NLP---自然语言处理
一·语言转换方法
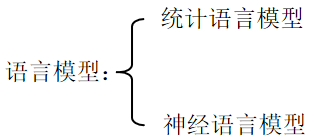
统计语言模型存在的问题:
1 、由于参数空间的爆炸式增长,它无法处理
( N>3 )的数据。
2 、没有考虑词与词之间内在的联系性。例如,
考虑 "the cat is walking in the bedroom" 这
句话。如果我们在训练语料中看到了很多类似
“ the dog is walking in the bedroom” 或是
“ the cat is running in the bedroom” 这样
的句子;那么,哪怕我们此前没有见过这句
话 "the cat is walking in the bedroom" ,也
可以
从“ cat” 和“ dog” (“ walking” 和“ runni
ng” )之间的相似性,推测出这句话的概率。
经语言模型 --- 词嵌入 embedding
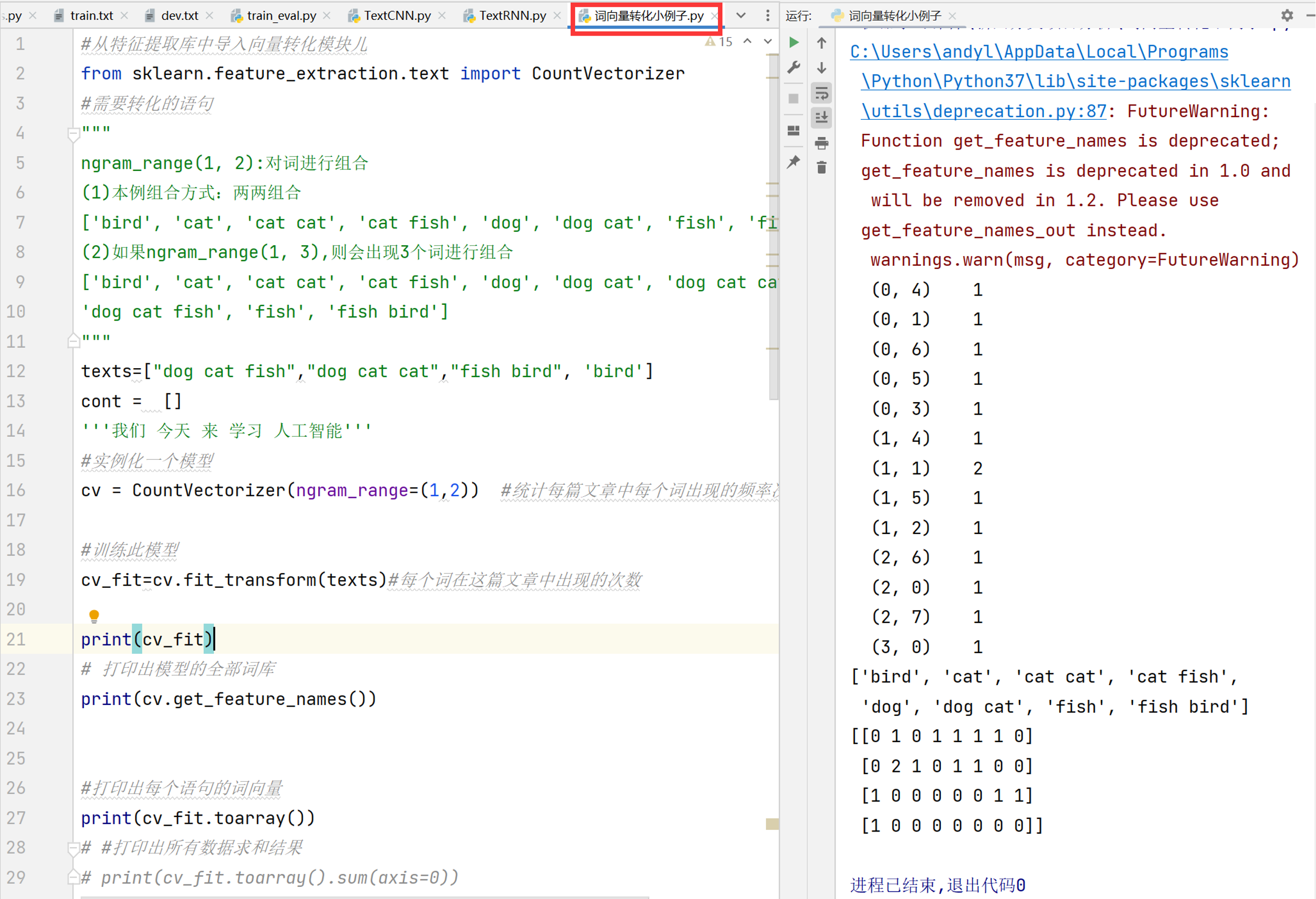
在处理自然语言时,通常将词语或者字做向量化,例如 one-hot 编码,例如我们有一句话为:“我爱北京天安门”,我们分词后对其
进行 one-hot 编码,结果可以是:
“我”: [1,0,0,0]
“爱”: [0,1,0,0]
“北京”: [0,0,1,0]
“天安门”: [0,0,0,1]
如果需要对语料库中的每个字进行 one-hot 编码如何实
现?
