Linux 线程之pthread库

序言:
上一篇博客我们详细介绍了线程的概念,这篇博客我们将介绍关于Linux原生线程库的相关操作进一步了解线程。
一、线程相关的函数
在我们使用pthread库的时候要在编译的时候带上 -lpthread,具体的原因我们将在说到线程库的时候才可以真正理解
1.1、线程的创建
pthread_create:可以创建一个新的线程。
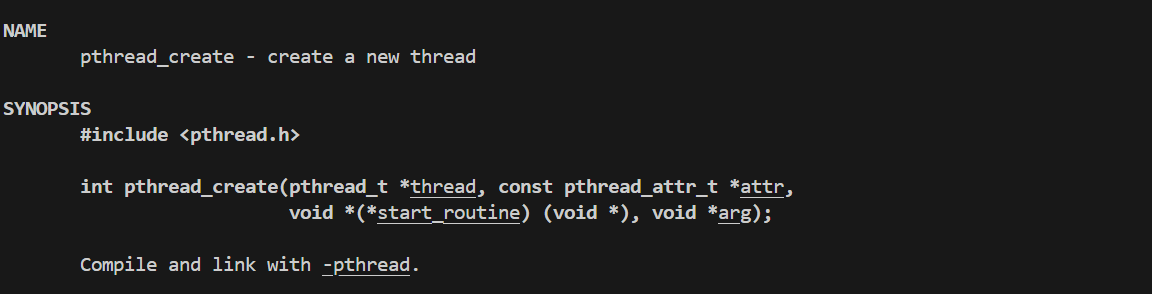
thread:这是一个输出型参数,向函数内传入一个pthread_t类型的指针,将来会得到创建线程的线程ID,其实这里的线程ID并不是真正意义上的ID但它也具有唯一标识符的作用,本质就是一个unsigned long int类型的。

attr:一个输入型参数,用来初始化线程的属性,通常设置成nullptr。
start_routine:一个回调函数,将来这个线程会把这个函数当成自己的入口函数。
arg:将来会回调start_routine函数时把arg当成参数传入进去。
返回值:当如果成功会返回0,如果失败会返回错误码。
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>void * routine(void * args)
{std::string name = (char*)(args);while(1){sleep(1);std::cout <<"我是一个新线程:"<< name << std::endl;}return nullptr;
}
int main()
{pthread_t tid;std::cout << "我是main进程" <<std::endl;pthread_create(&tid , nullptr , routine , (void*)"thread-1");while(true){pause();}return 0;
}ps -aL 可以查看线程信息:
while true; do sleep 1; ps -aL |head -1 && ps -aL |grep thread ; done #可以循环查看线程相关的信息

PID:PID是进程的唯一标识,同一个进程里的线程的PID是一样的。
LWP: LWP(light weight process)轻量级进程,线程的底层是轻量级进程实现的,LWP是线程的唯一标识。
PID和LWD的关系:
如果进程内只有一个线程那么PID和LWD是相同的,如果进程是多线程的那么只有主线程的LWP和PID是相同的其他的则不同。
1.2、线程的终止
线程终止的方式:
1、return返回终止。
2、线程调用pthread_exit()终止。
3、一个线程调用pthread_cancel()终止同一进程中的另一个线程。
1.2.1、return返回
最常见的一种终止线程方式,线程执行完自己的函数以后return返回。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);while (1){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d", pthread_self() , getpid());}return nullptr;//线程完成自己的函数调用return终止自己
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx , pid: %d", pthread_self(), getpid());pthread_create(&tid, nullptr, routine, (void *)"thread-1");while (true){pause();}return 0;
}在return的时候也可以把数据返回让主线程拿到。
return终止很简单我们不再赘述。
1.2.2、pthread_exit()
在线程完成自己的函数的时候调用pthread_exit()终止,和return的用法相似。

retval:线程想要让主线程拿到的数据,和return返回的数据一样。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);int cnt = 5;while (cnt--){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d\n", pthread_self() , getpid());}pthread_exit(0);
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx , pid: %d", pthread_self(), getpid());pthread_create(&tid, nullptr, routine, (void *)"thread-1");int cnt = 10;while (cnt--){sleep(1);}return 0;
}
pthread_exit的用法和return差不多,我们也不再去赘述。
1.2.3、pthread_cancel()
线程调用可以终止同一进程内的其他线程。

thread:想要终止线程的线程ID。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);while (true){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d\n", pthread_self() , getpid());}pthread_exit(0);
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx , pid: %d", pthread_self(), getpid());pthread_create(&tid, nullptr, routine, (void *)"thread-1");int cnt = 10;while (cnt--){sleep(1);}pthread_cancel(tid);return 0;
}
注意:
1、当主进程退出的时候,其他线程无论有没有执行完都退出。
2、线程不能调用exit()退出,因为调用exit()以后操作系统会给进程发信号,全部线程都要退出,这和我们期望的指定一个线程退出截然不同。
3、如果一个进程内创建多个线程,那么这个进程的时间片会平分给所有线程(比如一个进程内部有两个线程它有10nm的时间片那么这两个线程都将获得5nm的时间片),这是为了防止恶意进程创建多个线程来增加时间片让操作系统死机。
4、主线程创建新线程,主线程和新线程操作系统会先调用哪一个?
