SimpleVLA-RL:通过 RL 实现 VLA 训练的 Scaling
SimpleVLA-RL:通过 RL 实现 VLA 训练的 Scaling

- 论文题目:SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
- arXiv:2509.09674
- 单位:清华 & 上海 AI Lab & 上交大
- https://github.com/PRIME-RL/SimpleVLA-RL

TL;DR:SimpleVLA-RL 就是 DAPO 在 VLA 中的应用
论文速读
- 研究问题:通过 SFT 训练 VLA 模型取得了显著进展,但 SFT 存在数据稀缺及泛化性差的问题。最近推理型 LLM 的发展表明了 RL 可以显著提升逐步推理能力,这自然引发了一个问题:RL 能否同样提升 VLA 的长时逐步动作规划能力?
- 研究方法:本文提出了 SimpleVLA-RL,一个专为 VLA 模型设计的高效 RL 框架。基于 VeRL 训练框架,作者引入了 VLA 的 trajectory 采样、多环境渲染以及优化的 loss 计算等改进。当应用于 OpenVLA-OFT 模型时,SimpleVLA-RL 在 LIBERO 评测上实现了 SOTA 性能。
SimpleVLA-RL 不仅减少了对大规模数据的依赖并实现了鲁棒的泛化,还在实际任务中显著超越了 SFT。此外,该工作在 RL 过程中还发现了一个新现象“pushcut”,即 policy model 发现了之前在训练过程中未见到过的模式。
Background
以往 VLA 的训练通常采用两个阶段训练策略:首先在大规模多模态数据上做预训练(包括人类操作视频、图文对以及异构机器人数据集),然后在大量高质量机器人轨迹上进行 SFT,以提升特定任务的能力。
然而该范式存在两个关键挑战:
