亮数据MCP结合Dify:构建自动化视频数据抓取与智能分析工作流的深度实践
亮数据MCP结合Dify:构建自动化视频数据抓取与智能分析工作流的深度实践
在当今数字媒体时代,视频内容已成为信息传播和用户交互的核心载体。以TikTok、YouTube等平台为代表的视频分享网站,蕴含着海量的商业、文化和舆情价值。然而,如何高效、稳定地从这些结构复杂、动态加载且具备反爬取机制的平台中获取结构化的视频数据,并对其进行深度分析,是数据科学家、市场分析师和开发者面临的共同挑战。本文将详细阐述一种前沿的解决方案:通过在Dify这一LLM应用开发平台中,集成亮数据(Bright Data)的MCP(Multi-Channel Proxy,多渠道代理,此处指其Web Scaper智能数据提取工具),构建一个从视频链接输入到数据抓取,再到AI智能分析的全自动化工作流。
第一章:基础环境搭建——稳定运行的基石
构建任何强大的数据应用,首先需要一个稳定、可复现的运行环境。我们选择使用Docker作为基础架构,它通过容器化技术将应用及其依赖项打包,确保了环境的一致性和隔离性,极大地简化了部署和运维的复杂性。
1.1 Docker Desktop的定制化安装
为了优化系统资源分配并保持系统盘(C盘)的整洁,我们将Docker Desktop的程序文件及数据文件全部安装到D盘。
首先,从Docker官方网站下载最新的Docker Desktop Installer.exe安装程序。
