Netty从0到1系列之Netty内存管理【下】
文章目录
- Netty内存管理【下】
- 2.3.3 PoolChunk内存分配
- 2.3.4 PoolArena总结
- 2.3.5 PoolChunkList
- 2.3.6 PoolSubpage
- 2.3.7 PoolThreadCache & MemoryRegionCache
- 2.4 内存分配原理
- 2.4.1 Page级别的内存分配
- 2.4.2 Subpage 级别的内存分配
- 2.4.3 PoolThreadCache 的内存分配
- 2.4.4 内存回收原理
推荐阅读:
【01】Netty从0到1系列之I/O模型
【02】Netty从0到1系列之NIO
【03】Netty从0到1系列之Selector
【04】Netty从0到1系列之Channel
【05】Netty从0到1系列之Buffer(上)
【06】Netty从0到1系列之Buffer(下)
【07】Netty从0到1系列之零拷贝技术
【08】Netty从0到1系列之整体架构、入门程序
【09】Netty从0到1系列之EventLoop
【10】Netty从0到1系列之EventLoopGroup
【11】Netty从0到1系列之Future
【12】Netty从0到1系列之Promise
【13】Netty从0到1系列之Netty Channel
【14】Netty从0到1系列之ChannelFuture
【15】Netty从0到1系列之CloseFuture
【16】Netty从0到1系列之Netty Handler
【17】Netty从0到1系列之Netty Pipeline【上】
【18】Netty从0到1系列之Netty Pipeline【下】
【19】Netty从0到1系列之Netty ByteBuf【上】
【20】Netty从0到1系列之Netty ByteBuf【中】
【21】Netty从0到1系列之Netty ByteBuf【下】
【22】Netty从0到1系列之Netty 逻辑架构【上】
【23】Netty从0到1系列之Netty 逻辑架构【下】
【24】Netty从0到1系列之Netty 启动细节分析
【25】Netty从0到1系列之Netty 线程模型【上】
【26】Netty从0到1系列之Netty 线程模型【下】
【27】Netty从0到1系列之Netty ChannelPipeline
【28】Netty从0到1系列之Netty ChannelHandler
【29】Netty从0到1系列之Netty拆包、粘包【1】
【30】Netty从0到1系列之Netty拆包、粘包【2】
【31】Netty从0到1系列之Netty拆包、粘包【3】
【32】Netty从0到1系列之Netty拆包、粘包【4】
【33】Netty从0到1系列之Netty拆包、粘包【5】
【34】Netty从0到1系列之动态从内存分配】
【35】Netty从0到1系列之writeAndFlush原理分析】
【36】Netty从0到1系列之Netty内存管理【上】】
Netty内存管理【下】
2.3.3 PoolChunk内存分配
Netty 内存的分配和回收都是基于 PoolChunk 完成的,PoolChunk 是真正存储内存数据的地方,每个 PoolChunk 的默认大小为 16M,首先我们看下 PoolChunk 数据结构的定义:
final class PoolChunk<T> implements PoolChunkMetric {final PoolArena<T> arena;final T memory; // 存储的数据private final byte[] memoryMap; // 满二叉树中的节点是否被分配,数组大小为 4096private final byte[] depthMap; // 满二叉树中的节点高度,数组大小为 4096private final PoolSubpage<T>[] subpages; // PoolChunk 中管理的 2048 个 8K 内存块private int freeBytes; // 剩余的内存大小PoolChunkList<T> parent;PoolChunk<T> prev;PoolChunk<T> next;// 省略其他代码
}
PoolChunk 可以理解为 Page 的集合,Page 只是一种抽象的概念,实际在 Netty 中 Page 所指的是 PoolChunk 所管理的子内存块,每个子内存块采用 PoolSubpage 表示。Netty 会使用伙伴算法将 PoolChunk 分配成 2048 个 Page, 最终形成一颗满二叉树,二叉树中所有子节点的内存都属于其父节点管理,如下图所示。
PoolChunk 用于 Chunk 场景下的内存分配
【用于分配大于8KB内存】;
PoolChunk是 Netty 向 JVM 申请的一大块连续内存(例如 16MB)的抽象。
它是进行页级别(Page-Level) 分配的基本单位。
Netty 使用一种高效的