- 数据稀缺性:扩展 SFT 需要大量由人工操作的机器人轨迹数据,而这些数据目前仍然稀缺且成本高昂,严重制约了可扩展性。
- 泛化能力差:泛化仍是 VLA 的关键瓶颈,尤其是在涉及分布偏移的组合性、长时程或真实世界任务中。因为当前 VLA 的 SFT 通常依赖于有限的、场景和任务特定的数据。因此,当 VLA 模型遇到未见过的任务、环境或物体时,其性能不可避免地下降。
在 DeepSeek-R1 成功经验的驱动下,自然引出一个问题:RL 是否也能增强 VLA 模型逐步生成准确动作的能力?
SimpleVLA-RL 框架
作者对 VeRL 训练框架进行了扩展,引入了并行多环境渲染来加快 rollout 速读,并将其整合为一个一体化的训练-推理-渲染框架,实现了稳定的、样本高效的训练。
VLA 的 RL 形式化表述
状态(sts_tst):状态包含多模态观测,包括视觉输入(RGB 图像、深度图或点云)、本体感知信息(关节角度、末端执行器位姿)以及任务的语言指令。
动作(ata_tat):动作是机器人动作空间中的控制命令,通常为末端执行器的增量或关节角度目标,其中 at∈Rda_t \in \mathbb{R}^dat∈Rd,比如 d = 7 代表 6-自由度位姿加夹爪位置。
环境:环境表示机器人运行的物理世界或仿真环境。它提供状态转移和 reward 信号。
Rollout:VLA 模型通过与环境的迭代交互生成轨迹 τ\tauτ。在每个时间步,policy 以当前状态 sts_tst 作为输入,输出长度为 k 的动作块 (at,at+1,⋯ ,at+k−1)(a_t, a_{t+1}, \cdots, a_{t+k-1})(at,at+1,⋯,at+k−1)。机器人按顺序执行这些动作,环境根据物理动力学产生更新后的状态。执行后,模型将新状态 st+ks_{t+k}st+k 作为输入,并生成下一个动作块。此过程持续到任务完成或者达到最大 turn 长度。