随后,在D盘规划并创建Docker的安装路径和数据存储路径,例如:
D:\Program Files\Docker(用于存放程序)D:\Program Files\Docker\data(用于存放WSL镜像及数据)
关键步骤在于使用命令行进行静默安装,这给予我们高度的自定义权限。打开一个具有管理员权限的PowerShell或命令提示符窗口,导航至安装包所在的目录,并执行以下命令:
Start-Process -FilePath ".\Docker Desktop Installer.exe" -ArgumentList 'install --accept-license --installation-dir="D:\Program Files\Docker" --wsl-default-data-root="D:\Program Files\Docker\data" --windows-containers-default-data-root="D:\Program Files\Docker"' -Wait
这条命令中的参数至关重要:
--installation-dir: 明确指定了Docker程序本身的安装位置。--wsl-default-data-root: 指定了Windows Subsystem for Linux (WSL) 2发行版的数据存储根目录。Docker Desktop在Windows上严重依赖WSL2来运行Linux容器,将此数据目录移出C盘,可以有效避免因镜像、容器和卷的不断增多而导致的系统盘空间耗尽问题。
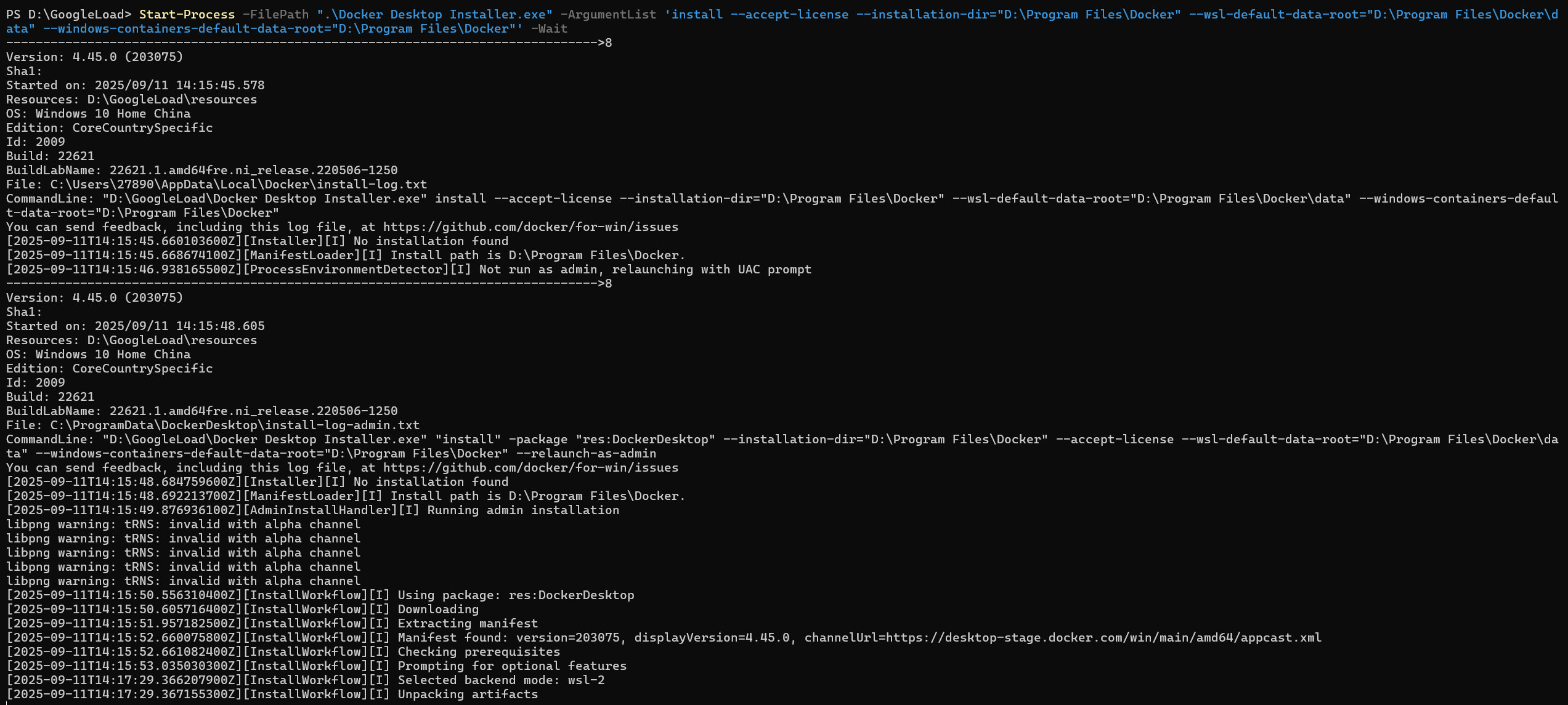
安装完成后,我们可以检查D:\Program Files\Docker目录,确认相关文件及数据文件夹已成功创建,这标志着我们的定制化安装策略已成功实施。
在初次启动Docker Desktop的设置向导中,建议勾选Add shortcut to desktop以便于日后快速访问。
系统会进行一些初始化配置,耐心等待其完成即可。
1.2 配置镜像加速
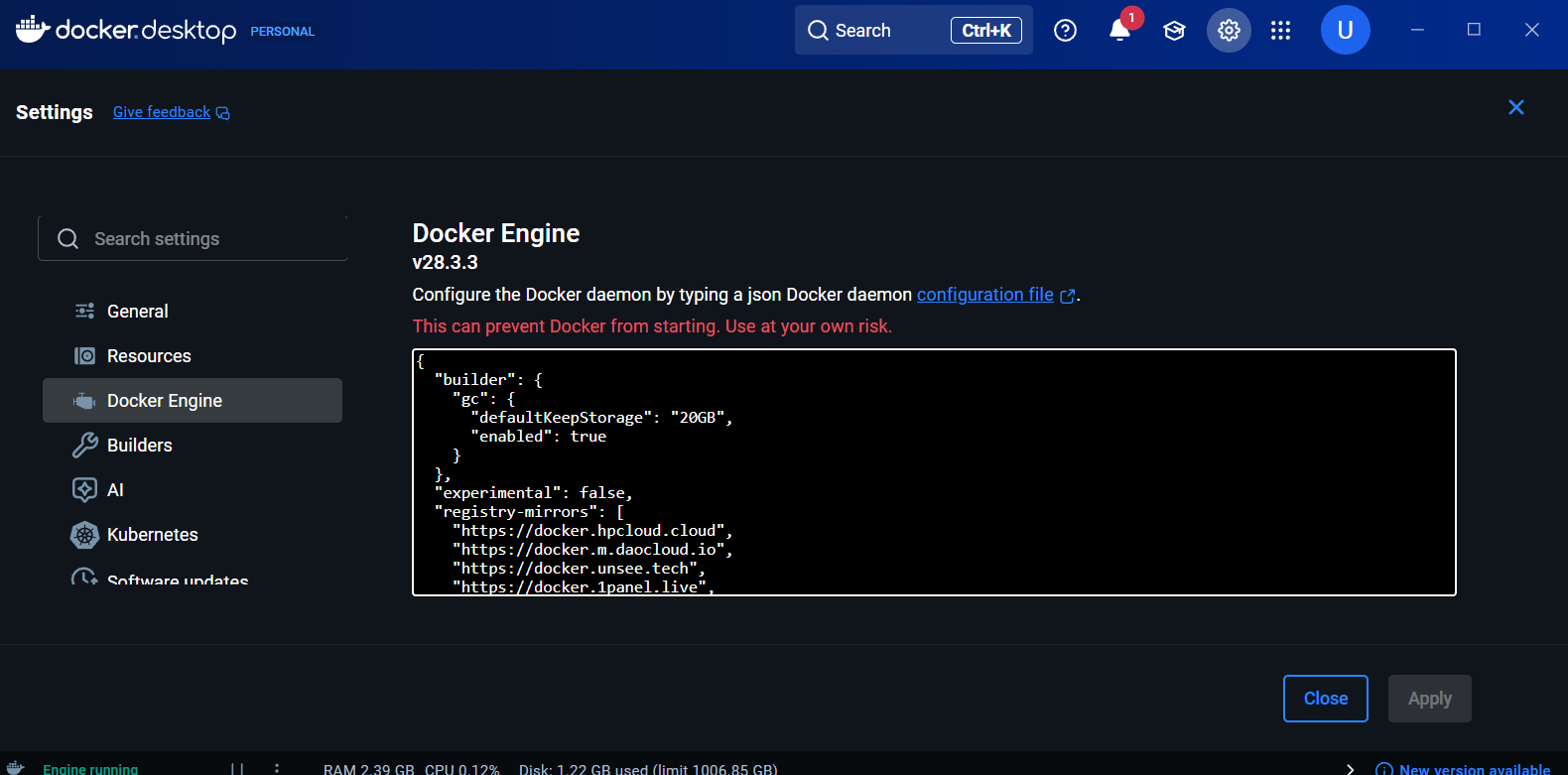
为了显著提升拉取Docker镜像的速度,配置国内镜像源是必不可少的一步。在Docker Desktop的设置(Settings)中,导航至Docker Engine选项卡,在右侧的JSON配置文件中加入registry-mirrors字段。这是一个包含多个镜像仓库URL的数组,Docker会按顺序尝试从这些镜像拉取,从而避开直连海外Docker Hub可能遇到的网络瓶颈。
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://docker.hpcloud.cloud","https://docker.m.daocloud.io","https://docker.unsee.tech","https://docker.1panel.live","http