One-Rec semantic-ID表征
目录
2.1. Tokenizer
2.1.1. Aligned Collaborative-Aware Multimodal Representation
RQ-Kmeans构造tokenization:
先来看下section 4.4
重建损失:
标记分布熵(Token Distribution Entropy)
4.2.2 语义标识符输入表征
附录例子
One-Rec对比集联推荐:可以在reward-model的指导下进行端到端的建模
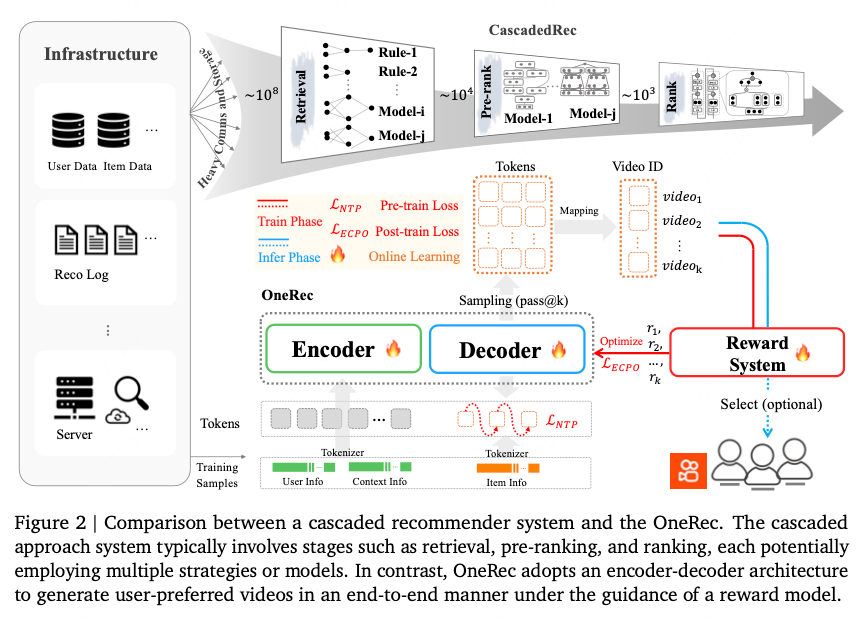
2.1. Tokenizer
OneRec tokenizes items into coarse-to-fine iao zheng IDs using a reduced and fixed vocabulary, enabling knowledge transfer among similar items and better generalization to new items.
然而之前专门根据context features来生成语义ID,但是忽视了协同信号并且产生局部最优重构质量。本文通过整合协同信号和多模态特征,利用RQ-means来生成高质量分层语义IDs。
2.1.1. Aligned Collaborative-Aware Multimodal Representation
-
多模态输入:
-
输入包括:视频标题(caption)、标签(tag)、自动语音识别文本(ASR)、光学字符识别文本(OCR)、封面图像(cover image)以及5个均匀采样的视频帧。
-
这些输入被馈送到 miniCPM-V-8B 模型(一个多模态大语言模型)中处理,生成 1280个token向量,每个向量的维度为512(即 M∈R1280×512M)。
-
-
特征压缩:
-
使用 Querying Transformer (QFormer) 对1280个token进行压缩。
-
QFormer 使用
个可学习的查询token通过交叉注意力和前馈网络(FFN)进行多轮交互(共4层),生成M的压缩版本:
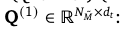
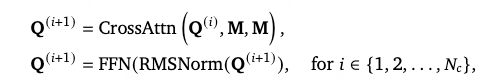
-
-
Item Pairs. : 我们通过以下方式构建高质量项目配对数据集D𝑝𝑎𝑖𝑟:
-
用户-项目检索:针对每位用户,选取一个被正面点击的目标项目,并将其与该用户最近历史正面点击中协同相似度最高的项目进行配对;
-
项目-项目检索:将展现高相似度分数(如Swing相似度算法(Yang et al., 2020))的项目进行配对。
