ICCV-2025 | 大模型驱动的认知导航框架!CogNav:面向目标导航的大型语言模型驱动的认知过程建模

- 作者:Yihan Cao1^{1}1, Jiazhao Zhang2^{2}2, Zhinan Yu1^{1}1, Shuzhen Liu1^{1}1, Zheng Qin3^{3}3, Qin Zou4^{4}4, Bo Du4^{4}4, Kai Xu1^{1}1
- 单位:1^{1}1国防科技大学计算机学院,2^{2}2北京大学计算机学院CFCS,3^{3}3军事科学院国防创新研究院,4^{4}4武汉大学计算机学院
- 论文标题:CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
- 论文链接:https://arxiv.org/pdf/2412.10439v3
- 项目主页:https://yhancao.github.io/CogNav/
- 代码链接:https://github.com/yhanCao/CogNav_ObjNav
主要贡献
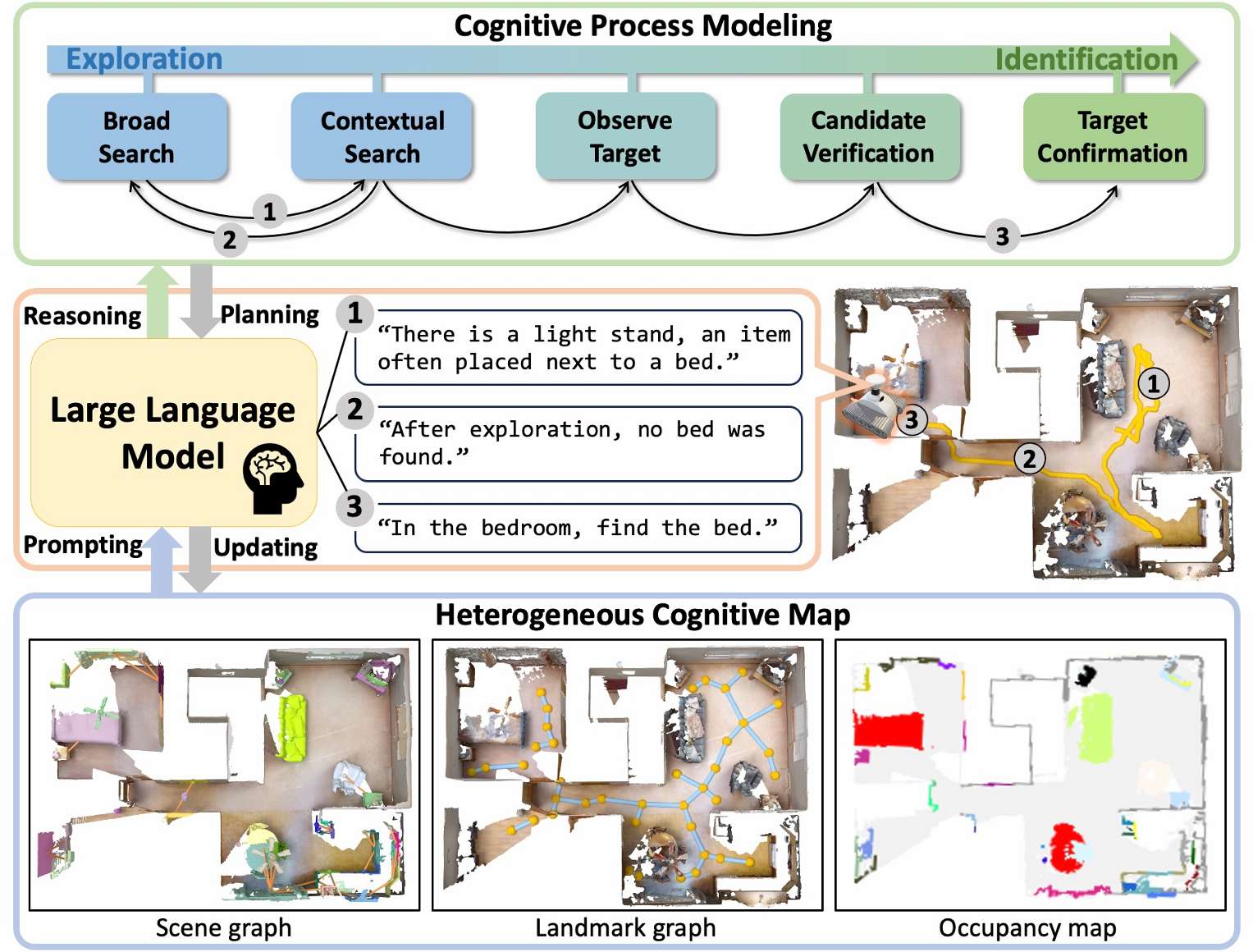
- 提出了面向目标导航(ObjectNav)任务的认知过程建模方法,通过利用大语言模型(LLMs)的常识和空间推理能力,显著提高了目标导航的成功率。
- 设计了精细的认知状态以及用于基于LLM的有根据的推理状态转换的提示,能够更好地模拟人类在新环境中搜索目标物体时的认知过程。
- 提出了一种在线构建的异构认知地图表示,该地图能够动态更新并通过提示LLM来确保高地图质量,为导航提供了更丰富的环境信息。
研究背景
