设计模式(C++)详解—享元模式(2)
各位亲爱的技术探险家们!准备好你们的好奇心,我们将开启一场关于享元模式(Flyweight Pattern)的深度奇幻之旅。这次旅程不仅有严谨的技术剖析,更有生动的比喻和故事,保证让你在轻松愉快的氛围中,彻底掌握这个“四两拨千斤”的设计模式。我们的目标是:不仅讲得透彻,更要让你听得过瘾!
<摘要>
享元模式是一种“以共享取胜”的轻量级英雄,它专门解决“对象海啸”导致的内存危机。其核心魔法在于:将对象的“灵魂”(内在状态,不变且可共享)与“躯壳”(外在状态,可变且不可共享)分离。通过建立一个“共享魂器库”(享元工厂),系统只需存储少量“灵魂”,而无数个“躯壳”则可以在运行时被灵活装配,从而用极小的内存开销驱动海量的对象表现。它是线程池、连接池等池化技术的设计基石,广泛应用于游戏世界、文本宇宙、图形王国等需要处理“人山人海”式对象的场景。本文将用一场长达20000字的沉浸式冒险,带你从设计模式的哲学思考,到C++的代码实战,再到数据库连接池的深度揭秘,彻底读懂、玩转享元模式。
<解析>
1. 背景与核心概念:一场内存世界的“粮食危机”
1.1 起源故事:对象王国的“人口爆炸”
想象一下,你是一位伟大的造物主(程序员),正在创造一个绚丽的文字世界(文本编辑器)。最初,你创造每一个字符(Character)都倾注心血,赋予它们完整的属性:字形、字体、大小、颜色,还有它们在文档中的位置。
// 一个“富二代”字符对象,啥都有,非常独立
class RichCharacter {
public:char charCode; // 它是谁?(如'A')string font; // 穿什么衣服?(如"Arial")int size; // 体型多大?(如12)Color color; // 什么颜色?int row, col; // 住在哪里?(行,列)// ... 还有各种方法
};
一开始,世界很小,只有一页文档,几百个字符。每个字符都占着一份家产(内存),其乐融融。
但很快,你的世界迎来了爆炸式增长!用户开始写入长篇巨著——十万字、一百万字的文档。如果你为这一百万个字符创建一百万个RichCharacter对象,你的内存王国将会面临一场可怕的“粮食危机”(内存耗尽)!而你会发现,这一百万个字符里,‘A’这个字符可能就出现了8万次。这8万个‘A’,除了位置(row, col)不同,它们的字形、字体、大小甚至颜色都一模一样!
这就好比:
你要为一场八万人的盛大晚会准备晚餐。如果给每个人都单独配一个专属厨房、一套专属厨师、一套独一无二的食谱和炊具,那成本将是天文数字,场地也根本不够用(内存爆炸)。但聪明的你发现,这八万人其实只吃有限的几种套餐(A套餐、B套餐…)。你真正的需求是:8万个不同的就餐座位(位置),但只需要准备几种食谱(内在状态)。
享元模式的智慧,就在于此。它不是在每个座位旁建厨房,而是建一个中央厨房(享元工厂),只负责生产几种标准套餐(享元对象)。你需要做的,就是把对应的套餐送到正确的座位上(传入外在状态)。
1.2 核心概念:对象的“灵魂”与“躯壳”
享元模式将对象的信息一分为二,这是它最精妙的设计:
| 概念 | 比喻 | 特点 | 文字编辑器中的例子 |
|---|---|---|---|
| 内在状态 (Intrinsic State) | 对象的“灵魂” 定义了它是“谁”,是它的本质 identity。 | 可共享的、不变的 如同标准食谱,可以被无数人使用。 | 字符的编码(‘A’)、字体(Arial)、大小(12pt)。所有‘A’的灵魂都一样。 |
| 外在状态 (Extrinsic State) | 对象的“躯壳”或“上下文” 定义了它在“哪里”,以及“当前怎样”。 | 不可共享的、可变的 如同每个人的就餐座位和就餐时间。 | 字符的位置(第5行第10列)、颜色(在某些情况下)。每个‘A’的躯壳都不同。 |
享元模式的解决方案就是:
- 把所有的“灵魂”(内在状态)提取出来,放在一个叫“享元工厂”的“中央厨房”里,每种灵魂只保留一份。
- 当需要展示一个对象时(例如在位置(5,10)画一个‘A’),就向工厂请求‘A’的灵魂。
- 工厂把‘A’的灵魂(共享对象)给你,你再把它和(5,10)这个“躯壳”(外在状态)结合起来,完成绘制。
这样一来,内存中只需要存储几十上百种“灵魂”(对应所有字母、数字、符号的种类),而不是百万个完整的“灵魂+躯壳”对象。内存节省了成百上千倍!