2 、按顺序依次给每个词进行 one-hot 编码,例如第 1 个词为: [1,0,0,0,0,0,0,….,0] ,最后 1 个词为: [0,0,0,0,0,0,0,….,1]
存在的问题?
矩阵为非常稀疏,出现维度灾难。例如有一句话为“我爱北京天安门”,传入神经网络输入层的数据为:
[1,0,0,0,0,0,0,
….,0]
[0,1,0,0,0,0,0, ( 4*4960 )
….,0]
[0,0,1,0,0,0,0,
….,0]
如何解决维度灾难问题 ?
通过神经网络训练,将每个词都映射到一个较短的词向量上来。
这个较短的词向量维度是多大呢?
一般需要在训练时自己来指定。现
在很常见的例如 300 维。
例如有一句话为“我爱北京天安门”,通过神经网络训练后的数据为:
[0.62,0.12,0.01,0,0,0,0,
….,0]
[0.1,0.12,0.001,0,0,0,0, ( 4*300 )
….,0]
[0,0,0.01,0.392,0.39, 0,
….,0]
[0,0,0,1,0,0.01,0.123,
….,0.11]
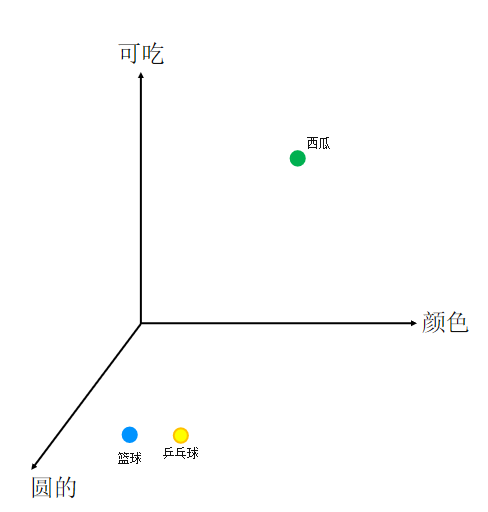
什么是词嵌入?