://mirrors.ustc.edu.cn","https://docker.chenby.cn","http://mirror.azure.cn","https://dockerpull.org","https://dockerhub.icu","https://hub.rat.dev"]
}
完成配置并点击Apply & Restart后,一个稳定、高效的本地容器化环境便搭建完成了,为后续部署Dify平台奠定了坚实的基础。
第二章:部署Dify平台——工作流的可视化编排中心
Dify是一个开源的、强大的LLM应用开发平台,它允许用户通过可视化的界面编排和管理复杂的AI工作流(Workflow),将不同的工具、API和模型组合起来,构建强大的应用程序。
2.1 获取并配置Dify
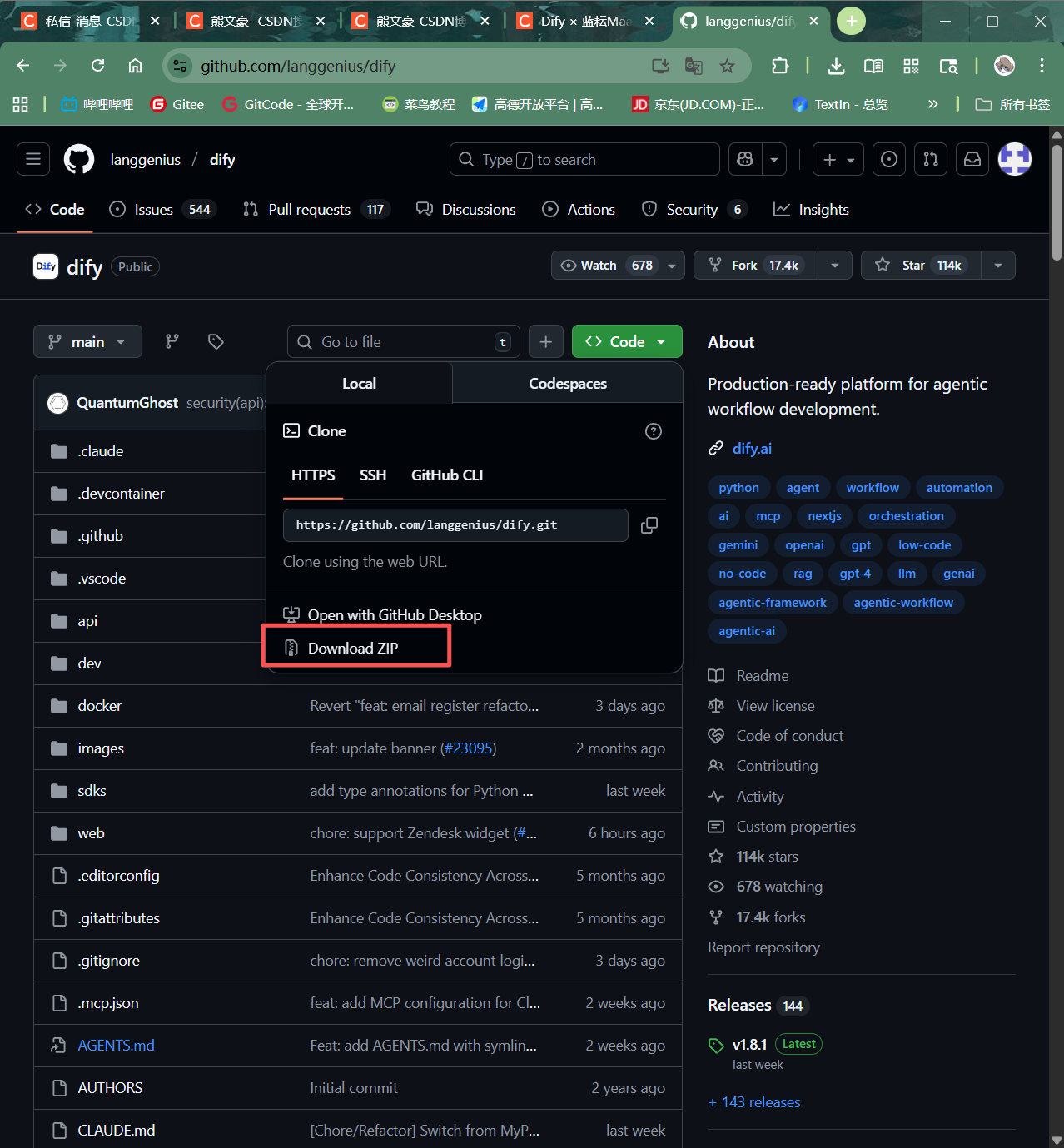
我们从Dify的官方GitHub仓库获取项目代码。可以直接下载ZIP压缩包,或使用git clone命令克隆仓库,后者更便于未来的版本更新。
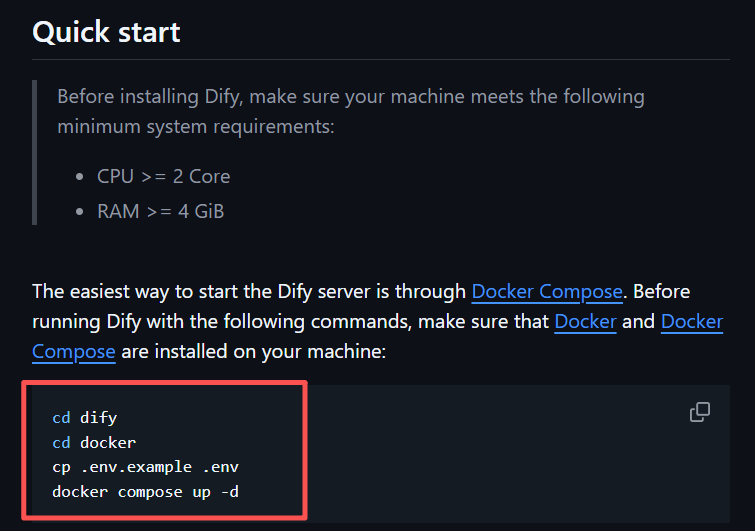
获取代码后,进入项目根目录下的docker子目录。在这里,我们需要进行关键的环境变量配置。将名为.env.example的文件复制一份,并重命名为.env。
.env文件是Docker Compose部署的核心配置文件,用于存放数据库密码、API密钥等敏感信息和环境特定参数,将其与代码分离是现代应用开发的标准实践。