1.3 UML 类图:揭秘“中央厨房”的架构
让我们用UML图来直观地看看享元模式这个“中央厨房”是如何搭建和运作的。
classDiagramdirection TBclass Flyweight {<<interface>>+operation(extrinsicState)}class ConcreteFlyweight {-intrinsicState+getIntrinsicState()+operation(extrinsicState)}class UnsharedConcreteFlyweight {-allState+operation(extrinsicState)}class FlyweightFactory {-flyweightsPool: Map+getFlyweight(key) Flyweight-createFlyweight(key)}class Client {-extrinsicState+doOperation()}Flyweight <|.. ConcreteFlyweight : implementsFlyweight <|.. UnsharedConcreteFlyweight : implementsClient --> FlyweightFactory : getsClient --> Flyweight : usesFlyweightFactory o--> Flyweight : manages pool ofConcreteFlyweight --> FlyweightFactory : created bynote for Flyweight "定义享元对象的操作接口。\n通常要求传入外在状态。"note for ConcreteFlyweight "可共享的具体享元。\n存储内在状态,并实现操作逻辑。"note for UnsharedConcreteFlyweight "不需要共享的享元子类。\n客户端可直接实例化。"note for FlyweightFactory "享元工厂。维护一个享元池(缓存)。\n根据客户端请求返回享元对象。"note for Client "维持外在状态。\n在操作时,将外在状态传递给享元对象。"
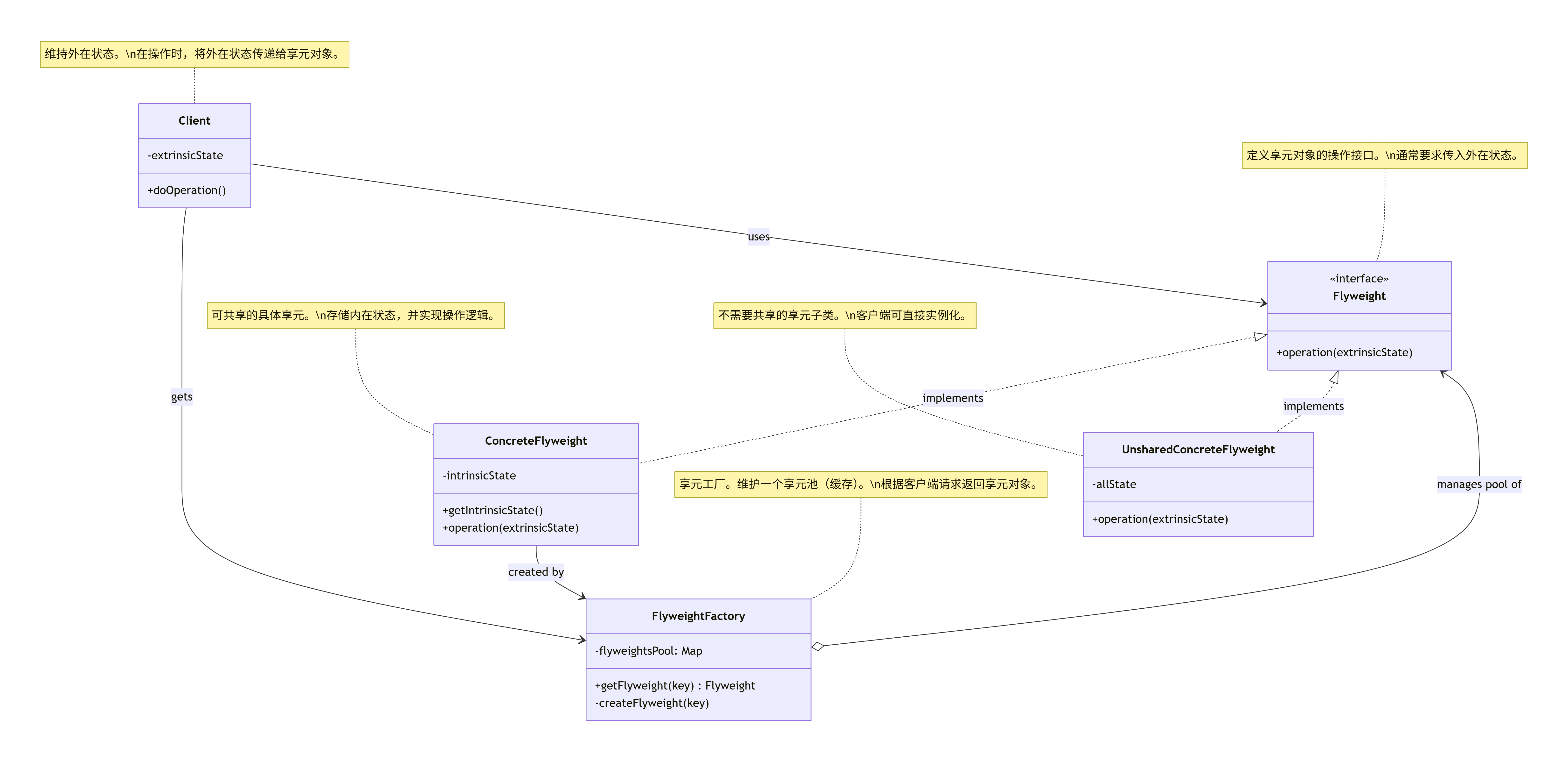
角色深度扮演:
-
Flyweight (享元接口) - 《操作手册》
- 它是所有“灵魂”必须遵守的协议。它规定了一个方法
operation(extrinsicState),意思是:“不管你是什么灵魂,必须能按照这份《操作手册》,结合给你的外在状态(躯壳信息)进行工作(比如绘制自己)。”
- 它是所有“灵魂”必须遵守的协议。它规定了一个方法
-
ConcreteFlyweight (具体享元) - “标准套餐”
- 这就是一种具体的“灵魂”,比如‘A’的灵魂。它把《操作手册》具体化:“我是‘A’,我的内在状态是Arial 12pt。当有人告诉我位置(x,y)时,我就在屏幕的(x,y)处画出Arial 12pt的‘A’字。”
- 它是可共享的明星员工,一份实例,服务万千。
-
UnsharedConcreteFlyweight (非共享具体享元) - “VIP定制餐”
- 有时候,总有些对象是特立独行的,它不需要共享,或者其状态全部都是外在的。这个类就是为它们准备的。它同样遵守《操作手册》,但不会被工厂缓存。
- 它是独立的临时工,用完即弃。
-
FlyweightFactory (享元工厂) - “中央厨房 & 餐厅经理”
- 这是模式的大脑和心脏。它管理着一个“食谱库”(
flyweightsPool: Map)。 - 它的工作流程是:
- 客户点餐:“经理,我来一份‘A’(Arial 12pt)。”
- 经理查单:看看食谱库里有没有‘A’(Arial 12pt)这道菜。
- 情况一:有 → 直接把它从厨房里端出来给客户。
- 情况二:没有 → 马上叫厨师
createFlyweight(key)做一份新的‘A’(Arial 12pt),存入食谱库,然后端给客户。
- 它确保了每种“灵魂”的独一无二性,是共享机制的核心。
- 这是模式的大脑和心脏。它管理着一个“食谱库”(
-
Client (客户端) - “服务员”
- 客户端是真正使用服务的人。它知道每个客人(需要显示的对象)坐在哪个座位(外在状态)。
- 它的工作是:从“餐厅经理”(工厂)那里拿到正确的“套餐”(享元对象),然后送到正确的“座位”(将外在状态传给享元对象的操作方法)。