Buddy算法 和 完全二叉树(Complete Binary Tree) 来管理PoolChunk中的内存分配。一个 16MB 的 Chunk 默认由 2048 个 8KB 的 Page 组成。这棵二叉树的深度为 11(从 0 开始计算),每个节点记录着其下属子树中可用的 Page 数量。
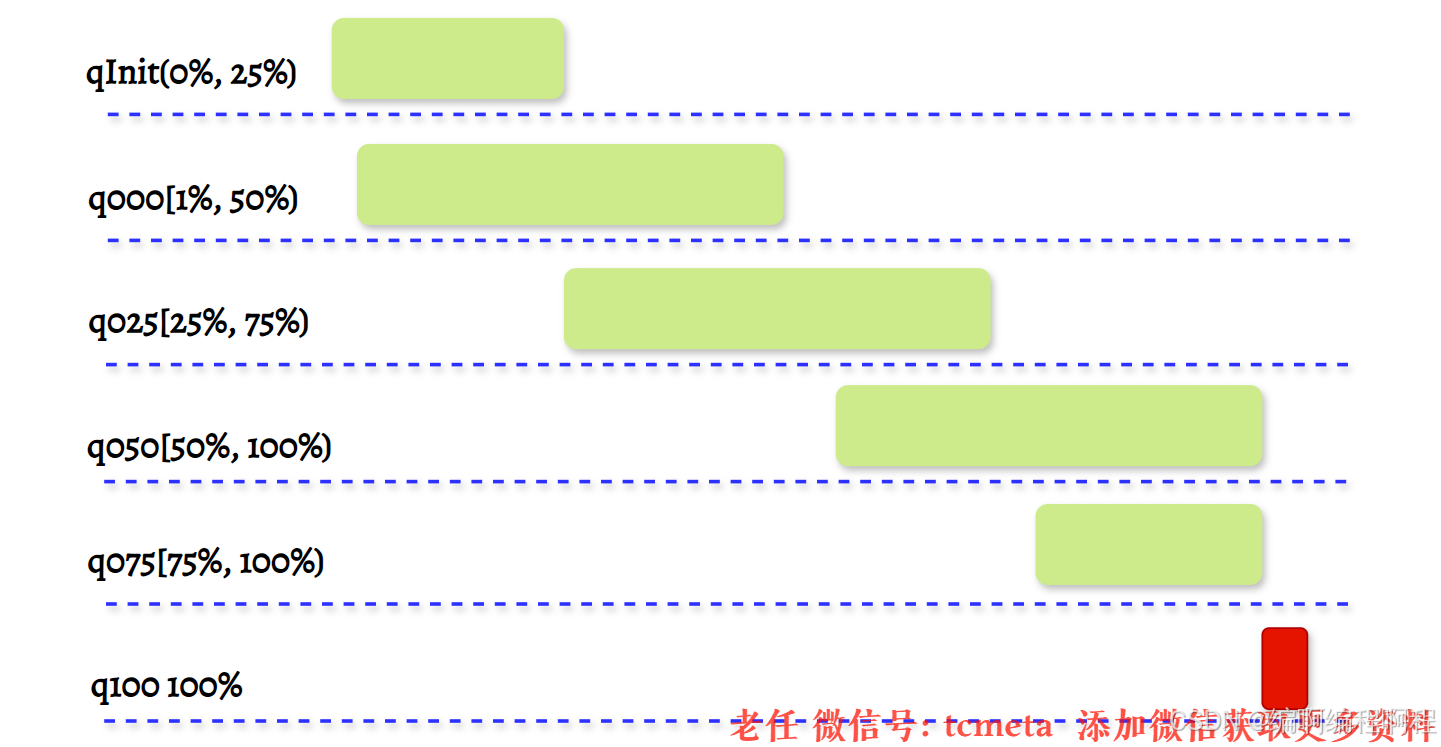
PoolArean初始化了6个PoolChunkList, 分别是qInit、q000、q025、q050、q075、q100, 分别代表不同的内存使用率,如下所示:
- 🔏 qInit,内存使用率为 0 ~ 25% 的 Chunk。
- 🉑 q000,内存使用率为 1 ~ 50% 的 Chunk。
- 💃 q025,内存使用率为 25% ~ 75% 的 Chunk。
- 🌓 q050, 内存使用率为 50% ~ 100% 的 Chunk。
- 🌔 q075,内存使用率为 75% ~ 100% 的 Chunk。
- 🥓 q100,内存使用率为 100% 的 Chunk。
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, sizeClass.chunkSize);
q075 = new PoolChunkList<T>(this, q100, 75, 100, sizeClass.chunkSize);
q050 = new PoolChunkList<T>(this, q075, 50, 100, sizeClass.chunkSize);
q025 = new PoolChunkList<T>(this, q050, 25, 75, sizeClass.chunkSize);
q000 = new PoolChunkList<T>(this, q025, 1, 50, sizeClass.chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, sizeClass.chunkSize);
六种类型的 PoolChunkList 除了 qInit,它们之间都形成了双向链表:

Chunk 内存使用率的变化,Netty 会重新检查内存的使用率并放入对应的 PoolChunkList,所以 PoolChunk 会在不同的 PoolChunkList 移动
- qInit 和 q000 为什么需要设计成两个,是否可以合并成一个?
qInit 用于存储初始分配的 PoolChunk
- 因为在第一次内存分配时,
PoolChunkList 中并没有可用的 PoolChunk,所以需要新创建一个 PoolChunk 并添加到 qInit 列表中。qInit 中的 PoolChunk 即使内存被完全释放也不会被回收,避免 PoolChunk 的重复初始化工作。- q000 则用于存放内存使用率为 1 ~ 50% 的 PoolChunk,q000 中的 PoolChunk 内存被完全释放后,PoolChunk 从链表中移除,对应分配的内存也会被回收.
【特别注意】: 在分配大于 8K 的内存时,其链表的访问顺序是 q050 -> q025 -> q000 -> qInit -> q075, 遍历检查 PoolChunkList 中是否有 PoolChunk 可以用于内存分配.
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {// 断言当前线程持有锁assert lock.isHeldByCurrentThread();// 尝试从 q050 队列分配内存if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) ||// 尝试从 q025 队列分配内存q025.allocate(buf, reqCapacity, sizeIdx, threadCache) ||// 尝试从 q000 队列分配内存q000.allocate(buf, reqCapacity, sizeIdx, threadCache) ||// 尝试从 qInit 队列分配内存qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) ||// 尝试从 q075 队列分配内存q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) {return;}// 如果上述队列都无法分配内存,则添加一个新的块(chunk)PoolChunk<T> c = newChunk(sizeClass.pageSize, sizeClass.nPSizes, sizeClass.pageShifts, sizeClass.chunkSize);// 尝试从新创建的块中分配内存boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);// 断言分配成功assert success;// 将新创建的块添加到 qInit 队列中qInit.add(c);
}
【特别注意】: 为什么会优先选择 q050,而不是从 q000 开始呢?