- 目标导航(ObjectNav)是具身人工智能中的一个基础任务,要求智能体在之前未见过的环境中找到目标物体,这一任务融合了感知和认知过程,包括目标识别和决策制定等。
- 近年来,视觉基础模型的快速发展显著提升了具身智能体的视觉感知能力,推动了零样本目标导航的进展。然而,在目标导航的认知过程建模方面,进展相对有限,主要受限于通过模拟器演示或回放进行隐式学习,或者依赖于预定义的启发式规则。
- 神经科学的证据表明,人类大脑在新环境中搜索目标物体时会维持并动态更新精细的认知状态,受此启发,本文提出CogNav框架,旨在利用LLMs模拟这一认知过程。
方法
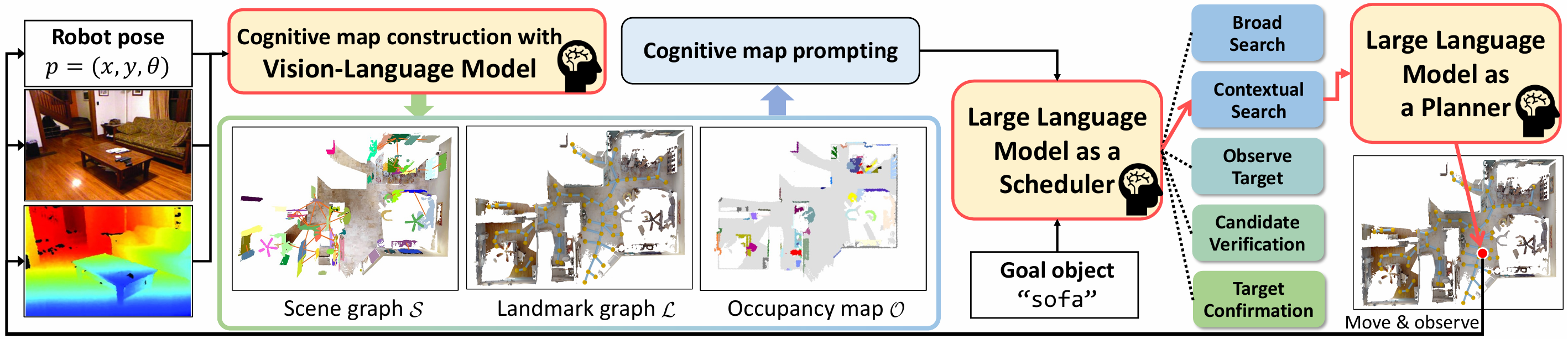
认知地图构建
为了全面编码场景环境信息,CogNav在线构建一个异构认知地图 C\mathcal{C}C,它包含语义场景图 S\mathcal{S}S、二维占用图 M\mathcal{M}M 和地标图 L\mathcal{L}L。这三个部分共同为智能体提供丰富的环境信息,辅助其进行导航决策。
场景图
- 定义:场景图 St=⟨Nt,Et⟩\mathcal{S}_t = \langle \mathcal{N}_t, \mathcal{E}_t \rangleSt=⟨Nt,Et⟩ 由实例节点 Nt\mathcal{N}_tNt 和空间信息边 Et\mathcal{E}_tEt 组成。每个节点 ntn_tnt 表示环境中的一个实例及其语义描述,每条边 ete_tet 表示两个节点之间的空间关系。