2.2 启动Dify服务
在docker目录下,打开命令行终端,执行以下命令即可一键启动Dify平台的所有服务,包括Web服务器、API后端、数据库和中间件等。
docker compose up -d
docker compose会读取同目录下的docker-compose.yml文件,并根据其定义自动拉取所需镜像、创建并启动所有关联的容器。-d参数表示在后台(detached mode)运行。
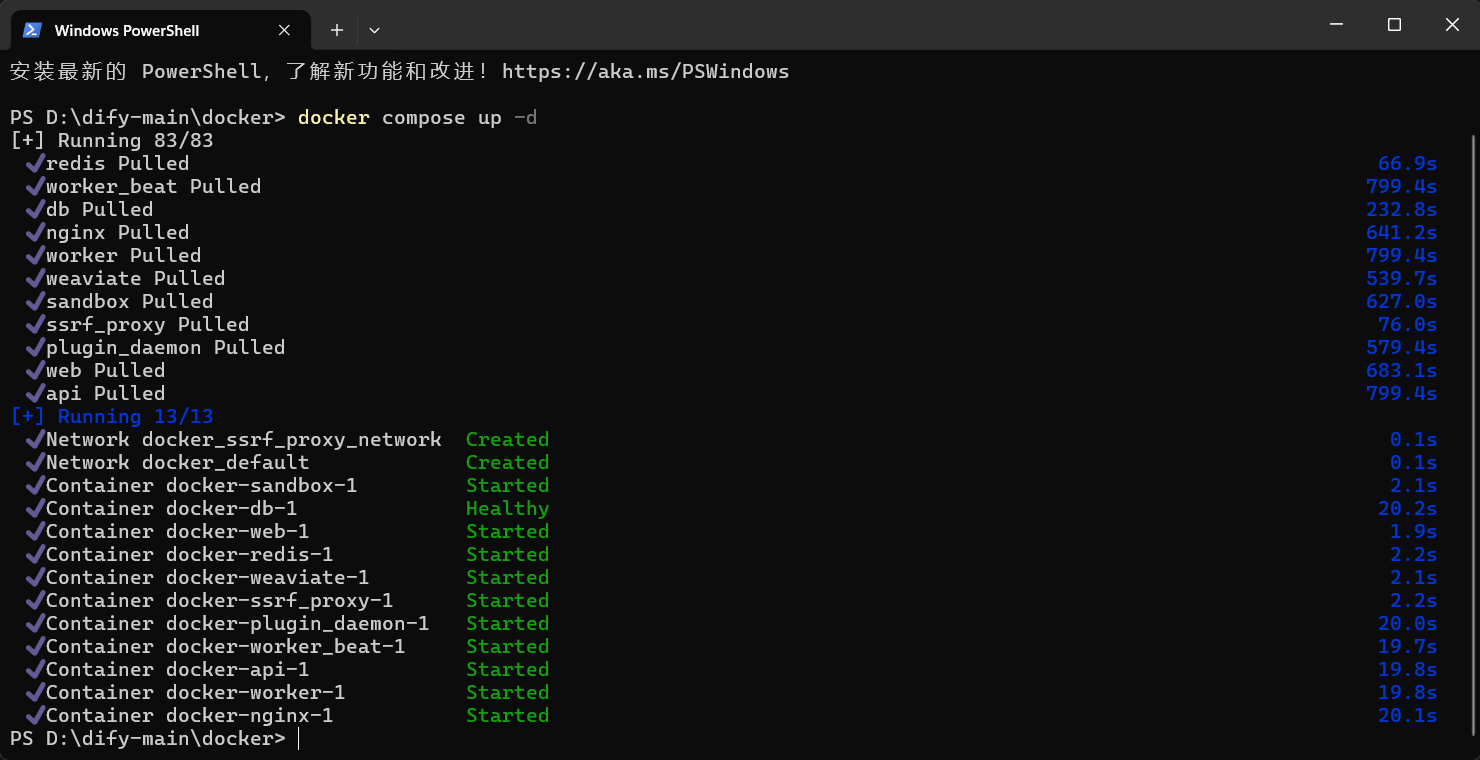
初次启动时,Docker会下载多个镜像,需要一些时间。当所有服务都成功启动并运行后,命令行会显示done的状态。
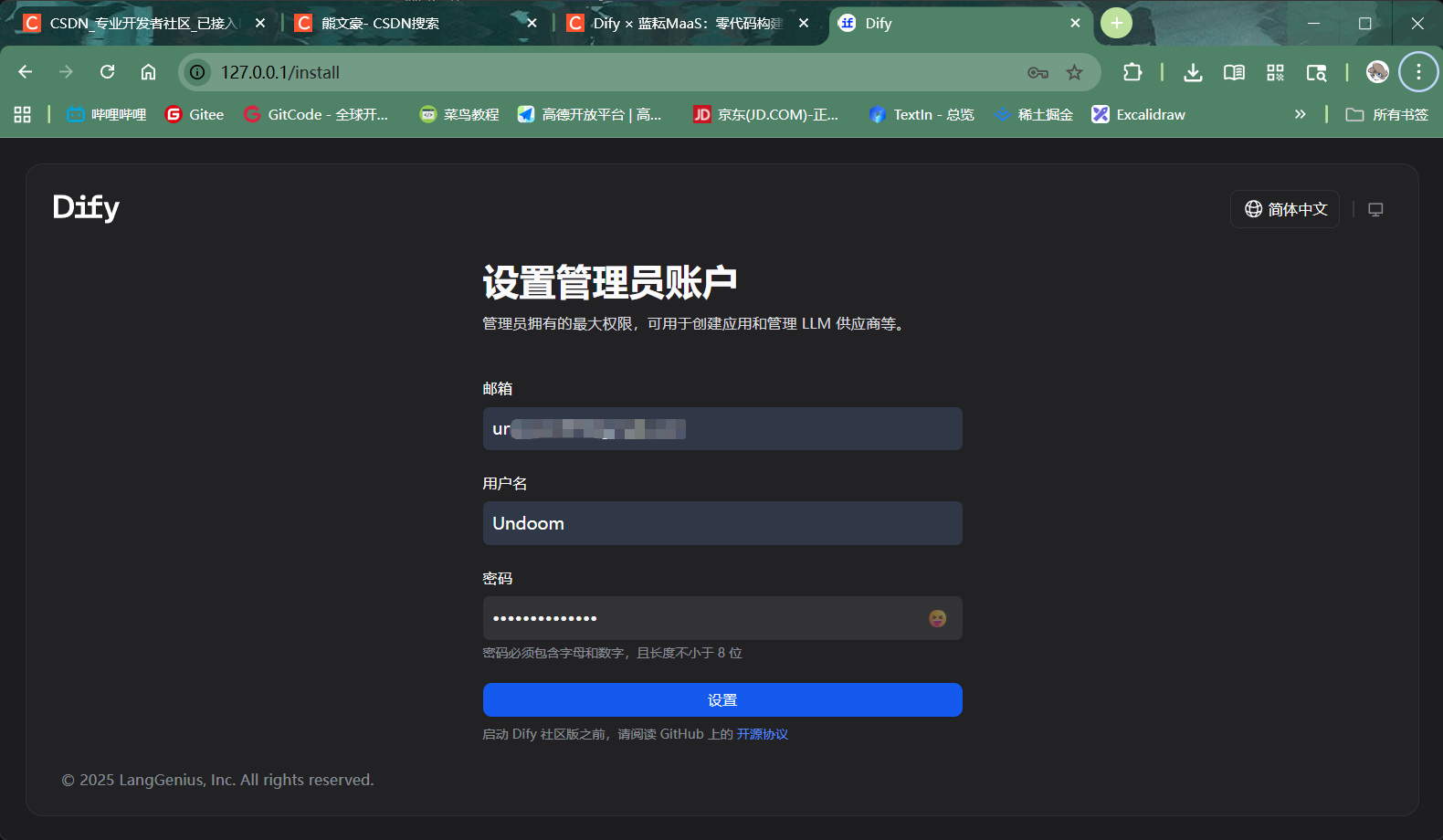
2.3 初始化Dify平台
在浏览器中访问http://127.0.0.1,即可看到Dify的欢迎界面。首次访问需要设置管理员账户的邮箱和密码,完成注册。
登录后,我们就进入了Dify的主控制台,可以开始创建我们的AI应用了。
第三章:亮数据MCP集成——解锁全网视频数据抓取能力
亮数据(Bright Data)是全球领先的网络数据平台,其提供的不仅仅是代理网络,更包含了一系列智能化的数据采集解决方案。其中,Structured Data Feeds(结构化数据订阅)工具,是一个强大的MCP(多渠道代理)实现,能够根据用户提供的URL和数据需求描述,自动处理IP轮换、验证码、浏览器指纹等复杂问题,直接返回干净的、结构化的JSON数据。这正是我们实现稳定视频数据抓取的核心能力。