这个没有一个确切的答案,因为这个要看操作系统的调度。
1.3、线程的等待
pthread_join:主线程阻塞式的等待新线程的退出,可以拿到新线程的退出码。

thread:想要对哪个线程等待的线程ID。
retval:可以把新线程的返回值拿出来,如果不想拿可以设置成nullptr。
返回值:如果成功会返回0,如果失败会返回错误码。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);int cnt = 5;while (cnt--){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d\n", pthread_self() , getpid());}pthread_exit((void*)123);
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx , pid: %d", pthread_self(), getpid());pthread_create(&tid, nullptr, routine, (void *)"thread-1");int cnt = 2;while (cnt--){sleep(1);}void* ret = nullptr;pthread_join(tid , &ret);std::cout << "新线程的退出码是:" << (long long)(ret) <<std::endl;return 0;
}
下面我们来解决几个问题:
如果调用pthread_cancel终止线程,返回值是多少?
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);int cnt = 5;while (cnt--){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d\n", pthread_self() , getpid());}pthread_exit((void*)123);
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx , pid: %d", pthread_self(), getpid());pthread_create(&tid, nullptr, routine, (void *)"thread-1");int cnt = 2;while (cnt--){sleep(1);}pthread_cancel(tid);void* ret = nullptr;pthread_join(tid , &ret);std::cout << "新线程的退出码是:" << (long long)(ret) <<std::endl;return 0;
}