- 可以说这是一个折中的选择,在频繁分配内存的场景下,如果从 q000 开始,
会有大部分的 PoolChunk 面临频繁的创建和销毁,造成内存分配的性能降低。- 如果从 q050 开始,会使 PoolChunk 的使用率范围保持在中间水平,降低了 PoolChunk 被回收的概率,
从而兼顾了性能。
分配过程
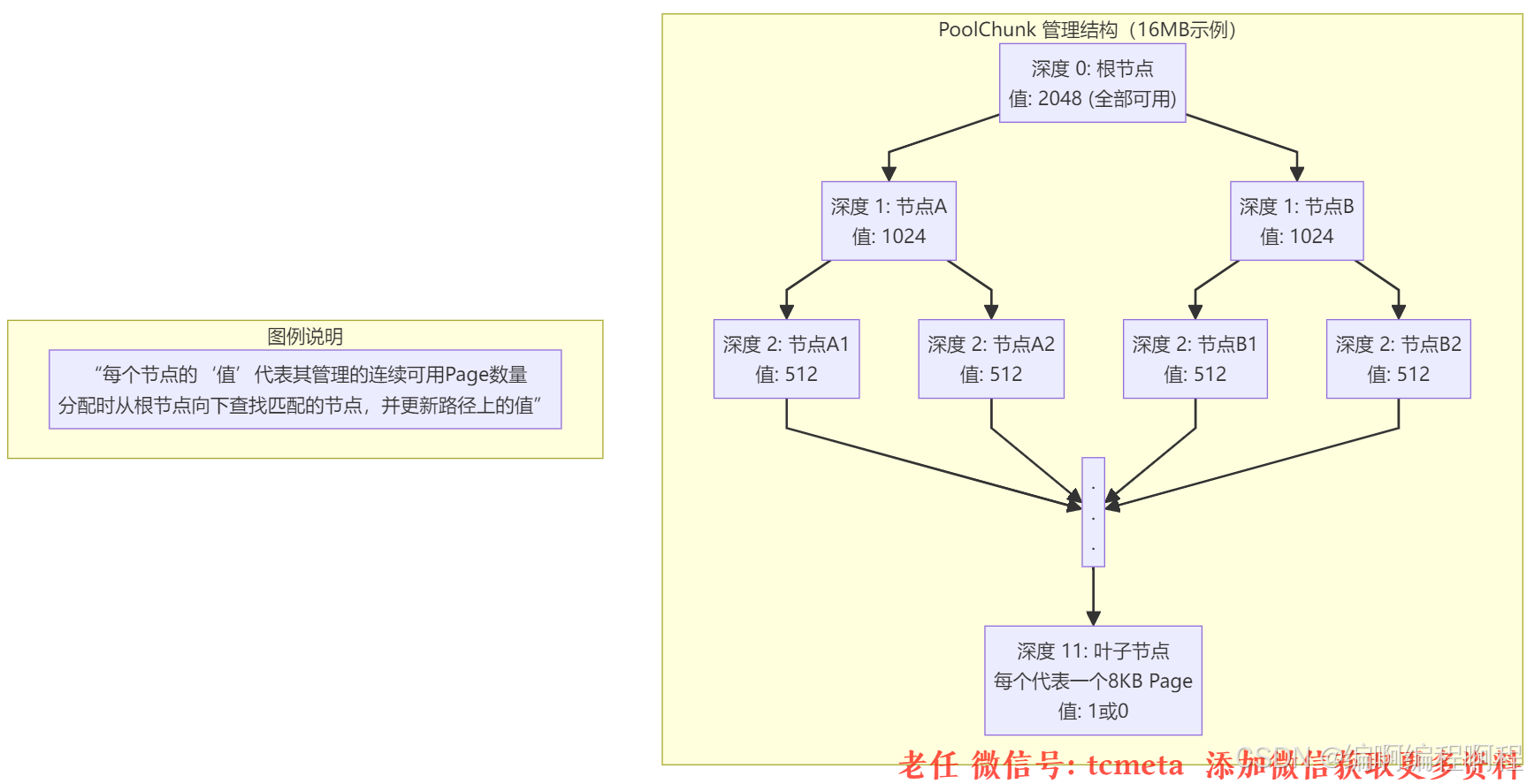
分配过程(譬如申请16KB,即2 Pages)
-
从根节点开始查找。
-
检查左子节点(值=1024)是否 >= 2?是,继续向下查找。
-
检查左子节点的左子节点(值=512)是否 >= 2?是,继续向下…
-
直到在深度为 3 的某个节点(管理着 16个Page)找到可用的 2 个连续 Page。
-
将该节点标记为已使用(值置为0),并递归更新其所有父节点的值(
父节点值 = max(左子节点值, 右子节点值))。
结合
PoolChunk的结构图,我们介绍一下PoolChunk 中几个重要的属性
- depthMap 用于存放节点所对应的高度, 例如第 2048 个节点 depthMap[1025] = 10
- memoryMap 用于记录二叉树节点的分配信息,memoryMap 初始值与 depthMap 是一样的,随着节点被分配,不仅节点的值会改变,而且会递归遍历更新其父节点的值,父节点的值取两个子节点中最小的值。
- subpages 对应上图中 PoolChunk 内部的 Page0、Page1、Page2 … Page2047
- Netty 中并没有
Page的定义,直接使用PoolSubpage表示。
当分配的内存小于 8K 时,PoolChunk 中的每个 Page 节点会被划分成为更小粒度的内存块进行管理,小内存块同样以 PoolSubpage 管理。- 小内存的分配场景下,会首先找到对应的 PoolArena ,然后根据计算出对应的 tinySubpagePools 或者 smallSubpagePools 数组对应的下标,如果对应数组元素所包含的 PoolSubpage 链表不存在任何节点,那么将创建新的 PoolSubpage 加入链表中。
2.3.4 PoolArena总结
Netty 内存规格的分类,PoolArena 对应实现了 Subpage 和 Chunk 中的内存分配
PoolSubpage 用于分配小于 8K 的内存- 🎟 Tiny
- tinySubpagePools[]
- 单位
最小为 16B,按 16B 依次递增,共32种情况
- 单位
- tinySubpagePools[]