- 构建方法:使用在线开放词汇分割方法从RGB图像中检测和分割出物体,并利用深度图和姿态信息将其反投影到全局三维空间,得到3D实例分割结果。然后通过DBSCAN聚类算法将新检测到的实例与已有的实例节点 Nt−1\mathcal{N}_{t-1}Nt−1 合并,更新实例节点 Nt\mathcal{N}_tNt。为了更准确地描述实例节点和边,利用视觉语言模型(VLM)进行推理,输出实例之间的空间关系和房间类型。
占用图
- 定义:占用图 Mt∈RM×M×4\mathcal{M}_t \in \mathbb{R}^{M \times M \times 4}Mt∈RM×M×4 是一个二维的俯视图,用于提供场景的空间信息,如已探索区域、未探索区域和边界等。
- 构建方法:根据RGB-D图像构建,其中 M×MM \times MM×M 定义了地图的大小,分辨率为5厘米。前三个通道分别表示被占用区域、已探索区域和智能体位置,第四个通道则包含了投影的3D实例节点 Nt\mathcal{N}_tNt。占用图在每个导航步骤都会更新。
地标图
- 定义:地标图 Lt={lt,i}\mathcal{L}_t = \{ l_{t,i} \}Lt={lt,i} 用于将场景图和占用图的信息锚定到导航上,离散化导航区域,其中 lt,il_{t,i}lt,i 是从Voronoi节点图中提取的二维位置。
- 构建方法:首先根据关键位置(包括边界位置和实例位置)构建Voronoi图,然后使用广义Voronoi图(GVD)对导航区域进行划分,提取地标图。地标图的更新频率与场景图一致,每10帧更新一次。
认知地图提示
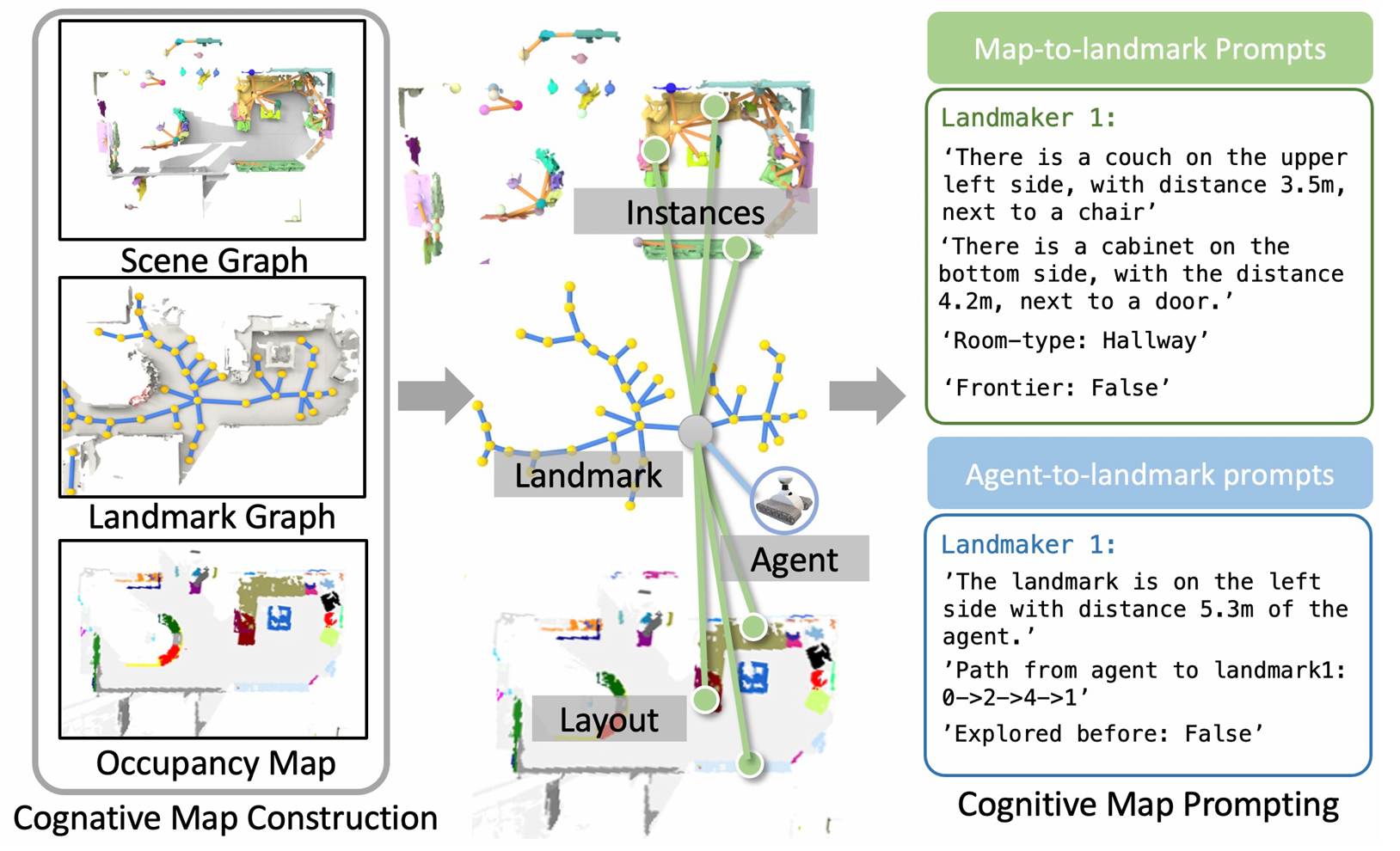
