NVIDIA Dynamo 推理框架
NVIDIA Dynamo 是 GTC 2025 上发布的开源分布式 AI 推理服务框架,旨在加速 AI 推理模型的部署。
- PD 分离:传统集成式推理流水线往往将 LLM 的 Prefill 和 Decode 阶段置于同一 GPU 上运行,资源需求不匹配导致 GPU 利用率不高。在推理服务中,如果用户请求 prefill 长度和 decode 长度非常不匹配,PD 分离是一个很好的选择。
- Prefix-aware rounter:在缺乏全局协调的情况下,不同请求的 KV Cache 会被反复计算和丢弃,造成大量冗余计算开销,所以需要 router 考虑 prefix 在哪个节点已经有了。SGLang 和 vllm production stack 里也有这样的设计
- KV cache offoading:大模型长上下文带来的 KV Cache 数据量极大,GPU 的 HBM 可能存不下,需要 offload 到 CPU memory 甚至 SSD 里。Mooncake、华为的 CachedAttention 等工作也有类似做法
- 推理流量的峰谷变化也使固定分配 GPU 资源的方式难以兼顾高负载和资源浪费 NVIDIA 宣称 dynamo 可以让 Llama 模型推理性能翻倍,在大规模集群上对 DeepSeek-R1 模型的推理 throughout 提升 30x+。
github:https://github.com/ai-dynamo/dynamo
1 整体架构
Dynamo采用模块化的分布式架构,由多个协同工作的核心组件组成,包括API 服务器、Planner、Smart Router、Prefill/Decode推理工作节点、Event plane、KV Cache manager以及NIXL高速通信库等。
- API 服务器:负责接收用户请求,兼容 OpenAI API,Llama API 等接口
- Planner:根据系统实时状态进行资源调度
