一个数字。PRI即进程的优先级,默认为80;NI即进程优先级的偏移值,也就是nice值。
真实的优先级=PRI(默认)+NI。接下来我们通过两种方式修改进程的优先级。
方法1:
先修改代码
#include<stdio.h>2 #include<sys/types.h>3 #include<unistd.h>4 int main(){5 while(1){6 printf("我是一个父进程,pid:%d,ppid:%d\n",getpid(),getppid()); 7 sleep(1);8 }9 // pid_t id=fork();10 // if(id==0)11 // {12 // //child13 // while(1){14 15 // printf("我是一个子进程,pid:%d,ppid:%d\n",getpid(),getppid());16 // sleep(1);17 // }18 // }19 // else{20 // //father21 // while(1){22 // printf("我是一个父进程,pid:%d,ppid:%d\n",getpid(),getppid());23 // sleep(1);24 // }25 // }26 return 0;27 }
~
~ 启动进程之后,使用top命令——>r命令——>输入当前要修改的优先级的进程的pid。
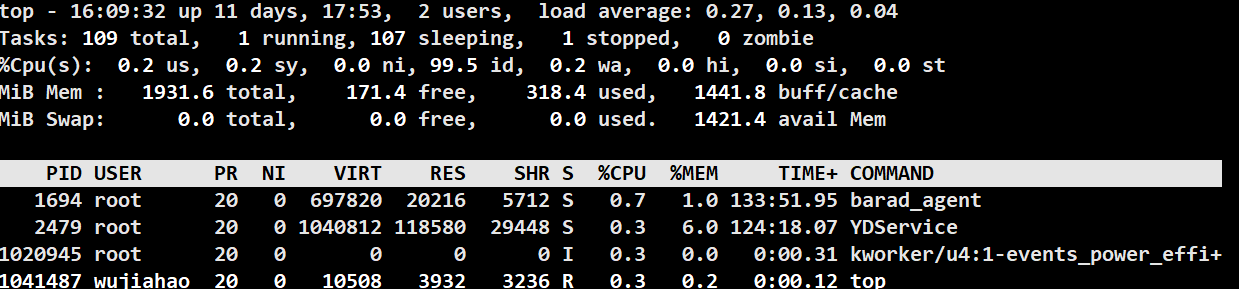
输入要修改的值。

之后再去查看进程的状态。发现进程的优先级已经成功被修改。
wujiahao@VM-12-14-ubuntu:~$ ps -al|head -1 && ps -al|grep myprocess
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 1002 1041409 1031091 0 90 10 - 694 hrtime pts/0 00:00:00 myprocess
需要注意的一点是,进程的优先级都是基于PRI的默认值80修改的,这个设计的用意我们下面就会说。
方法2:使用nice/renice指令
优先级的极值问题:如果优先级跨度过大,会有人恶意修改自己的进程优先执行,优先级低的进程长时间的不到cpu资源,引发进程饥饿。
我们用renice指令修改进程优先级,分别让他们-100,+100,看看结果如何。
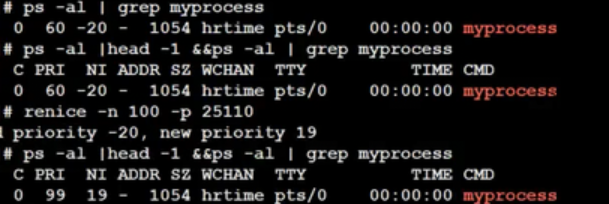
最终发现nice值的区间为[-20,19],也就是说我们进程的优先级会控制在[60,99]的范围。
2.进程的切换
本节将讲解进程切换和进程调度原理,在此之前我们需要补充一些前置知识。
1.竞争性:系统进程数目众多,而CPU资源有限,所以进程之间有竞争属性。为了高效完成任务,更合理竞争相关资源,于是有了优先级的概念。