将认知地图 Ct\mathcal{C}_tCt 的知识以自然语言的形式编码,构建以地标为中心的提示,将场景信息和智能体信息 p1:tp_{1:t}p1:t 嵌入到每个地标 lt,il_{t,i}lt,i 中,以便大语言模型(LLM)能够理解和分析。
地图到地标提示
- 内容:对于每个地标 lt,il_{t,i}lt,i,整合场景信息,包括周围物体及其关系、房间类型和边界属性。选择与地标 lt,il_{t,i}lt,i 在场景图 St\mathcal{S}_tSt 中距离在一定阈值范围内的物体节点 Nt,li⊆Nt\mathcal{N}_{t,l_i} \subseteq \mathcal{N}_tNt,li⊆Nt 作为周围物体,并将这些节点的语义信息和空间关系嵌入到提示中,以实现对周围环境的更深入理解。同时,还将房间类型和边界属性附加到地标上。
- 作用:通过这种方式,可以将场景图的结构信息嵌入到提示中,使LLM能够更好地理解周围环境。
智能体到地标提示
- 内容:提示智能体与地标之间的空间关系。对于每个地标 lt,il_{t,i}lt,i,计算智能体到该地标的路径,包括距离和方向信息。此外,还记录该地标是否已经被智能体探索过,以避免重复探索。
- 作用:帮助LLM了解智能体的当前位置和导航历史,从而做出更合理的导航决策。
认知过程建模
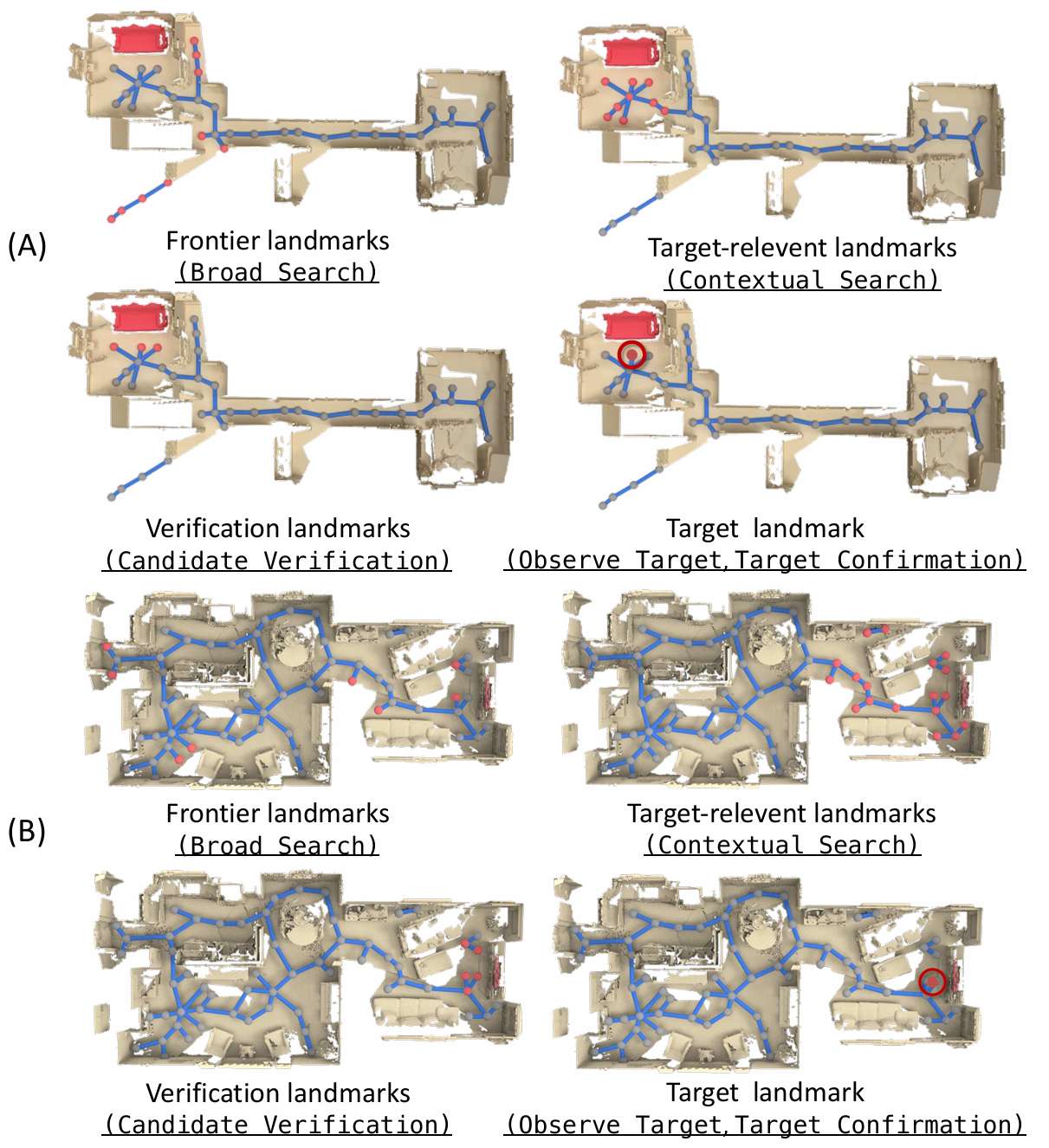
认知状态定义
- 广泛搜索(Broad Search, BS):在没有关注任何与目标物体类别相关的特定物体或房间信息的情况下探索环境。
- 上下文搜索(Contextual Search, CS):调查可能包含目标物体的房间或与目标物体相关的物体周围的地标。
