浅谈矩阵在机器学习线性回归算法中的数学推导
线性回归算法
是机器学习中最基础、最经典的监督学习算法之一,核心思想是建立输入特征(自变量)与输出目标(因变量)之间的线性映射关系,用于解决回归类问题(预测连续型数值,如房价、销量、温度等)。
即:
YYY = α1\alpha_1α1X1X_1X1 + α2\alpha_2α2X2X_2X2 + α3\alpha_3α3X3X_3X3 + … + αn\alpha_nαnXnX_nXn
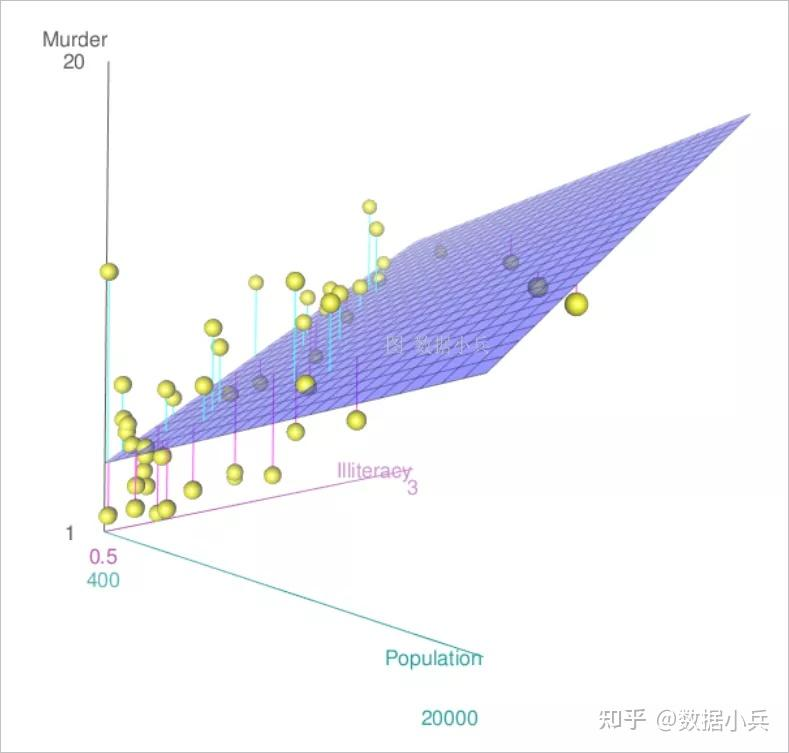
在机器学习中,我们往往可以获得大量数据集,
((( X11X_{11}X11, X12X_{12}X12, X13X_{13}X13, Y1Y_1Y1 )))
((( X21X_{21}X21, X22X_{22}X22, X23X_{23}X23, Y2Y_2Y2 )))
((( X31X_{31}X31, X32X_{32}X32, X33X_{33}X33, Y3Y_3Y3 )))
((( X41X_{41}X41, X42X_{42}X42, X43X_{43}X43, Y4Y_4Y4 )))
((( X51X_{51}X51, X52X_{52}X52, X53X_{53}X53, Y5Y_5Y5 )))
…
((( XN1X_{N1}XN1, XN2X_{N2}XN2, XN3X_{N3}XN3, YNY_NYN )))
若假定以上数据应满足线性回归,
则有:
Y1Y_1Y1 = α11\alpha_{11}α11X11X_{11}X11 + α12\alpha_{12}α12X12X_{12}X12 + α13\alpha_{13}α13X13X_{13}X13 + … + α1n\alpha_{1n}α1nX1nX_{1n}X1n
Y2Y_2Y2 = α21\alpha_{21}α21X21X_{21}X21 + α22\alpha_{22}α22X22X_{22}X22 + α23\alpha_{23}α23X23X_{23}X23 + … + α2n\alpha_{2n}α2nX2nX_{2n}X2n
Y3Y_3Y3 = α31\alpha_{31}α31X31X_{31}X31 + α32\alpha_{32}α32X32X_{32}X32 + α33\alpha_{33}α33X33X_{33}X33 + … + α3n\alpha_{3n}α3nX3nX_{3n}X3n
…
YNY_NYN = αN1\alpha_{N1}αN1XN1X_{N1}XN1 + αN2\alpha_{N2}αN2XN2X_{N2}XN2 + αN3\alpha_{N3}αN3XN3X_{N3}XN3 + … + αNn\alpha_{Nn}αNnXNnX_{Nn}XNn
N 指 数据集数量,
n 指 自变量个数
上述方程组可以用矩阵来表示即为:
[X11X12X13X14...X1nX21X22X23X24...X2nX31X32X33X34...X3nX41X42X43X44...X4n..................XN1XN2XN3XN4...XNn]×[α1α2α3α4...αn] =[Y1Y2Y3Y4...Yn] \begin{bmatrix} X_{11} & X_{12} & X_{13} & X_{14} & ... & X_{1n} \\ X_{21} & X_{22} & X_{23} & X_{24} & ...& X_{2n} \\ X_{31} & X_{32} & X_{33} & X_{34} &...& X_{3n} \\ X_{41} & X_{42} & X_{43} & X_{44} &...& X_{4n} \\ ... & ... & ... & ... &... &...& \\ X_{N1} & X_{N2} & X_{N3} & X_{N4} &...& X_{Nn} \\ \end{bmatrix} \times \begin{bmatrix} \alpha_{1} \\ \alpha_{2} \\ \alpha_3 \\ \alpha_4 \\ ... \\ \alpha_n \\ \end{bmatrix} \ = \begin{bmatrix} Y_{1} \\ Y_{2} \\ Y_3 \\ Y_4 \\ ... \\ Y_n \\ \end{bmatrix} X11X21X31X41...XN1X12X22X32X42...XN2X13X23X33X43...XN3X14X24X34X44...XN4..................X1nX2nX3nX4n...XNn×α1α2α3α4...αn =Y1Y2Y3Y4...Yn