- ⛵️ Small
- smallSubpagePools[]
- 512B、1024B、2048B、4096B
四种情况
- 512B、1024B、2048B、4096B
- smallSubpagePools[]
- 🎟 Tiny
PoolChunkList 用于分配大于 8K 的内存- 共有
6个PoolChunkList- qInit、q000、q025、q050、q075、q100
- 在
分配大于8K内存的时候,从q050开始分配- q050->q025->q000->qInit->q075
- 共有
2.3.5 PoolChunkList
Arena 不会直接管理零散的 PoolChunk,而是通过 PoolChunkList 来管理。PoolChunkList 是一个 PoolChunk 的链表,但这些链表是根据 Chunk 的内存使用率来划分的。
Netty 定义了多个 PoolChunkList,例如:
q000: 使用率 0% - 25%q025: 使用率 25% - 50%q050: 使用率 50% - 75%q075: 使用率 75% - 100%q100: 使用率 100%
分配策略:分配请求会优先在 q050 -> q025 -> q000 -> q075 -> q100 这样的顺序中寻找合适的 Chunk。这样可以优先使用使用率适中的 Chunk,提高内存使用率并减少碎片。
释放策略:当一个 Chunk 的内存被释放导致使用率下降时,它会被移动到更低使用率的 PoolChunkList 中。反之,当分配导致使用率上升时,它可能会被移动到更高使用率的列表中。
- PoolChunkList 负责管理
多个 PoolChunk 的生命周期- 同一个 PoolChunkList 中存放内存使用率相近的
PoolChunk,这些 PoolChunk 同样以双向链表的形式连接在一起- 因为 PoolChunk 经常要从 PoolChunkList 中删除,并且需要在不同的PoolChunkList 中移动,所以双向链表是管理 PoolChunk 时间复杂度较低的数据结构。
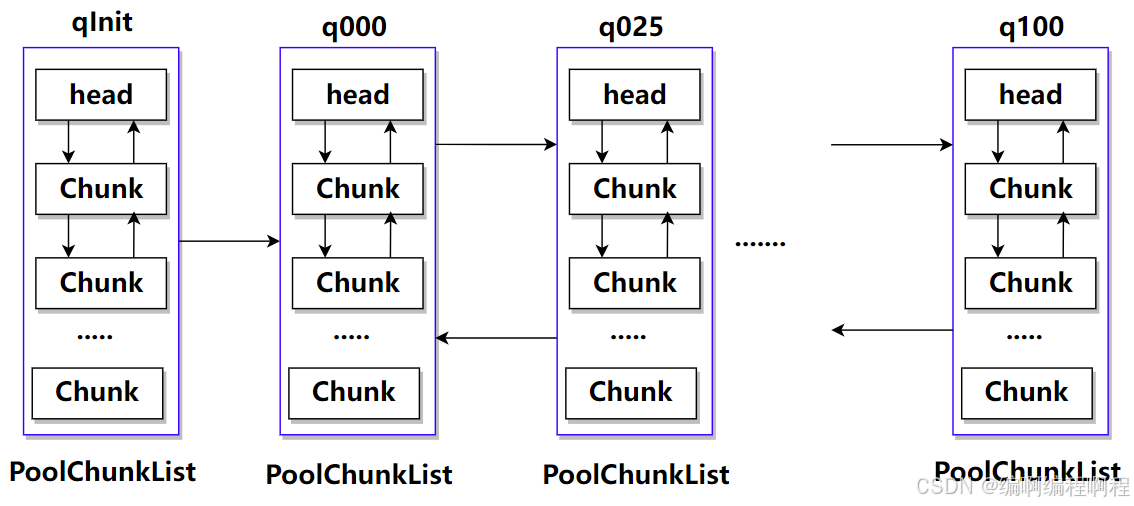
当 PoolChunk 进行内存分配后,如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个 PoolChunkList。
同理,PoolChunk 中的内存发生释放后,如果使用率小于 minUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到前一个 PoolChunkList。