我们可以看见如果主线程调用pthread_cancel终止新线程,主线程获得的新线程的返回值是 -1,这个是 -1其实是PTHREAD_CANCELED。

为什么retval是二级指针?
我们先来看一段代码:
void routine(int** pp)
{p = (int**)123;
}int main()
{int* p = nullptr;routine(&p);return 0;
}
我们想要获得在routine中的地址,我们只能传入p的地址(二级指针),如果传入p(一级指针) , 在routine里的将会是p的一份临时拷贝不会把地址真正的写入到p内部,这个问题的本质答案还得要在说到pthread库的时候才能说清楚。
1.4、分离线程
如果我们想要像进程那样,父进程不想对子进程进行回收应该怎么办?pthread_detach可以帮我们解决这个问题。
当我们创建一个新线程的时候,这个新线程的joinable(一个标志位,表示线程不是分离的需要主线程等待回收资源)是开启的,调用pthread_detach可以关闭。
pthread_detach:可以设置新线程终止的时候,主线程不需要获得退出码,新线程终止的时候直接退出释放资源。

thread:不需要哪个线程回收的线程ID。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>void *routine(void *args)
{std::string name = (char *)(args);int cnt = 2;while (cnt--){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx , pid : %d\n", pthread_self() , getpid());}std::cout << "新线程退出" <<std::endl;pthread_exit((void*)123);
}
int main()
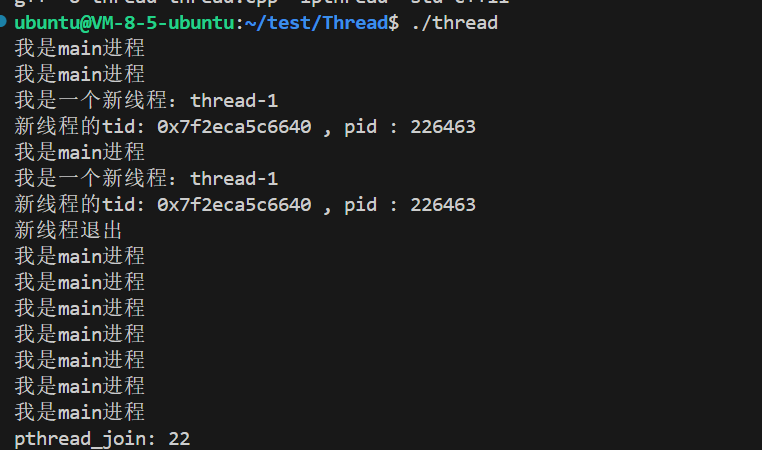
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread-1");int cnt = 10;while (cnt--){std::cout << "我是main进程" << std::endl;sleep(1);}pthread_detach(tid);void *count = nullptr;int ret = pthread_join(tid , &count);std::cout << "pthread_join: " << (ret) <<std::endl;return 0;
}
注意:
1、当我们detach之后主线程等待新线程会失败,我们可以看见上面的运行结果错误码为22。
2、分离线程既可以新线程分离主线程也可以主线程分离新线程。
