MySQL索引篇---B+树在索引中的工作原理
要想弄清索引在MySQL中的工作原理,首先要从MySQL的存储结构说起,也就是关于页的内容
1.什么是页
在一个数据库中创建一张表时,此时就会生成一个.ibd文件,一张表对应一个.ibd文件,而页就是.ibd文件中最重要的结构体,在MySQL中,页是内存与磁盘交互的最小单元,一个页的默认大小为16KB,且每次内存与磁盘交互是都至少读取一页,且在磁盘中,每个页内部的地址都是连续的,之所以这样做,因为根据局部性原理,将来要使用的数据的位置与当前使用的数据的位置大概率是相邻的,所以一次性将一页的数据加载到内存中,如果将来要使用的数据恰好也存储在这个页中,此时就直接从这个内存中读取即可,这就可以减少磁盘IO的次数,从而提高查询效率
且一个页中即使没有数据,也会使用16KB的空间来存储,且也会与索引中的B+树的节点对应
2.页的基本结构
在MySQL中,页的种类有很多,最常用的就是用来存储数据的数据页和存储索引的索引页,但是无论是哪种类型的页,都会包含页头和页尾这两部分,且主题用数据行来填充
数据页的基本结构如下图
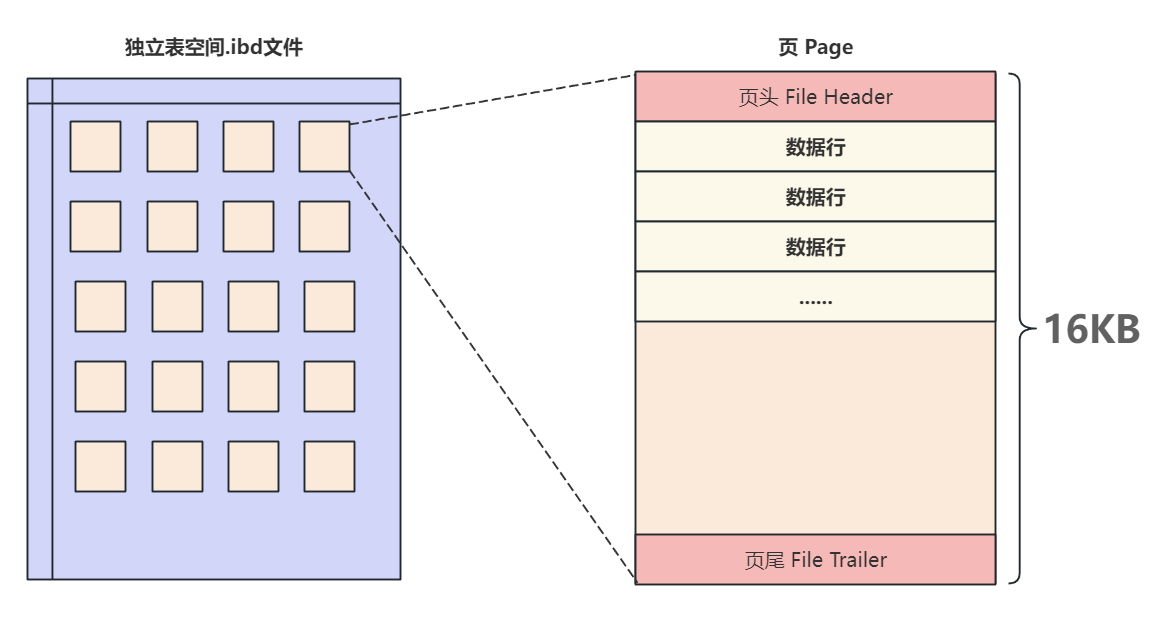
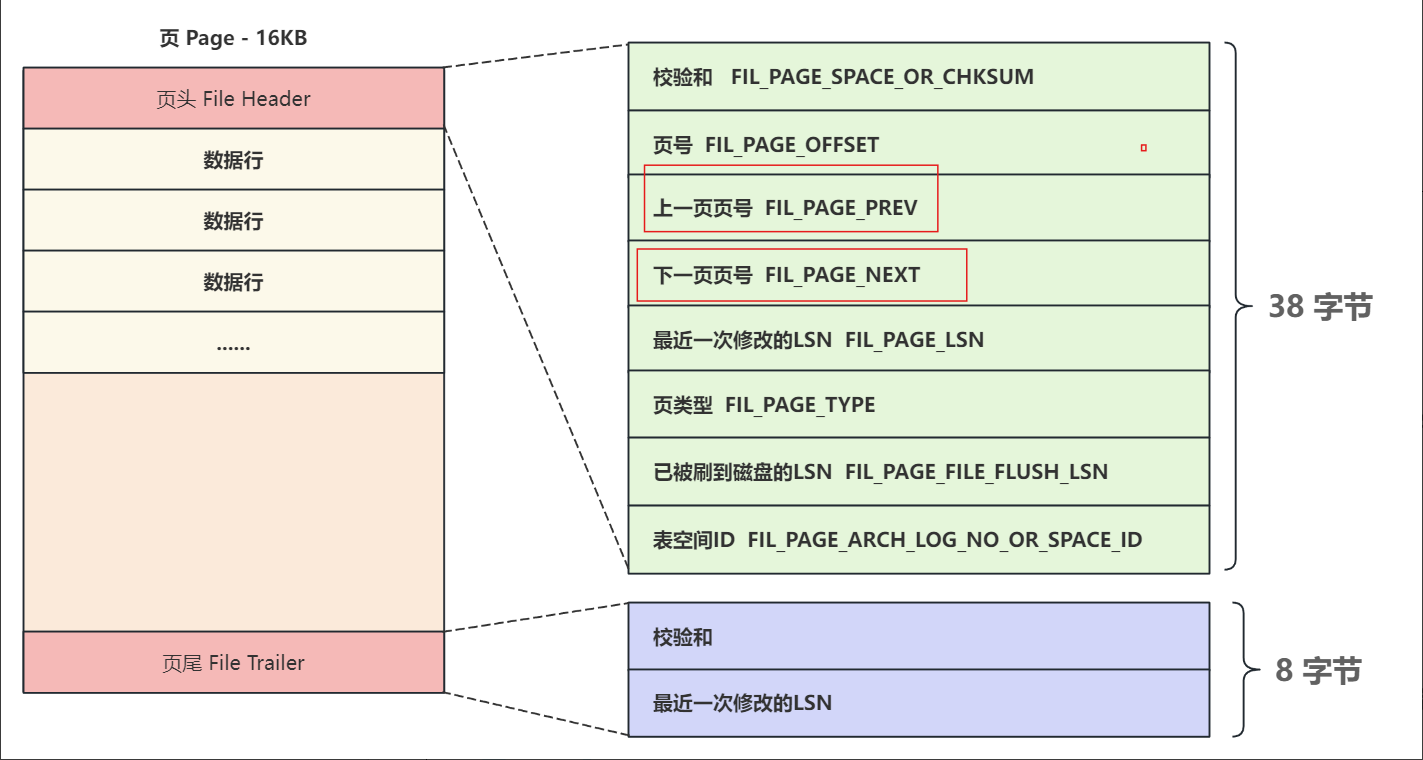
2.1 页文件头和页文件尾
关于这部分的内容,现在只需要关注页头中的上一页页号和下一页页号即可,因为每个页中的页头都记录了上一页页号和下一页页号,通过这两个属性就可以将页与页之间连接了起来,从而形成了双向链表
