【Linux】网络——HTTP协议,HTTPS加密
📝前言:
这篇文章我们来讲讲计算机网络中的HTTP协议,参考文章:【计算机网络】HTTP 协议详解 和【Linux篇章】穿越网络迷雾:揭开 HTTP 应用层协议的终极奥秘!【这篇特别好】
🎬个人简介:努力学习ing
📋个人专栏:Linux
🎀CSDN主页 愚润求学
🌄其他专栏:C++学习笔记,C语言入门基础,python入门基础,C++刷题专栏
目录
- 一,超链接基本认识
- 二,HTTP
- 1. 基本认识
- 2. HTTP工作过程
- 3. HTTP协议格式总览
- Request
- Response
- 4. 常见请求方法
- 5. 状态码
- 重定向
- 6.报头
- 7. 长短连接
- 8. cookie和session
- 三,练习代码
- 四,HTTPS加密
一,超链接基本认识

以上面的超链接(也叫URL)为例:
https:代表协议,协议确定了,服务端在实现时会固定默认端口号(如:https : 443,http : 80)://:特殊分隔符blog.csdn.net:域名,域名会通过域名服务器得到对应的IP以后返回给浏览器(所以域名其实就是服务端的IP),也可以后面跟端口号- 我们在浏览器中输入
localhost:port以后,浏览器会自动解析,并给建立好TCP连接,然后把HTTP 请求报文通过TCP连接发送给我们的服务器
- 我们在浏览器中输入
/tan_run/article/...:资源路径- 这里的
/是web根目录并非服务器对应的Linux系统的根目录 - 对于静态资源而言:这一串路径的
/可能就是服务器中的某一个用来存放资源的目录,/tan_run/article/...就是从这个目录开始的指定文件的路径。(即:这个资源为Linux服务器中的一个特殊文件) - 静态资源是指:内容在服务器上固定不变,每次请求返回结果都相同的文件,无需服务器动态计算生成(如:文本,图片,视频…)
- 这里的

如果观察到wd=hello%40%3A...world这种“乱码”,其实是因为我们使用了@://这种特殊字符,这些特殊字符有特殊用途,直接在url中出现,会解析失败,所以浏览器会把我们这些字符进行urlencode
二,HTTP
如果想要学习前端网页的编写,可以查看 :w3schools,下文主要探讨计算机网络相关的知识
1. 基本认识
- HTTP(Hyper Text Transfer Protocol): 全称超文本传输协议,是用于从万维网服务器传输超文本到本地浏览器客户端的传送协议。