这种将高维度的词表示转换为低维度的词表示的方法,我们称之为词嵌入( word embedding )。
Google 研究团队里的 Tomas Mikolov 等人于 2013 年的《 Distributed Representations ofWords and Phrases and their
Compositionality 》以及后续的《 Efficient Estimation of Word Representations in Vector Space 》两篇文章中提出的一种
高效训练词向量的模型,也就是 word2vec 。
二·循环神经网络 RNN
序列数据:如文本、语音、股票、时间序列等数据,当前数据内容与前面的数据有关
传统神经网络存在的问题?
无法训练出具有顺序的数据。模型搭建时没有考虑数据上下之间的关系。
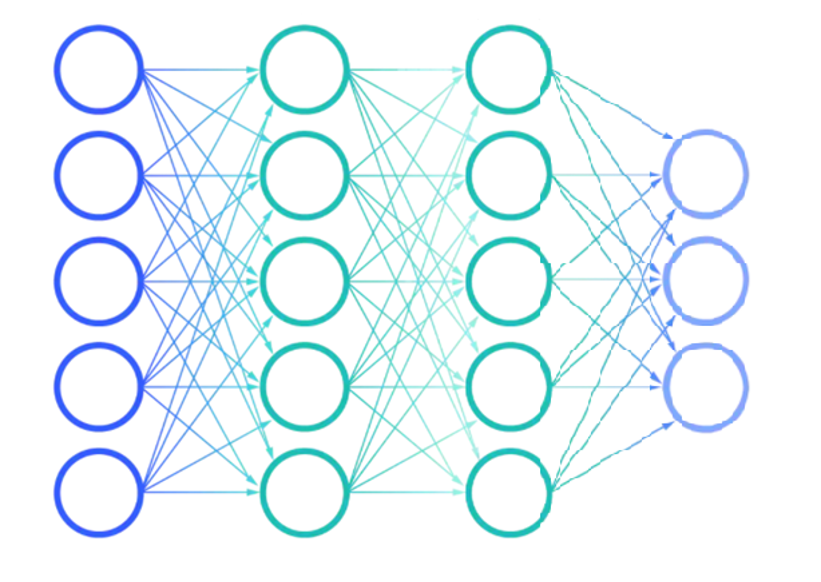
提出一种新的神经网络:
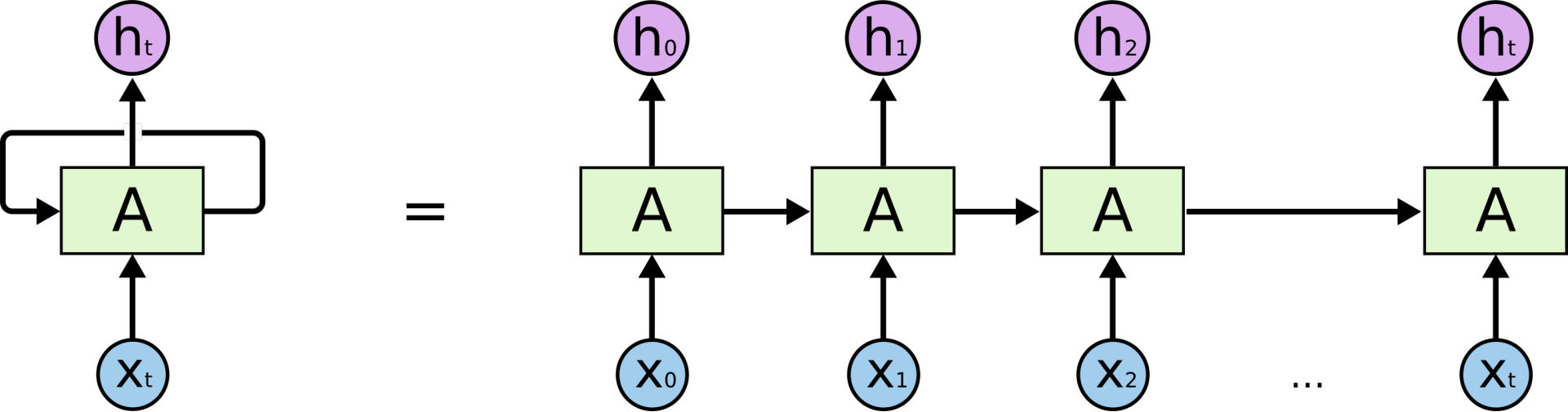
RNN ( Recurrent Neural Network )在处理序列输入时具有记忆
性,可以保留之前输入的信息并继续作为后续输入的一部分进行计算。
