零基础-动手学深度学习-13.10. 转置卷积
到目前为止,我们所见到的卷积神经网络层,例如卷积层( 6.2节)和汇聚层( 6.5节),通常会减少下采样输入图像的空间维度(高和宽)。 然而如果输入和输出图像的空间维度相同,在以像素级分类的语义分割中将会很方便(如果是用传统卷积是没法进行像素的分类的)。 例如,输出像素所处的通道维可以保有输入像素在同一位置上的分类结果。
为了实现这一点,尤其是在空间维度被卷积神经网络层缩小后,我们可以使用另一种类型的卷积神经网络层,它可以增加上采样中间层特征图的空间维度。 本节将介绍 转置卷积(transposed convolution) (Dumoulin and Visin, 2016), 用于逆转下采样导致的空间尺寸减小。
13.10.1. 基本操作
感觉上面的描述挺抽象的,沐神写公式更容易看懂一点:
![]()

卷积操作可以被看作是一个线性变换,用矩阵乘法来实现,V 是根据卷积核 W 构造出来的一个稀疏矩阵?如果将稀疏矩阵进行转置会导致维度上变化和原来操作是相反的。
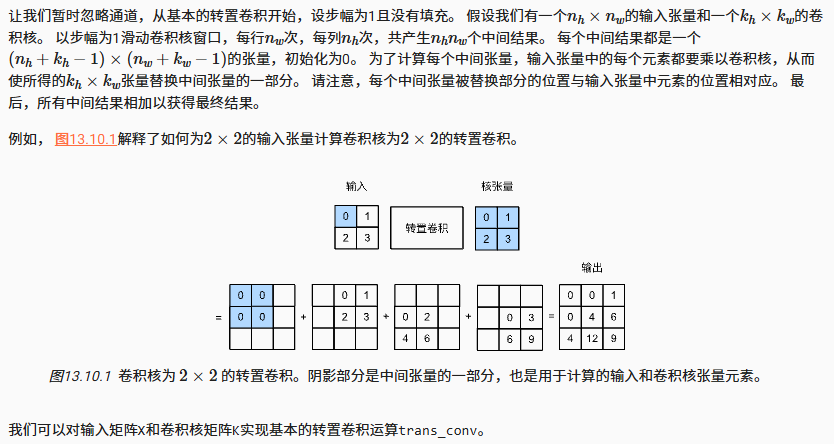
def trans_conv(X,K):h,w = K.shapeY = torch.zeros((X.shape[0]+h-1,X.shape[1]+w-1))for i in range(X.shape[0]):for j in range(X.shape[1]):Y[i:i+h,j:j+w] += X[i,j]*Kreturn Y与通过卷积核“减少”输入元素的常规卷积(在 6.2节中)相比,转置卷积通过卷积核“广播”输入元素,从而产生大于输入的输出。 我们可以通过 图13.10.1来构建输入张量X和卷积核张量K从而验证上述实现输出。 此实现是基本的二维转置卷积运算。
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
trans_conv(X, K)输出:
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
trans_conv(X, K)或者,当输入X和卷积核K都是四维张量时,我们可以使用高级API获得相同的结果:
X, K = X.reshape(1, 1, 2, 2), K.reshape(1, 1, 2, 2)
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, bias=False)
tconv.weight.data = K
tconv(X)输出:
tensor([[[[ 0., 0., 1.],[ 0., 4., 6.],[ 4., 12., 9.]]]], grad_fn=<ConvolutionBackward0>)13.10.2. 填充、步幅和多通道
与常规卷积不同,在转置卷积中,填充被应用于的输出(常规卷积将填充应用于输入)。 例如,当将高和宽两侧的填充数指定为1时,转置卷积的输出中将删除第一和最后的行与列。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=1, bias=False)
tconv.weight.data = K
tconv(X)输出:tensor([[[[4.]]]], grad_fn=<ConvolutionBackward0>)在转置卷积中,步幅被指定为中间结果(输出),而不是输入。 使用 图13.10.1中相同输入和卷积核张量,将步幅从1更改为2会增加中间张量的高和权重,因此输出张量在 图13.10.2中。
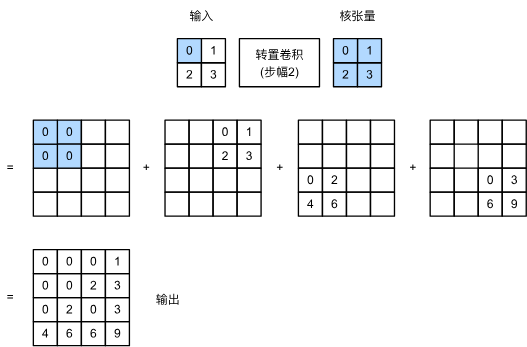
以下代码可以验证 图13.10.2中步幅为2的转置卷积的输出。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, stride=2, bias=False)
tconv.weight.data = K
tconv(X)输出:tensor([[[[0., 0., 0., 1.],[0., 0., 2., 3.],[0., 2., 0., 3.],[4., 6., 6., 9.]]]], grad_fn=<ConvolutionBackward0>)
X = torch.rand(size=(1, 10, 16, 16))
conv = nn.Conv2d(10, 20, kernel_size=5, padding=2, stride=3)
tconv = nn.ConvTranspose2d(20, 10, kernel_size=5, padding=2, stride=3)
tconv(conv(X)).shape == X.shape输出:True13.10.3. 与矩阵变换的联系
转置卷积为何以矩阵变换命名呢? 让我们首先看看如何使用矩阵乘法来实现卷积。 在下面的示例中,我们定义了一个3*3的输入X和2*2卷积核K,然后使用corr2d函数(卷积最简单版本操作)计算卷积输出Y。
X = torch.arange(9.0).reshape(3, 3)
K = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
Y = d2l.corr2d(X, K)
Y输出:tensor([[27., 37.],[57., 67.]])
接下来,我们将卷积核K重写为包含大量0的稀疏权重矩阵W。 权重矩阵的形状是(4,9),其中非0元素来自卷积核K。
def kernel2matrix(K):k, W = torch.zeros(5), torch.zeros((4, 9))k[:2], k[3:5] = K[0, :], K[1, :]W[0, :5], W[1, 1:6], W[2, 3:8], W[3, 4:] = k, k, k, kreturn WW = kernel2matrix(K)
W输出:
tensor([[1., 2., 0., 3., 4., 0., 0., 0., 0.],[0., 1., 2., 0., 3., 4., 0., 0., 0.],[0., 0., 0., 1., 2., 0., 3., 4., 0.],[0., 0., 0., 0., 1., 2., 0., 3., 4.]])逐行连结输入X,获得了一个长度为9的矢量。 然后,W的矩阵乘法和向量化的X给出了一个长度为4的向量。 重塑它之后,可以获得与上面的原始卷积操作所得相同的结果Y:我们刚刚使用矩阵乘法实现了卷积。
Y == torch.matmul(W, X.reshape(-1)).reshape(2, 2)输出:
tensor([[True, True],[True, True]])同样,我们可以使用矩阵乘法来实现转置卷积。 在下面的示例中,我们将上面的常规卷积2*2的输出Y作为转置卷积的输入。 想要通过矩阵相乘来实现它,我们只需要将权重矩阵W的形状转置为(9,4)。
Z = trans_conv(Y, K)
Z == torch.matmul(W.T, Y.reshape(-1)).reshape(3, 3)输出:
tensor([[True, True, True],[True, True, True],[True, True, True]])