- Smart Router:基于 LLM 请求内容和缓存状态执行智能请求路由
- Prefill/Decode 推理工作节点:实际的推理由底层的 prefill 和 decode 动作节点执行
- Event Plane:整个系统通过Event plane传递各组件的状态指标,由Planner动态调整GPU资源分配
- KV Cache manager:通过KV Cache manager维护全局的KV Cache索引(如使用Radix Tree)和多层次存储,实现缓存的快速存取与逐出
- NIXL库:在多节点环境下,Dynamo利用NIXL库进行低延迟的GPU间数据直传,绕过繁琐的中转拷贝,保障跨服务器通信的高吞吐和低延迟
- 扩展性:Dynamo的每个组件均可独立scale,方便魔改某一组件
- Rust + Python:核心性能相关模块使用Rust编写以保证性能和内存安全,而Python用于上层逻辑以方便开发定制
NVIDIA Dynamo的整体架构示意图如下:
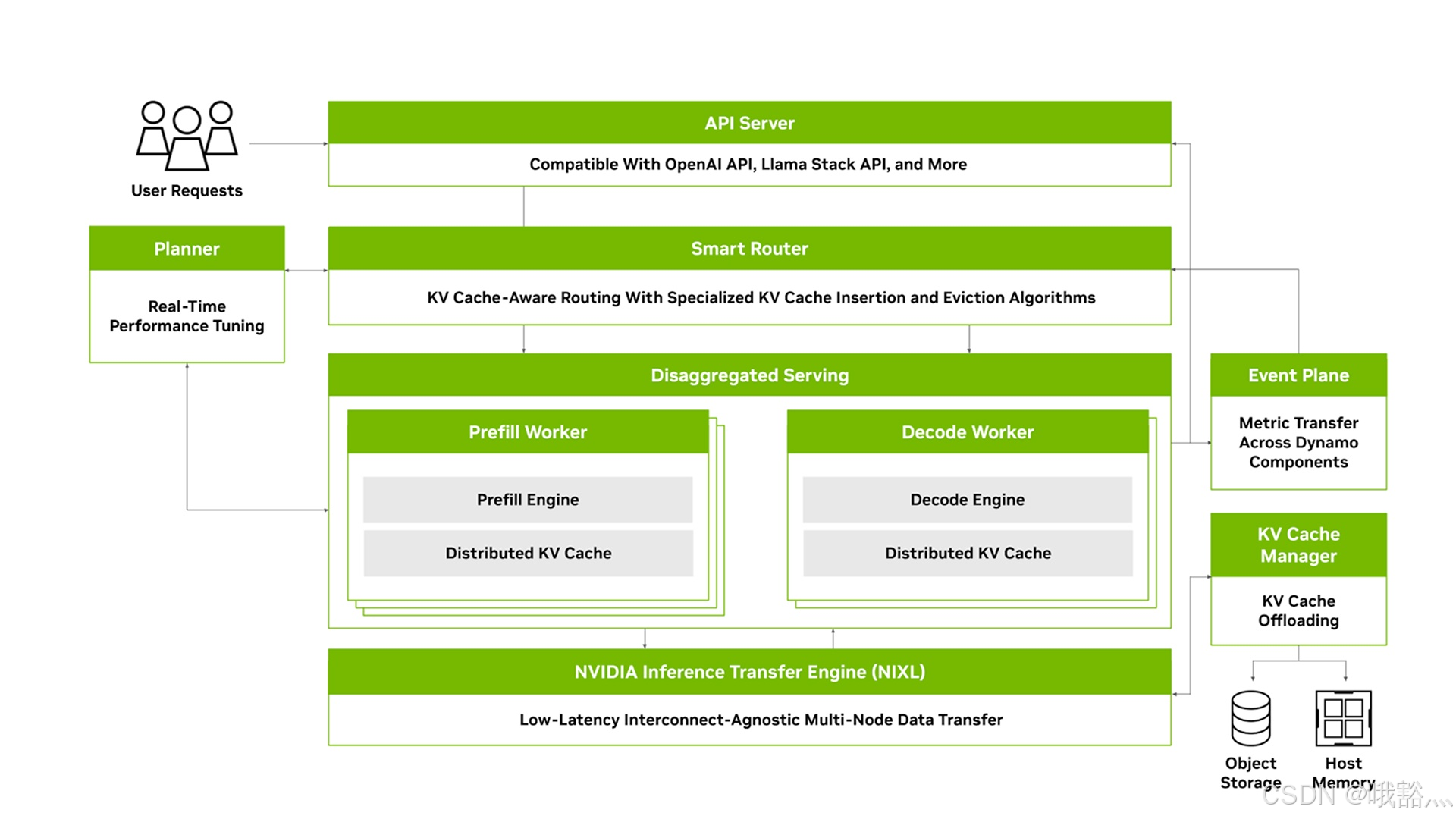
该架构将用户请求接入与后台推理执行解耦:
- API Server接收请求后,由Planner根据实时性能指标进行实时资源调优
- Smart Router执行KV Cache感知的请求路由,将请求分配给最优(例如prefix hit rate最高)的Prefill或Decode工作节点
- Prefill Worker和Decode Worker分别承担LLM推理的上下文处理和文本生成阶段,并通过分布式KV Cache共享上下文
- 底层的NIXL引擎提供低延迟、与互连硬件无关的数据传输能力,支持在多节点GPU、主机内存及存储之间零拷贝传递大规模推理数据。例如,当Prefill阶段完成后,可迅速将生成的KV Cache经由NIXL推送给Decode节点
- Event plane在各组件间传递度量和信号(如负载变化)