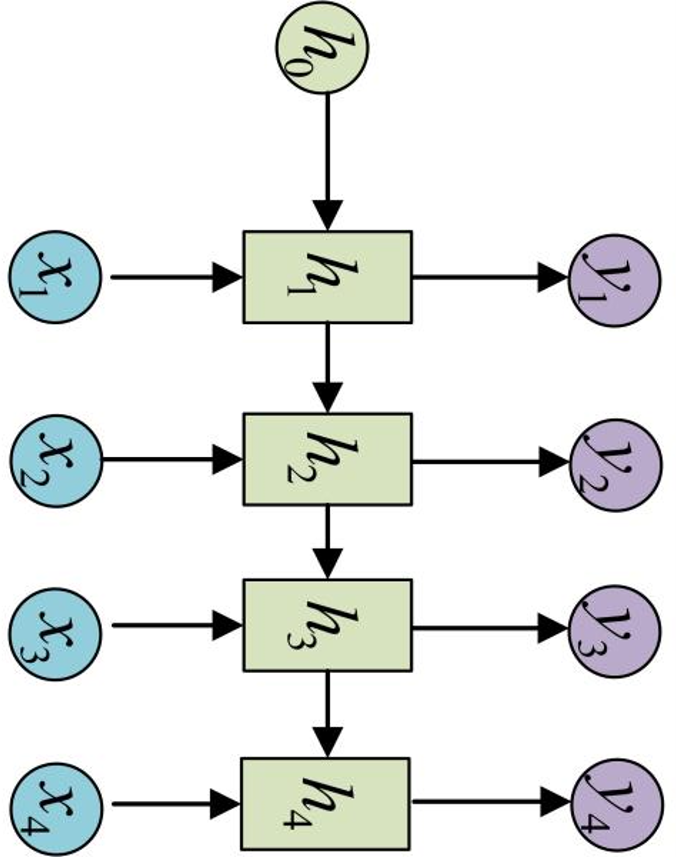
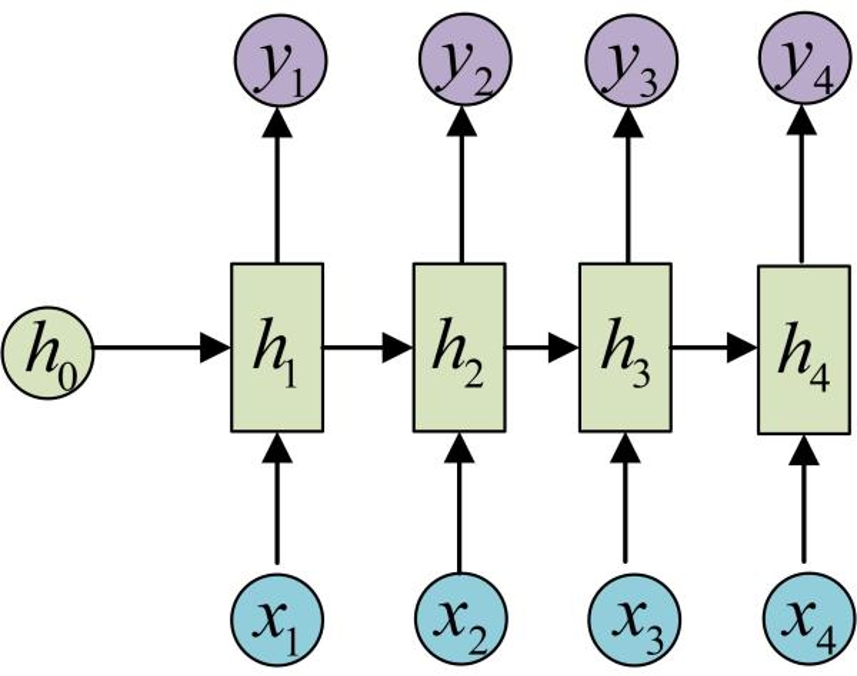
RNN 的特点:引入了隐状态 h ( hidden state )的概念,隐状态 h 可以对序列形的数据提取特征,接着再转换为输出。
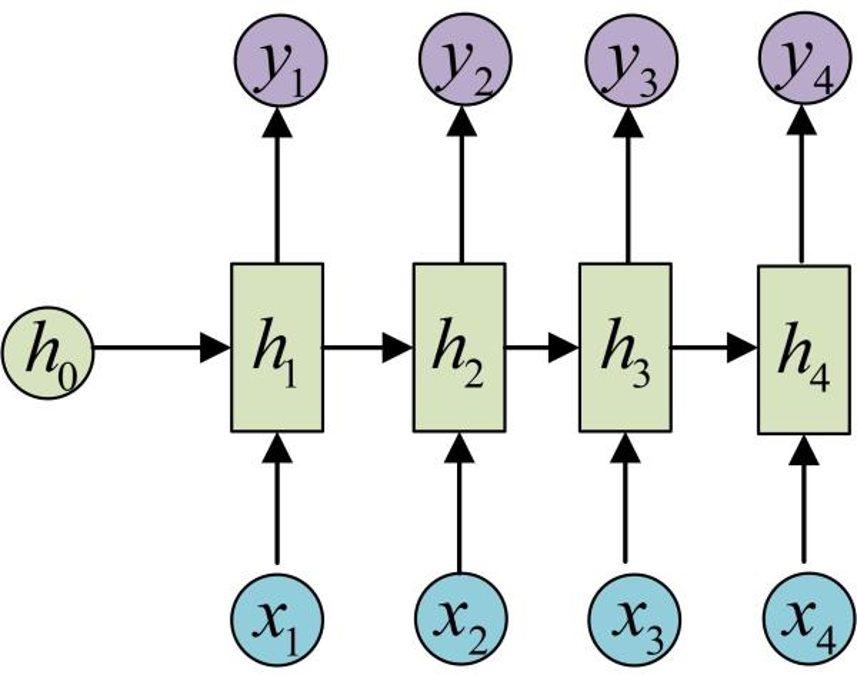
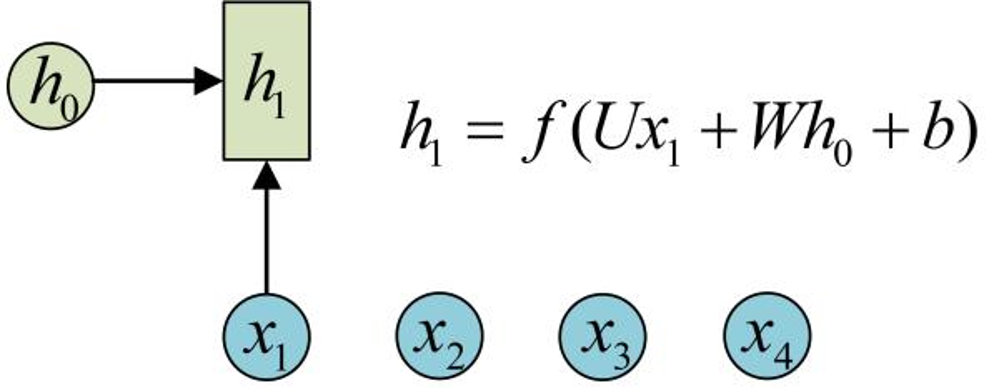
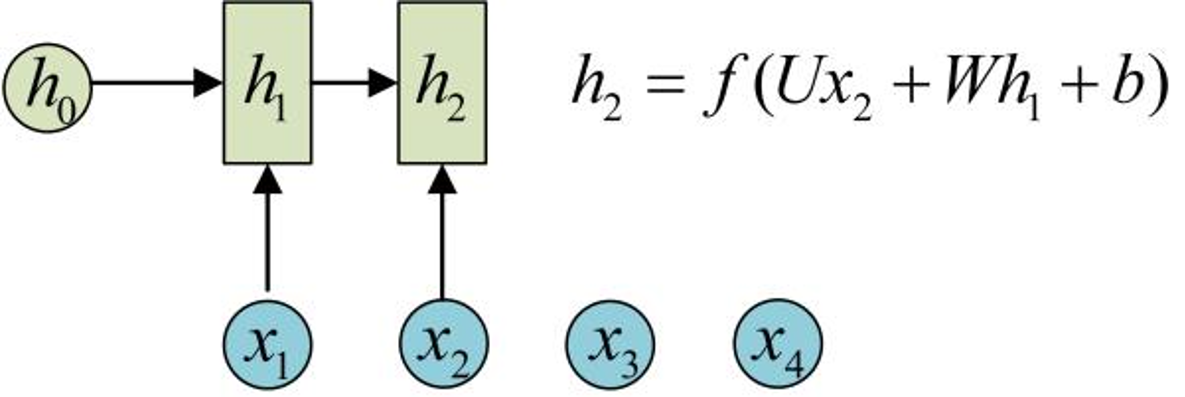
为了方便起见,只画出序列长度为4的情况,实际上,这个计算过程可以无限地持续下去。
注意:
1 、在计算时,每一步使用的参数 U 、 W 、
b 都是一样的,也就是说每个步骤的参数都
是共享的,这是 RNN 的重要特点;
2 、下文的 LSTM 和 GRU 中的权值则不共
享。
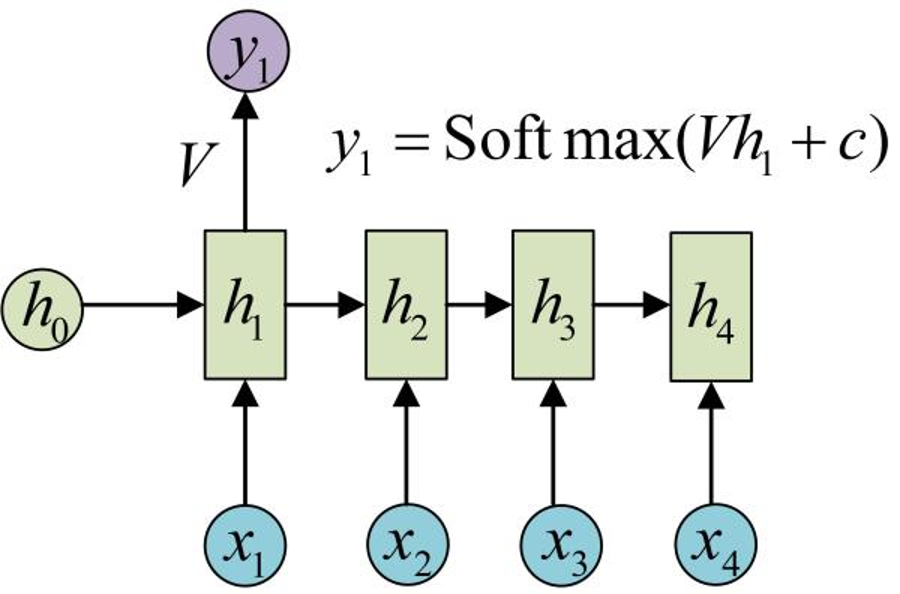
RNN 结构中输入是 x1, x2, .....xn ,输出为 y1,
y2, ...yn ,也就是说,输入和输出序列必须要
是等长的