SimpleVLA-RL 概述
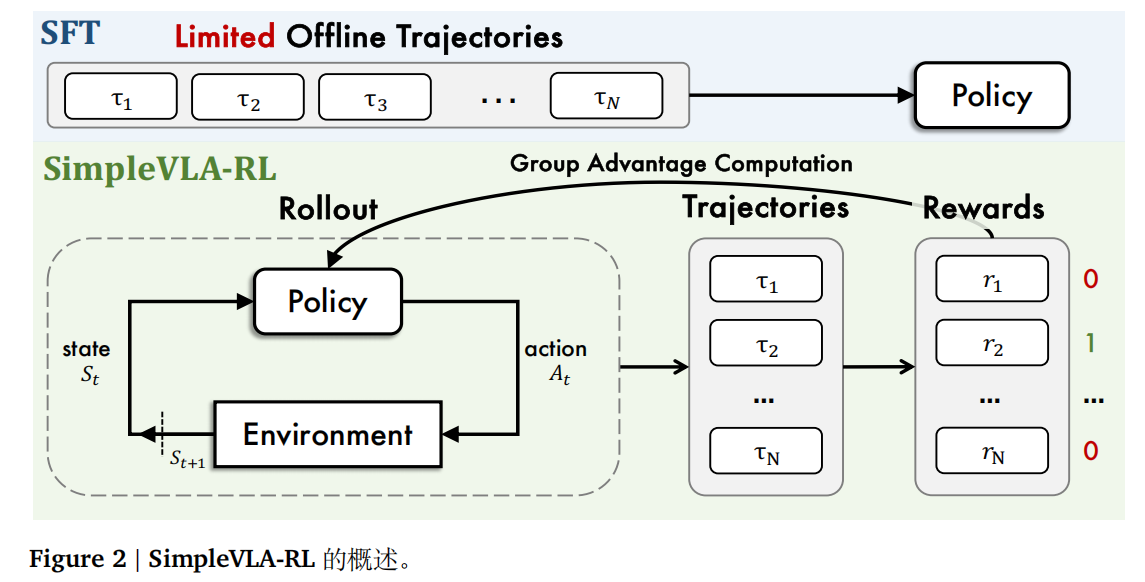
首先,通过对每个输入进行随机采样,生成多条轨迹。随后,根据环境反馈为每条轨迹分配一个简单的结果奖励(成功为 1,失败为 0)。利用这些奖励以及对应的动作 token 概率,我们计算 GRPO 损失以更新策略模型。
Rollout 采样
相比于 LLM,VLA 模型由于其动作解码策略而面临独特的挑战,当前的 VLA 通常采用三种策略:
- 生成类似于 LLM 的 action token 分布
- 在 latent state 上基于 Diffusion 的降噪
- 通过 MLP 进行确定性回归
在这些策略中,基于 token 的方法最兼容 PPO 类强化学习算法,因为它自然地提供了随机采样和策略梯度计算所需的动作分布。因此,我们采用此方法,即 VLA 模型输出动作 token的概率分布,并利用随机采样来生成多样化的轨迹。
还有一个与 LLM 不同的是,VLA 的 rollout 需要与环境持续交互,以动态更新视觉观测和机器人状态。
下图展示了 LLM 与 VLA 的 rollout 算法的伪代码对比:

结果奖励建模
SimpleVLA-RL 采用简单的二元奖励函数进行 RL 训练:仅根据任务是否完成,为轨迹分配 0 或 1 的轨迹级奖励。
增强 RL 训练中的“探索”能力
在 RL 中鼓励“探索”至关重要,而这一因子在 VLA 的 RL 中显得更加关键。操纵任务通常允许多种有效的解决方案,然而 VLA 模型往往收敛于一组狭窄的解题模式,这主要归因于其训练轨迹的同质性,从而限制了强化学习的效率。
基于这一洞察,作者实施了 3 项关键改进来增强 RL 中的探索能力:
- Rollout 时动态采样:剔除掉所有 trajectories 的 reward 均相同的训练样本。