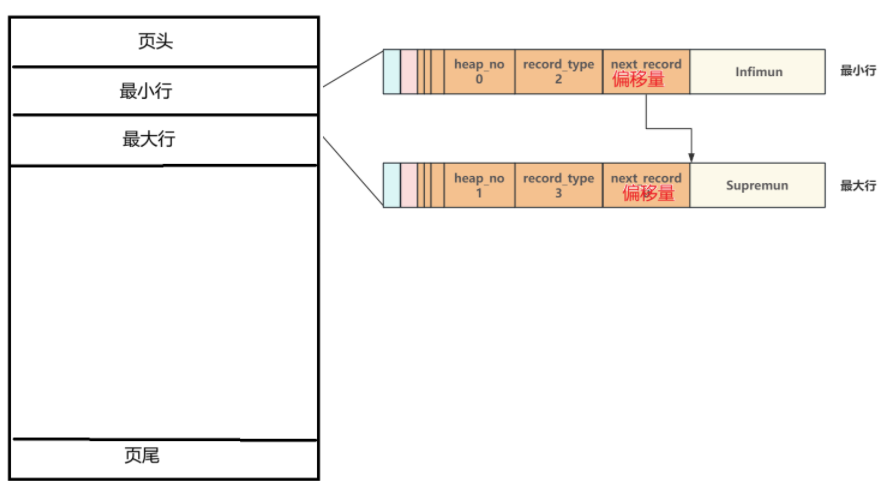
2.2 页主体
页主体部分是存储数据的主要部分,每当创建一个新页时,都会自动分配两个行,一个是最小行,另一个是最大行,这两行并不存储真实的数据,而是作为数据行链表的头和尾,在页主体中,每一个数据行(包括最大行和最小行)都有保存下一行数据行的偏移量区域next_record,通过这个偏移量就可以将页主体中的所有数据行以单向链表的形式链接起来
下图是一个新页的结构图
当往一个新页中插入数据时,也会往最小行和最大行之间插入对应的数据行,当有更多的数据插入时,就会按照插入数据的主键值的大小进行连接,从而形成单向链表
如下图