循环的由来:
RNN的局限:
当出现“我的职业是程序员,…,我最擅长的是电脑”。当需要预测最后的词“电脑”。当前的信息建议下一个词可能是一种技能,但是如果我们需要弄清楚是什么技能,需要先前提到的离当前位置很远的“职业是程序员”的上下文。这说明相关信息和当前预测位置之间的间隔就变得相当的大。 在理论上,RNN绝对可以处理这样的长期依赖问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN则没法太好的学习到这些知识。 原因是:梯度会随着时间的推移不断下降减少,而当梯度值变得非常小时,就不会继续学习。
循环神经网络 --- LSTM网络
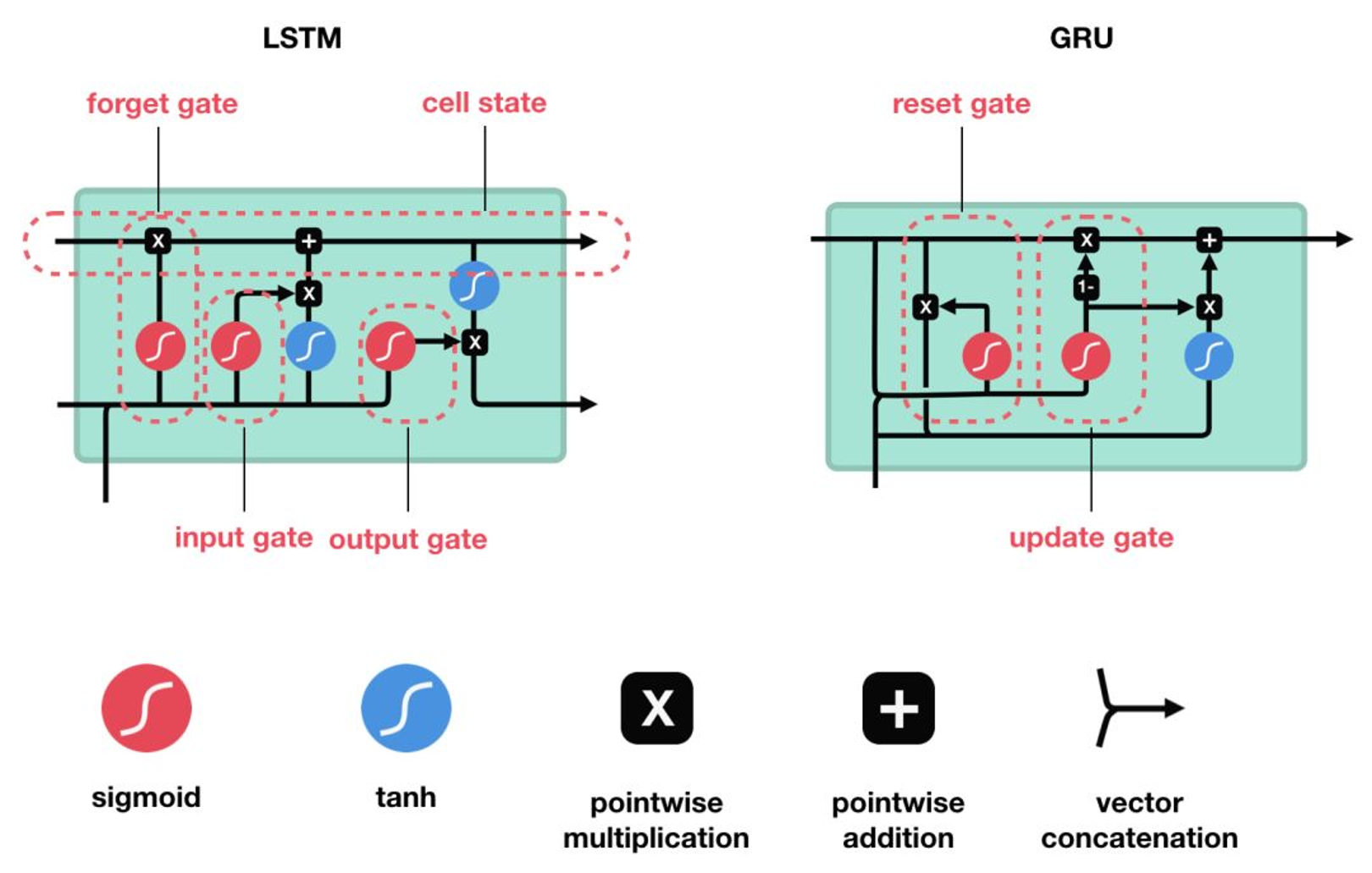
LSTM的介绍:是一种RNN特殊的类型,可以学习长期依赖信息。大部分与RNN模型相同,但它们用了不同的函数来计算隐状态。
举例:当你想在网上购买生活用品时,一般都会查看一下其他已购买的用户评价。当你浏览评论时,大脑下意识记住重要的关键词,比如“好看”和“真酷”这样的词汇,而不太会关心“我”、“也”、“是”等字样。如果朋友第二天问你用户评价都说了什么,你不可能会全部记住它,而是说出大脑里记得的主要观点,比如“下次肯定还会来买”,无关紧要的内容自然会从记忆中逐渐消失。