- KV Cache manager则维护全局的缓存索引(Radix Tree)并负责将冷数据异步地卸载到CPU内存、NVMe SSD或远端存储,以腾出GPU显存
2 主要技术
NVIDIA Dynamo包含四项关键技术创新来降低大规模LLM推理的开销、提升性能: 分离式推理(Disaggregated Prefill)、智能请求路由(Smart Routing)、分布式KV Cache管理(Distributed KV Cache Manager)、NIXL高速传输库
2.1 分离式推理(Disaggregated Prefill)
大规模LLM推理通常分为两个阶段:
- Prefill阶段:负责处理用户输入(将提示词编码为 embedding 并通过 Transformer 模型生成首个输出 token),计算密集型且主要消耗算力;
- Decode阶段:负责根据上下文依次解码生成后续输出 token,对内存带宽和缓存依赖更强。
传统方案往往在同一 GPU 上串行执行这两个阶段,但由于二者的资源需求特性不同,这种聚合式部署无法充分利用 GPU:在 Prefill 计算时 Decode 部分资源闲置,反之亦然,造成性能瓶颈
为此,Dynamo 采用分离式推理,将 LLM 推理的上下文处理处理和生成两个阶段拆分到不同的 GPU 或节点上执行。这样可以根据各阶段特点分别优化:**在 Prefill 阶段使用较低的张量并行度以减少通信开销,而在 Decode 阶段采用较高的并行度来增强内存访问效率。**通过针对性地为每个阶段分配最合适的 GPU 类型和并行策略,分离式推理能够提升整体吞吐率、降低端到端延迟,并允许对首字节延迟(TTFT)和逐 token 延迟(ITL)进行更细粒度的性能调优。
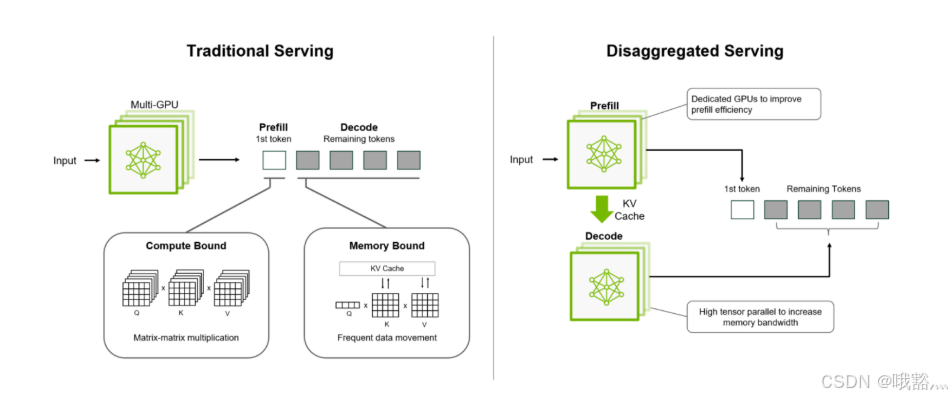
分离式架构显著改善了多GPU推理的Scale效率。在单机H100环境对Llama-70B模型的测试中,引入Dynamo后每卡吞吐提升约30%,而在两机分布式情况下吞吐提高超过2倍。
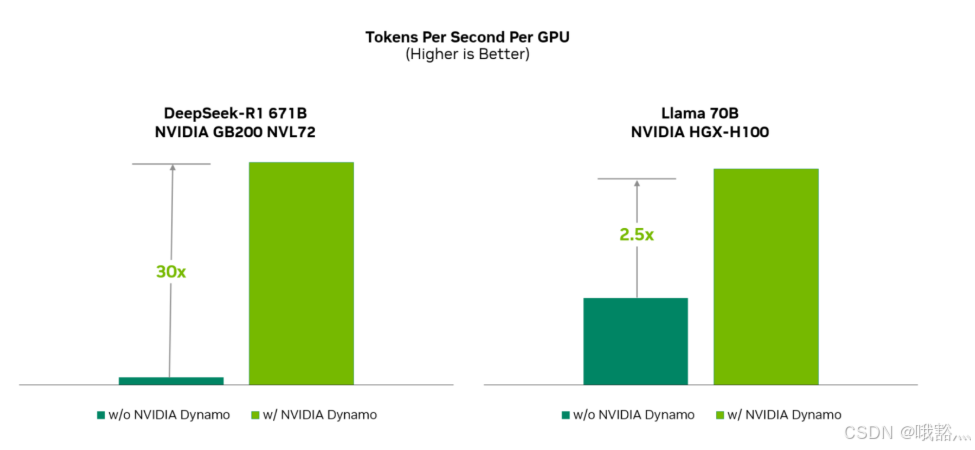