在尝试进行多元线性拟合的过程,就是一个简单的求点到直线/平面的最短距离的高中数学问题,即为求解当方程系数α\alphaα该为何值时,各个数据点距离直线\平面,或者说方程的距离之和最短。
即求:
J=min∣∣Xα−Y∣∣2=min[V12+V22+V32+...+Vn2]J = min||X\alpha - Y||^2 = min[V_1^2 + V_2^2 + V_3^2 + ... + Vn^2]J=min∣∣Xα−Y∣∣2=min[V12+V22+V32+...+Vn2]
所以 对 J 求偏导
这里我们要注意,对于 矩阵 (Xα−Y)(X\alpha - Y)(Xα−Y) 其本质是一个列向量啊,
所以,求得上面的 J,只需要对 列向量 (Xα−Y)(X\alpha - Y)(Xα−Y) 进行一次内积,也就是:
J=(Xα−Y)T(Xα−Y)=(αTXT−YT)(Xα−Y)=αTXTXα−αTXTY−YTXα+YTY\begin{align*}J &= (X\alpha - Y)^T(X\alpha - Y) \\&= (\alpha^TX^T - Y^T)(X\alpha - Y) \\&= \alpha^TX^TX\alpha - \alpha^TX^TY - Y^TX\alpha +Y^TY\end{align*}J=(Xα−Y)T(Xα−Y)=(αTXT−YT)(Xα−Y)=αTXTXα−αTXTY−YTXα+YTY
对 J 求偏导,当偏导=0时,即可得到极值 min[J]min[J]min[J]。
这里要用到三个矩阵求偏导的基础公式,见文章末尾。
- XTXX^TXXTX必为对称阵,证明如下:对称阵即矩阵转秩等于矩阵本身 (XTX)T=XTX(X^TX)^T = X^TX(XTX)T=XTX,
- 对于 αTXTY\alpha^TX^TYαTXTY求偏导,很明显的,[α1,α2,...αn]×[XTY][\alpha_1,\alpha_2, ... \alpha_n ] \times [X^TY][α1,α2,...αn]×[XTY] 其结果为标量,所以 αT(XTY)=(XTY)Tα\alpha^T(X^TY) = (X^TY)^T\alphaαT(XTY)=(XTY)Tα
∂J∂α=2XTXα−XTY−XTY+0=0
\frac{\partial J}{\partial \alpha} = 2X^TX\alpha - X^TY - X^TY + 0 = 0
∂α∂J=2XTXα−XTY−XTY+0=0
得:XTXα=XTY X^TX\alpha = X^TY XTXα=XTY
若 XTXX^TXXTX 可逆, 可得 所求系数 α=(XTX)−1XTY\alpha=(X^TX)^{-1}X^TYα=(XTX)−1XTY
三个矩阵求偏导的基础公式,
f=αTMαf = \alpha^T M \alpha f=αTMα ∂f∂α=2Mα\frac{\partial f}{\partial \alpha} = 2 M \alpha∂α∂f=2Mα
M 必须是对称矩阵 辅助记忆:f=αCα f = \alpha C \alpha f=αCα ∂f∂α=2Cα\frac{\partial f}{\partial \alpha} = 2 C \alpha∂α∂f=2Cα 证明: 若M是对称矩阵,此时我们才可以合并同类项,得到
∂f∂α=2Mα\frac{\partial f}{\partial \alpha} = 2M\alpha∂α∂f=2Mαf=bTα f = b^T \alpha f=bTα ∂f∂α=b \frac{\partial f}{\partial \alpha} = b ∂α∂f=b 证明: 设: b=[b1b2b3b4] b = \begin{bmatrix} b_1 \\ b_2 \\ b_3 \\ b_4 \end{bmatrix} b=b1b2b3b4 α=[α1α2α3α4] \alpha = \begin{bmatrix} \alpha_1 \\ \alpha_2 \\ \alpha_3 \\ \alpha_4 \end{bmatrix} α=α1α2α3α4 f=bTα=b1α1+b2α2+b3α3+b4α4 f = b^T \alpha = b_1\alpha_1 + b_2\alpha_2 + b_3\alpha_3 + b_4\alpha_4f=bTα=b1α1+b2α2+b3α3+b4α4 ∂f∂α=[b1b2b3b4] \frac{\partial f}{\partial \alpha} = \begin{bmatrix} b_1 \\ b_2 \\ b_3\\b_4 \end{bmatrix} ∂α∂f=b1b2b3b4
对常量求偏导为0