-
-
Item-to-Item Loss and Caption Loss. 引入双重训练目标:
-
项目间对比损失函数:使协同相似的视频配对(𝑖, 𝑗)∈D𝑝𝑎𝑖𝑟的表征在向量空间中对齐,从而捕捉用户行为模式;
-
描述文本损失函数:使用LLaMA3(Dubey et al., 2024)作为解码器对视频描述文本执行下一词元预测,以此防止模型产生幻觉现象,同时保持其对内容的理解能力。
-
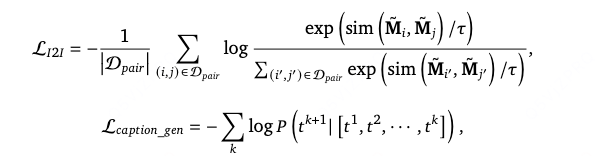
-
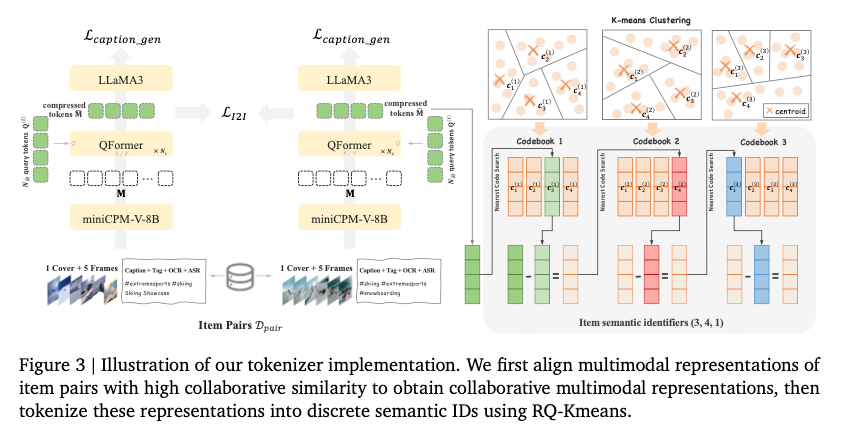
RQ-Kmeans构造tokenization:
其采用残差量化以从粗到细的方式生成语义ID。通过在残差上直接应用K-means来构造codebooks。
具体过程:
第一层的残差就是R(第一层,其值就是Mi), 对其进行k-means聚类得到聚类中心,作为codebook。对item i计算最近中心的index-> s_i, 计算R-i与最近聚类中心的残差作为下一层的输入R_{l+1},再对其进行聚类。。。

每个item v通过L-t个从粗到细的语义标识符表示(每层的聚类中心)

先来看下section 4.4
我们采用三项指标全面评估分词方法的性能,涵盖准确性、资源利用率和分布均匀性三个维度:
-
重建损失:衡量离散标记重建原始输入的准确性,反映模型保留输入数据的保真度
-
码本利用率(Zhu等人,2024):评估codebook中向量的使用效率,体现模型利用可用资源表征数据的有效性
-
标记分布熵(Bentz和Alikaniotis,2016):基于香农熵量化标记分布的均匀性,揭示模型标记分配的多样性与平衡性(是每层K-means的聚类中心吗)
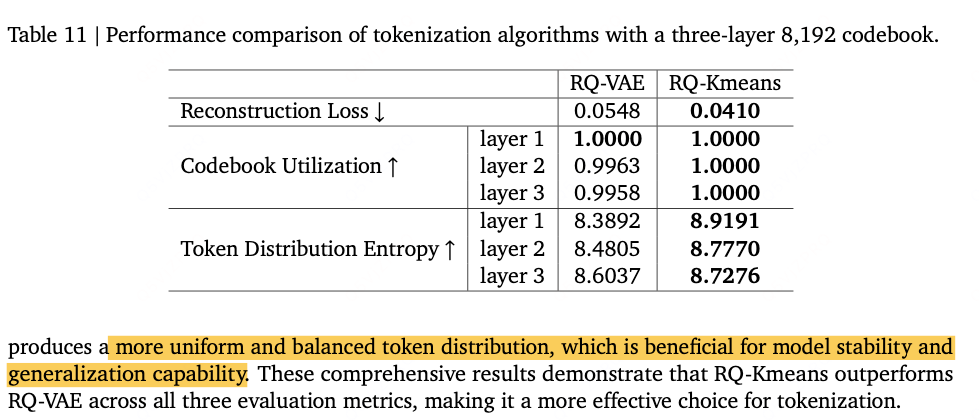
如表11所示,与RQ-VAE相比,RQ-Kmeans的重建损失降低25.18%,在保持输入信息方面展现出更高精度。同时,RQ-Kmeans在所有三层均实现完美利用率(1.0000),表明码本资源效率达到最优,而RQ-VAE在第二、三层的利用率略低。此外,RQ-Kmeans在所有三层均展现出比RQ-VAE更高的熵值,分别显著提升6.31%、3.50%和1.44%,这表明RQ-Kmeans能实现更均匀的标记分布。
重建损失:
计算原理与步骤
重建损失的计算通常遵循以下流程:
-
编码(Encoder):
-
输入:原始的、稠密的(dense)数据表示(在您的场景中,很可能是视频的Embedding向量)。
-
过程:分词器(如RQ-VAE或RQ-Kmeans)将这个输入向量映射为一组离散的标识符(Token IDs)。
-
输出:一组离散的Token序列,例如