2.独立性:进程=内核数据结构(task_struct)+代码和数据,多进程运行独享资源,并且运行期间互不干扰。其中一个进程挂了不会影响其他进程。
3.并发:多个进程在一个CPU运行,采用进程切换的方式分时运行多个进程。
4.并行:多个进程在多个CPU分别同时运行,是真正同时运行。
我们也可以通过指令查看我们当前的云服务器的CPU配置(不重要)。
cat /proc/cpuinfo
wujiahao@VM-12-14-ubuntu:~/process_test$ cat /proc/cpuinfo
processor : 0
vendor_id : AuthenticAMD
cpu family : 25
model : 1
model name : AMD EPYC 7K83 64-Core Processor
stepping : 0
microcode : 0x1000065
cpu MHz : 2545.216
cache size : 512 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm rep_good nopl cpuid extd_apicid tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 erms rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 arat fsrm
bugs : fxsave_leak sysret_ss_attrs null_seg spectre_v1 spectre_v2 spec_store_bypass srso ibpb_no_ret
bogomips : 5090.43
TLB size : 1024 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 48 bits physical, 48 bits virtual
power management:processor : 1
vendor_id : AuthenticAMD
cpu family : 25
model : 1
model name : AMD EPYC 7K83 64-Core Processor
stepping : 0
microcode : 0x1000065
cpu MHz : 2545.216
cache size : 512 KB
physical id : 0
siblings : 2
core id : 0
cpu cores : 1
apicid : 1
initial apicid : 1