- 超文本就是:除传文本外,还可以传图片,音频,视频…
- HTTP 是一种应用层协议,是基于 TCP/IP 通信协议来传递数据的,其中 HTTP1.0、HTTP1.1、HTTP2.0 均为 TCP 实现,HTTP3.0 基于 UDP 实现。现主流使用 HTTP1.0 和 HTTP3.0
- 协议: 为了使数据在网络上从源头到达目的,网络通信的参与方必须遵循相同的规则,这套规则称为协议,它最终体现为在网络上传输的数据包的格式。
(参考文章:【计算机网络】HTTP 协议详解)
2. HTTP工作过程
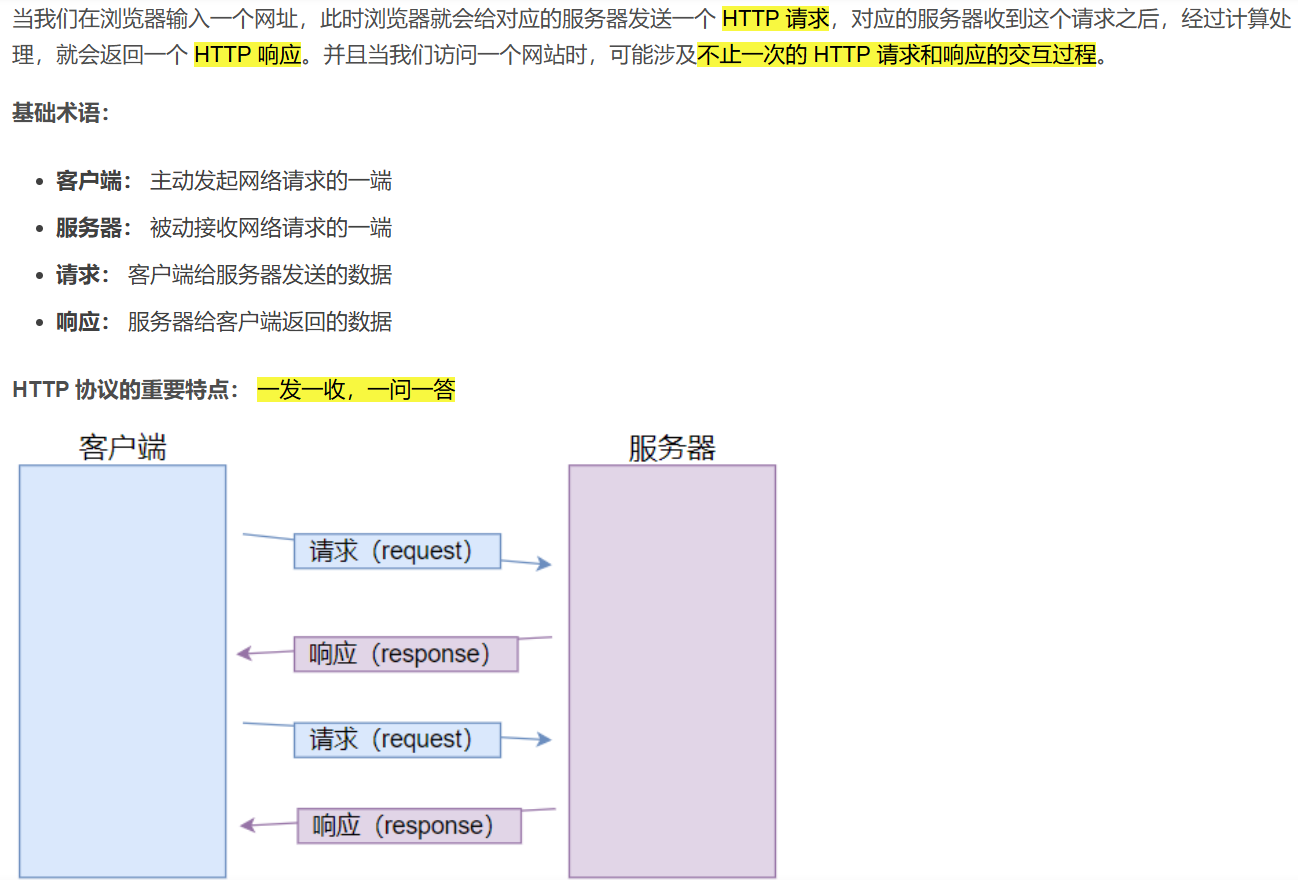
(图片来源:【计算机网络】HTTP 协议详解)
3. HTTP协议格式总览
Request
- 在文章【计算机网络】HTTP 协议详解中有抓取格式的方法,在这里直接介绍格式了。
- 在看了【计算机网络】HTTP 协议详解这篇文章以后,感觉已经讲的很好了,站在巨人的肩膀上学习吧,补充两张图便于理解
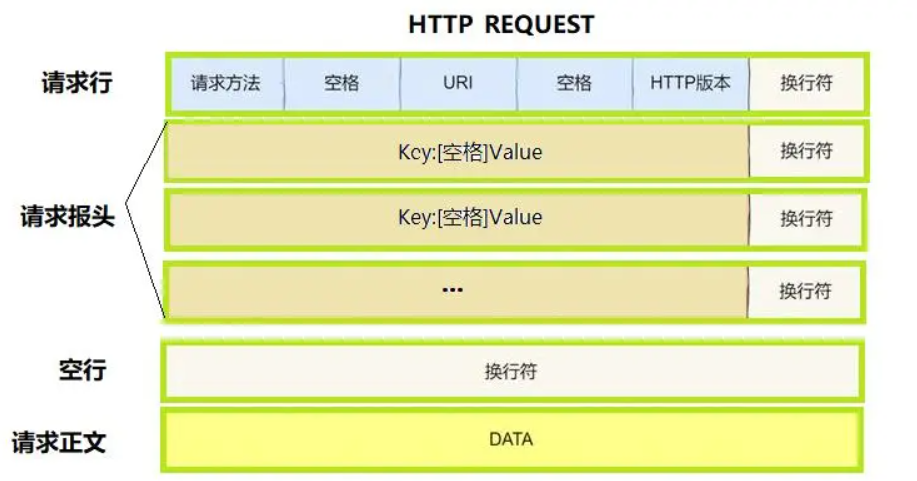
- 为什么这里需要
HTTP版本,假如:微信版本更新了,但是你还没进行最新版本的更新,理论上就应该用不了一些新功能功能。所以,HTTP 协议首行携带 HTTP 版本信息,是为了确保客户端和服务器之间能够正确、高效、安全地进行通信,避免因版本不兼容导致的各种问题 - 这里请求行的请求目标描述为
URI,URL属于URI,是一种完整的路径- 请求目标还有可能是其他格式的
URI,主要目的是:要告诉服务器要访问哪里 URI:中?前是目标资源路径,?...后面是搜索字符串(用于参数传递)
- 请求目标还有可能是其他格式的
- 换行符:
\r\n,如果不规范的话,可能收到\n
Response

- 请求正文:是浏览器要传给服务器的请求数据
- 响应正文:是服务器处理完请求以后,给浏览器返回的结果
4. 常见请求方法
对文章【计算机网络】HTTP 协议详解中的内容做补充
网页跳转:
- 我们在主页里面如果用
a标签实现了网页的跳转,则我们点击新链接的时候,浏览器会形成新的访问网址,发起第二次请求。
补充:
-
GET方法,也可以上传资源(比如我们登录时输入的账号和密码),这时候,账号和密码就作为参数资源被上传到服务器
- 通常:域名后 ? 前跟的是服务名称,如百度的
/s,?后面就是上传的参数

- 通常:域名后 ? 前跟的是服务名称,如百度的
-
GET提交参数以URI的方式提交,POST提交参数,以正文方式提交(但是两种都不安全,需要以HTTPS协议加密最好)