在部署6710亿参数的DeepSeek-R1推理服务时,使用NVIDIA GB200 NVL72(Blackwell架构)GPU集群并启用Dynamo的分离式推理,可使每GPU每秒生成的Token数提升约30倍;对于70亿参数的Llama-70B模型在NVIDIA HGX-H100平台上,Dynamo也实现了超过2倍的吞吐提升 。
2.2 智能请求路由(Smart Routing)
大型语言模型在处理每个请求时都会生成KV Cache,用于存储对话上下文或中间推理思考结果。
生成KV Cache非常耗时,其计算复杂度随输入长度平方增长。然而在许多场景下,不同请求间存在重复或相似的上下文,例如相同的系统提示、多轮对话中的上下文复用、或多个代理任务共享部分知识。这就意味着如果能复用之前计算得到的KV Cache,则无需每次都从零计算,能够显著降低延迟和计算消耗。
Smart Router 会对每个传入的内容进行哈希,并将其记录在全局Radix Tree中,以跟踪在集群各GPU上已缓存的KV数据位置。当新的推理请求到来时,Router首先计算该请求与各GPU已存在KV Cache块的“重叠得分”,综合考虑缓存命中程度和各GPU当前负载情况,将请求智能地路由到KV Cache命中率最高且资源空闲的GPU上。
此外,Smart Router 还设计了 KV Cache 插入和 eviction 算法。
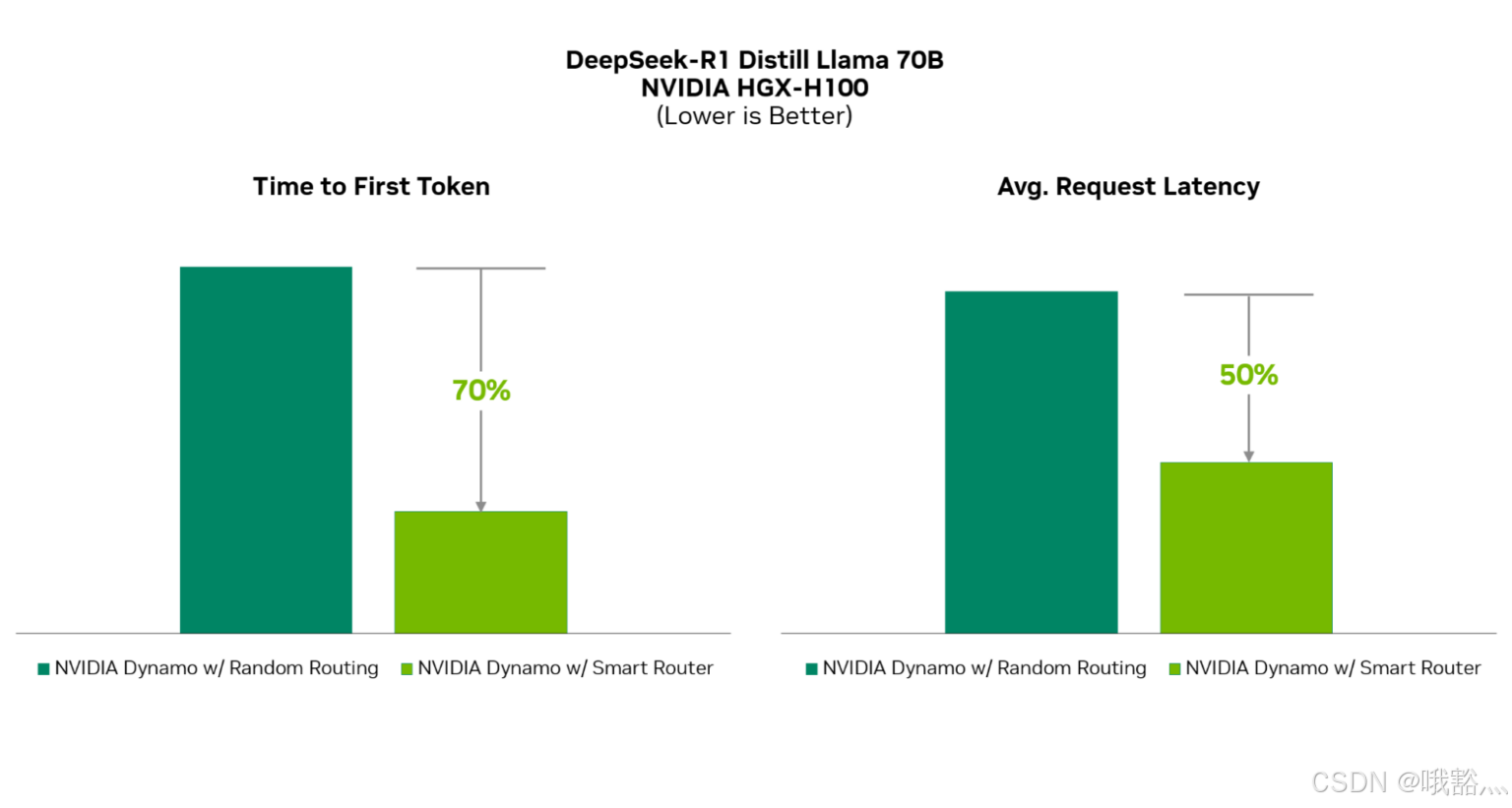
这种KV Cache感知路由显著提升了模型响应效率。在实际测试中,与不考虑缓存的简单负载均衡策略相比,Dynamo Smart Router使LLM的首字节延迟(TTFT)减少约70%,平均请求延迟降低约50%。
在双节点H100集群上对8实例Distill-Llama-70B模型进行10万次真实请求测试的结果:
2.3 分布式KV Cache管理(Distributed KV Cache Manager)