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm rep_good nopl cpuid extd_apicid tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw topoext ibpb vmmcall fsgsbase bmi1 avx2 smep bmi2 erms rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 arat fsrm
bugs : fxsave_leak sysret_ss_attrs null_seg spectre_v1 spectre_v2 spec_store_bypass srso ibpb_no_ret
bogomips : 5090.43
TLB size : 1024 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 48 bits physical, 48 bits virtual
power management:
要讲解进程切换,我们从三个方面入手。
1.死循环进程如何运行?
2.谈谈CPU和寄存器
3.进程切换原理
1.死循环如何运行
一旦一个进程占有CPU,会把自己的代码跑完吗?不会,系统分配时间片,时间片一到就会进程切换。所以死循环系统不会打死系统,不会一直占有CPU。
2.cpu与寄存器
代码和数据由CPU处理的时候,不会一下子全放进去,而是一条一条存在CPU的寄存器中。
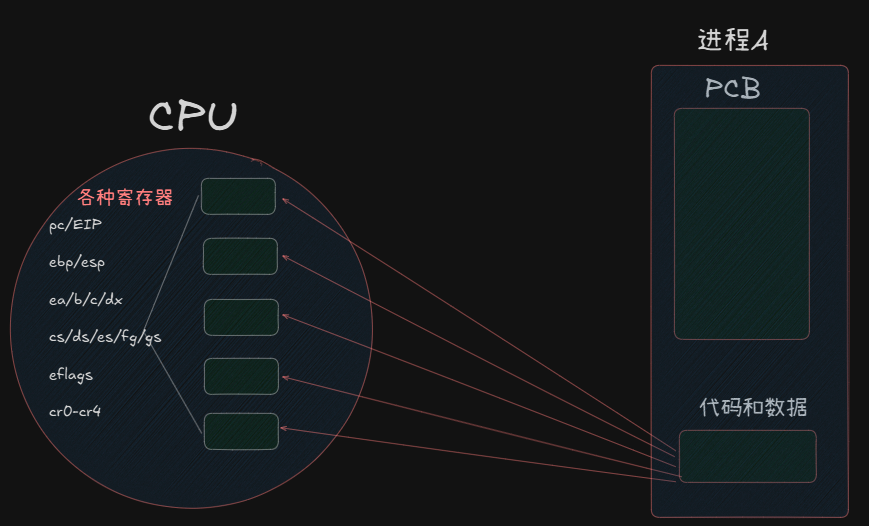
CPU中有很多类别的寄存器,它们各自有各自独特的功能。
寄存器起到一个临时存储的作用,它会存储一个正在运行的进程的临时数据。
我们需要明确的一点是:寄存器是一个空间,它只有一份;而寄存器内的数据是临时数据,可能下一秒就会有不同的内瓤存入。
3.进程切换原理
要深入讲解进程切换原理,我们首先来讲一个例子。
比如你正在上大学,准备应征入伍,成为光荣的军人。但是在此之前,学校需要将你的学籍保留在一个文件袋,因为我们很容易想到一种糟糕的情况——如果没有保留学籍,一年没有上课没有考试,当然会挂很多科,要补起来就很难。于是保留学籍后,就可以入伍了。退伍之后,学校就可以把你的学籍恢复,跟着新一届的同学一起学习。
那么这个过程中:整个学校,导员和你就组成了一个完整的调度过程。

我们接着讲真实的进程切换。
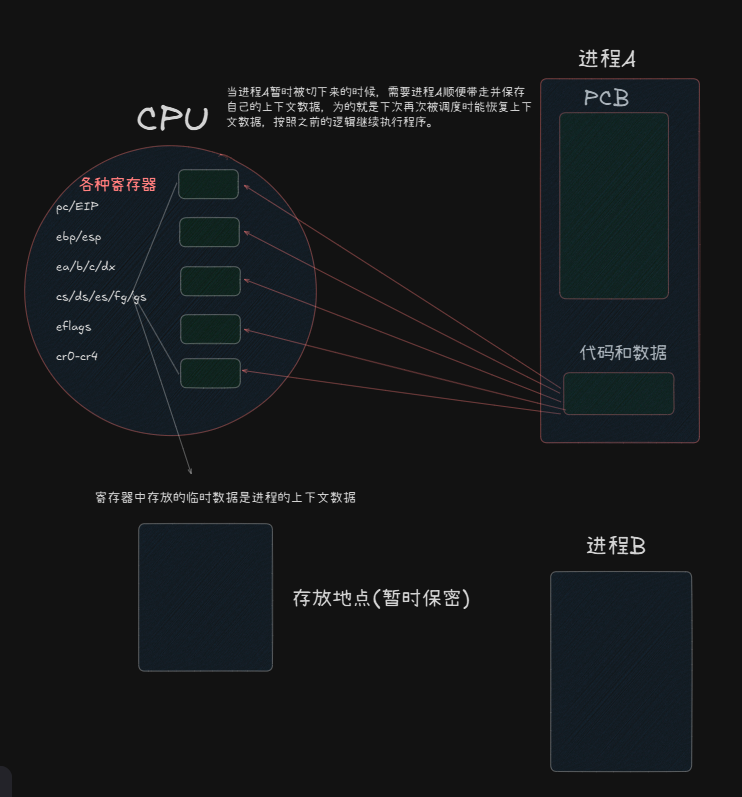
进程A被分配的时间片用完之后,要把A切走;我们需要把寄存器中的所有值都带走(拷贝出来,在哪?)此时直接A进程换到running Queue队尾,进程B上去运行,数据直接覆盖。一定时间后,进程B的时间片也用完,复刻进程A的操作,然后进程A继续上去运行,恢复历史位置,继续运行。
也就是说,进程切换的最核心问题就是
保存当前进程的上下文数据
当前可能还有一个大家比较好奇的问题:被拷贝的寄存器数据存放到哪里了?
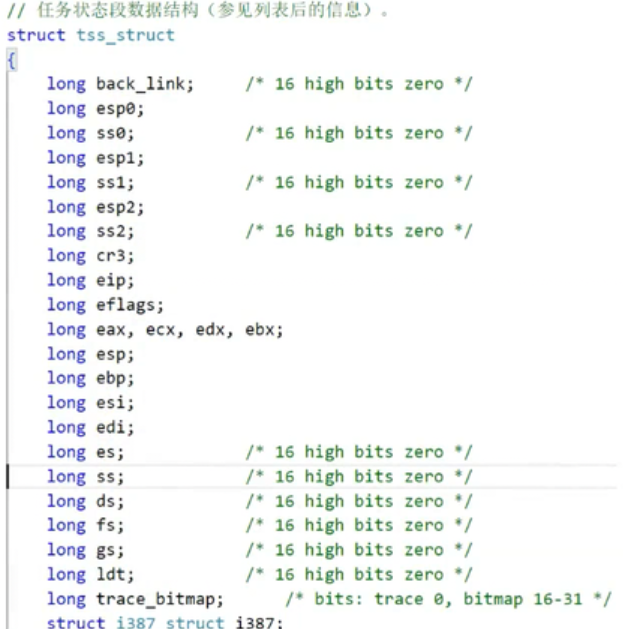
进程的task_struct中的TSS字段(任务状态段)。TSS中会定义一系列寄存器变量存储值。
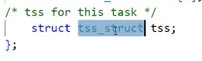
TSS字段内容
3.进程的调度
在此之前,我们要明白一件事:一个内核级的指针,永远指向当前运行的进程
struct task_struct *currentLinux真实的调度算法讲解
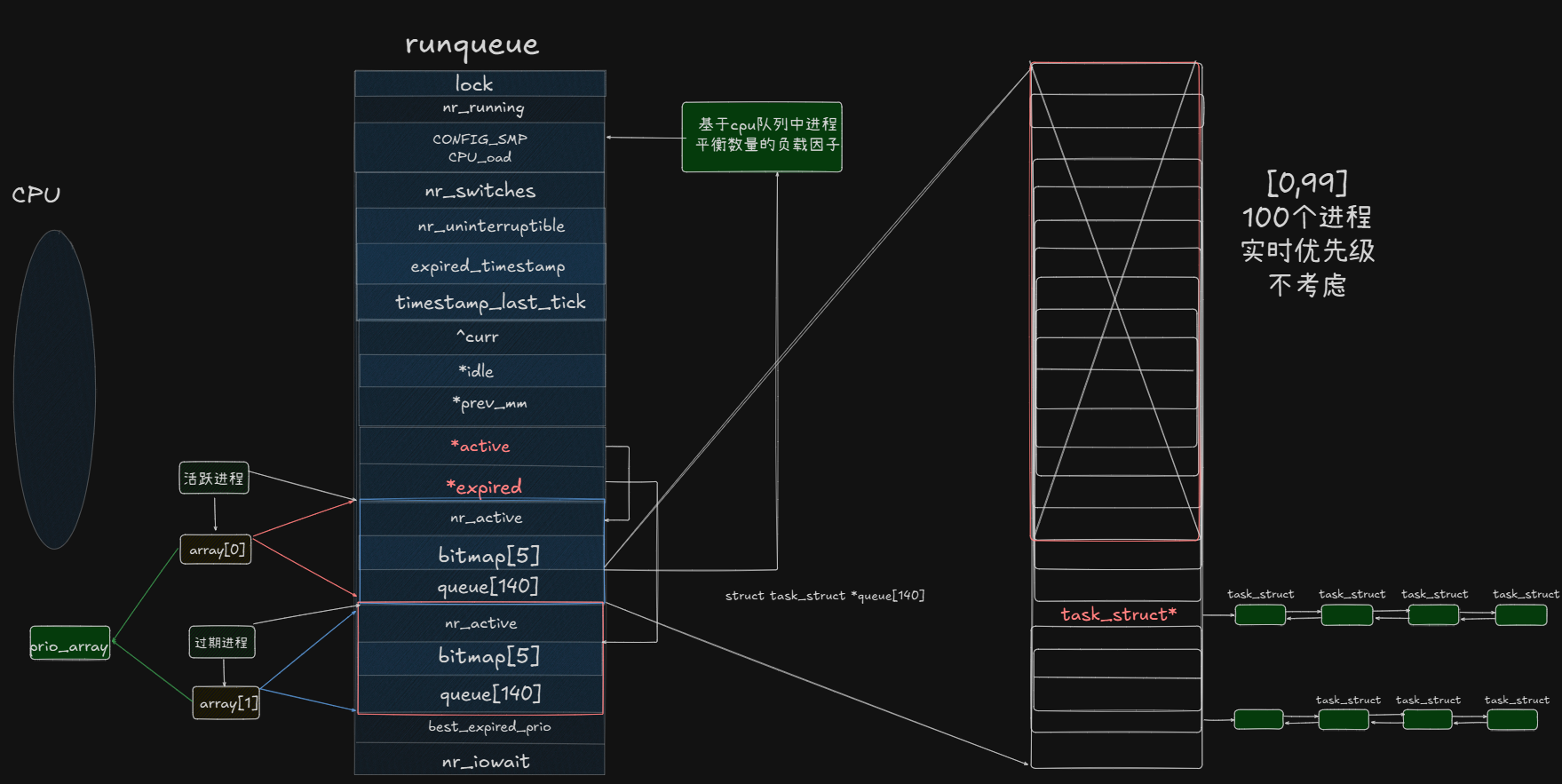
当前讲解情况:一个CPU一个运行队列。
分时操作系统——互联网,服务器
0-99这个区间的优先级我们目前暂时不考虑,只考虑后四十个队列。这里就可以看到,这个区间实际上就是上面的进程优先级区间
实时操作系统——基于实际情况实时生成任务,使用于制造生产
这里的queue[140],实际上就是一个指针数组;而这个优先级队列,实际上就是一个哈希表。优先级,就是一个key,我们要根据一定的hash函数映射到这个指针数组中。
调度器如何快速挑选一个进程?
bitmap[5]:位图,unsigned类型。这里bitmap的比特位,跟queue是一一对应的(32*50=160),比特位的内容:0或1,是否有进程。
调度器调度队列:
1.挑队列:查看位图,近乎O(1)的调度算法。
2.挑进程:nr:当前队列中有多少进程。
调度过程:先查nr,nr>0,再查bitmap确认下标,直接索引,找到目标队列然后从队列头部移除,拿出来后把当前进程的PCB用current指针管理,然后执行切换算法,让current指针的进程放到CPU执行。
但这样设计还是无法完成一个优秀的调度算法。
比如现在60号进程在运行,时间片到了先切换下去,它最多会回到它的优先级队列的尾部。如果单纯这样设计,CPU会永远把前面的进程跑完才会跑第二个,第三个....如果出现一个死循环的进程,就会造成其他进程的饥饿。
因此又有一个队列,跟上面讲过的一模一样的队列。就是上面的一蓝一红

定义两个指针,一个是 struct rqueue_elem *active =&prio_array[0]
另一个是struct rqueue_elem *expired =&prio_array[1]
选队列时,只从active里找,如果发生了上面的切换问题,此时进程不能再放回active里,要放回expired里(执行完了就完了)。active中的进程会越来越少,而expired中的进程会越来越多。一定要把active的队列全部调度完成,再进行下一步。这样原本active中优先级较低的一定会被调到,不会发生饥饿。
此时把active中的队列全部调度完,执行一个操作:
swap(&active,&expired);
交换指针内容,这样active就又执行一个满的队列,而expired管理一个空的队列,重复执行以上流程。
这样就是大O(1)调度算法的设计。
新进程来了,是a队列还是e队列?放在e队列,可以看作是就绪队列。
链到a队,就会自动根据优先级插队了。
其他内容讲解:
cpu_load:实际的运行中会优先把新进程插在负载较低的队列中,保证负载均衡
因此我们能理解之前讲解的优先级算法,其实是为了配套这个调度算法设计的。