[ token_1, token_2, ..., token_n ]。
-
-
解码(Decoder):
-
输入:上一步得到的离散Token序列。
-
过程:分词器的解码器部分根据这些Token,从码本(Codebook)中查找对应的向量表示,并将它们组合起来。
-
输出:重建后的向量,即试图尽可能接近原始输入向量的一个近似值。
-
-
计算损失(Loss Calculation):
-
现在,将原始输入向量 与 重建后的向量 进行直接比较。
-
最常用的方法是计算它们之间的均方误差(Mean Squared Error, MSE)。
-
公式:
Reconstruction Loss = MSE(Original_Input, Reconstructed_Output) -
这个MSE值越小,说明重建后的数据与原始数据越接近,分词器的保真度(Fidelity) 就越高,信息损失就越少。
-
标记分布熵(Token Distribution Entropy)
的计算源于信息论,它用于量化模型输出标记(Tokens)分布的均匀性或随机性。
其核心思想是:一个健康的、能力强大的模型应该能够多样化地使用其整个词汇表(码本),而不是反复使用少数几个熟悉的标记。
计算公式
标记分布熵通常使用香农熵(Shannon Entropy) 公式进行计算。对于一个离散随机变量 $X$(在这里就是码本中的每一个可能的标记),其熵 $H(X)$ 的计算公式为:
其中:
-
$n$:是码本的大小(即一共有多少个不同的标记)。在您的RQ中,这可能对应某一层的码本大小。
-
$x_i$:表示码本中的第 $i$ 个标记。
-
$P(x_i)$:是第 $i$ 个标记在整个数据集或大量样本中被使用到的概率(即频率)。
-
$\log_b$:通常取自然对数($b = e$,此时单位为奈特nats)或以2为底的对数($b = 2$,此时单位为比特bits)。在机器学习中,两者都很常见,只要在比较时使用同一标准即可。
-
公式前的负号是为了确保最终的熵值为正。
计算步骤:
-
收集数据:使用训练好的分词器(如RQ-VAE或RQ-Kmeans)对大量的输入数据(视频embedding)进行编码,生成海量的语义ID序列。这个过程如图Fig. 3所示。
-
统计频率:对于码本中的每一个标记(例如,对于第一层码本,有8192个可能的标记),统计它在所有生成的语义ID中出现的次数。
-
例如,标记
”101“出现了 1,000,000 次。 -
标记
”2047“出现了 50 次。
-
-
计算概率:将每个标记的出现次数除以所有标记出现的总次数,得到每个标记的使用概率 $P(x_i)$。
-
$P(x_i) = \frac{\text{标记 } x_i \text{ 的出现次数}}{\text{所有标记的出现总次数}}$
-
-