- 它是连接共享对象和外部世界的桥梁。
这个过程完美演绎了“共享”的艺术,将不变与变、共享与独享优雅地解耦。
2. 设计意图与考量:权衡的艺术
2.1 核心目标:拯救内存的“环保大使”
享元模式的核心意图非常纯粹和高尚:运用共享技术有效地支持大量细粒度的对象。它是一个不折不扣的“内存环保大使”,它的KPI就是:
- 极大减少内存中对象实例的数量。
- 显著降低程序的内存占用 footprint。
- 对于创建成本高的对象(如线程、连接),节省大量初始化时间。
它的成就就像是把一场需要8万个独立厨房的晚会,变成了一个中央厨房供应8万份餐食,其效率和资源节省是革命性的。
2.2 设计哲学:时空转换与职责分离
享元模式背后蕴含着深刻的软件设计哲学:
-
以时间换空间 (Time-Space Tradeoff):
- 这是计算机科学中最经典的权衡。享元模式增加了微小的运行时开销(需要工厂查找、需要传递参数),换来了巨大的内存空间节省。
- 在绝大多数情况下,内存都是比CPU时间更稀缺的资源,尤其是在过去。因此这笔交易非常划算。这就好比,你多花几秒钟走到中央厨房取餐(时间),相比给每个人建一个厨房(空间),代价几乎可以忽略不计。
-
单一职责原则 (Single Responsibility Principle) 的完美体现:
- 享元对象:只负责处理内在状态以及如何根据外在状态执行操作。它的职责是“我是谁”和“我能做什么”。
- 客户端:负责维护和管理所有的外在状态。它的职责是“它在哪”和“现在怎么样”。
- 工厂:负责创建、管理和缓存享元对象。它的职责是“保证灵魂的唯一性”。
- 这种清晰的职责划分使得系统更容易理解、维护和扩展。
-
接口隔离与契约精神:
- 享元接口强制所有享元对象都必须通过接收外在状态参数来工作。这建立了一种强大的契约,保证了系统行为的一致性,无论背后是哪种具体的享元。
2.3 现实的代价:没有免费的午餐
引入享元模式并非毫无代价,实现时需要仔细考量:
-
运行时开销:最重要的权衡。每次操作都需要一次(可能很快的)Map查找和一次函数调用传参。对于性能极度敏感的场景,需要评估这点损耗是否可接受。但在大多数情况下,这远优于内存耗尽。
-
线程安全挑战:
- “中央厨房”(享元工厂)是整个多线程应用程序的共享资源。如果两个线程同时请求一个还不存在的享元,工厂可能会创建两份,这就违背了共享的初衷。
- 解决方案:必须给工厂的
getFlyweight()方法加上锁(Mutex),确保创建过程的原子性。在C++中,可以使用std::mutex和std::lock_guard来实现。
// 线程安全的享元工厂获取方法 ConcreteFlyweight* FlyweightFactory::getFlyweight(const Key& key) {std::lock_guard<std::mutex> lock(m_mutex); // 加锁,函数结束时自动释放if (m_flyweights.find(key) == m_flyweights.end()) {m_flyweights[key] = new ConcreteFlyweight(key);}return m_flyweights[key]; } -
设计的复杂性:
- 识别状态:正确地区分内在状态和外在状态是应用此模式最大的难点。如果划分错误,会导致共享失败或逻辑错误。这需要开发人员对问题域有深刻的理解。
- 管理外在状态:客户端现在需要负责维护、计算和传递所有外在状态。如果外在状态很复杂,这个负担可能会很重,有时甚至需要引入新的管理器类来帮忙。
3. 实例与应用场景:享元模式的“名人堂”
享元模式不是纸上谈兵的理论,它在现实世界的软件中有着辉煌的应用。让我们走进它的“名人堂”。
3.1 案例一:文本编辑器 - “不朽的经典”
- 场景:任何需要处理大量字符的软件,如Word、VS Code、浏览器。
- 内在状态 (灵魂):
字符编码(unicode)、字体、字号、字重(粗体、斜体)。同一种样式字符共享一个灵魂。 - 外在状态 (躯壳):
位置(x, y坐标)、前景色、背景色(如果颜色是实时计算而非样式一部分)、是否被选中。 - 工作流程:
- 编辑器有一个
GlyphFactory(字形工厂)。 - 加载文档时,解析出文本和样式。样式信息(字体、大小等)用于构建享元的Key。
- 对于每个字符,用它的样式Key向工厂请求一个
Glyph(字形)享元对象。 - 编辑器维护一个列表,记录每个位置(外在状态)对应哪个