分布式KV Cache manager负责在全局范围内存储和调度LLM推理过程中产生的大量KV Cache。对于支持长上下文和海量并发的推理服务而言,KV Cache的size可能远超单机GPU的显存容量。
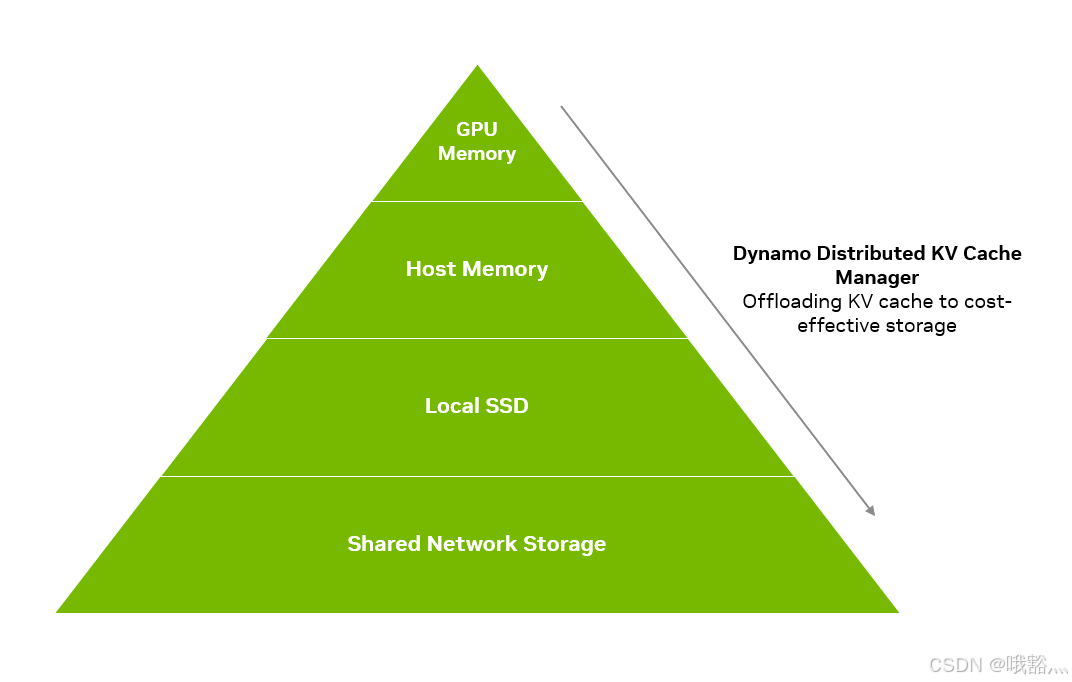
Dynamo选择了分层存储:将不常访问的KV Cache块从GPU显存中offload到容量更大且成本更低的存储介质中,例如主机DDR内存、本地SSD甚至远程对象存储。
当有新请求到来时,KV管理器会决定是使用GPU本地缓存、还是从CPU内存或更慢的介质中提取所需的KV数据,从而在开销和效率之间取得平衡。
KV Cache manager的eviction policy试图在“过度缓存”(缓存过多导致查找变慢)和“缓存不足”(由于缓存不足导致命中率下降)中取得平衡。该manager能够跨多GPU节点协同工作,支持分布式和分离式推理场景下的全局KV Cache共享,并提供分层级的缓存策略(GPU节点内部、节点之间、集群全局)以充分利用各层级的存储资源。
NVIDIA做了80位用户+每人10轮对话的模拟实验。即使在推理引擎开了GPU prefix caching的情况下,引入offloading方案后,TTFT仍额外改善约40%。
2.4 NIXL(NVIDIA Inference Transfer Library)
在分布式推理场景下,大规模模型推理不仅需要消耗计算和内存资源,还对节点间的数据传输提出了极高要求。
- LLM 的并行(张量并行TP,流水线并行PP,专家并行EP等)需要GPU间频繁交换激活和梯度
- 在Dynamo的分离式推理中,Prefill阶段计算得到的KV Cache需要快速发送给Decode阶段所在的其他GPU节点
- 传统训练中常用的通信机制(如GPU直接RDMA、NCCL等)在推理场景下有有一些不足:推理负载的通信模式更为动态和复杂,可能涉及GPU与CPU内存、甚至SSD之间的数据交换。