LSTM (长短时记忆网络)或 GRU(门控循环单元)就是如此,它们可以学习只保留相关信息来进行预测,并忘记不相关的数据。简单说,因记忆能力有限,记住重要的,忘记无关紧要的。
LSTM网络的介绍
LSTM 和 GRU 是解决短时记忆问题的解决方案,它们具有称为“门”的内部机制,可以调节信息流。
RNN网络的结构
1、第一个词被转换成了机器可读的向量,然后 RNN 逐个处理向量序列。
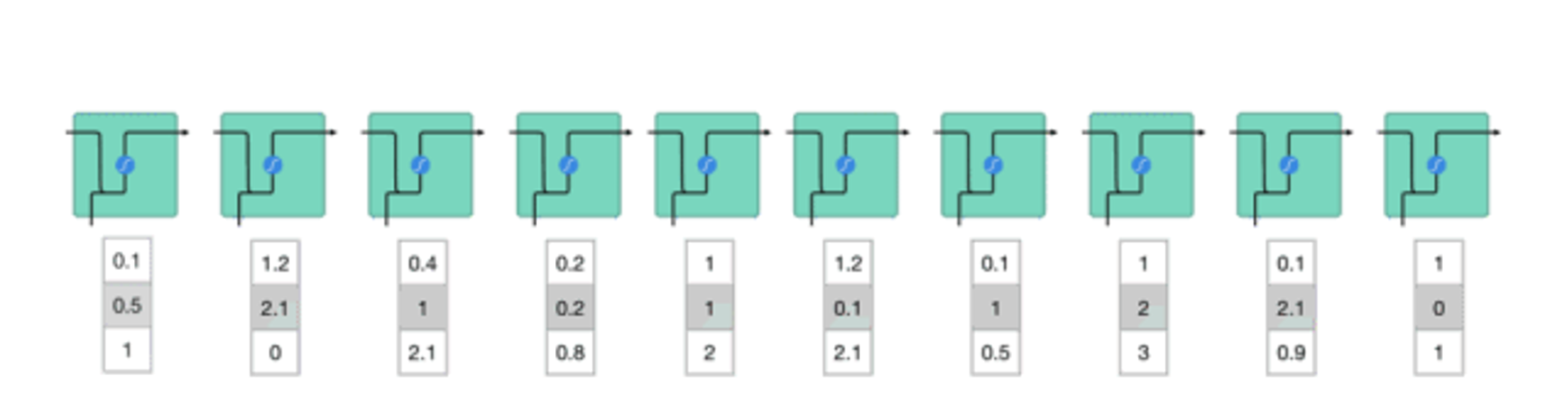
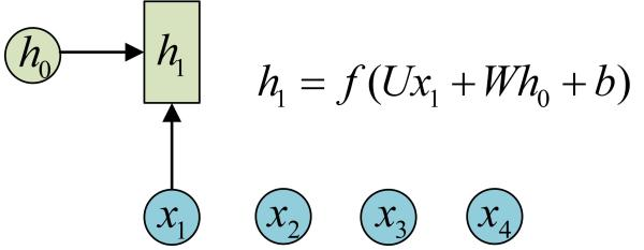
小细节
tanh 函数确保值保持在 -1~1 之间,从而调节了
神经网络的输出,相当于给每一层做了一次归一化。
LSTM 有3种类型的门结构:
遗忘门
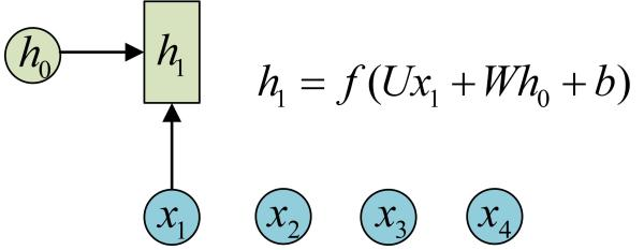
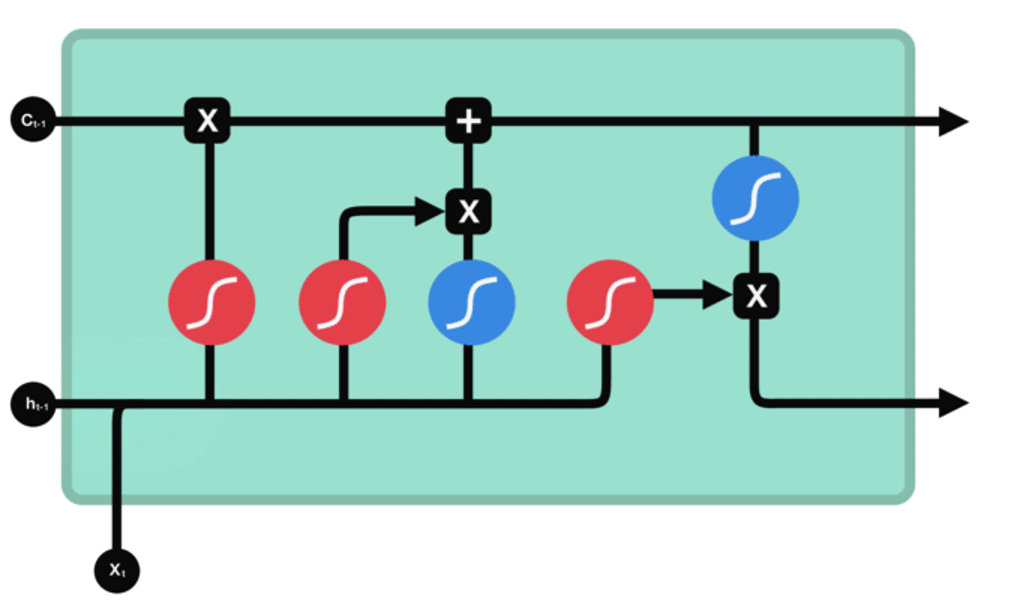
功能:决定应丢弃或保留哪些信息。
步骤:来自前一个隐藏状态的信息和当前
输入的信息同时传递到 sigmoid 函数中