3.1 创建工作流并定义输入
在Dify中,我们首先创建一个新的空白应用。
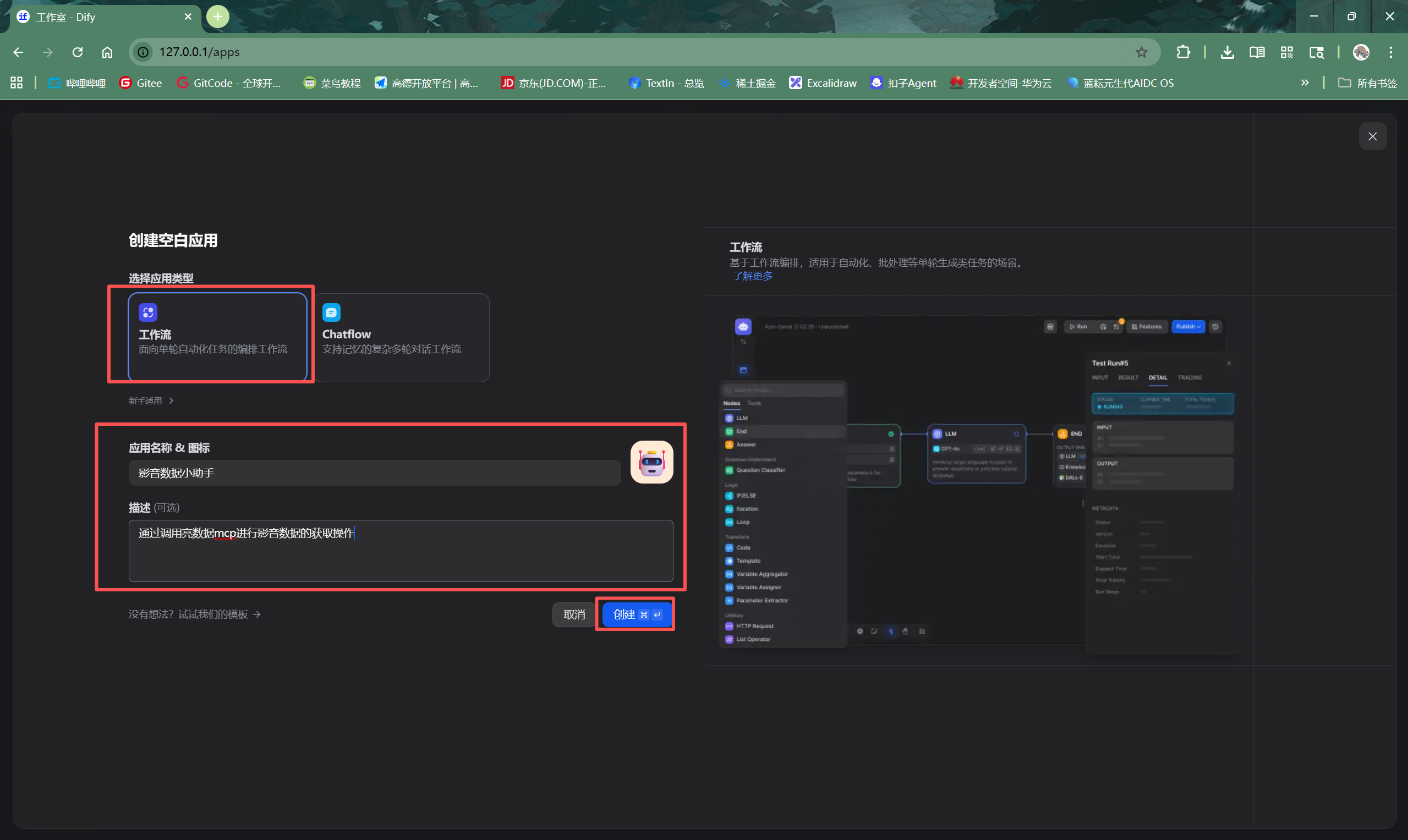
应用类型选择“工作流(Workflow)”,并为其指定一个清晰的名称和描述,例如“视频数据分析工作流”。
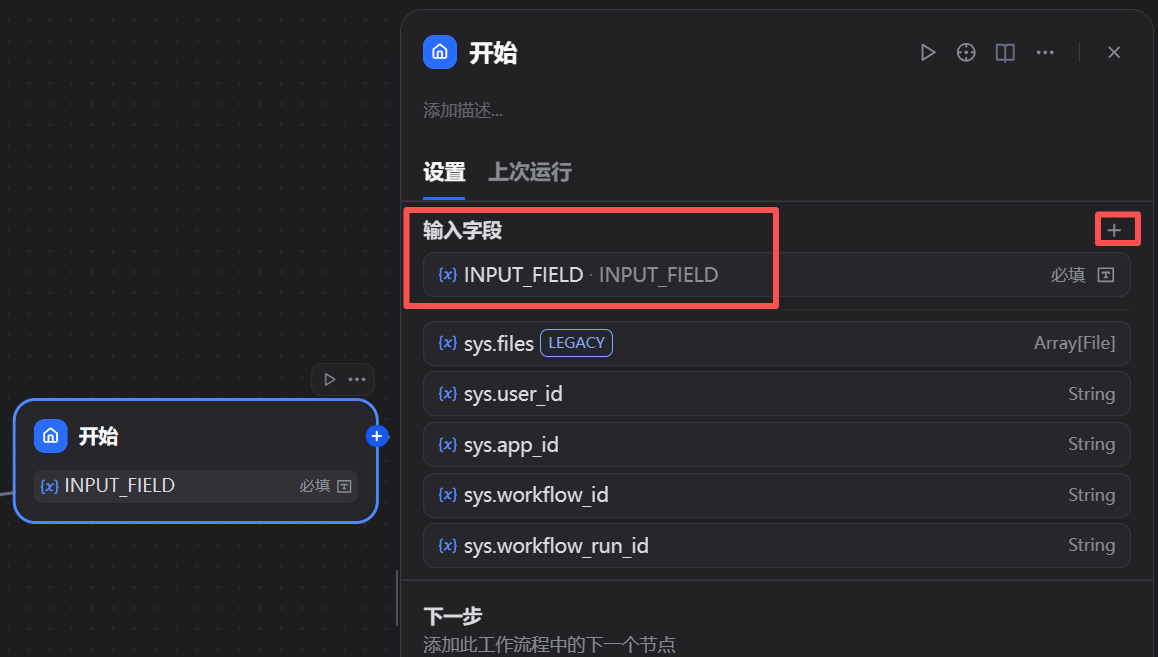
一个工作流由多个节点构成,数据在节点间流动和处理。起点是“开始(Start)”节点,它定义了整个工作流的输入参数。我们点击该节点,为其添加一个输入字段。
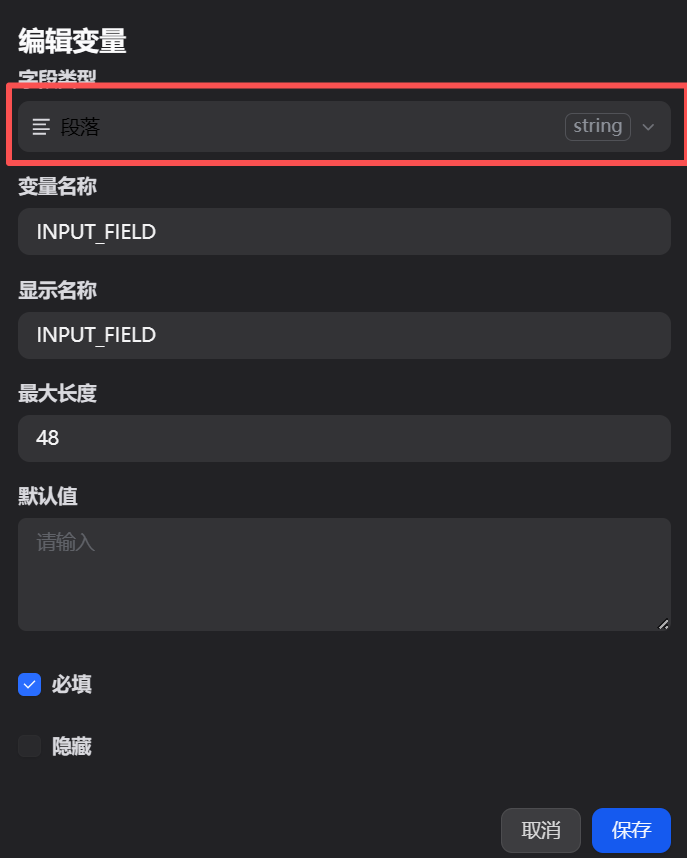
我们将这个输入字段的类型设置为“段落(Paragraph)”,变量名(Variable Name)定义为product_url,并适当增加最大长度限制(如200个字符),以确保能完整接收一个URL。这个product_url变量将作为后续亮数据节点的目标抓取地址。
3.2 授权并配置亮数据工具
要使用亮数据的能力,首先需要将其作为一个工具集成到Dify中。
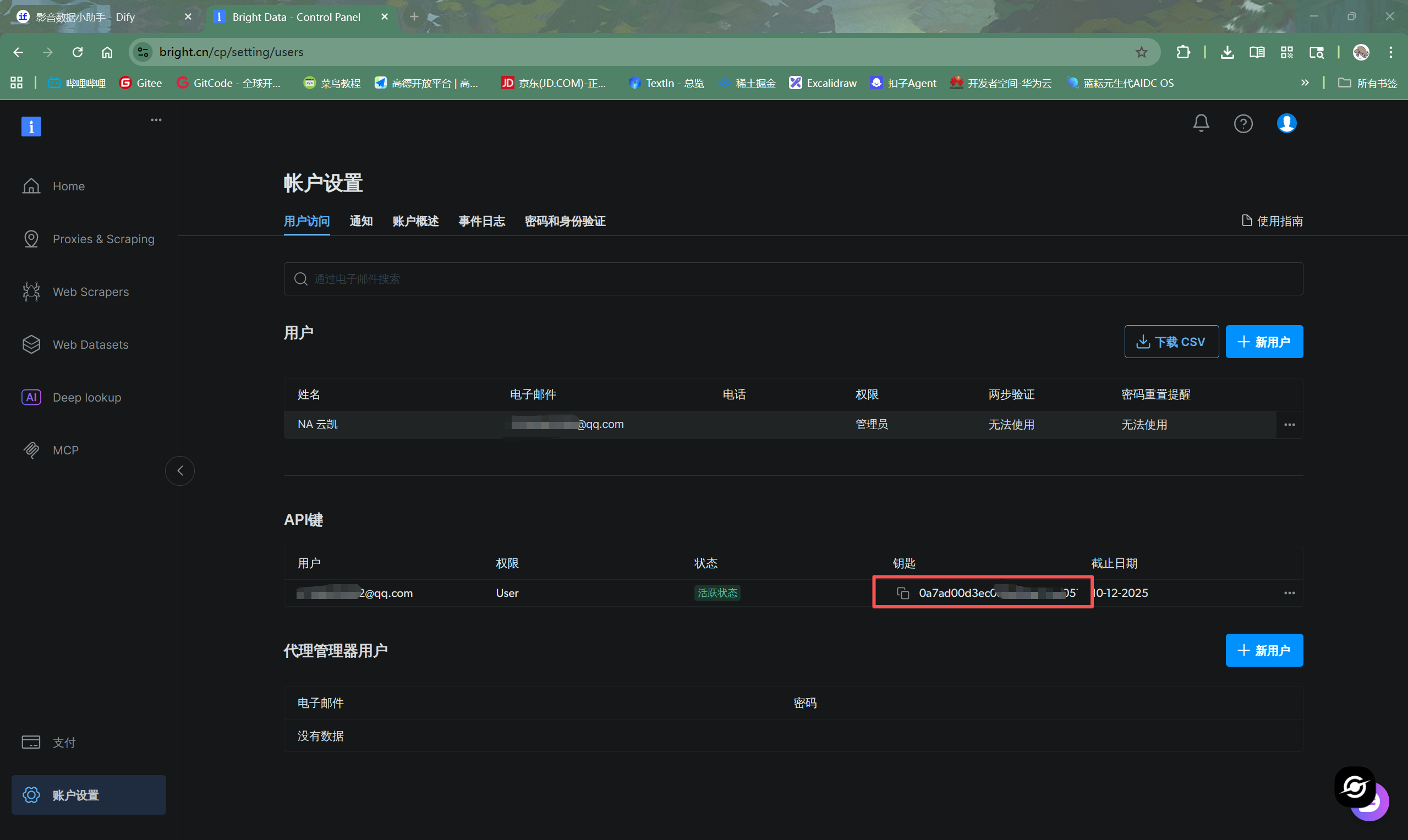
第一步,注册亮数据账户并获取API密钥。在亮数据的账户设置中,可以轻松找到并复制API密钥。
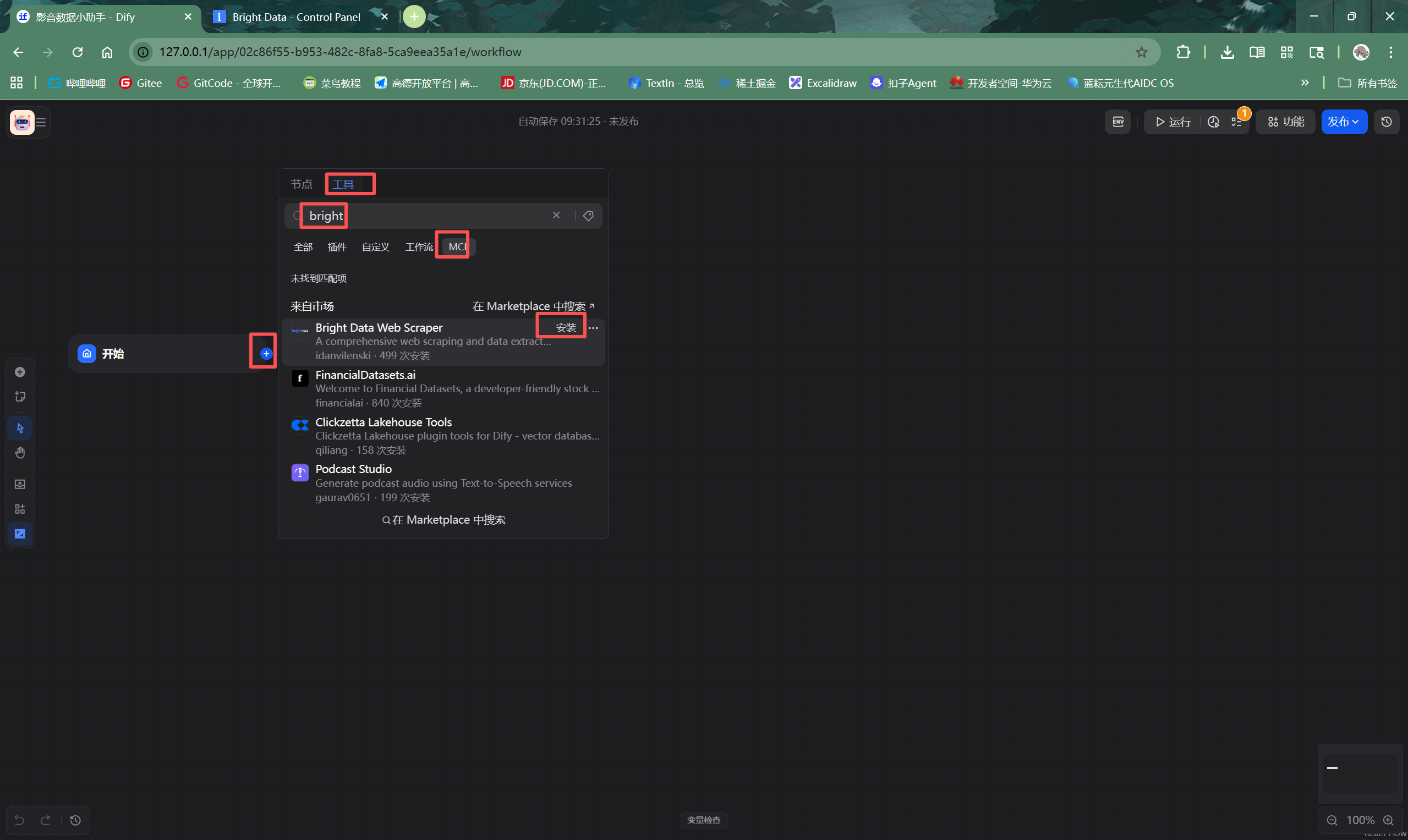