Glyph享元。 - 渲染时,遍历每个位置,调用
glyph->draw(x, y, color)方法,将位置和颜色作为外在状态传入。
- 编辑器有一个
没有享元模式,一篇百万字的文档可能需要几百MB内存来存储字符对象。
使用享元模式,内存用量可能骤降到几MB,因为只存储了百来个不同的Glyph对象。
3.2 案例二:大型游戏 - “3A级的应用”
- 场景:《荒野大镖客2》中一望无际的草原、森林,充满了成千上万棵树木、石块和草丛。
- 内在状态 (灵魂):
网格模型(顶点数据)、纹理(树皮、树叶贴图)、材质、着色器。同一种3D模型共享一个灵魂。这些数据是GPU资源,非常庞大。 - 外在状态 (躯壳):
世界变换矩阵(包含位置、旋转、缩放)、动画状态、LOD等级(Level of Detail,离得远的树用低模渲染)。 - 工作流程:
- 游戏资源管理器就是一个巨大的
ModelFactory。 - 世界编辑器在摆放物体时,实际上只是在记录“这里有一个PineTree01模型,位置是(X,Y,Z)”。
- 游戏运行时,对于每一棵要渲染的树,GPU指令大致是:
// 设置这颗树的“灵魂”(共享的模型、纹理资源) Renderer::SetModel(pineTreeModel); Renderer::SetTexture(pineTreeTexture); // 传入这颗树独有的“躯壳”信息(世界矩阵) Renderer::SetWorldMatrix(treeInstanceWorldMatrix); // 绘制! Renderer::DrawMesh(); - 通过这种方式,GPU可以一次性批量渲染大量相同模型的物体,效率极高。
- 游戏资源管理器就是一个巨大的
享元模式是现代游戏能够呈现庞大、复杂世界的核心技术之一。
3.3 案例三:UI控件库 - “身边的例子”
- 场景:一个包含大量相同按钮、图标、标签的软件界面。
- 内在状态 (灵魂):
控件类型(按钮)、默认图标、尺寸、样式表(CSS)。 - 外在状态 (躯壳):
位置、当前显示的文本、是否可用、是否鼠标悬停。 - 工作流程:工具栏上有20个使用相同图标的按钮。它们共享一个
Icon享元对象。每个按钮独自管理自己的位置、点击状态等外在状态,并在绘制时告诉Icon:“请在这个位置,以高亮(或灰显)的状态绘制你自己”。
3.4 案例四:池化技术 - “享元的超级变种”
线程池、数据库连接池是享元模式思想最典型、最成功的延伸应用。
- 场景:一个Web服务器需要处理大量并发请求,每个请求都需要使用数据库连接。
- “内在状态”:连接的建立方式/配置(数据库URL、用户名、密码)。所有连接的这个信息都是一样的,这就是它们的“灵魂”。
- “外在状态”:连接的当前状态(空闲/繁忙)、被哪个线程持有、最后一次使用时间。这些是“躯壳”信息,随着连接被借出和归还而不断变化。
- 工作流程:
- 初始化:连接池(
ConnectionPool,即享元工厂)根据配置(内在状态)创建N个连接对象(享元),并把它们标记为“空闲”(初始外在状态)。 - 获取连接:应用程序
getConnection(),池子找一个“空闲”的连接,将其状态改为“繁忙”,然后返回。这相当于工厂返回一个享元对象,并改变了它的外在状态。 - 使用连接:应用程序使用连接执行SQL。
- 归还连接:应用程序调用
close()(实际是releaseConnection()),池子将连接状态改回“空闲”,放回池中。这相当于客户端“使用”完享元对象,并重置了它的外在状态。
- 初始化:连接池(
池化技术巧妙地将享元模式中“外在状态由客户端管理”变成了“外在状态由池自己集中管理”,但其共享内在资源、减少创建销毁开销的核心思想与享元模式一脉相承。它是享元模式在资源管理领域的巅峰实践。
4. 数据库连接池的C++实现:从理论到实战
现在,让我们把享元模式的思想,注入到一个实用的C++数据库连接池中。我们将一步步构建它,并理解每一行代码背后的设计哲学。
4.1 代码实现:构建一个工业级的“连接池享元工厂”
我们的连接池将具备以下特性:
- 单例模式:确保全局只有一个连接池实例。
- 享元模式:共享连接对象(内在状态:配置信息)。
- RAII:自动管理连接的获取和释放,避免泄漏。
- 线程安全:使用互斥锁和信号量处理多线程并发。
首先,是头文件 connection_pool.h:
#ifndef CONNECTION_POOL_H