- Clip Higher:DAPO 的优化之一,将 GRPO 训练目标中的裁剪范围从 [0.8, 1.2] 修改为 [0.8, 1.28]。
- 更高的 sampling temperature:相关研究表明,在较高温度下进行采样时表现出显著的改进。因此,该工作将采样温度从 1.0 提升到了 1.6。
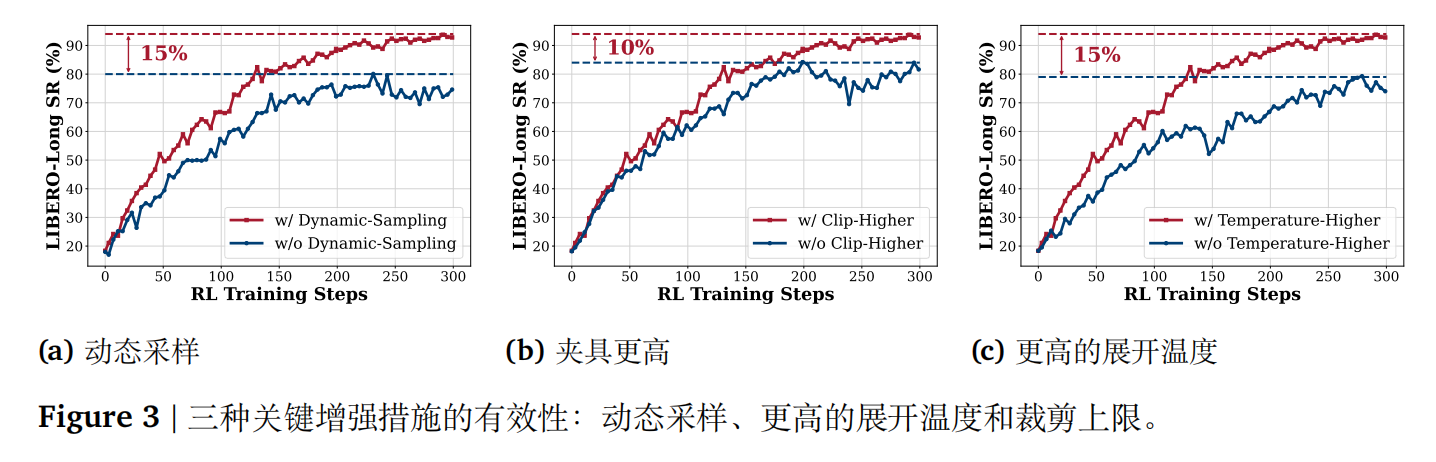
此外,为了消除训练过程中对 ref model 的需求,作者移除了 KL 散度的正则化,这降低了内存消耗并加速了训练过程。
实验
实验设置
benchmarks:LIBERO、RoboTwin1.0 和 RoboTwin2.0
骨干网络:OpenVLA-OFT,它采用视觉编码器和 LLaMA2-7B 作为 backbone,并结合动作分块和并行解码的设计,特别适合在线强化学习场景。我们使用 LLaMA2 输出
头生成动作 token,并采用交叉熵损失。
实现细节:在 8x A800 80GB 上进行全参数训练,学习率 5×10−6,训练 batch-size 是 64,rollout_n 是 8,mini-batch 大小是 128,裁剪比例 ϵlow=0.2\epsilon_{\text{low}} = 0.2ϵlow=0.2,ϵhigh=0.28\epsilon_{\text{high}} = 0.28ϵhigh=0.28,温度 T = 1.6。LIBERO 中的动作块数量为 8,RoboTwin1.0&2.0 中为 25。模型共配置了 256 个动作 token。环境交互的最大步数在 LIBERO 中设置为 512,在 RoboTwin1.0&2.0 中根据不同的任务分别设为 200、400 或 800。
主要结果
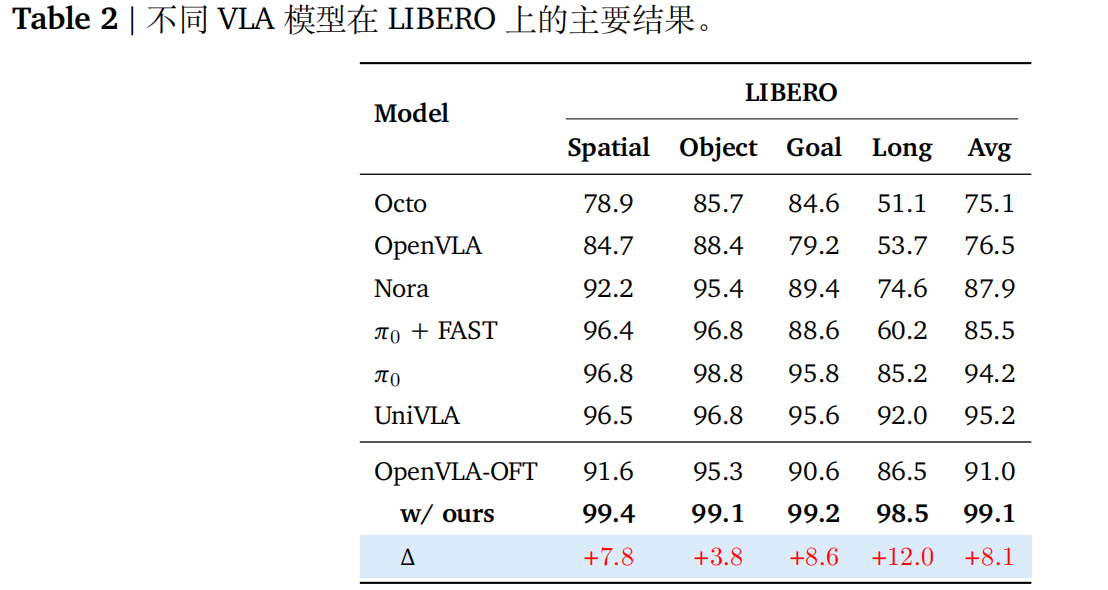