3、当线程分离之后,两个线程依旧共享地址空间,只是新线程的退出不在需要主线程的等待。
4、一个线程不能既是joinable的又是分离的。
1.5、线程的其他函数
1.5.1、pthread_self
pthread_self:用来查看调用这个函数线程的线程ID。

pthread_self:不需要任何参数。
返回值:会返回线程的线程ID,pthread_self不会失败所以没有错误的返回值。
下面我们来使用一下:
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
void *routine(void *args)
{std::string name = (char *)(args);while (1){sleep(1);std::cout << "我是一个新线程:" << name << std::endl;printf("新线程的tid: 0x%lx", pthread_self());}return nullptr;
}
int main()
{pthread_t tid;std::cout << "我是main进程 ,tid :";printf("0x%lx", pthread_self());pthread_create(&tid, nullptr, routine, (void *)"thread-1");while (true){pause();}return 0;
}
二、深入了解pthread库
2.1、进程地址空间
pthread库作为一个第三方库,要想被我们的进程使用必须要被映射到我们进程的地址空间中
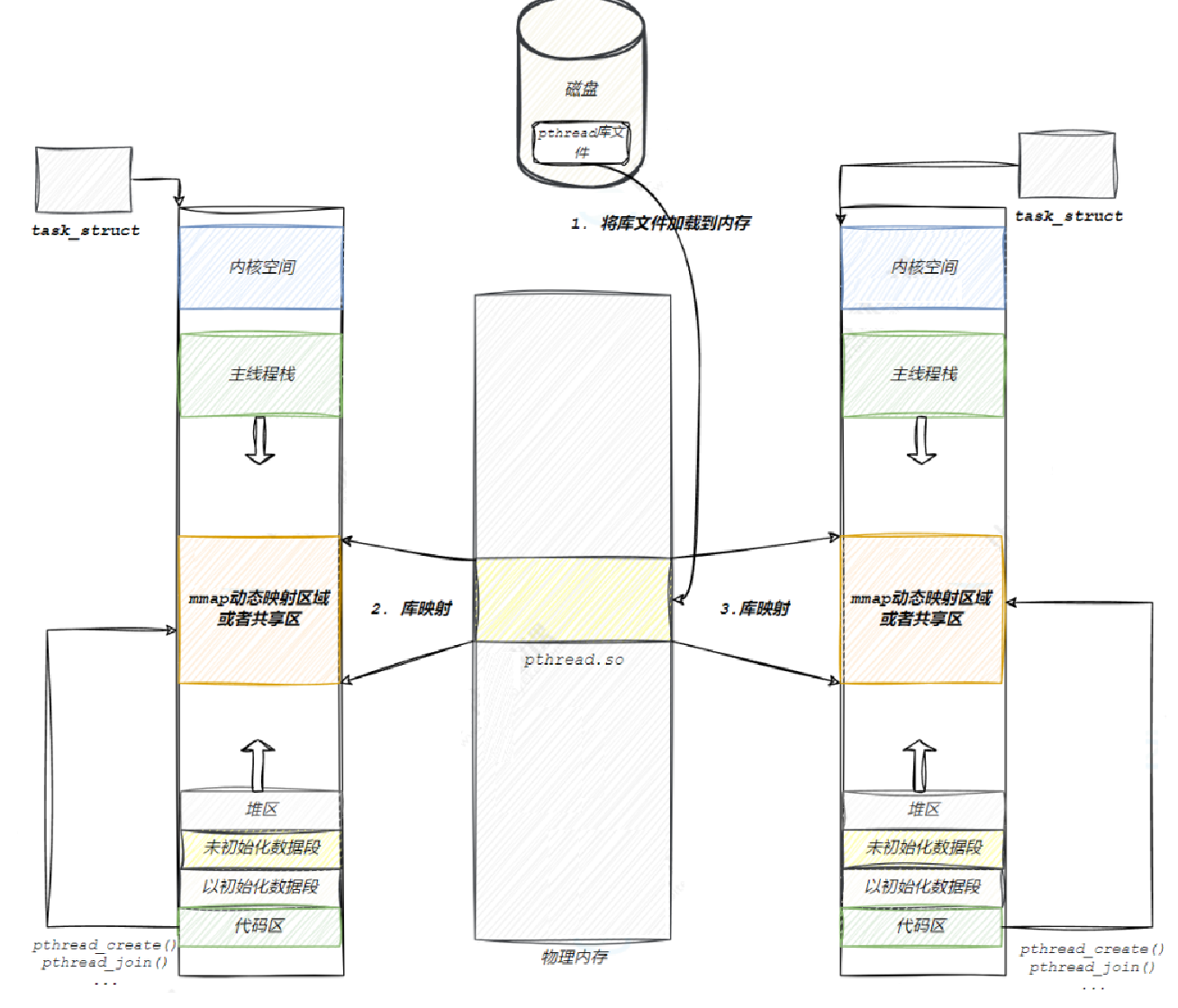
我们的可执行文件和库都是ELF格式的,当我们的可执行文件加载进内存形成进程,对动态地址进行重定向,如果发现库文件没有加载进地址空间触发缺页中断把库文件载入进内存再去创建页表建立映射,最后重新进行对动态地址的重定向,这样我们的进程可以访问我们的库中的函数。
为什么线程库是第三方库?
我们在上一篇博客中说过,在Linux中没有线程的概念,在Linux中线程是用轻量级进程去模拟的,但我们的《操作系统》教材规定每个操作系统都要有线程的概念,Linux要想要有线程的概念的话只能再写一份库去封装轻量级线程的概念向用户提供线程,这个库就是pthread库,pthread库又叫做原生线程库,所以在我们调用pthread库编译的时候要加上 -lpthread 让编译器知道这个库是第三方库。

为什么《操作系统》要求有线程我们就要实现线程?
因为《操作系统》就是我们计算机系统的一份指导手册,我们不同的操作系统比如Linux,Windows等就是基于《操作系统》的指导实现出来的一份具体方案,所以我们不可能要求用户再去学习Linux的底层,大家都去按一个指导思想去实现可以减少用户的学习成本。
2.2、pthread是如何实现线程的?