Netty 初始化的六个 PoolChunkList,每个 PoolChunkList 的上下限都有交叉重叠的部分,如下图所示。因为 PoolChunk 需要在 PoolChunkList 不断移动,如果每个 PoolChunkList 的内存使用率的临界值都是恰好衔接的,例如 1 ~ 50%、50% ~ 75%,那么如果 PoolChunk 的使用率一直处于 50% 的临界值,会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。
2.3.6 PoolSubpage
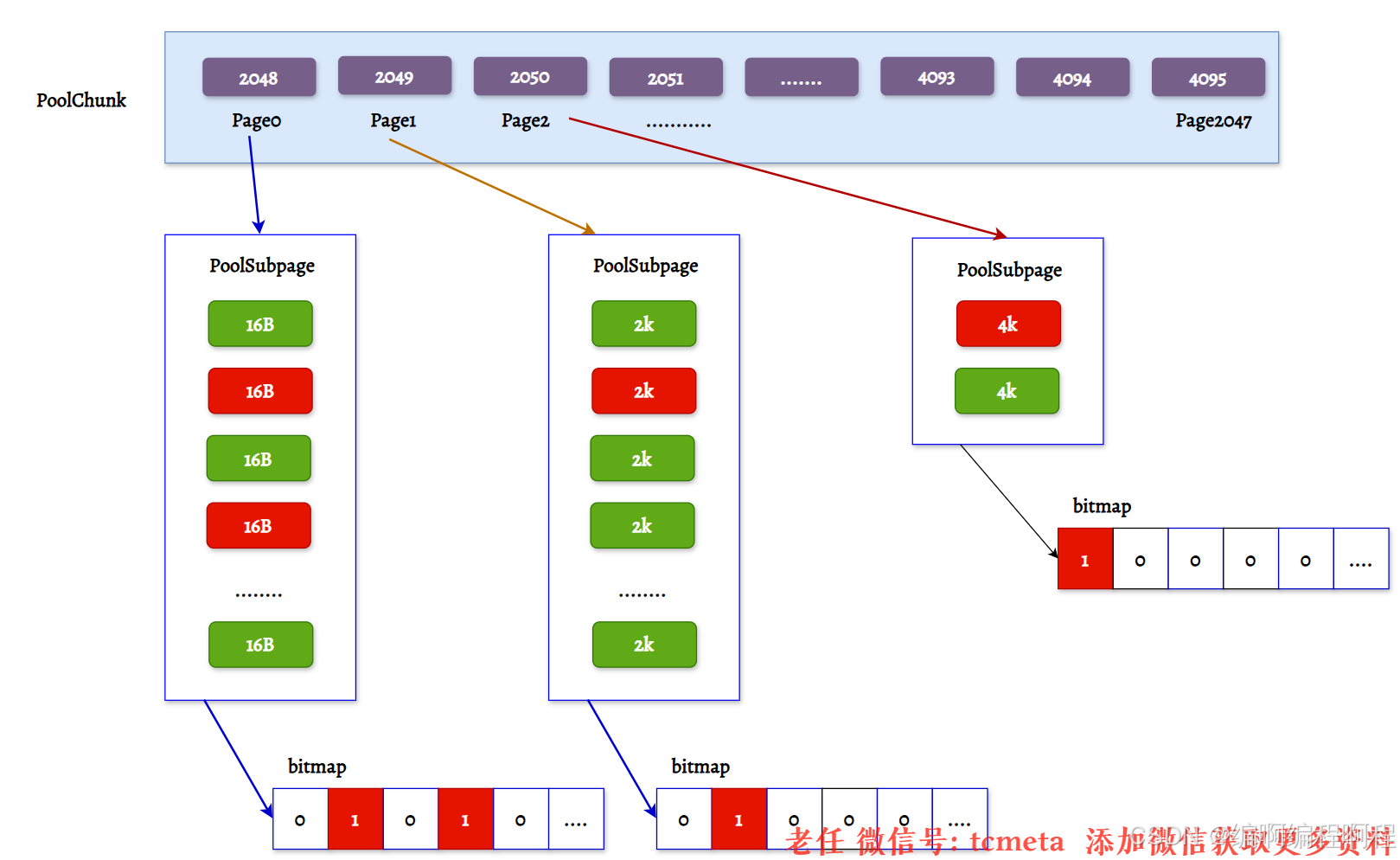
PoolSubpage 应该有了一些认识,在小内存分配的场景下,即分配的内存大小小于一个 Page 8K,会使用 PoolSubpage 进行管理。首先看下 PoolSubpage 的定义:
final class PoolSubpage<T> implements PoolSubpageMetric {final PoolChunk<T> chunk;private final int memoryMapIdx; // 对应满二叉树节点的下标private final int runOffset; // PoolSubpage 在 PoolChunk 中 memory 的偏移量private final long[] bitmap; // 记录每个小内存块的状态// 与 PoolArena 中 tinySubpagePools 或 smallSubpagePools 中元素连接成双向链表PoolSubpage<T> prev;PoolSubpage<T> next;int elemSize; // 每个小内存块的大小private int maxNumElems; // 最多可以存放多少小内存块:8K/elemSizeprivate int numAvail; // 可用于分配的内存块个数// 省略其他代码
}
PoolSubpage 中每个属性的含义都比较清晰易懂;
❓第一个就是 PoolSubpage 是如何记录内存块的使用状态的呢?
PoolSubpage通过位图bitmap 记录子内存是否已经被使用,bit 的取值为 0 或者 1
2.3.7 PoolThreadCache & MemoryRegionCache
PoolThreadCache 顾名思义,对应的是 jemalloc 中本地线程缓存的意思。那么 PoolThreadCache 是如何被使用的呢?