第二步,回到Dify平台,在工作流编辑界面的节点添加菜单中,选择“工具” -> “MCP”,然后在搜索框中输入bright,找到Bright Data Web Scaper工具并点击安装。
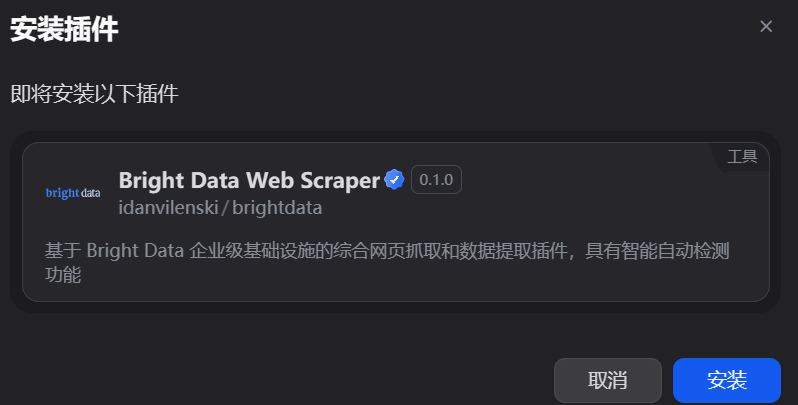
第三步,进行API授权。安装完成后,从顶部导航栏进入“工具”页面,找到已安装的亮数据MCP,点击进行API-KEY授权配置。
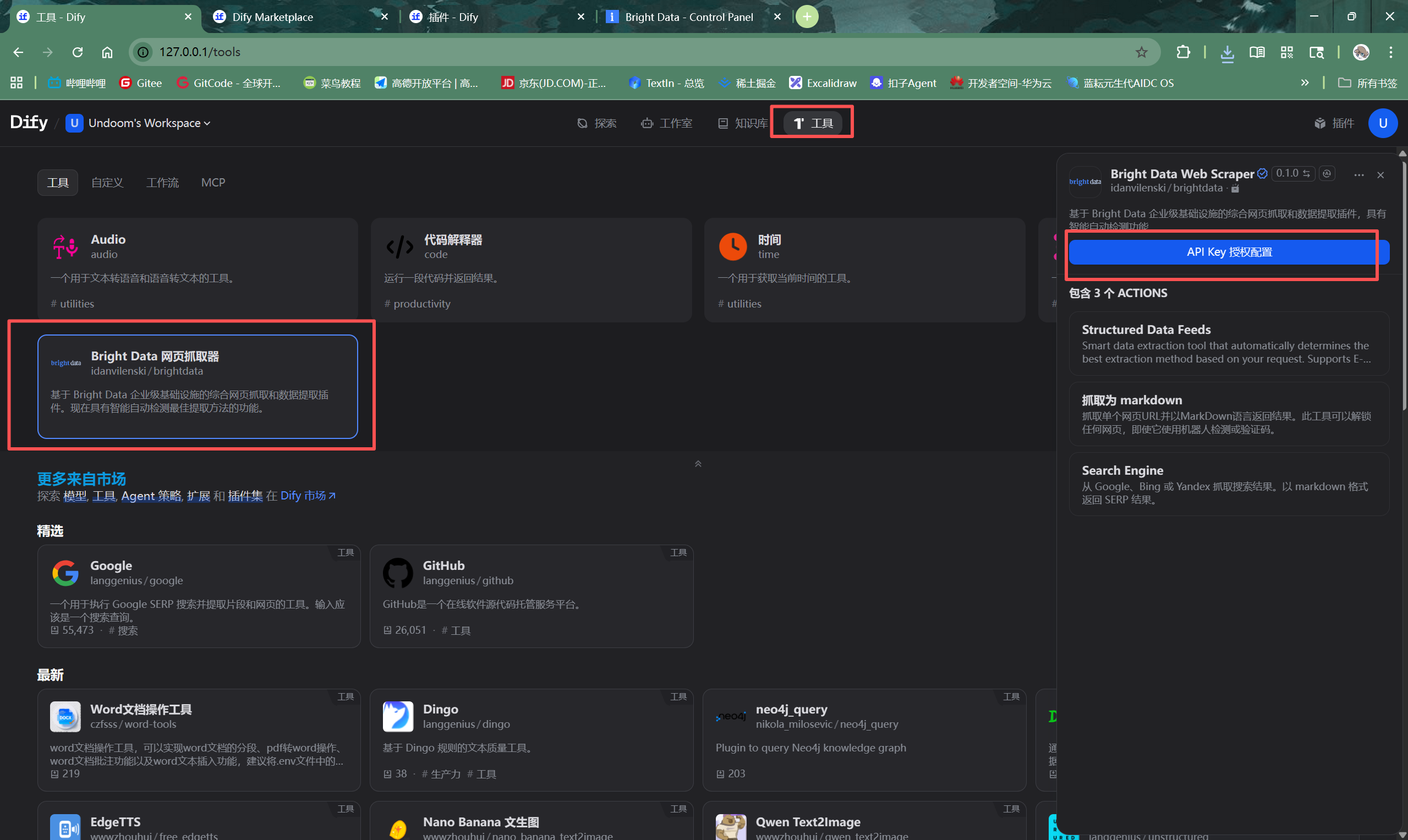
将之前复制的亮数据API密钥粘贴到此处,并保存。
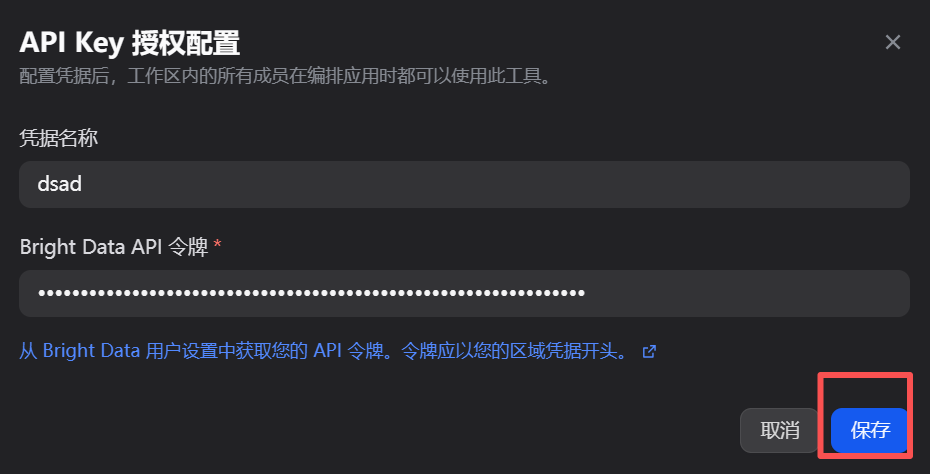
配置成功后,工具状态会显示为“已授权”,表明Dify现在已经具备了调用亮数据服务的能力。
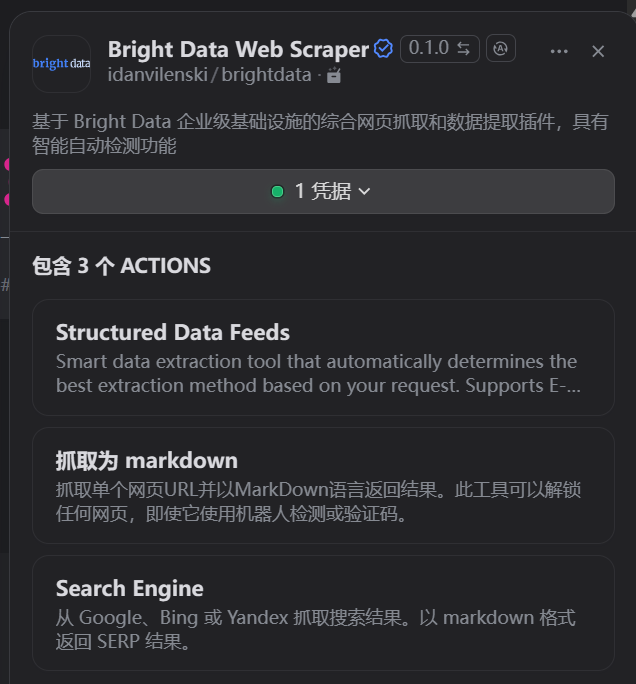
3.3 在工作流中使用亮数据节点
返回工作流编辑界面,在“开始”节点后点击加号,选择“工具” -> Structured Data Feeds,将亮数据的核心功能节点添加到我们的工作流中。
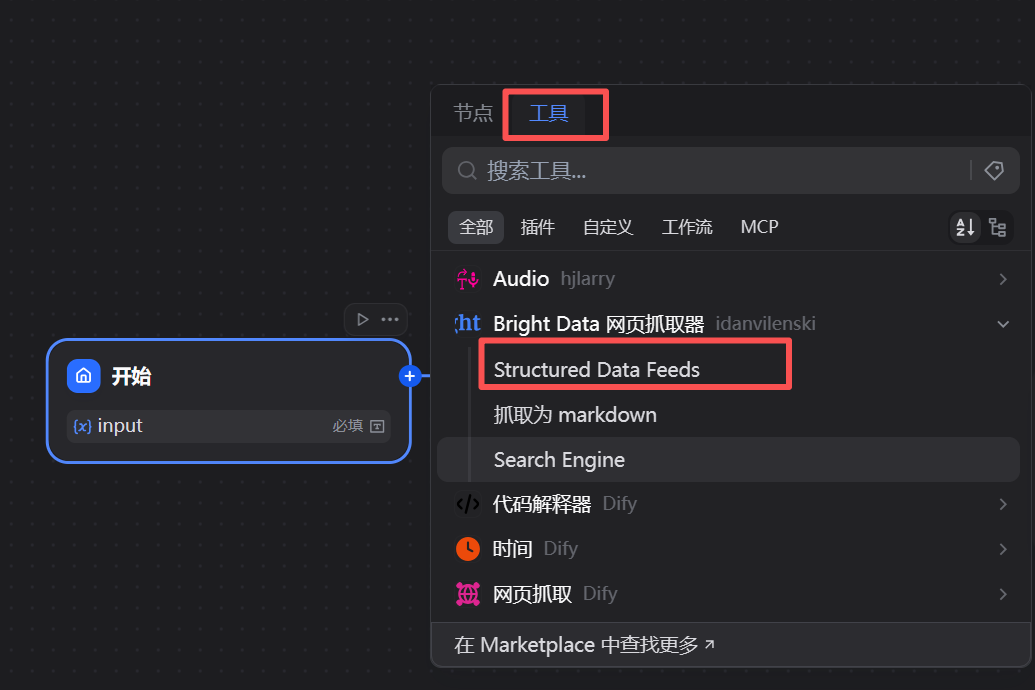
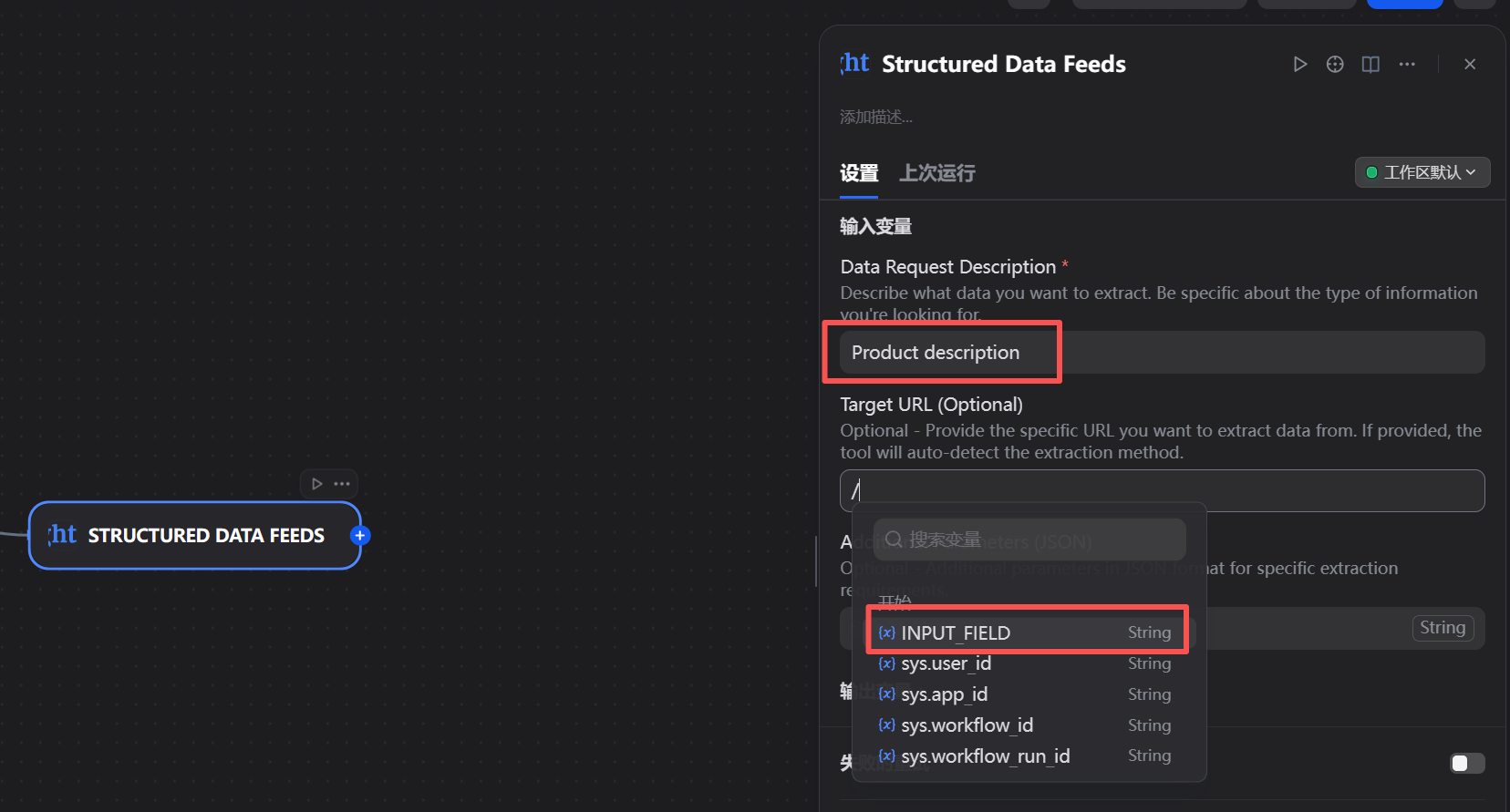
配置该节点的关键在于输入映射:
- Target URL: 我们需要将“开始”节点定义的