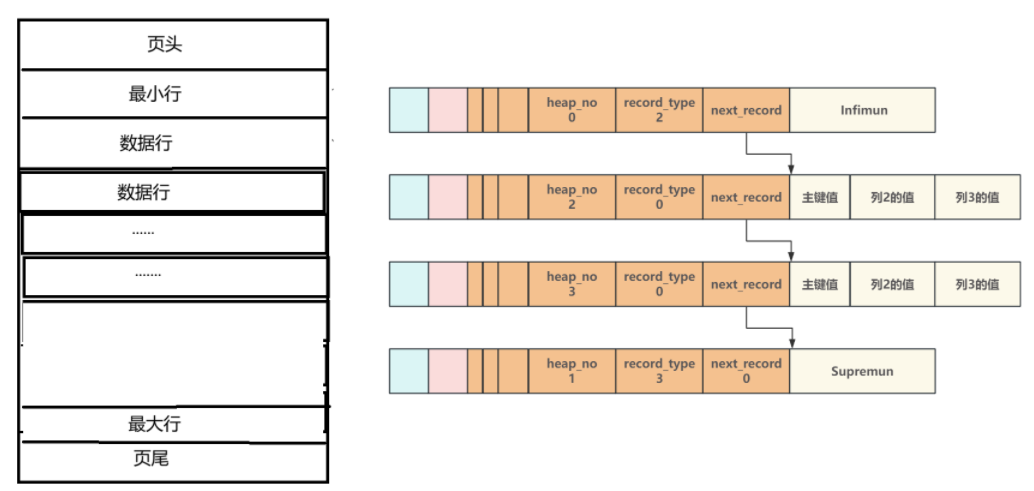
可是由于数据行还是以单向链表的形式连接起来的,这样查询的时间复杂度不还是O(N),所以MySQL在这一部分还做了一部分的优化,也就是页目录
2.3页目录
在讲页目录之前,首先要知道页主体中的数据行是会进行分组的,最小行默认为一组,且最大行永远在最后一组,除了最小行这一组,其他组中最多可以包含的8条数据行,如果这超过8个数据行,此时就会分裂出一个新的组,如下图
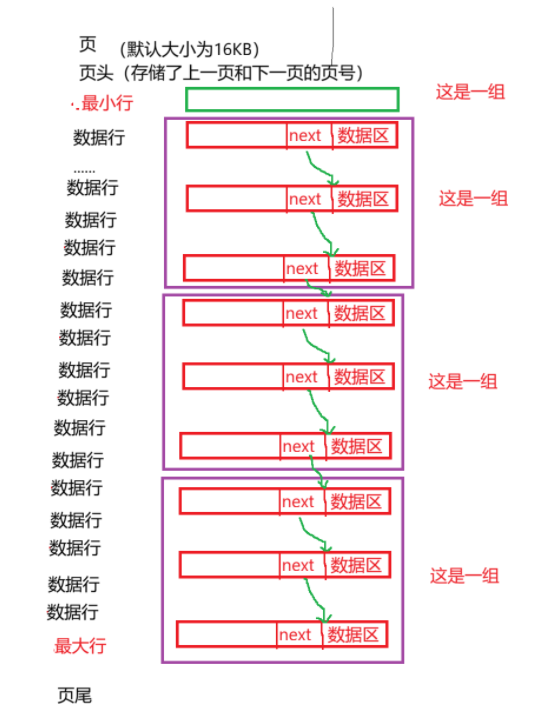
知道了分组的概念之后,此时就来介绍页目录
页目录就是用来提高查询效率的,页目录中有一个叫槽的东西,每当页主体中的数据行进行了分组之后,页目录中就会创建一个槽,槽的数量与组的数量是一致的,槽中会指定每一组中的最后条记录,同时保存这条数据行的主键值。