-
POST 方法:客户端把数据(参数)放到正文中,然后把 HTTP Request发送给服务器,服务器通过读取首行,识别请求方法,发现是POST于是获取参数,对参数进行分析处理以后,得到结果,然后组织成HTTP Response 发送会客户端(浏览器)
5. 状态码
对文章【计算机网络】HTTP 协议详解中的内容做补充
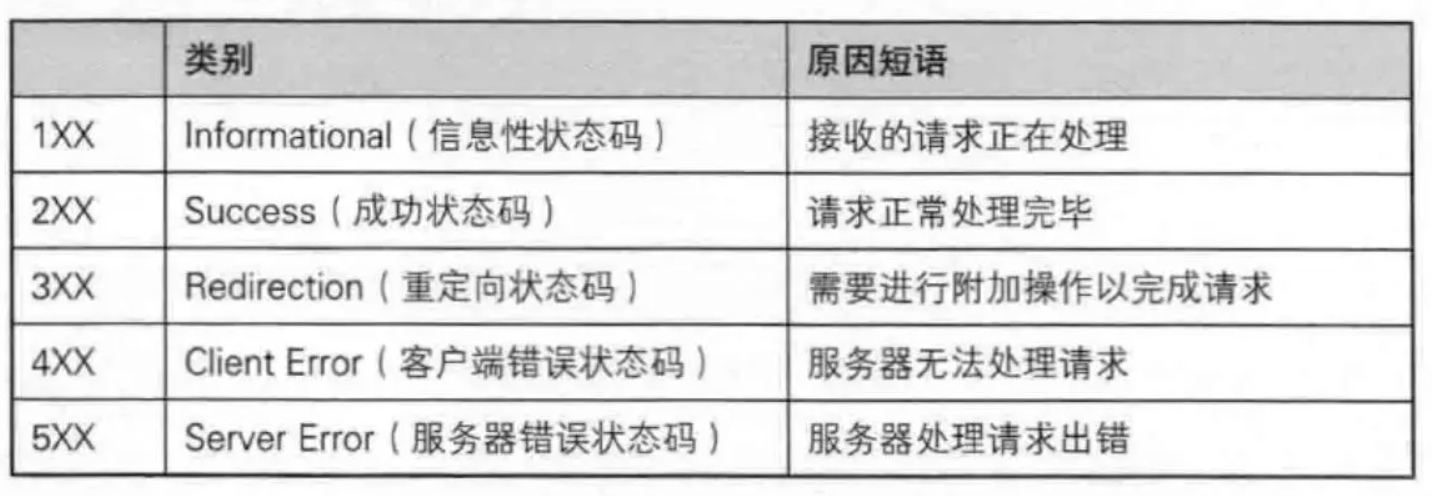
100:上传大文件时,服务器告诉客户端可以继续上传

重定向
补充:浏览器向服务器请求后,收到服务器的Response 后,发现Response报头Location中有新的HTTP地址,于是发起二次请求,于是完成了重定向
6.报头
点击可查 → HTTP content-type 对照表
- 服务器在返回Http Response给浏览器的时候,需要往报头Header里面加上Content-Type(指明资源类型,按照对照表返回) 和 Content-Length(正文长度,这个看情况加)
- 当一个网页内有多种资源的时候,浏览器先会向网页本身发起第一次请求(核心请求),然后发现还有图片资源、视频资源。则会向其他资源在发起请求(这种情况又分长短连接)
7. 长短连接
这里的长短连接针对的是底层的TCP是否重新建立连接。HTTP本身无连接,HTTP只关注Request和Response(在确保报文完整性的情况下,while(ture)的处理Request),是应用层的。
- 短连接:每次应答完都关闭连接,然后重新建立连接接受Request → 服务器压力大。比如网页中有一份网页 + 3张图片,则总共要建立4次连接。
- 长连接:建立一次连接,然后不关闭,后续的Request和Response都通过这个连接,则一份网页+3张图片,只需要建立两次连接:第一次:获取HTML网页,第二次:发现网页中有其他资源,然后其他资源通过第二次连接进行通信
报头Connection:
Connection: keep-alive:表示希望保持连接以复用 TCP 连接。(长连接)Connection: close:表示请求/响应完成后,应该关闭 TCP 连接。(短连接)
在HTTP/1.1中默认使用长连接,HTTP/1.0中默认使用短连接。如果两端不同的话,则以较低版本的HTTP为准。
8. cookie和session
cookie:应对HTTP无状态这一特点(但浏览器是有缓存的)
原理流程:
- 首次登录成功后,服务器会在 Response 里面生成一个