- 观察目标(Observe Target, OT):根据基础模型的检测识别出潜在的目标物体。
- 候选验证(Candidate Verification, CV):导航到其他地标以验证潜在的目标物体。
- 目标确认(Target Confirmation, TC):通过分析周围环境和导航历史,确认潜在物体为目标物体,并直接接近它。
认知状态转换
- 与现有工作不同,CogNav不依赖于阈值来指导决策,而是利用LLM分析来自认知地图的提示,从而确定当前情况下最合适的状态。这种设计提高了性能,并展现出对不同目标类别的适应性。
- 通过LLM的推理,CogNav能够更灵活地应对不同的导航场景,更好地模拟人类在搜索目标物体时的认知过程。
状态引导的导航策略
根据不同的认知状态,设计相应的导航策略,由LLM分析当前以地标为中心的场景信息,并选择合适的地标来引导智能体的导航。
- 具体策略:
- 广泛搜索(BS):选择边界地标作为导航目标,引导智能体探索环境以获取场景信息。
- 上下文搜索(CS):选择与目标物体相关的地标作为导航目标,引导智能体进入可能包含目标物体的房间或区域。
- 观察目标(OT):当检测到潜在的目标物体时,智能体直接接近该物体。
- 候选验证(CV):选择附近的地标作为导航目标,从不同角度观察和验证潜在的目标物体。
- 目标确认(TC):确认目标物体后,直接引导智能体接近目标地标,结束搜索。
- 路径规划:在导航过程中,使用快速行进法(Fast Marching Method, FMM)引导智能体到达目标地标。当智能体到达目标地标且当前认知状态为目标确认时,智能体停止搜索。
实验
实验设置
数据集
- HM3D:一个大规模的3D室内场景数据集,包含20个高保真建筑的重建和2K个目标导航任务的验证集,涵盖6个目标物体类别。
- MP3D:一个包含11个室内场景和1.8K个目标导航任务验证集的3D室内环境数据集,包含20个目标物体类别。
- RoboTHOR:包含1.8K个验证集和15个验证环境,涵盖12个目标物体类别的数据集。
评估指标
- 成功率(Success Rate, SR):智能体成功到达目标物体一定距离内的百分比。
- 路径长度加权成功率(Success weighted by Path Length, SPL):考虑路径长度的成功率,偏好于路径更短的智能体。
- 目标距离(Distance to Goal, DTG):导航结束时智能体与目标物体之间的最终距离。
实现细节
- 每个导航任务的最大步数为500步。
- 智能体的观察数据为640×480的RGB-D图像,深度值范围为0.5米到5米,相机高度为0.9米。
- 智能体每次前进0.25米,旋转角度为30度。
- 占用图配置为960×960,分辨率为0.05米。
- 使用OpenSEED作为2D基础模型进行实例检测和分割。
- 在认知过程中,使用GPT-3作为大语言模型(LLM),GPT-4v作为视觉语言模型(VLM)。
基线方法
- SemExp:基于语义探索的导航方法。
- PONI:基于潜在函数的导航方法。
- ZSON:零样本目标导航方法。
- L3MVN:利用LLM进行视觉目标导航的方法。
- ESC:基于软常识约束的零样本目标导航方法。
- VoroNav:基于Voronoi图的零样本目标导航方法。
- SG-NAV:基于场景图的LLM驱动的零样本目标导航方法。
- OPENFMNAV:利用LLM进行零样本导航的方法。
- TriHelper:零样本目标导航方法。
定量实验
性能比较
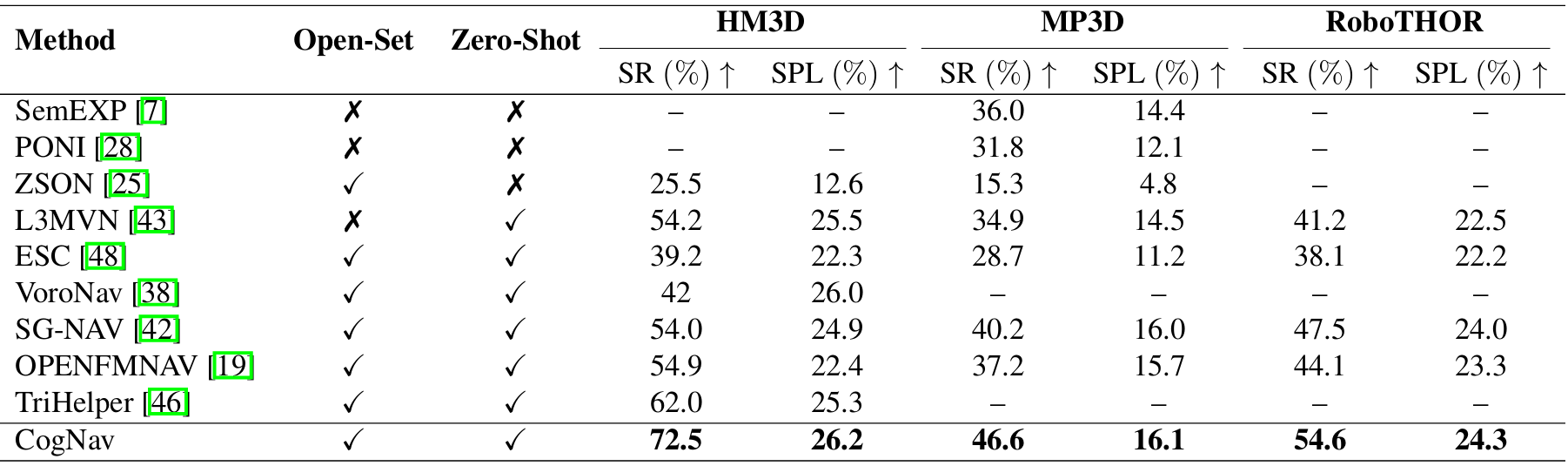
- 在HM3D、MP3D和RoboTHOR数据集上,CogNav均取得了最佳性能,显著优于其他基线方法。
- 在HM3D数据集上,CogNav的成功率(SR)比之前的最佳方法提高了10.5%,路径长度加权成功率(SPL)提高了0.7%,目标距离(DTG)降低了0.5米。
- 在MP3D数据集上,CogNav的成功率(SR)比之前的最佳方法提高了6.4%,路径长度加权成功率(SPL)提高了1.1%,目标距离(DTG)降低了0.2米。
- 在RoboTHOR数据集上,CogNav的成功率(SR)比之前的最佳方法提高了7.1%,路径长度加权成功率(SPL)提高了2.1%,目标距离(DTG)降低了0.5米。
按类别比较

- 在HM3D数据集上,CogNav在所有类别上的成功率均高于其他方法,平均成功率达到了71.3%。
- 在MP3D数据集上,CogNav在大多数类别上的成功率也高于其他方法,尤其是在床、植物、浴缸和沙发等类别上,成功率显著高于其他方法。
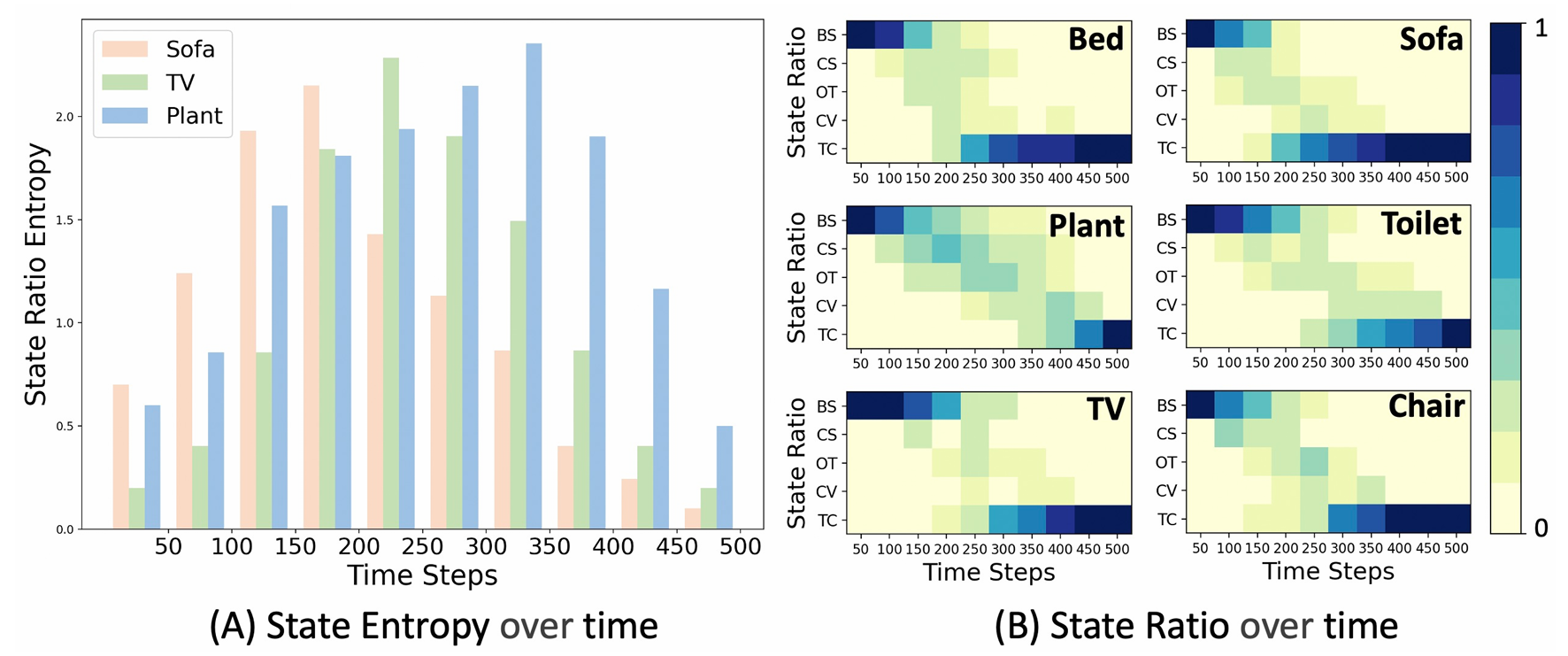
定性实验
导航过程可视化
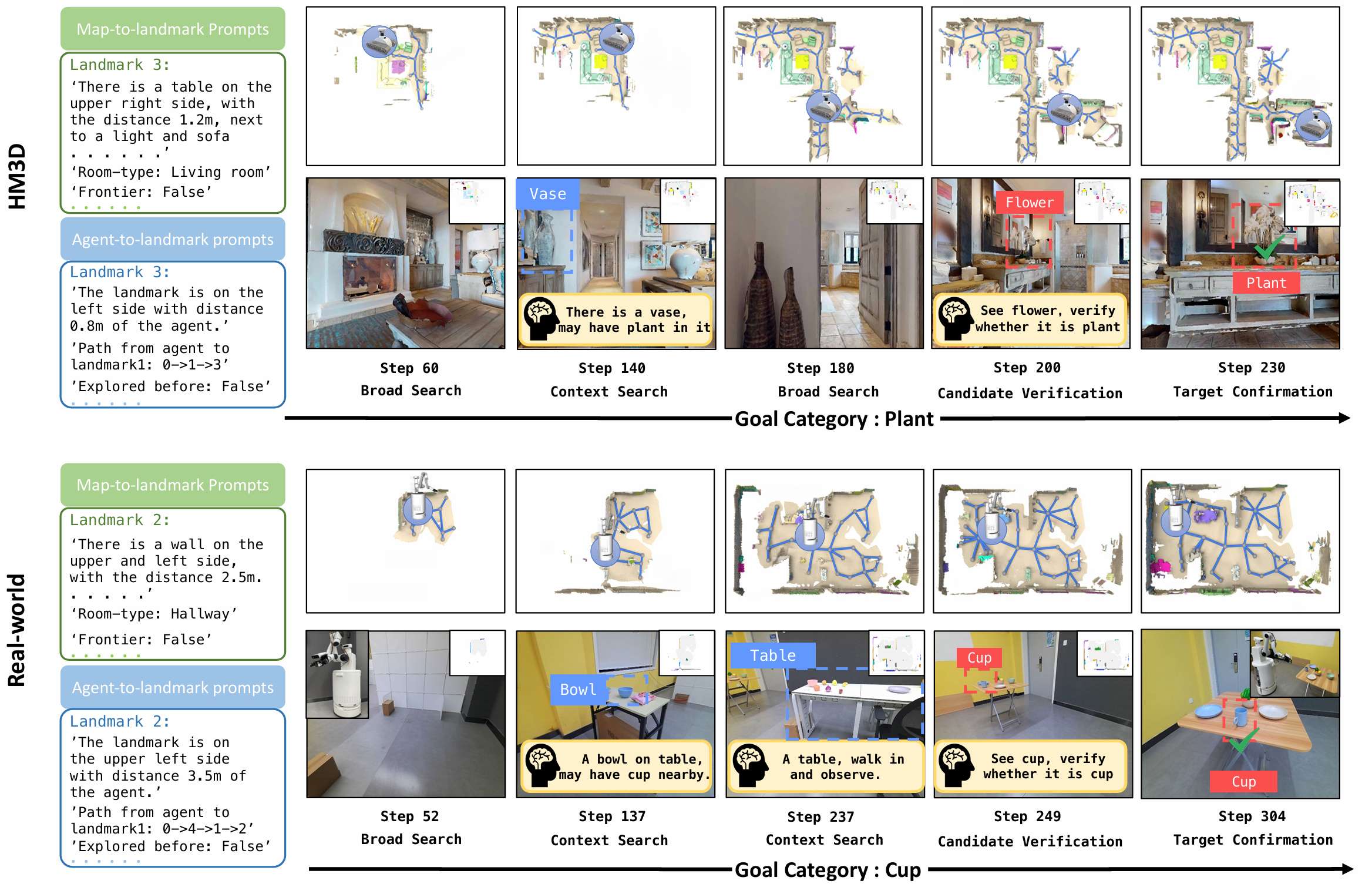
- 提供了CogNav在合成场景和真实世界场景中的导航过程可视化结果。
- 展示了智能体如何在不同状态下利用LLM的分析执行适当的策略找到目标物体。
- 在真实机器人平台上进行了测试,验证了CogNav在真实世界环境中的有效性。

错误纠正能力
- 通过一个示例展示了CogNav在目标物体被误分类时的错误纠正能力。与之前的方法相比,CogNav能够在不同视角下验证目标物体,从而纠正错误。
消融研究
认知状态的影响
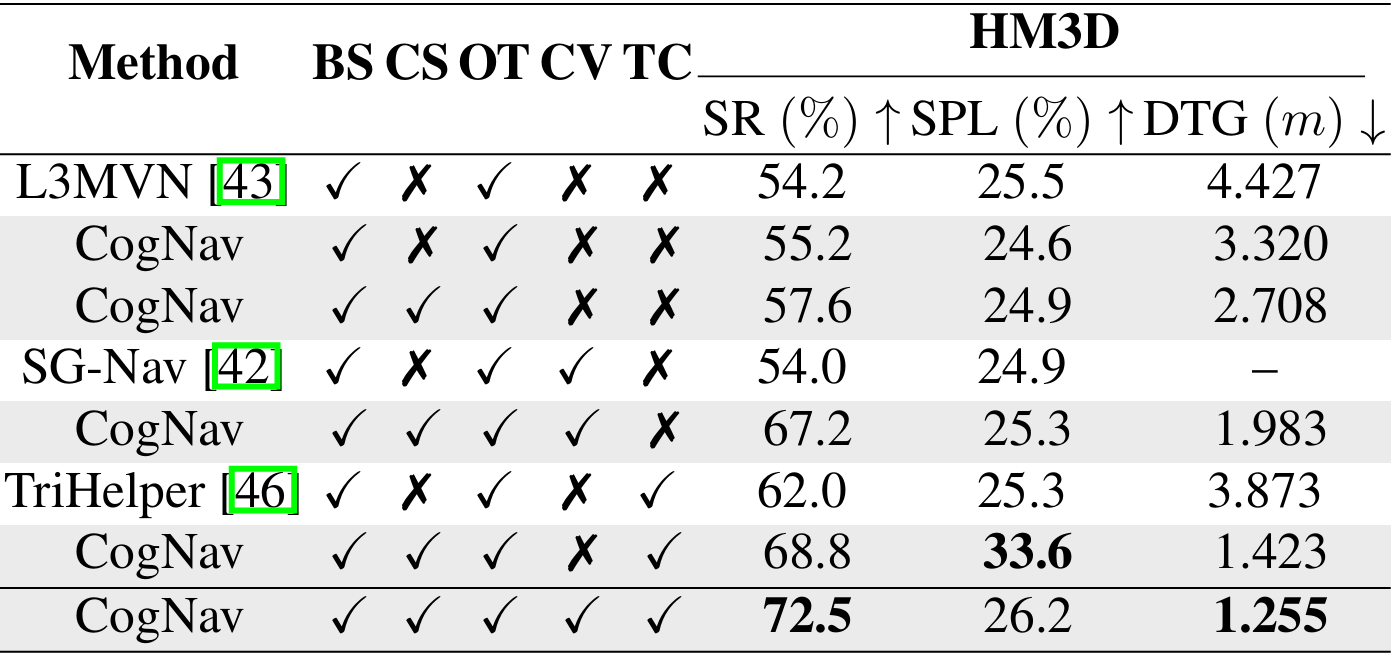
- 通过移除不同的认知状态,验证了每个状态在成功找到目标物体中的重要性。
- 移除候选验证状态(CV)会导致成功率下降3.7%,但路径长度加权成功率(SPL)会增加7.8%,因为智能体需要访问不同视角的目标物体进行观察和确认。
- 结果表明,考虑更多的认知状态可以提高导航性能。
提示组件的影响
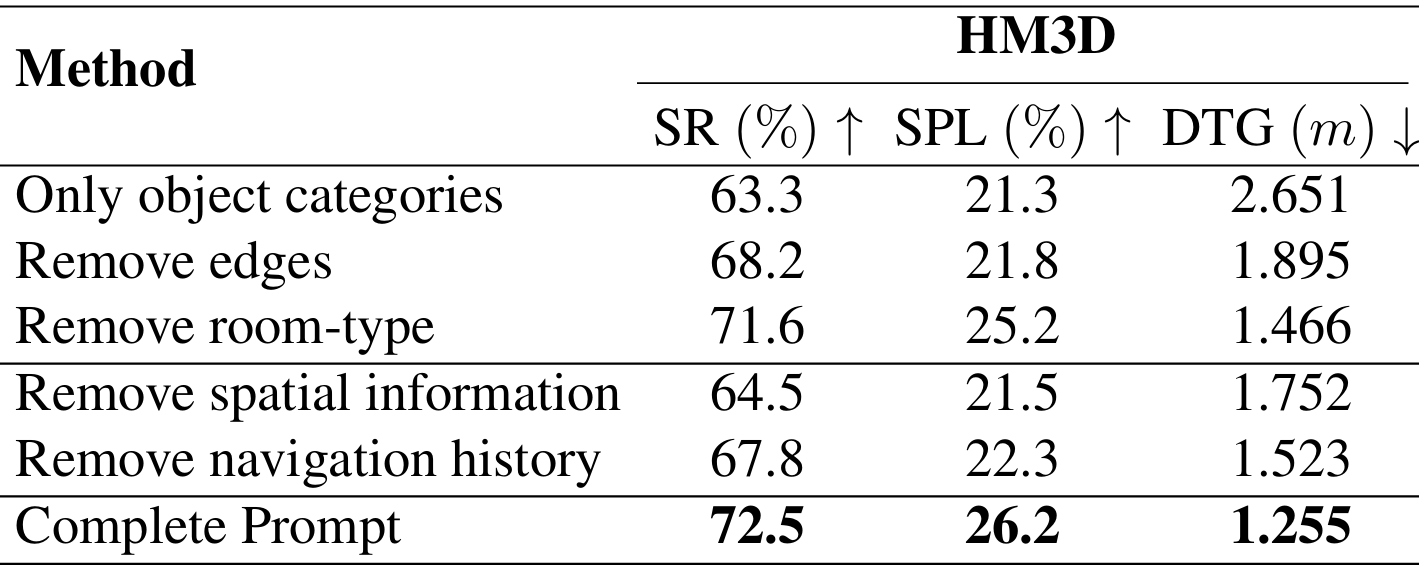
- 通过移除不同的提示组件,验证了每个组件在导航中的有效性。
- 添加带有房间类型的边(edges with room-type)可以显著提高性能,因为它能够提供周围物体和房间之间的关系。
- 移除空间信息和导航历史会降低性能,表明这些信息对于LLM的推理至关重要。
结论与未来工作
- 结论:
- CogNav框架通过模拟人类的认知过程,利用LLMs的强大推理能力,实现了零样本目标导航任务的高效解决,在模拟环境和真实世界环境中均取得了优异的性能,证明了该方法的可行性和有效性。
- 尽管取得了显著成果,CogNav仍存在一些局限性,例如依赖于2D基础模型的检测和分割结果,以及目前仅支持目标物体导航而不支持基于自由形式语言描述或特定导航指令的导航任务。
- 未来工作:
- 未来的工作可以进一步扩展该方法,以处理具有无限输入格式的导航任务,充分发挥LLMs和视觉语言模型(VLMs)的泛化能力。