既然要封装线程的话,那么线程作为独立的执行流必须要有栈用作后面的函数栈帧的开辟和对临时数据的存储
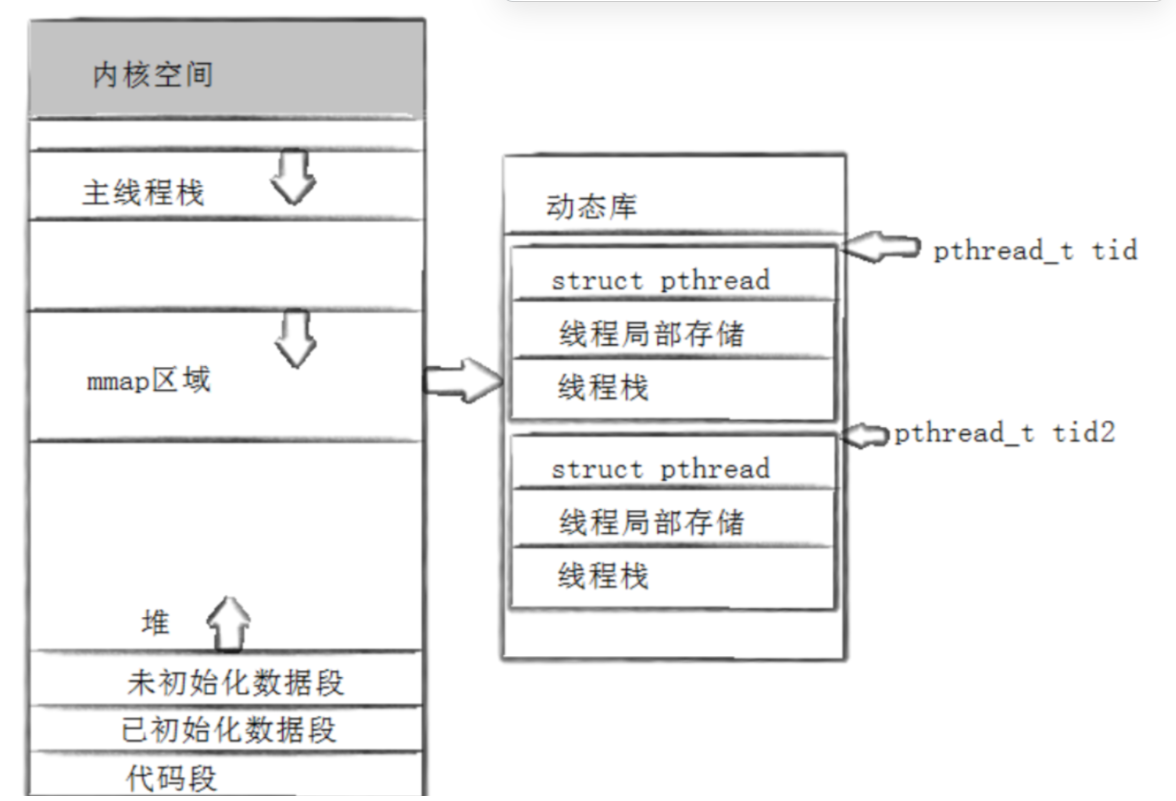
在我们的操作系统中有很多的线程,操作系统需要对这些线程管理,所有会调用pthread_create函数时会创建struct thread结构体和对应的线程栈空间,当线程被调度的时候产生的临时数据会被存在线程栈的内部。
调用pthread_create会做什么?
1、在库中创建线程的控制模块。
2、在内核中调用clone函数创建PCB,向clone函数传入函数指针和线程栈的地址。
那线程的ID是什么?
其实线程ID是一个地址,就是线程控制模块的地址也就是struct thread的地址。
2.3、__thread
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>int cnt = 100;
void *routine(void *args)
{std::string name = static_cast<const char *>(args);int num = 3;while (num--){cnt++;std::cout << name << std::endl;}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread -1");while (true){std::cout << "我是主线程 cnt:" << cnt << std::endl;sleep(1);}return 0;
}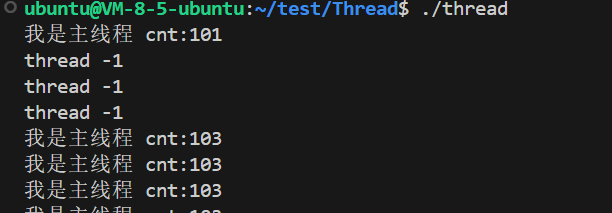
对于一个全局变量的话每个线程都可以去访问和改变,如果我们不想让其他线程改变这个变量我们可以在这个变量的前面加上__thread修饰,如果在一个全局变量前加__thread,这个变量不会在数据区开辟空间而是在每个线程的线程局部存储开辟。
#include <pthread.h>
#include <iostream>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <sys/types.h>__thread int cnt = 100;
void *routine(void *args)
{std::string name = static_cast<const char *>(args);int num = 5;while (num--){cnt++;std::cout << name << "cnt: "<< cnt << std::endl;}return nullptr;
}int main()
{pthread_t tid;pthread_create(&tid, nullptr, routine, (void *)"thread -1");while (true){std::cout << "我是主线程 cnt:" << cnt << std::endl;sleep(1);}return 0;
}
2.4、线程栈
当我们的创建线程的时候我们也要给对应的线程创建线程栈,因为线程作为一个执行流的概念它需要去执行代码开辟函数栈帧去存放临时变量和数据,当我们创建struct thread的时候也会开辟对应的线程栈,在struct thread中有一个指针指向这个线程栈的地址。从上面的图我们可以看见线程栈的位置也是在我们的用户区的。
下面我们来回答几个问题:
为什么我们的线程栈不放在内核空间中?