#define CONNECTION_POOL_H#include <stdio.h>
#include <list>
#include <mysql/mysql.h>
#include <error.h>
#include <string.h>
#include <iostream>
#include <string>
#include "../lock/locker.h" // 假设我们已经封装好了互斥锁和信号量/*** @class connection_pool* @brief 数据库连接池类,享元工厂模式的典范应用。* * 它将数据库连接视为享元对象,其内在状态是连接配置(URL、用户名等)。* 它负责创建、管理和共享这些连接,而连接的外在状态(是否繁忙、被谁持有)则由池自身管理。* 采用单例模式确保全局唯一,通过信号量和互斥锁保证线程安全。*/
class connection_pool {
public:// 获取单例对象的静态方法static connection_pool* GetInstance();/*** @brief 初始化连接池,建立所有共享连接。* * 这是构建“享元对象池”的过程。根据提供的配置信息(内在状态),* 创建指定数量的物理数据库连接,并将它们置于空闲状态。* * @param url 数据库主机地址,如"127.0.0.1"* @param User 数据库用户名* @param PassWord 数据库密码* @param DBName 要连接的数据库名* @param Port 数据库端口,默认3306* @param MaxConn 最大连接数,即池的大小* @param close_log 日志开关 (0:开, 1:关)* @return true 初始化成功* @return false 初始化失败*/bool init(std::string url, std::string User, std::string PassWord, std::string DBName, int Port, int MaxConn, int close_log);/*** @brief 从池中请求一个可用连接。* * 此方法体现了享元模式的“获取享元”过程。如果池中有空闲连接(享元),* 则直接返回;如果没有,则阻塞等待直到有连接被归还。* 线程安全由信号量和互斥锁保证。* * @return MYSQL* 指向MySQL连接的指针。等待失败可能返回NULL。*/MYSQL* GetConnection();/*** @brief 将一个使用完毕的连接归还给池。* * 将连接的状态重置为空闲,并放回池中,供其他线程使用。* 同时释放一个信号量,通知等待的线程有新的资源可用。* * @param conn 要归还的MySQL连接指针* @return true 归还成功* @return false 归还失败(如连接指针无效)*/bool ReleaseConnection(MYSQL* conn);// 获取当前空闲连接数int GetFreeConn();// 销毁连接池,关闭所有连接void DestroyPool();private:connection_pool(); // 构造函数私有化,实现单例~connection_pool(); // 析构函数int m_MaxConn; // 最大连接数int m_CurConn; // 当前已使用的连接数int m_FreeConn; // 当前空闲的连接数locker lock; // 互斥锁,保护连接列表m_connList的并发访问sem reserve; // 信号量,计数可用连接资源std::list<MYSQL*> m_connList; // 连接池,存储所有共享的连接对象(享元)// 数据库连接配置(享元的内在状态)std::string m_url;std::string m_Port;std::string m_User;std::string m_PassWord;std::string m_DatabaseName;int m_close_log;
};/*** @class connectionRAII* @brief 连接资源的RAII包装类。* * 利用C++ RAII特性,在构造函数中自动获取连接,在析构函数中自动归还连接。* 这确保了即使在发生异常的情况下,连接也能被安全释放,避免了资源泄漏。* 它是客户端使用连接池的最佳实践方式。*/
class connectionRAII {