有了槽之后,查询一条记录的过程就变为:
假设我们要查找主键值为6的数据行,查询步骤如下
首先要找到这条记录所在的页,然后通过主键值去找到对应的槽,然后根据槽去找对应的分组,接着就可以在分组中去查询这条记录的
所以,通过页目录中的槽,在查询某一条记录时,就在也不用一一遍历页主体中的所有数据行了。
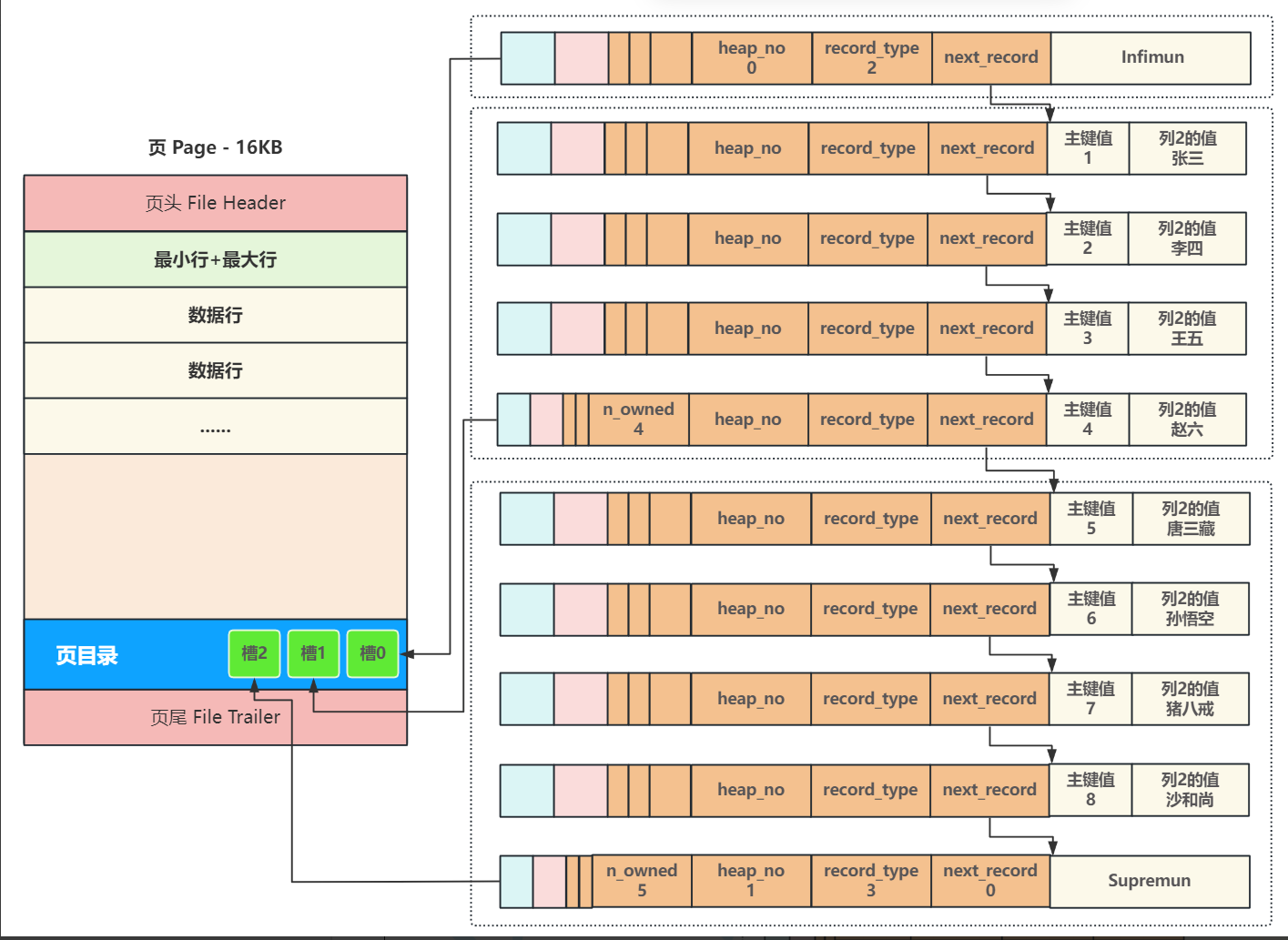
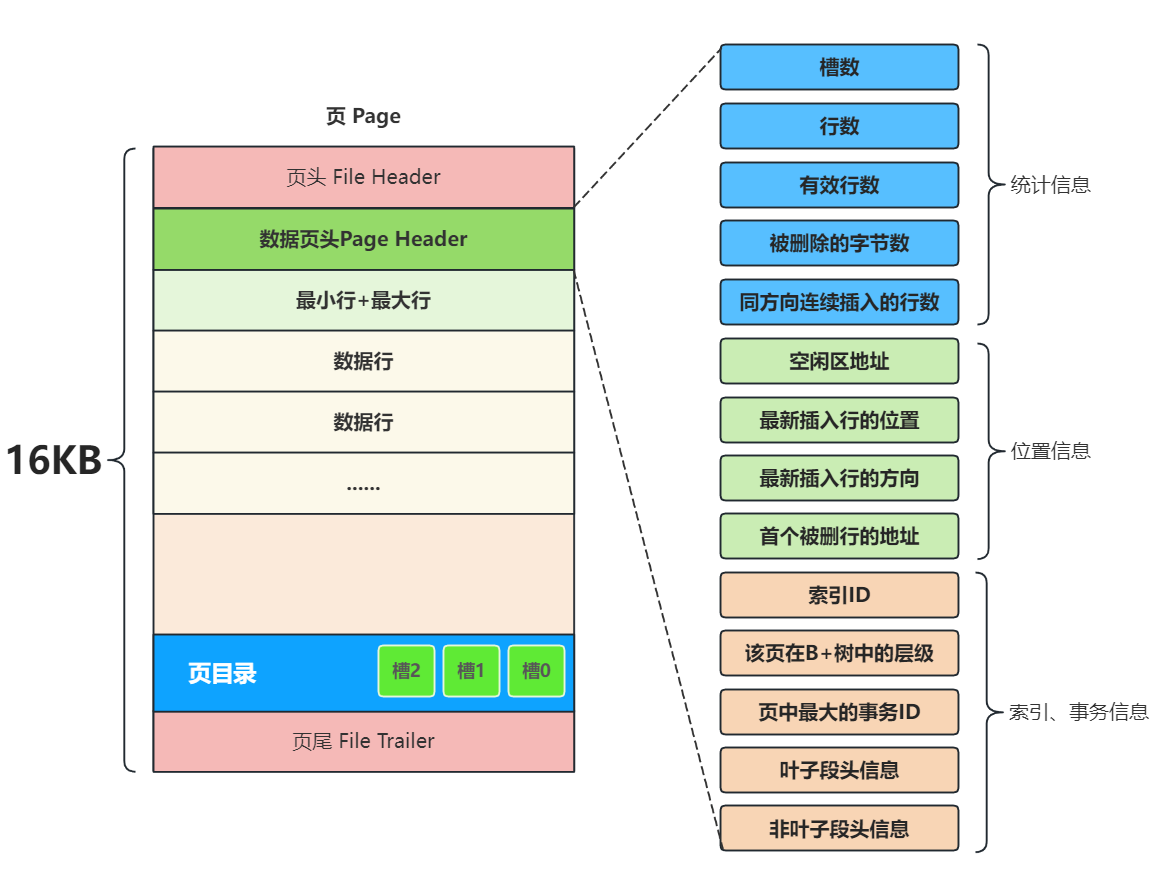
2.4数据页头
数据页头中记录了当前页保存数据的相关信息,如下图,不详细介绍了