第一肯定是有安全性的考虑,因为如果用户线程栈结构在内核空间中那么如果这个线程更改内核的数据怎么办?所以为了安全性把它放在了用户空间。第二是从效率角度考虑的,因为如果线程栈放在内核空间我们的线程访问它自己的栈结构还需要从用户态转换成内核态并且线程肯定会频繁访问自己的线程栈这样的话会对效率大打折扣。
线程栈和我们fork出来的进程开辟的栈空间有什么不一样?
我们的线程栈不可以动态增长,开辟时开多大就多大不会再去增长,而我们的fork出来的进程的栈可以动态增长。我们的线程栈底层是我们mmap出来的对于其他线程也是可以看见的但由于其他线程不知道这个栈的具体地址无法访问,如果我们把这块栈的地址给其他的线程的话,其他线程也可以去访问,总结来说:对于线程而言其实大部分东西都是共享的,只有少部分是独占的(比如在内核结构中的task_struct(LWP))。
2.5、哪些数据是我们进程独占的?
我们说过我们的线程大部分都是共享的,只有少部分是独占的:
1、线程的LWD是自己独占的
这个也很好理解,我们的线程是调度的基本单位,调度就会有上下文数据,它们需要在线程切换的时候保存在task_struct中,当线程被切换回来的时候在把上下文恢复出来,这说明了什么线程的独立调度的。
2、线程有自己的栈
我们上面说过我们的线程栈只能被自己看见(别的线程能不能看见是取决我们程序员的,我们尽量不要让其他的线程看见),这说明了我们的线程是动态的概念,因为线程有自己独立的栈,可以被创建和终止而不影响其他的线程。
三、线程的优缺点
3.1、线程的优点
1、创建一个线程的代价比进程小
因为创建一个线程不需要申请内存空间,加载数据和代码,文件描述符表,页表等内核数据,创建线程只需要创建PCB,线程管理块,划分资源。
2、线程切换比进程切换代价小
次要原因:
线程切换不需要去切换页表只需要把PCB和CPU中的临时数据保存和切换就好了。
主要原因:
为了保证局部性原理,我们会把数据进行缓存,TLB(transfer lookaside buffer)又叫做快表用来进行保存高频使用的虚拟页地址和物理页地址的缓存,还有cache缓存,cache缓存可以将我们访问代码周围的代码加载进来减少访问内存IO的事件,其实cache缓存就是我们CPU的三级缓存(L1,L2,L3级),这个才是导致我们进程切换比线程切换慢的主要原因,如果进程切换我们要重新刷新,如果是线程切换这些大部分都不会变,效率会提高很多。
3、多线程可以充分利用多处理器可并行的数量
4、计算密集型应用可以将计算分在多个处理器上运行
比如游戏就是一个计算密集型应用,游戏画面的渲染需要GPU的大量的计算,它可以大数据分在多核上并发的执行最后再去合并数据
5、I/O密集型应用,可以多个进程进行I/O提高效率
比如下载就是I/O密集型,我们可以创建多个线程并行的去下载可以提高效率节省事件。
3.2、线程的缺点
1、对于计算密集型应用过多的线程会导致效率下降
因为过多的线程的话,操作系统会频繁调度进行线程的切换,线程切换是有代价的,太多线程,多线程并行的优势将会被线程的频繁调度抵消。
2、健壮性降低
因为线程共享地址空间,不像进程地址空间是相互独立的,如果一个线程异常整个进程都会被杀掉。
3、编程难度提高
这个很容易理解,并发编程肯定比但执行流的代码难写。
=========================================================================
本篇关于Linux的文件理解与操作的介绍就暂告段落啦,希望能对大家的学习产生帮助,欢迎各位佬前来支持纠正!!!