Dynamo集成了全新的NVIDIA推理传输库(NIXL)。NIXL是一个高吞吐、低延迟的点对点通信库,提供统一的API来在不同存储介质间快速异步传输数据。它针对推理的数据流特点进行了优化,支持非阻塞和非连续内存的数据传输操作,提升跨GPU、CPU内存以及磁盘/对象存储的数据移动性能。
NIXL 希望在硬件和网络拓扑上实现了无关性和自适应性。它封装了底层的多种通信后端,如GPUDirect Storage、UCX、甚至S3协议等,并针对具体环境(NVLink/NVSwitch、InfiniBand、RoCE以太网等互连)自动选择最优的传输方式。开发者只需使用NIXL提供的统一接口描述数据传输需求,而无需关心数据是在HBM显存、主机DRAM、本地SSD还是远程对象存储上,也不需要指定使用哪种网络协议——NIXL会抽象这些差异,采用通用的内存段概念表示各种存储介质,并将数据高效地在其间搬运。
NIXL通过减少同步开销和智能批处理来加速数据传输,显著降低了分布式推理中的通信延迟。这在Prefill/Decode分离部署时很重要:有了NIXL,Prefill节点可以在毫秒级将大批量KV Cache推送给Decode节点,这样分离式推理并不会因为跨节点的数据交换而拖慢生成速度。
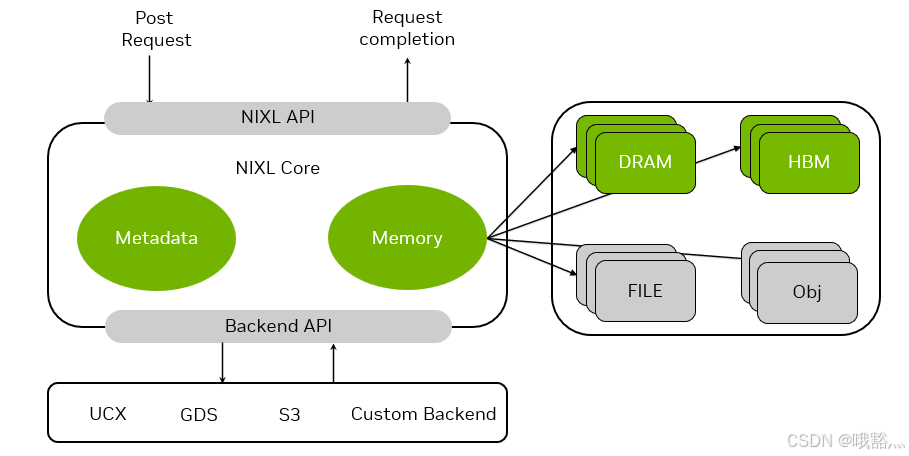
NIXL提供上层统一的API(灰色栏)供推理服务调用,将数据传输请求提交至NIXL核心。NIXL核心内部管理传输元数据和内存操作(绿色模块),底层通过Backend API对接各种通信后端实现,包括UCX、GPUDirect Storage (GDS)、S3协议或自定义后端等。右侧示意NIXL能够处理不同类型的源和目标内存介质(GPU HBM、高带宽DRAM、本地文件、对象存储等),并对上传/下载过程进行了抽象封装。当应用通过NIXL API提交数据传输请求后,NIXL核心将数据从源内存提取并经由适当的后端(如NVLink直连、InfiniBand、以太网)传输,在目标端完成写入,最后通过回调通知请求完成。