去,输出值介于 0 和 1 之间,越接近
0 意味着越应该丢弃,越接近 1 意味着
越应该保留。
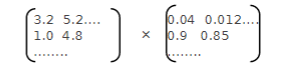
输入门
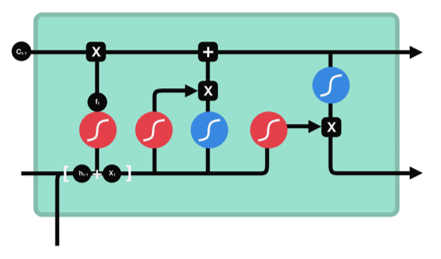
功能:用于更新细胞状态。
步骤: 1 、首先将前一层隐藏状态的信息和当前输入的信息传
递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要
更新哪些信息。 0 表示不重要, 1 表示重要。
2 、将前一层隐藏状态的信息和当前输入的信息传递到 tanh
函数中去,创造一个新的侯选值向量。最后将 sigmoid 的输
出值与 tanh 的输出值相乘, sigmoid 的输出值将决定
tanh 的输出值中哪些信息是重要且需要保留下来的。
输出门
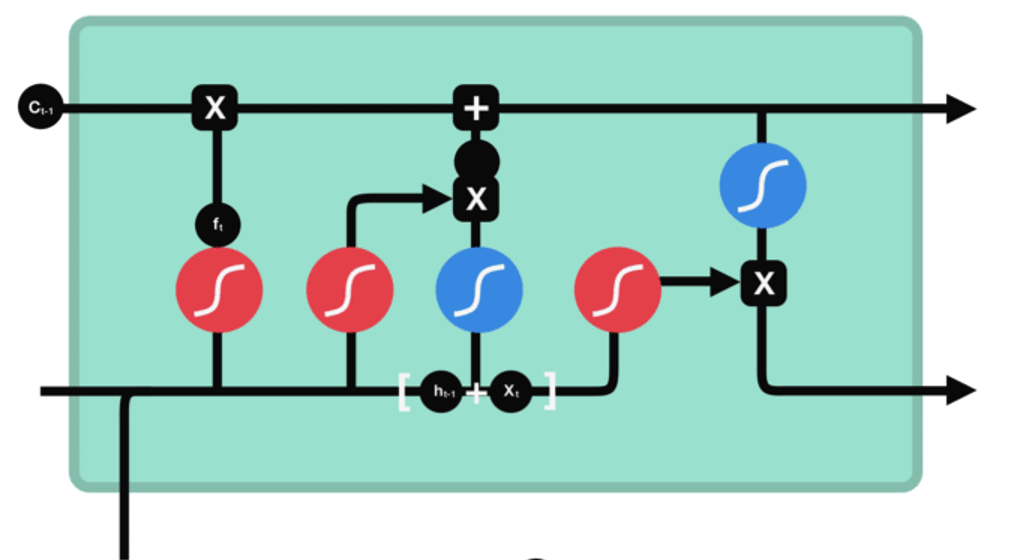
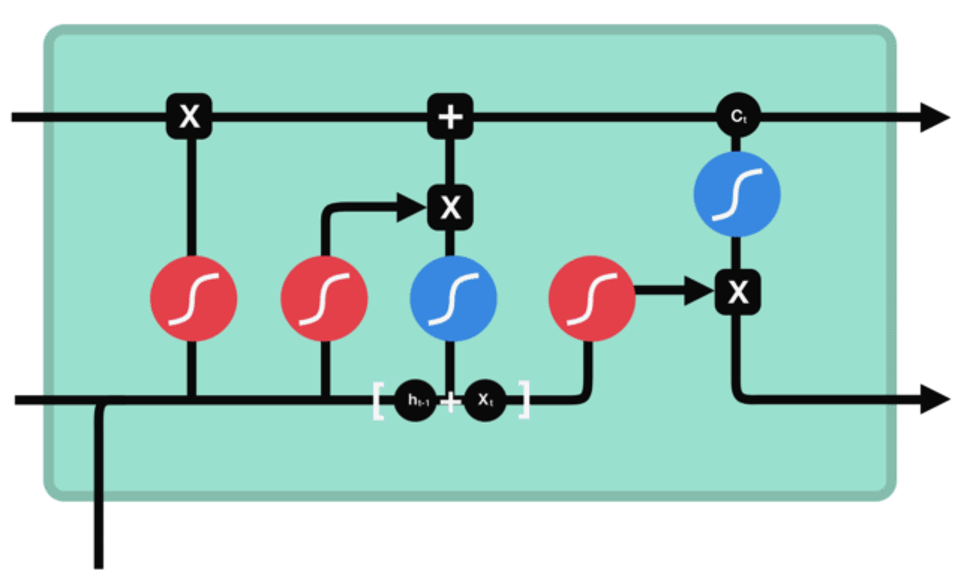
功能:用来确定下一个隐藏状态的值。
步骤: 1 、将前一个隐藏状态和当前输入传递到 sigmoid
函数中,然后将新得到的细胞状态传递给 tanh 函数。
2 、将 tanh 的输出与 sigmoid 的输出相乘,以确定隐
藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,
把新的细胞状态和新的隐藏状态传递到下一个时间步长中
去。
自然语言处理项目(情感分析)
项目介绍
vocab

思考:向模型中传递数据时,需要提前处理好数据
1 、目标:将评论内容转换为词向量。
2 、每个词 / 字转换为词向量长度 ( 维度 )200
3 、每一次传入的词 / 字的个数是否就是评论的长度 ?
应该是固定长度,每次传入数据与图像相似。
例如选择长度为 32 。则传入的数据为 32*200
4 、一条评论如果超过 32 个词 / 字怎么处理?
直接删除后面的内容
5 、一条评论如果没有 32 个词 / 字怎么处理?
缺少的内容,统一使用一个数字(非词 / 字的数字)替代。
6 、如果语料库中的词 / 字太多是否可以压缩?
可以,某些词 / 字出现的频率比较低,可能训练不出特征。因此可以
选择频率比较高的词来训练。例如选择 4760 个。
7 、被压缩的词 / 字如何处理?
可以统一使用一个数字(非词 / 字的数字)替代。