- LIBERO 基准:在四个 LIBERO 任务套件上,SimpleVLA-RL 将 SFT 调优的 OpenVLA-OFT 模型的平均成功率从 91% 提高到 99%,达到了最先进的性能,并在 LIBERO-Long 任务中提高了 12%。
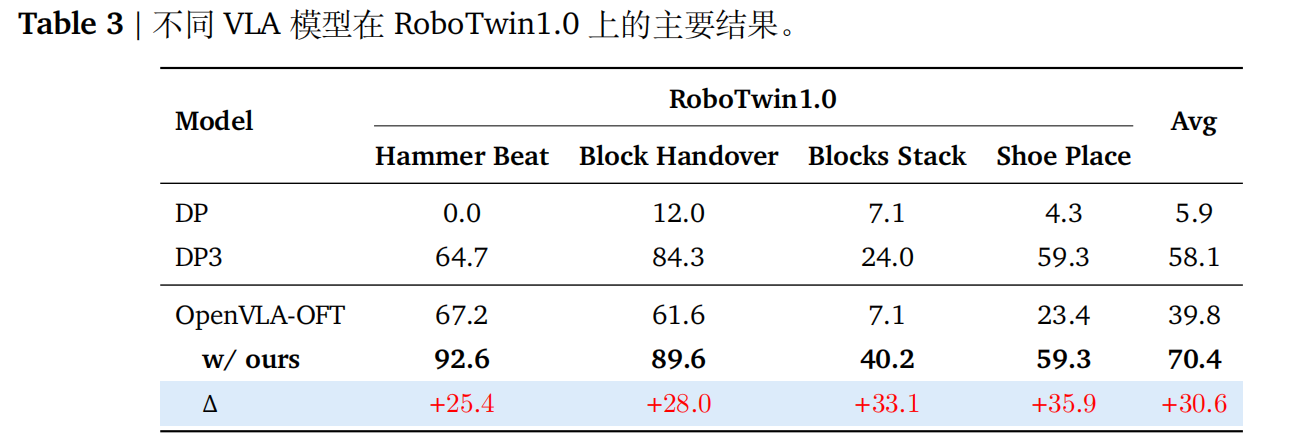
- RoboTwin1.0基准:在四个双臂任务上,SimpleVLA-RL相比调优后的OpenVLA-OFT基线提高了30.6%,平均成功率达到70.4%。
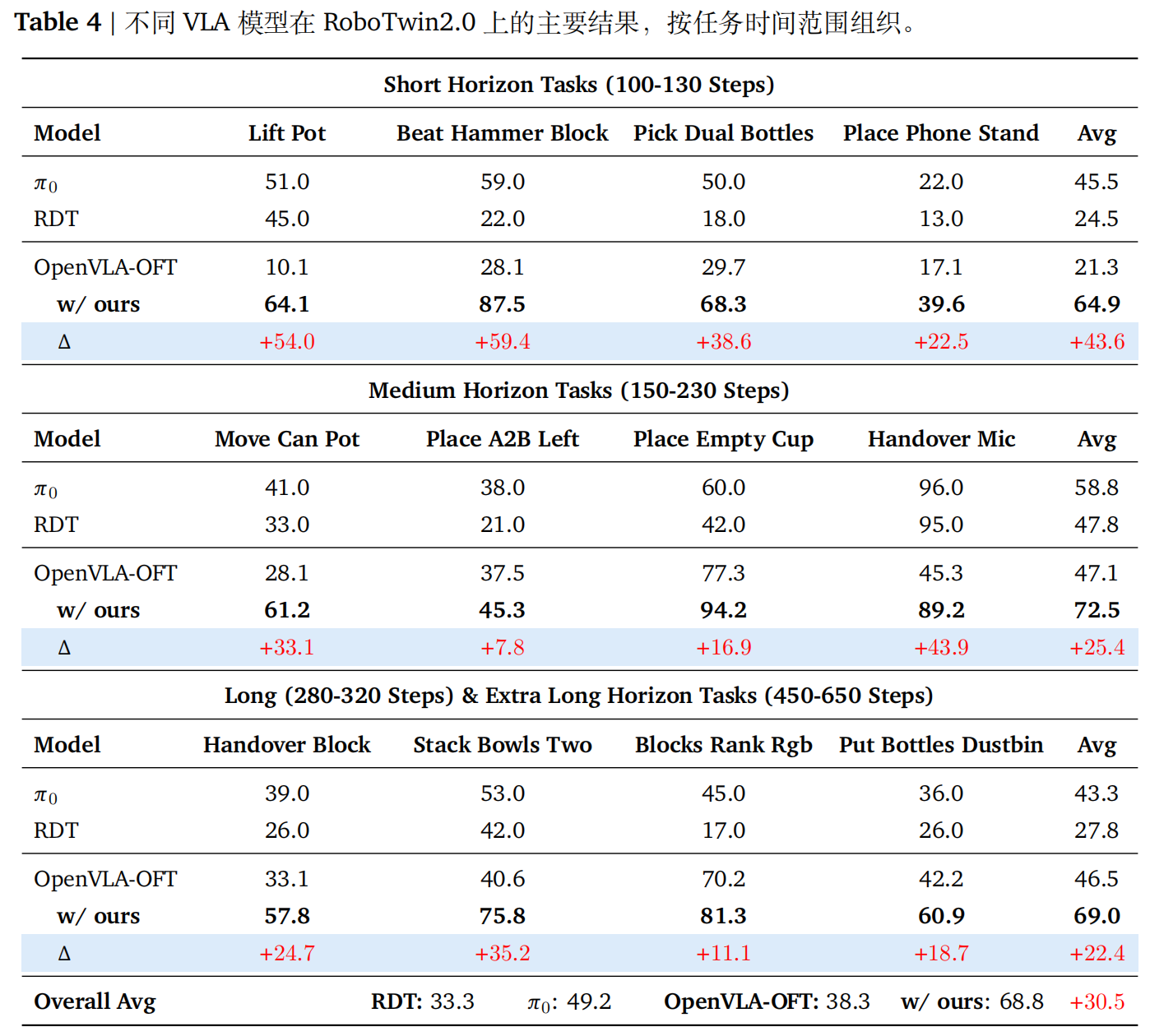
- RoboTwin2.0基准:在12个双臂任务上,SimpleVLA-RL实现了80%的相对改进,平均成功率从38.3%提高到68.8%,并在两个超长任务上分别提高了11.1%和18.7%。在12个双臂任务上,SimpleVLA-RL实现了80%的相对改进,平均成功率从38.3%提高到68.8%,并在两个超长任务上分别提高了11.1%和18.7%。
分析
Takeways:
- 数据:SimpleVLA-RL 可显著降低对示范数据的依赖,有效缓解制约 VLA 缩放的数据稀缺瓶颈。
- 泛化能力:与 SFT 相比,SimpleVLA-RL 在空间配置、物体类型和任务情景方面均展现出强大的泛化能力。
- 真实世界任务:SimpleVLA-RL 展现出强大的仿真到现实的迁移能力,大规模仿真训练显著提升了真实世界中的表现,表明了一条极具前景的实现真实世界策略扩展的路径。
讨论
“Pushcut”:通过 RL 涌现的新模式
作者展示了 RL 训练过程中涌现的一种行为:“pushcut”,指在 SimpleVLA-RL 训练过程中,VLA 模型学习到了演示数据中不存在的新颖行为。
具体而言,在 RoboTwin2.0 的 move can pot 任务中,目标是将罐子运输至指定锅具的相邻位置,所有演示轨迹始终遵循“抓取–移动–放置”的策略,但经过 RL 训练后的 VLA 模型自主发现了一种更高效的解决方案:不在通过抓取,而是直接将罐子推动到目标位置。