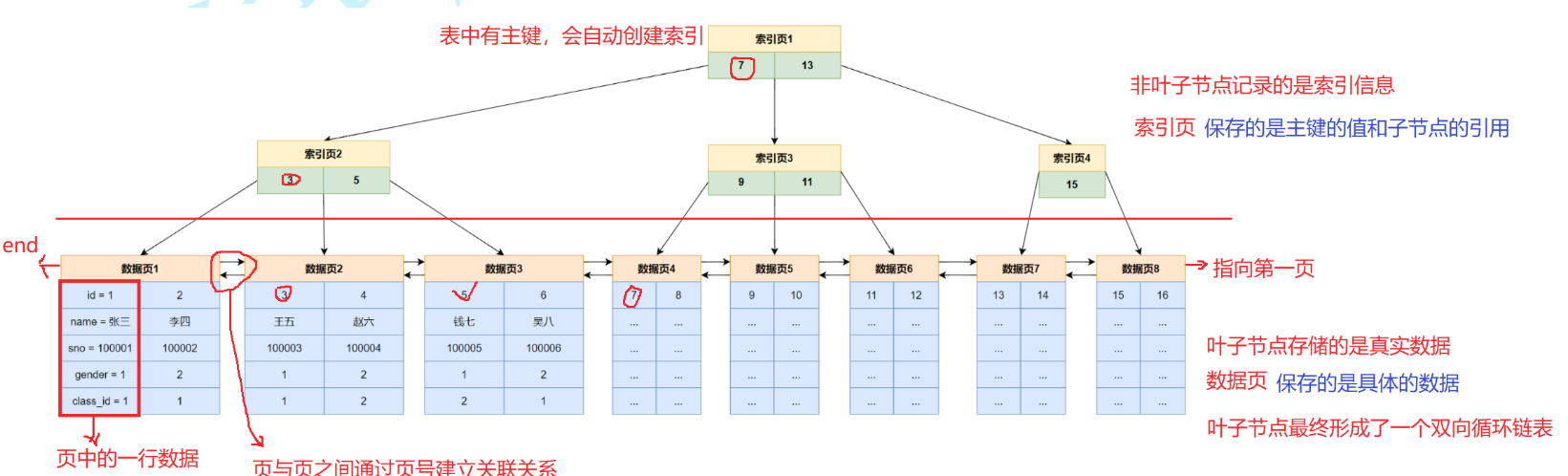
3.B+树在索引中的工作原理
首先,会根据要查询数据的主键值去B+树中找到对应的索引页并将索引页加载到内存中,在根据得到的索引页去找到要查询数据所在的数据页并将其加载到内存中,最终在页中查询数据时,会根据主键值去与页目录中存储的主键值去比较找到对应的槽,由于槽和对应一个组,所以根据槽很快就可以定位到该数据在页主体中的那一个分组中,找到对应的分组后,就可以在该组去取对应的数据
举个例子,如下图
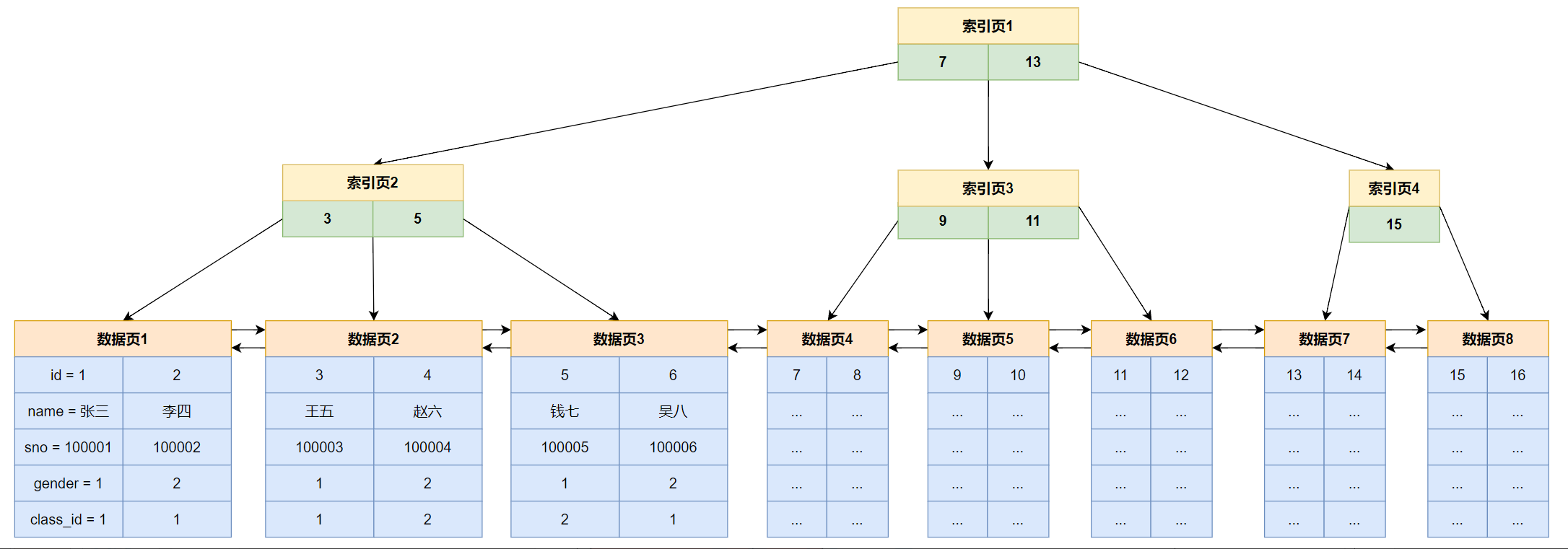
假设要查找id为5的记录,完整的过程如下:
首先,判断B+树根节点的索引记录,也就是索引页1,根据5<7,就可以判断id=5的记录在左子树中,然后找到索引页2,根据id,在索引页2中找到id==5的索引记录,然后根据索引记录去找到对应的数据页并将数据页加载到内存中,接着就去对应的数据页去对应的记录即可
总结图如下
4.计算三层树高的B+树可以存放多少条记录(理论上的)
一个数据页的默认大小为16KB,假设数据页中的一条记录的大小为1KB,那么一个数据页中就可以存储16条记录
一个索引页中存的是主键值和子节点的引用,假设主键类型为bigint类型,大小为8byte,下一页地址的大小为6byte,则此时一天索引记录占14byte,此时一个索引页中可以存储1024*16/14=1170条记录,则理论上一个三层B+树在理论上可以存1170*1170*16=21902400条记录
总结如下图