public:/*** @brief 构造函数,自动获取一个连接。* * @param con 输出参数,用于接收获取到的连接指针的地址。* @param connPool 连接池实例的指针。*/connectionRAII(MYSQL** con, connection_pool* connPool);/*** @brief 析构函数,自动归还连接。*/~connectionRAII();private:MYSQL* conRAII; // 它持有的连接connection_pool* poolRAII; // 它使用的连接池
};#endif
接下来,是源文件 connection_pool.cpp:
#include "connection_pool.h"// 1. 单例实现 (C++11 Meyers' Singleton, 线程安全)
connection_pool* connection_pool::GetInstance() {static connection_pool connPool; // 局部静态变量,首次调用时初始化return &connPool;
}// 2. 构造函数初始化列表
connection_pool::connection_pool() : m_MaxConn(0), m_CurConn(0), m_FreeConn(0) {}// 3. 初始化连接池 - 构建享元对象池
bool connection_pool::init(std::string url, std::string User, std::string PassWord, std::string DBName, int Port, int MaxConn, int close_log) {// 保存配置参数(内在状态)m_url = url;m_User = User;m_PassWord = PassWord;m_DatabaseName = DBName;m_Port = Port;m_close_log = close_log;m_MaxConn = MaxConn; // 设置池容量// 创建MaxConn个数据库连接(享元对象)for (int i = 0; i < MaxConn; i++) {MYSQL* con = NULL;con = mysql_init(con); // 初始化MYSQL句柄if (con == NULL) {LOG_ERROR("MySQL Initialization Error"); // 记录日志exit(1); // 初始化失败,程序退出}// 建立实际的物理连接(使用内在状态参数)con = mysql_real_connect(con, url.c_str(), User.c_str(), PassWord.c_str(), DBName.c_str(), Port, NULL, 0);if (con == NULL) {LOG_ERROR("MySQL Connection Error: %s", mysql_error(con));exit(1);}// 将创建好的连接加入连接池链表(享元池)m_connList.push_back(con);++m_FreeConn; // 空闲连接数增加}// 初始化信号量,初始值设为当前空闲连接数(即可用资源数)reserve = sem(m_FreeConn); // 最大连接数就是初始创建的数量m_MaxConn = m_FreeConn; return true;
}// 4. 获取连接 - 享元工厂的getFlyweight方法
MYSQL* connection_pool::GetConnection() {MYSQL* con = NULL;if (m_connList.size() == 0) {return NULL; // 池为空,返回NULL(通常不会发生)}reserve.wait(); // P操作,等待信号量(申请资源)。如果没有空闲连接,线程将在此阻塞。lock.lock(); // 加锁,保护对共享链表m_connList的访问con = m_connList.front(); // 从链表头部取出一个连接(享元对象)m_connList.pop_front(); // 从池中移除--m_FreeConn; // 空闲连接数减1++m_CurConn; // 已使用连接数加1lock.unlock(); // 解锁return con; // 返回获取到的连接