这个现象突显了模型绕过传统“抓取—移动—放置”模式的能力。
这一现象凸显了 SFT 与 RL 之间的根本区别。SFT 仅复制演示中存在的固定模式,而 RL 则通过奖励驱动探索,从而发现新的策略。在 RL 训练过程中,有效行为通过正向奖励得到强化,而效率较低的行为则逐渐被淘汰。结果层面的奖励进一步促进了这些新策略的出现:由于成功完成抓取或推动均能获得等量奖励,稀疏奖励设计避免了过程层面监督的程序性约束,为智能体提供了更广阔的探索空间,使其能够发现意料之外但有效的解决方案。
SimpleVLA 的失效模式
作者在五个 RoboTwin2.0 任务上的实验表明,模型先验是决定强化学习效果的关键因子。即基础模型不具备初始任务能力时,RL 完全失效。
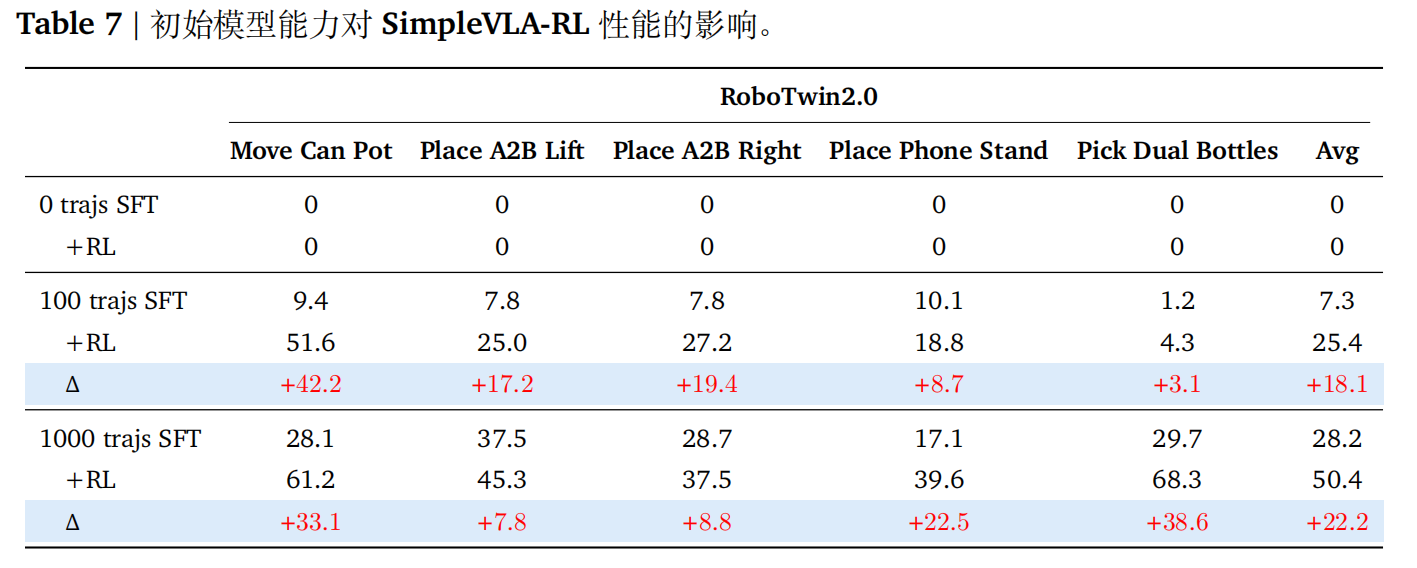
上表展示了,基础模型(0-轨迹 SFT)在所有任务上的成功率均为 0%,表现出完全无关任务的行为。由于采样过程中未生成任何成功轨迹,且仅使用结果奖励(无过程奖励),因此每条轨迹均获得零奖励。结果导致 RL 无法提升性能,性能始终维持在 0%。
结论
在本工作中,我们提出了 SimpleVLA-RL,这是一种专为 VLA 模型设计的强化学习框架。通过在 veRL 基础上扩展针对 VLA 的轨迹采样方法以及并行化的训练–推理–渲染能力,SimpleVLA-RL 实现了可扩展且样本高效的在线强化学习。SimpleVLA-RL 在数据效率、泛化能力和仿真到现实的迁移方面展现出显著提升。在 LIBERO 和 RoboTwin 基准上的持续性能优势,凸显了强化学习不仅能够缓解 SFT 的数据稀缺问题,还能显著增强 VLA 模型的泛化容量。我们希望这些发现能为更自主和适应性强的机器人模型铺平道路。