代入公式计算:将每个标记的概率 $P(x_i)$ 代入香农熵公式,求和得到最终的熵值 $H(X)$。
在您的Table 11中,RQ-Kmeans在所有三层上都显示出比RQ-VAE更高的熵值,这意味着:
-
分布更均匀:RQ-Kmeans生成的标记,其频率分布比RQ-VAE更平坦、更均匀。没有某些标记被极端频繁地使用,也没有某些标记被完全冷落。
-
资源利用率高:更高的熵与您观察到的完美码本利用率(1.0000) 是高度一致的。它表明模型几乎100%地充分利用了码本中的所有向量来表达信息,没有资源浪费。
-
模型能力更强:一个熵值过低的系统,意味着它可能只重复使用少数几个“安全”的标记,这表明模型模式坍塌(Mode Collapse) 或表达能力有限。而RQ-Kmeans的高熵表明它更具创造性、多样性和鲁棒性,能够根据不同的输入灵活地选择最合适的标记进行组合。(可以通过这种方式来衡量模型tokenizer的合理性与性能)
总结来说:标记分布熵是一个至关重要的诊断工具。它从信息论的角度证明了您提出的 RQ-Kmeans 方法不仅在精度(更低的重建损失)和效率(更高的码本利用率)上更优,在生成结果的多样性和资源使用的健康度上也超越了传统的RQ-VAE方法。这为其在后续大规模模型中的应用提供了坚实的基础。
4.2.2 语义标识符输入表征
对比语义标识符表征和稀疏视频标识符的对比:
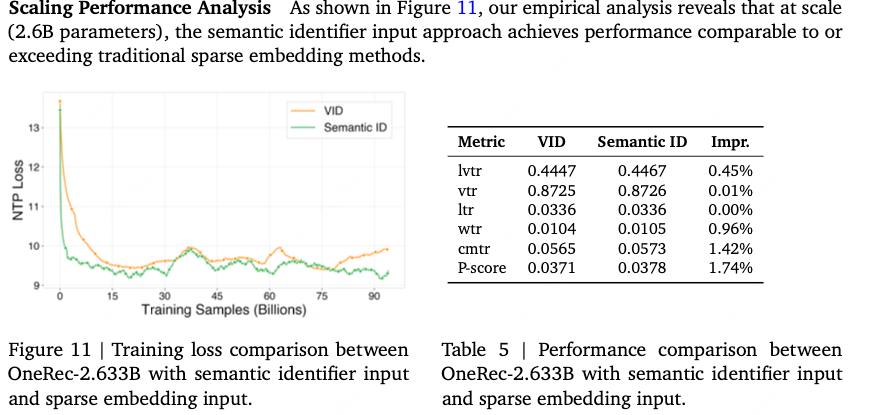
随着模型规模扩展至数十亿参数,我们探索了一种替代性输入表征策略:利用视频语义标识符表示用户交互历史,而非为视频标识符(vid)构建独立的稀疏嵌入。该语义标识符输入在达到传统稀疏嵌入方法相当性能的同时,在参数效率、通信开销和序列处理能力方面具有显著优势,使其在进一步扩展探索中展现出特殊潜力。
优势与扩展前景
相较于传统稀疏嵌入方法,语义标识符方法具有以下关键优势:
-
参数效率:通过共享输入输出表征的嵌入参数,无需为vid维护独立的稀疏嵌入表。这对拥有数十亿项目的快手平台而言,能大幅降低总参数量
-
通信效率:在分布式训练环境中,稀疏嵌入操作需要参数服务器进行大量通信以完成嵌入查找和梯度更新。语义标识符方法通过稠密操作和共享词表降低通信开销,提升训练吞吐量并缓解通信瓶颈
-
扩展序列容量:消除大型稀疏嵌入表后,可将计算资源用于处理更长的用户交互序列。这使得模型能捕获更完整的用户偏好演化模式,有望将序列长度从数千扩展至数万级交互
-
表征一致性:输入输出共享相同语义空间确保表征一致性,使模型能学习更连贯的项目间关系。这种统一表征有助于提升不同推荐场景的泛化能
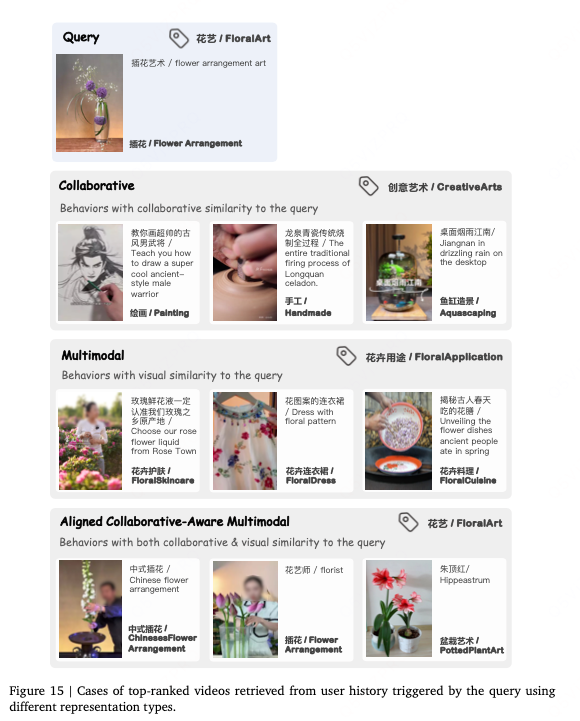
附录例子
文章附录中展现了表征方式的优点:联合context semantics和行为模式: