code2prompt 快速生成项目 Markdown 文档(结合大模型进行问答)
在做整个项目时,常常需要对项目代码进行整体梳理,方便记录、复盘和向大模型描述。手工去复制粘贴既低效又容易遗漏。这里介绍一个非常实用的小工具:code2prompt。
什么是 code2prompt?
code2prompt 是一个用于将代码项目转换为适合大语言模型(LLM)阅读的提示文本(Prompt)的工具。
它能自动扫描代码文件、保留结构(目录 + 文件内容)、添加语法高亮标记,并生成一个结构化的 .txt 或 .md 文件,并可选择性地加入行号。方便复制粘贴到 ChatGPT、Claude、通义千问等模型中使用。
基本用法
使用前提: code2prompt 要求 Python 3.9 或更高版本。
这是因为它使用了 Python 3.9 引入的类型标注新语法(如
list[str]),在 Python 3.8 及以下版本中会报错:
TypeError: 'type' object is not subscriptable推荐使用 Python 3.10 或 3.11,以获得最佳兼容性和性能支持。
使用 pip 安装:
pip install code2prompt安装完成后,即可在命令行中直接使用 code2prompt 命令。你应该能看到帮助信息输出,表示安装成功。
code2prompt --help最常见的命令格式是:
code2prompt -p <项目路径> -o <输出文件路径> [参数]示例:
code2prompt -p D:\Project\SR\SR_2x -o D:\Project\SR\SR.md --line-number这条命令表示:
-p:输入路径,指定要解析的项目目录;-o:输出路径,指定生成的 Markdown 文件位置;--line-number:启用代码行号功能。该参数会在打包代码时自动添加行号标记,使AI在解析代码或回答问题时能准确定位到具体行数,有助于提升沟通效率!
执行后,会出现下面的成功提示。

在输出目录中会得到一个完整的md文件,里面包含项目代码和行号,直接可以交给大模型进行问答。
举例:项目结构如下图:
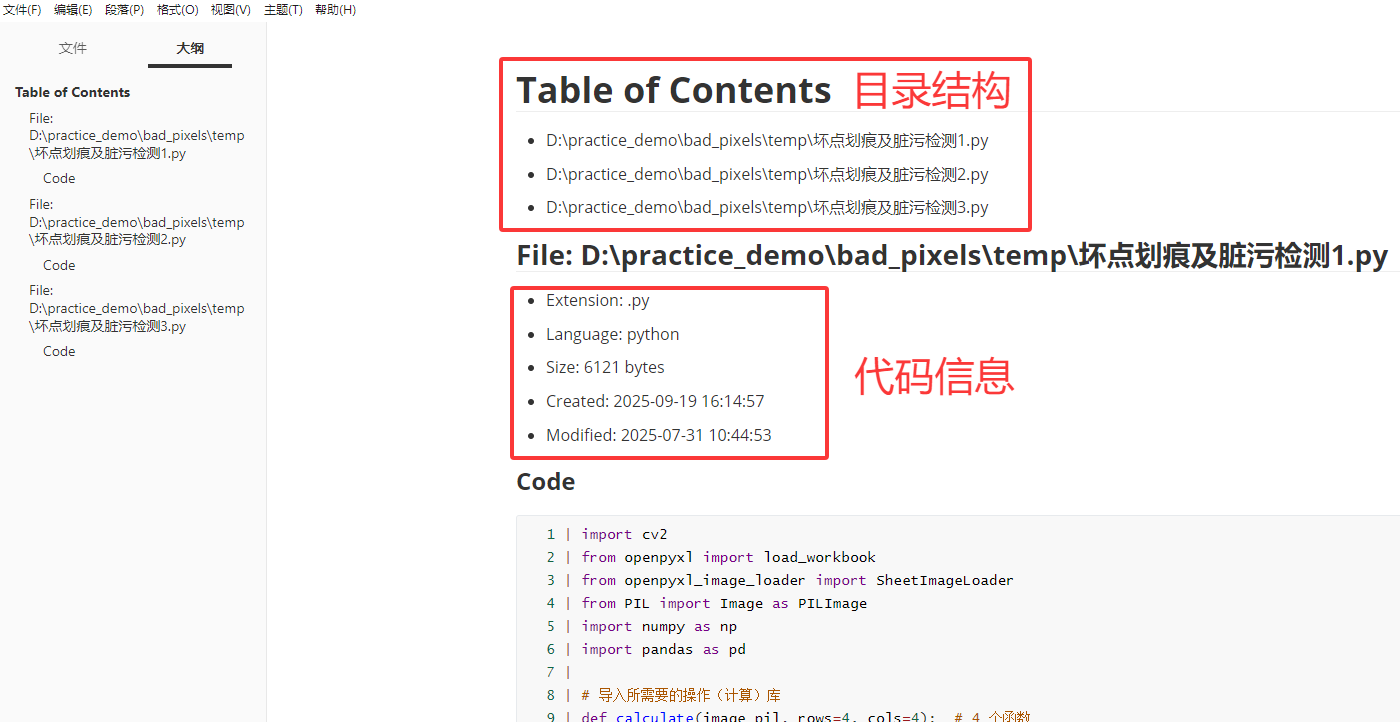
输出文件内容如下图:
常用参数说明
以下是一些常见参数及作用:
| 参数 | 说明 | 示例 |
|---|---|---|
-p, --path | 指定要扫描的项目根目录路径 | --path ./src |
-o, --output | 指定输出文件路径(默认打印到终端) | --output prompt.txt |
--copy, -c | 将生成的 prompt 直接复制到剪贴板(不写文件) | --copy |
--extensions, -e | 指定要包含的文件扩展名(多个用逗号分隔) | --extensions .py,.js,.ts |
--exclude, -x | 指定要排除的目录或文件模式(支持通配符) | --exclude node_modules,__pycache__,*.log |
--ignore-git, -g | 忽略 .gitignore 中定义的规则(默认自动读取) | --ignore-git |
--line-number, -l | 在代码块中添加行号(便于讨论具体行) | --line-number |
--language | 强制指定所有文件的语言类型(用于语法高亮) | --language python |
--max-size | 设置单个文件最大大小(KB),超过则跳过 | --max-size 500(默认 500KB) |
--template | 使用自定义模板文件(Jinja2 格式) | --template my_template.md |
--token-count | 显示生成内容的预估 token 数(适配 GPT、Claude 等) | --token-count |
--model | 指定目标 LLM 模型以计算 token(如 gpt-4, claude-3) | --model claude-3-opus |
--include-hidden | 包含隐藏文件(以 . 开头的文件) | --include-hidden |
--verbose, -v | 显示详细处理过程(调试用) | -v |
使用场景
大模型协作
把项目转成 Markdown,交给 ChatGPT 或 Claude,快速提问“帮我解释某个模块的逻辑”。项目归档
把代码结构和实现保留下来,生成可读文档,方便团队成员理解。调试/复盘
配合行号定位,可以快速跳转到具体代码片段,提升调试效率。
将 Markdown 输入 ChatGPT
在对话中设置上下文,比如:
这是我的xxx项目完整代码,请作为上下文,回答我后续的问题。
这样 ChatGPT 或者其他大模型就能记住整个项目结构。
有了上下文之后,可以更方便的进行提问,不用频繁复制代码或上传文件进行交互。