NeurIPS 2025 spotlight |FSDrive 自动驾驶迈向视觉推理
想象一下,你开车在繁忙的十字路口准备左转,你是怎么做决策的?
你大概不会在心里默念一段长长的文字:“前方绿灯,对向有直行车辆,速度约50公里/小时,距离我约100米,左侧行人正在等待,我需要先驶入待转区,待对向车辆通过后,迅速转动方向盘……”
太慢了!
我们人类司机的“超能力”,其实是在脑海中瞬间“脑补”出接下来几秒钟的画面:那辆车会开到哪里,我应该在哪个位置,会不会有危险。我们用的是一种视觉化、沉浸式的“预演”,而不是干巴巴的文字逻辑。
然而,你可能不知道,现在很多顶尖的自动驾驶AI,它们的“思考”方式,更像是后者——它们在“看图说话”。
一、 当前AI驾驶的“窘境”:看图说话的“文字狱”
近年来,大模型(VLM/LLM)的推理能力让自动驾驶技术突飞猛-进。一个主流的思路是“思维链”(Chain-of-Thought, CoT),就是让AI在做出决策(比如打方向盘)前,先用文字“思考”一步,把场景分析和决策逻辑写出来。
比如,AI会先生成这样的文字:“分析:我正处于直行道,前方车辆减速。决策:我需要保持车距并减速。”
这听起来很智能,对吧?但问题也恰恰出在这里。
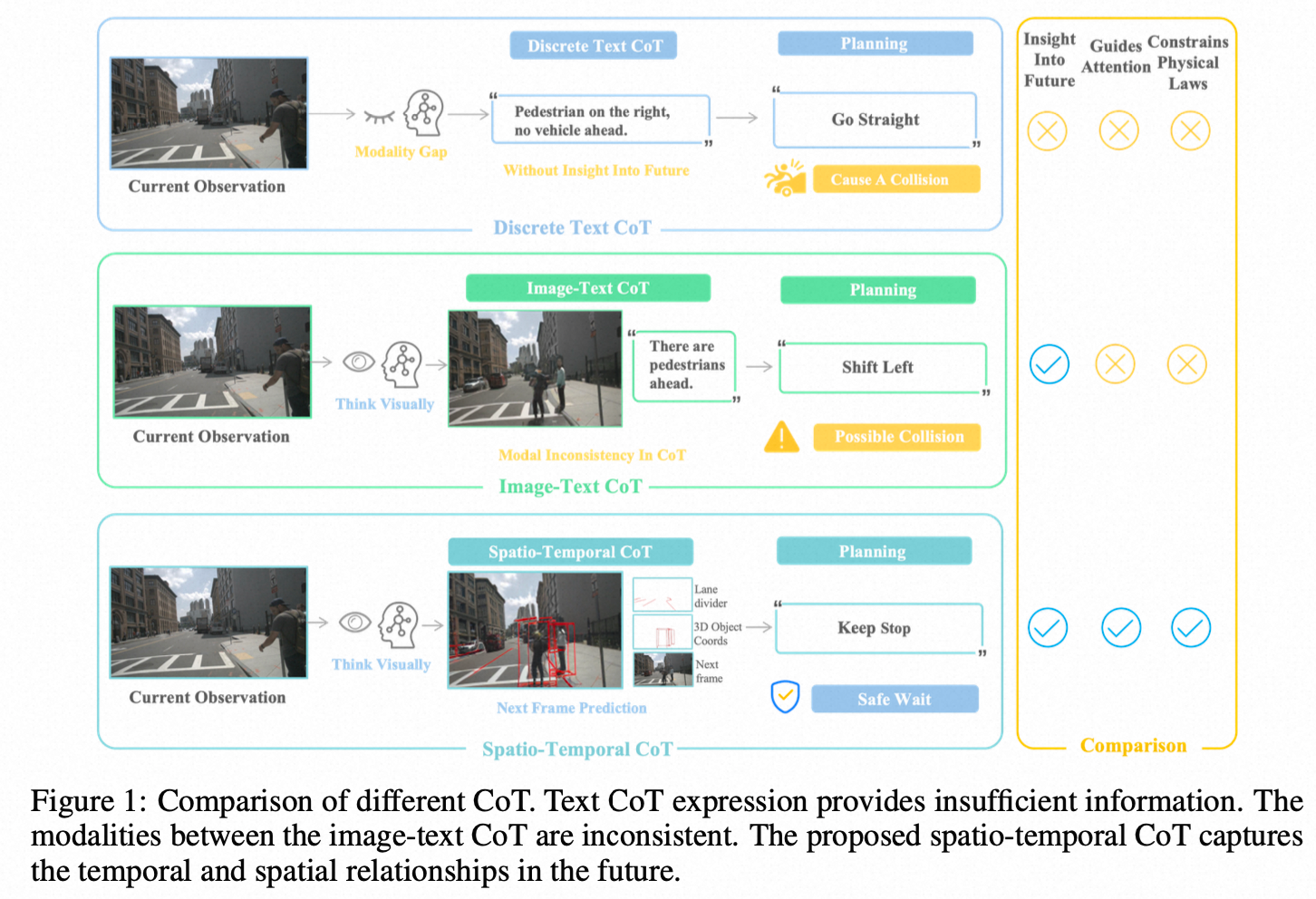
- 信息严重压缩和丢失:把丰富、动态的视觉世界,压缩成几行干巴巴的文字,丢失了太多细节。比如,“前方车辆”的确切位置、姿态、速度、加速度,文字很难精确描述。
- 时空关系模糊:文字是线性的、符号化的,很难表达复杂的空间布局和时间演变。“车在左前方”,到底有多“左”、多“前”?几秒后它又会在哪?文字描述起来既啰嗦又模糊。
- 模态鸿沟:从“图像”到“文字”,再从“文字”到“动作”,反复横跳的转换过程本身就会产生偏差和错误。就像你把一句中文翻译成英文,再翻译回中文,意思可能就变了。
总而言之,让一个天生为视觉世界设计的驾驶任务,强行去走“文字思考”的路线,就像让一个画家放弃画笔,只能用文字描述他的画作一样,憋屈又低效。
那么,我们能不能让AI跳出这个“文字狱”,像人类司机一样,直接用“画面”来思考未来?
二、 我们的答案:FutureSightDrive——让AI拥有“视觉想象力”
这就是我们这篇论文《FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving》的核心思想。我们提出了一种全新的**“时空思维链”(Spatio-Temporal CoT)**,让AI学会“脑补”未来!
与其让AI当个“分析师”写报告,我们让它当一个“导演+画家”,直接把未来的场景给“画”出来。
具体怎么做呢?
我们的FutureSightDrive模型,在规划行驶轨迹之前,会先做一步“视觉思考”:生成一张包含未来时空信息的图像。
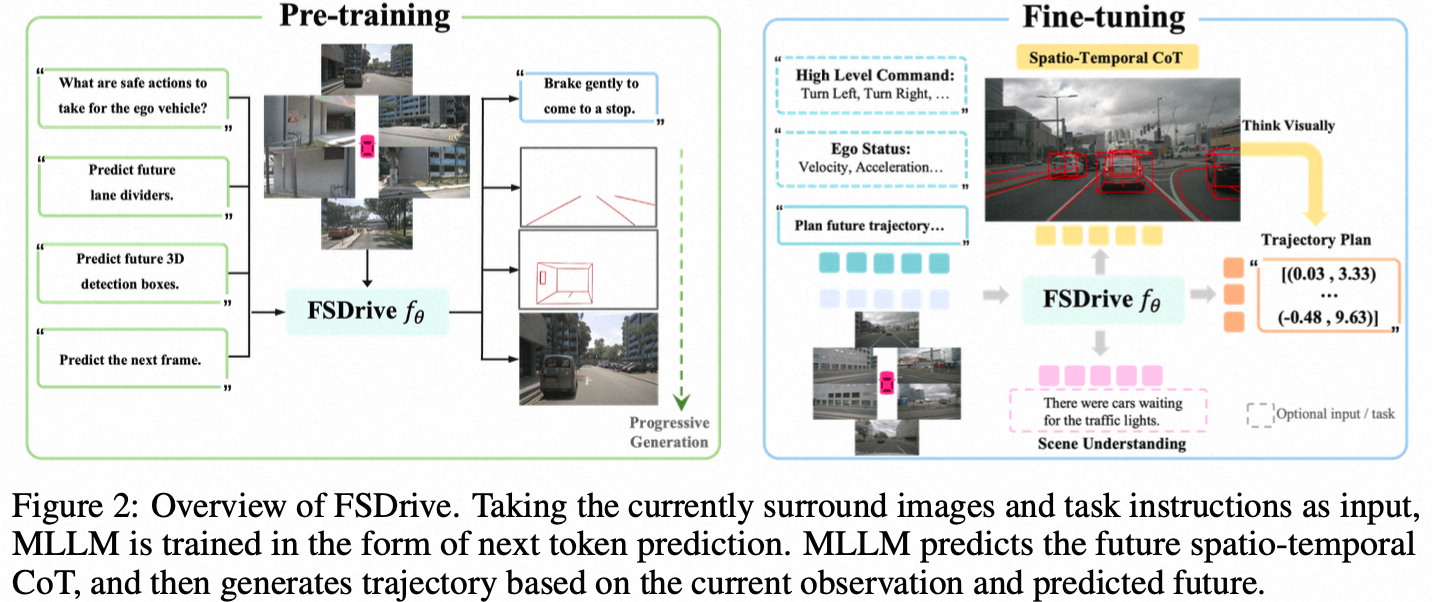
这张“脑补”出来的未来画面,可不是简单的视频预测。它包含了两个关键信息,我们称之为“时空思维链”:
空间思维(Spatial CoT):AI会先在脑海中勾勒出未来的“骨架”。它会用红色的线条画出未来的车道线,用3D框标出未来关键车辆的位置。这就像一个画家先打好草稿,确保了整个画面的结构是合理且符合物理规则的。这为自动驾驶提供了最关键的可行驶区域和避障对象。
时间思维(Temporal CoT):在“骨架”的基础上,AI会填充细节,生成一幅完整的、逼真的未来场景图像。这张图直观地展示了世界是如何随时间演变的,车辆、行人、光影的变化都一目了然。
看到了吗?这整个“思维”过程,都是在图像这个统一的模态里完成的。
当AI“脑补”出这样一幅清晰、具体的未来蓝图后,再基于当前的观测和这幅“未来图景”去规划轨迹,就成了一件水到渠成的事情。这就像你看着脑中的预演画面开车,自然得心应手。
这种“视觉思考”的方式,彻底解决了文字CoT的那些问题:
- 信息保真:所有精细的视觉细节都被保留。
- 时空明确:物体的位置、关系在图像中一清二楚。
- 端到端视觉推理:从视觉输入到视觉思考,再到动作输出,避免了模态转换的损耗。
三、 我们是如何做到的?(一点点技术揭秘)
当然,让AI“无中生有”地画画,尤其是画出符合物理规律的未来,并不容易。我们提出了两个“秘方”:
统一的预训练范式:我们没有从零开始训练一个庞大的模型。而是巧妙地“激活”了现有视觉语言模型(VLM)的图像生成能力。我们只用了极少的训练数据(大约是同类工作的0.3%),就让一个原本只会“看”和“答”的模型,学会了“画”。
渐进式生成策略(从易到难):我们教AI像人学画画一样,先画骨架,再填细节。它会先学习预测简单的车道线(静态约束),然后是动态的车辆位置,最后才是完整的、复杂的场景。这样一步步来,保证了AI“脑补”的画面不是天马行空的幻想,而是对物理世界合理的推演。
四、 效果怎么样?一句话:非常能打!
“吹了”这么多,是骡子是马拉出来遛遛。
- 规划更准,碰撞更少:在权威的nuScenes数据集上,我们的FSDrive在轨迹规划的L2误差和碰撞率上,都显著优于之前的方法,达到了SOTA(State-of-the-Art) 水平。这意味着它开得更稳、更安全。
- “脑补”画面以假乱真:我们生成的未来画面质量,用FID指标来衡量,甚至可以媲美专门的图像生成模型。
- 理解能力也没落下:我们的模型不仅会“画”,在传统的场景理解问答任务(DriveLM)上也取得了顶尖成绩,证明了我们的方法没有顾此失彼。
更有趣的是一个实验:我们故意给模型一个错误的导航指令(比如让它在直行道上左转),没有我们“视觉思考”的模型可能会犯错甚至撞车。但我们的FSDrive,通过“脑补”未来,发现指令和现实情况冲突,从而自主修正了轨迹,避免了危险。这展现了它真正的“世界模型”和“逆向动力学”能力!

结语
我们相信,从符号化的文字思考,迈向形象化的视觉思考,是自动驾驶AI认知能力的一次飞跃。FutureSightDrive正是朝着这个方向迈出的坚实一步。它让AI不再是一个只会执行指令的机器,而更像一个拥有“想象力”、能够预见未来的智能体。
当然,我们的工作也有局限,比如目前主要生成前视视角的未来,未来我们会探索生成360°环视的未来场景。
让AI像人一样“看见”未来,是通往更安全、更智能自动驾驶的关键。