当内存释放时,与 jemalloc 一样,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。PoolThreadCache 缓存 Tiny、Small、Normal 三种类型的数据,而且根据堆内和堆外内存的类型进行了区分
final class PoolThreadCache {final PoolArena<byte[]> heapArena;final PoolArena<ByteBuffer> directArena;private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches;private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches;private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches;private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches;private final MemoryRegionCache<byte[]>[] normalHeapCaches;private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches;// 省略其他代码
}
PoolThreadCache 中有一个重要的数据结构:MemoryRegionCache。MemoryRegionCache 有三个重要的属性,分别为 queue,sizeClass 和 size,下图是不同内存规格所对应的 MemoryRegionCache 属性取值范围:
| Queue | sizeClass | size |
|---|---|---|
| Queue<Entry<T>> | tiny (0 ~ 512B) | N*16B |
| Queue<Entry<T>> | samll (512B ~ 8K) | 512B、1K、2K、4K |
| Queue<Entry<T>> | normal (8k ~ 16M) | 8K、16K、32K |
MemoryRegionCache 实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
PoolThreadCache 将不同规格大小的内存都使用单独的 MemoryRegionCache 维护,如下图所示,图中的每个节点都对应一个 MemoryRegionCache
2.4 内存分配原理
Netty 中负责线程分配的组件有两个:PoolArena和PoolThreadCache。PoolArena 是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache 是每个线程私有的缓存空间,如下图所示。
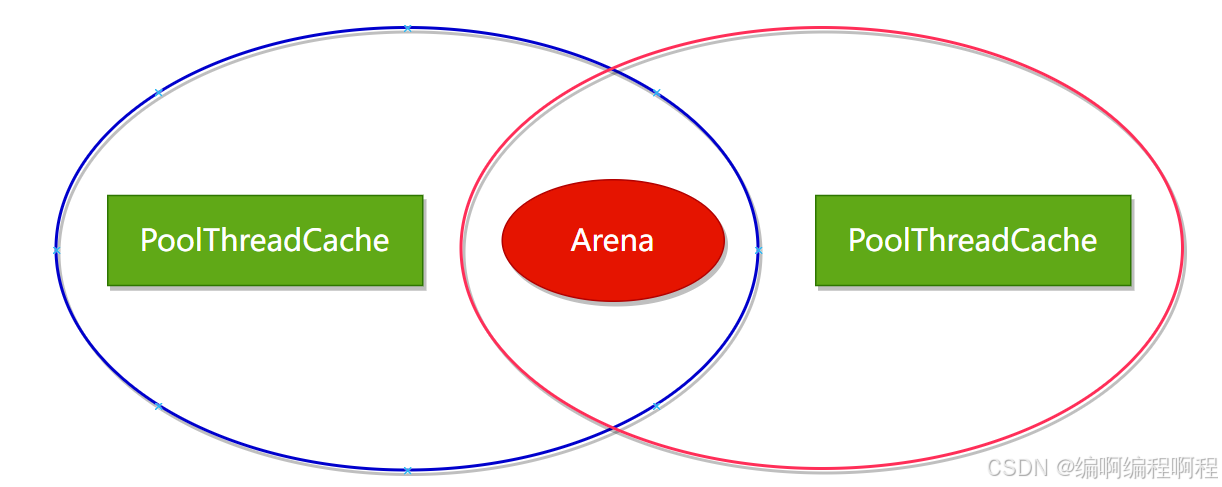
- PoolArena 中管理的内存单位为 PoolChunk【大小16MB, 16384KB】,每个 PoolChunk 会被划分为 2048【16384/8=2048】 个 8K 的 Page.
申请的内存【大于8KB】时, PoolChunk会以Page为单位进行内存分配.申请的内存【小于8KB】时, 会由PoolSubpage管理粒度更小的内存分配.
- PoolArena 分配的内存被释放后, 不会立即会还给 PoolChunk,
而且会缓存在本地私有缓存 PoolThreadCache 中,在下一次进行内存分配时,会优先从 PoolThreadCache 中查找匹配的内存块。
总结:
- 分配内存
大于 8K 时,PoolChunk 中采用的Page 级别的内存分配策略。- 分配内存
小于 8K 时,由 PoolSubpage 负责管理的内存分配策略。- 分配
内存小于 8K 时,为了提高内存分配效率,由 PoolThreadCache 本地线程缓存提供的内存分配。
2.4.1 Page级别的内存分配
每个 PoolChunk 默认大小为 16M,PoolChunk 是通过伙伴算法管理多个 Page,每个 PoolChunk 被划分为 2048 个 Page.
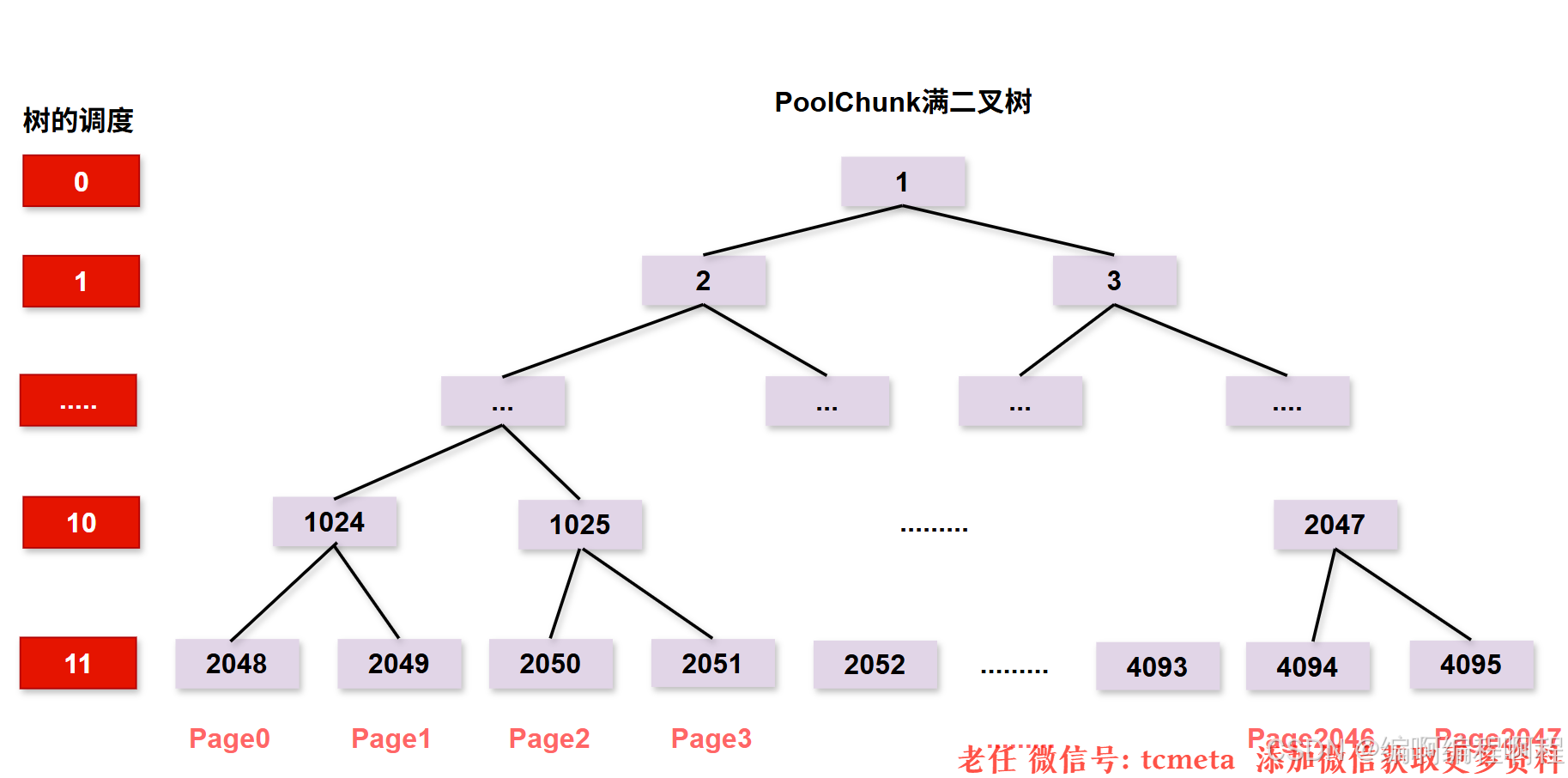
假如用户需要依次申请 8K、16K、8K 的内存,通过这里例子我们详细描述下 PoolChunk 如何分配 Page 级别的内存,方便大家理解伙伴算法的原理.
[!tip]
- PoolChunk 分配 Page 主要分为三步
- 首先根据分配内存大小计算二叉树所在节点的高度
- 然后查找对应高度中是否存在可用节点
- 如果分配成功则减去已分配的内存大小得到剩余可用空间
2.4.2 Subpage 级别的内存分配
为了提高内存分配的利用率,在分配小于 8K 的内存时,PoolChunk 不在分配单独的 Page,而是将 Page 划分为更小的内存块,由 PoolSubpage 进行管理。
long allocate() {if (numAvail == 0 || !doNotDestroy) {return -1;}final int bitmapIdx = getNextAvail();if (bitmapIdx < 0) {removeFromPool(); // Subpage appear to be in an invalid state. Remove to prevent repeated errors.throw new AssertionError("No next available bitmap index found (bitmapIdx = " + bitmapIdx + "), " +"even though there are supposed to be (numAvail = " + numAvail + ") " +"out of (maxNumElems = " + maxNumElems + ") available indexes.");}int q = bitmapIdx >>> 6;int r = bitmapIdx & 63;assert (bitmap[q] >>> r & 1) == 0;bitmap[q] |= 1L << r;if (-- numAvail == 0) {removeFromPool();}return toHandle(bitmapIdx);
}
2.4.3 PoolThreadCache 的内存分配
我们知道 PoolArena 分配的内存被释放时,Netty 并没有将缓存归还给 PoolChunk,而是使用 PoolThreadCache 缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。所以下面我们从 PoolArena#allocate() 的源码中看下 PoolThreadCache 是如何使用的。
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {final int normCapacity = normalizeCapacity(reqCapacity);if (isTinyOrSmall(normCapacity)) { // capacity < pageSizeint tableIdx;PoolSubpage<T>[] table;boolean tiny = isTiny(normCapacity);if (tiny) { // < 512if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {return;}tableIdx = tinyIdx(normCapacity);table = tinySubpagePools;} else {if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {return;}tableIdx = smallIdx(normCapacity);table = smallSubpagePools;}// 省略其他代码}if (normCapacity <= chunkSize) {if (cache.allocateNormal(this, buf, reqCapacity, normCapacity)) {return;}synchronized (this) {allocateNormal(buf, reqCapacity, normCapacity);++allocationsNormal;}} else {allocateHuge(buf, reqCapacity);}
}
- 对申请的内存大小做向上取整,例如 20B 的内存大小会取整为 32B。
- 当申请的内存大小小于 8K 时,分为 Tiny 和 Small 两种情况,分别都会优先尝试从 PoolThreadCache 分配内存,如果 PoolThreadCache 分配失败,才会走 PoolArena 的分配流程。
- 当申请的内存大小大于 8K,但是小于 Chunk 的默认大小 16M,属于 Normal 的内存分配,也会优先尝试从 PoolThreadCache 分配内存,如果 PoolThreadCache 分配失败,才会走 PoolArena 的分配流程。
- 当申请的内存大小大于 Chunk 的 16M,则不会经过 PoolThreadCache,直接进行分配
2.4.4 内存回收原理
当用户线程释放内存时会将内存块缓存到本地线程的私有缓存 PoolThreadCache 中,这样在下次分配内存时会提高分配效率,但是当内存块被用完一次后,再没有分配需求,那么一直驻留在内存中又会造成浪费。接下来我们就看下 Netty 是如何实现内存释放的呢?直接跟进下 PoolThreadCache 的源码.