Set-Cookie的报头(值包含用户标识、过期时间等信息),返回给浏览器。 - 浏览器会记录这个Cookie, 把它保存在浏览器的文件里面。
- 后续用户在访问服务器的时候(发Request时),浏览器会在 Request 请求头中添加 Cookie 字段,然后发送给服务器。
- 服务器就会识别这个 Cookie,如果识别通过了,就可以继续访问
安全隐患:
- 中间人攻击:在中途截取
Set-Cookie,得到里面的内容,然后使自己也能访问 - 在浏览器文件中,拿到高相关的用户信息
session
- 首次登录成功后,服务端会创建一个Session(会话)来存储用户的信息(包括用户权限…),并且会用一些方法给这个会话生成一个Session ID(这是加密后的随机字符串)
- 然后通过
Set-Cookie(放在Response里)把这个Session ID发回给浏览器 - 后续请求,浏览器在 Cookie 字段中携带 Session ID(相比于
cookie“用户信息” 变成了 “Session ID”) - 如果服务端有Session ID与之匹配,通过Session内容即可判断用户权限…
安全隐患:
- 也有中间人攻击风险,但是总有其他安全手段可以加强安全,如HTTPS…
- 因为用户信息存在服务器端了,所以拿不到。
三,练习代码
点击 → GIthub链接
四,HTTPS加密
可以查看这篇文章:【Linux篇章】穿越数据迷雾:HTTPS构筑网络安全的量子级护盾,重塑数字信任帝国!
在这里我主要对整个过程做一个总结,整个过程涉及两个非对称密钥,一个对称密钥,服务器非对称(s, s'),CA机构的非对称(c, c'),客户端的对称x:
- 首先,服务器拿着自己的公钥
s和域名等东西,到CA机构申请证书 - CA机构会用自己的私钥
c'对数据进行签名(这个签名只有c才可以解),然后把形成的证书发给服务器 - 服务器在和客户端建立第一次密钥协商的时候,会把证书发给客户端
- 对于客户端:每个浏览器都会内置CA机构的公钥,客户端拿到证书以后,通过公钥解密,就可以得到服务器的公钥
s - 然后,客户端再用
s加密自己的对称密钥x,后发回给客户端 - 服务器再用
s'进行解密,得到x - 后续两者就用
x进行加密了
这种方法有效的避免了中间人攻击,并且速度还快
🌈我的分享也就到此结束啦🌈
要是我的分享也能对你的学习起到帮助,那简直是太酷啦!
若有不足,还请大家多多指正,我们一起学习交流!
📢公主,王子:点赞👍→收藏⭐→关注🔍
感谢大家的观看和支持!祝大家都能得偿所愿,天天开心!!!