}// 5. 归还连接 - 重置享元的外在状态并放回池中
bool connection_pool::ReleaseConnection(MYSQL* con) {if (con == NULL) {return false;}lock.lock(); // 加锁// 将连接重新放回链表尾部(重置为空闲状态)m_connList.push_back(con);++m_FreeConn;--m_CurConn;lock.unlock(); reserve.post(); // V操作,释放信号量(释放一个资源),唤醒一个等待的线程。return true;
}// 6. 获取空闲连接数
int connection_pool::GetFreeConn() {return this->m_FreeConn;
}// 7. 销毁连接池
void connection_pool::DestroyPool() {lock.lock(); // 加锁if (m_connList.size() > 0) {// 遍历连接列表,关闭所有数据库连接(销毁所有享元对象)for (auto it = m_connList.begin(); it != m_connList.end(); ++it) {MYSQL* con = *it;mysql_close(con);}m_CurConn = 0;m_FreeConn = 0;m_connList.clear(); // 清空链表}lock.unlock();
}// 8. 析构函数
connection_pool::~connection_pool() {DestroyPool();
}// ----------- connectionRAII 类的实现 -----------
// RAII:Resource Acquisition Is Initialization
connectionRAII::connectionRAII(MYSQL** SQL, connection_pool* connPool) {*SQL = connPool->GetConnection(); // 在构造函数中获取资源(连接)conRAII = *SQL;poolRAII = connPool;
}connectionRAII::~connectionRAII() {poolRAII->ReleaseConnection(conRAII); // 在析构函数中释放资源(归还连接)
}
4.2 流程图与时序图:可视化连接池的一生
连接池初始化流程图
客户端获取与归还连接时序图
sequenceDiagramparticipant Client as 客户端线程participant RAII as connectionRAIIparticipant Pool as ConnectionPoolparticipant Sem as Semaphoreparticipant List as ConnListNote over Client: 需要执行数据库操作Client ->>+ RAII: new connectionRAII(&conn, pool)Note left of RAII: 构造函数执行RAII ->>+ Pool: GetConnection()Pool ->>+ Sem: wait() // P操作,申请资源Sem-->>Pool: 资源获取成功(或阻塞等待)Pool ->> Pool: lock() // 加锁Pool ->> List: pop_front() // 取出一个连接Pool -->> Pool: m_FreeConn--, m_CurConn++Pool ->> Pool: unlock() // 解锁Pool -->>- RAII: return conRAII -->> Client: conn is ready->>- RAII: 构造完成Note over Client: 使用连接conn执行SQL...Client ->> RAII: delete (析构)Note left of RAII: 析构函数执行RAII ->>+ Pool: ReleaseConnection(con)Pool ->> Pool: lock()Pool ->> List: push_back(con) // 归还连接Pool -->> Pool: m_FreeConn++, m_CurConn--Pool ->> Pool: unlock()Pool ->> Sem: post() // V操作,释放资源Pool -->>- RAII: returnNote over Client: 操作完成,连接已自动归还