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {if (cache == null) {return false;}// 默认每执行 8192 次 allocate(),就会调用一次 trim() 进行内存整理boolean allocated = cache.allocate(buf, reqCapacity);if (++ allocations >= freeSweepAllocationThreshold) {allocations = 0;trim();}return allocated;
}void trim() {trim(tinySubPageDirectCaches);trim(smallSubPageDirectCaches);trim(normalDirectCaches);trim(tinySubPageHeapCaches);trim(smallSubPageHeapCaches);trim(normalHeapCaches);
}
Netty 记录了 allocate() 的执行次数,默认每执行 8192 次,就会触发 PoolThreadCache 调用一次 trim() 进行内存整理,会对 PoolThreadCache 中维护的六个 MemoryRegionCache 数组分别进行整理.
public final void trim() {int free = size - allocations;allocations = 0;// We not even allocated all the number that areif (free > 0) {free(free, false);}
}private int free(int max, boolean finalizer) {int numFreed = 0;for (; numFreed < max; numFreed++) {Entry<T> entry = queue.poll();if (entry != null) {freeEntry(entry, finalizer);} else {// all clearedreturn numFreed;}}return numFreed;
}
通过 size - allocations 衡量内存分配执行的频繁程度,其中 size 为该 MemoryRegionCache 对应的内存规格大小,size 为固定值,例如 Tiny 类型默认为 512。allocations 表示 MemoryRegionCache 距离上一次内存整理已经发生了多少次 allocate 调用,当调用次数小于 size 时,表示 MemoryRegionCache 中缓存的内存块并不常用,从队列中取出内存块依次释放。
此外 Netty 在线程退出的时候还会回收该线程的所有内存,PoolThreadCache 重载了 finalize() 方法,在销毁前执行缓存回收的逻辑,对应源码如下:
@Override
protected void finalize() throws Throwable {try {super.finalize();} finally {free(true);}
}void free(boolean finalizer) {if (freed.compareAndSet(false, true)) {int numFreed = free(tinySubPageDirectCaches, finalizer) +free(smallSubPageDirectCaches, finalizer) +free(normalDirectCaches, finalizer) +free(tinySubPageHeapCaches, finalizer) +free(smallSubPageHeapCaches, finalizer) +free(normalHeapCaches, finalizer);if (numFreed > 0 && logger.isDebugEnabled()) {logger.debug("Freed {} thread-local buffer(s) from thread: {}", numFreed,Thread.currentThread().getName());}if (directArena != null) {directArena.numThreadCaches.getAndDecrement();}if (heapArena != null) {heapArena.numThreadCaches.getAndDecrement();}}
}
线程销毁时 PoolThreadCache 会依次释放所有 MemoryRegionCache 中的内存数据,其中 free 方法的核心逻辑与之前内存整理 trim 中释放内存的过程是一致的,有兴趣的同学可以自行翻阅源码。
到此为止,整个 Netty 内存池的分配和释放原理我们已经分析完了,其中巧妙的设计思路以及源码细节的实现,都是非常值得我们学习的宝贵资源。
内存分配总结
- 分四种内存规格管理内存,分别为 Tiny、Samll、Normal、Huge,PoolChunk 负责管理 8K 以上的内存分配,PoolSubpage 用于管理 8K 以下的内存分配。当申请内存大于 16M 时,不会经过内存池,直接分配。
- 设计了本地线程缓存机制 PoolThreadCache,用于提升内存分配时的并发性能。用于申请 Tiny、Samll、Normal 三种类型的内存时,会优先尝试从 PoolThreadCache 中分配。
- PoolChunk 使用伙伴算法管理 Page,以二叉树的数据结构实现,是整个内存池分配的核心所在。
- 每调用 PoolThreadCache 的 allocate() 方法到一定次数,会触发检查 PoolThreadCache 中缓存的使用频率,使用频率较低的内存块会被释放。
- 线程退出时,Netty 会回收该线程对应的所有内存