4.3 Makefile 范例:项目的构建蓝图
一个清晰的项目结构和管理依赖的Makefile是专业C++项目的标配。
假设项目结构:
project_root/
├── bin/ # 最终可执行文件
├── build/ # 编译中间文件 (.o)
├── include/ # 头文件 (.h)
│ ├── connection_pool.h
│ └── locker.h
├── src/ # 源文件 (.cpp)
│ ├── connection_pool.cpp
│ ├── locker.cpp # 锁的实现
│ └── main.cpp # 测试程序
└── Makefile
Makefile 内容:
# Compiler and flags
CXX := g++
CXXFLAGS := -Wall -Wextra -g -std=c++11 -I./include
LDFLAGS := -L/usr/lib64/mysql -lmysqlclient -lpthread# Directories
SRC_DIR := src
BUILD_DIR := build
BIN_DIR := bin# Targets
TARGET := $(BIN_DIR)/test_conn_pool
SRCS := $(wildcard $(SRC_DIR)/*.cpp)
OBJS := $(SRCS:$(SRC_DIR)/%.cpp=$(BUILD_DIR)/%.o)# Default target
all: $(TARGET)# Link the target executable
$(TARGET): $(OBJS) | $(BIN_DIR)$(CXX) $(OBJS) -o $@ $(LDFLAGS)# Compile source files to object files
$(BUILD_DIR)/%.o: $(SRC_DIR)/%.cpp | $(BUILD_DIR)$(CXX) $(CXXFLAGS) -c $< -o $@# Create directories if they don't exist
$(BIN_DIR):mkdir -p $@
$(BUILD_DIR):mkdir -p $@# Clean up build artifacts
clean:rm -rf $(BUILD_DIR) $(BIN_DIR)# Phony targets
.PHONY: all clean
编译与运行:
- 安装依赖:确保系统已安装 MySQL C Connector 开发库。
- Ubuntu/Debian:
sudo apt-get install libmysqlclient-dev - CentOS/RHEL:
sudo yum install mysql-devel
- Ubuntu/Debian:
- 编译:在终端中,进入项目根目录,执行
make命令。 - 运行:编译成功后,执行
./bin/test_conn_pool。你需要确保 MySQL 服务器正在运行,并在你的main.cpp测试程序中设置正确的数据库连接参数。
结果解读:
一个良好的测试程序会创建多个线程,每个线程通过connectionRAII获取连接,执行简单查询(如SELECT 1;),然后析构connectionRAII自动归还。你应当观察到:
- 程序正常运行,所有查询成功。
- 连接数稳定,不会超过池的
MaxConn大小。 - 没有连接泄漏(可以用
SHOW PROCESSLIST;在MySQL中监控)。 - 多线程并发下行为正确,没有崩溃或死锁。
5. 总结与升华
享元模式是一种深刻体现了“共享”和“分离”哲学的设计模式。它通过将对象的内在状态(不变的灵魂)和外在状态(变化的躯壳)分离,并通过一个享元工厂来管理和共享内在状态,从而有效地解决了大量细粒度对象带来的性能问题。
它教会我们一个重要的设计原则:识别并抽离系统中的不变部分和可变部分,并将不变部分共享化。这种思想不仅适用于对象设计,也适用于系统架构的各个层面。
数据库连接池是享元模式的一个高级应用和成功实践。它将昂贵的数据库连接对象化身为“享元”,通过池化技术集中管理,辅以单例模式、RAII、信号量和互斥锁,构建了一个高效、稳定、安全且易于使用的资源管理中间件。