product_url变量传递给这个字段。在字段中输入/或{{,Dify会智能提示可用的上游变量,我们选择product_url即可。 - Data Request Description: 这是亮数据MCP强大能力的体现。我们无需编写复杂的CSS选择器或XPath,只需用自然语言描述我们想要从目标URL中获取什么数据。例如,对于一个TikTok视频链接,我们可以描述为:“请提取这个TikTok视频的作者名、视频描述、点赞数、评论数和分享数”。
至此,工作流的数据获取部分已经完成。当工作流运行时,用户输入的任何URL都将通过亮数据MCP进行智能解析和数据提取,其强大的代理网络和反屏蔽技术确保了极高的成功率和数据质量。
第四章:集成大语言模型——赋予数据分析的智慧
获取到的原始数据需要进一步的加工和提炼才能转化为有价值的洞察。我们通过集成一个大语言模型(LLM)节点,对亮数据返回的结构化数据进行深度的、智能化的分析。
4.1 接入第三方LLM服务
我们选用蓝耘(Lanyun)作为LLM的服务提供商。首先,注册并登录蓝耘平台,在其Mass平台的API-KEY管理页面创建一个新的API Key并复制。
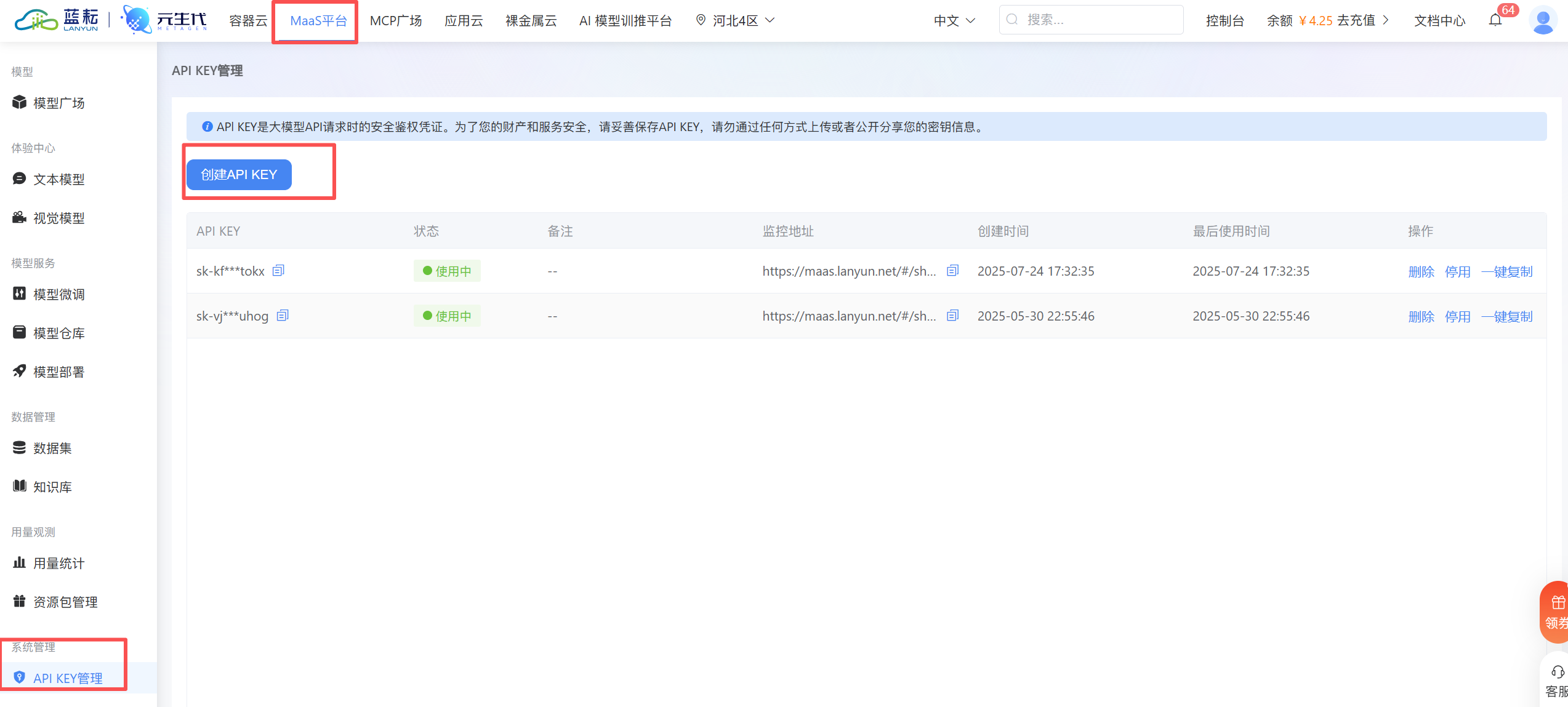
4.2 在Dify中配置LLM
Dify通过插件机制支持接入符合OpenAI API规范的任何模型服务。
-
在Dify的“工具” -> “插件市场”中,搜索并安装
OpenAI-API-compatible插件。
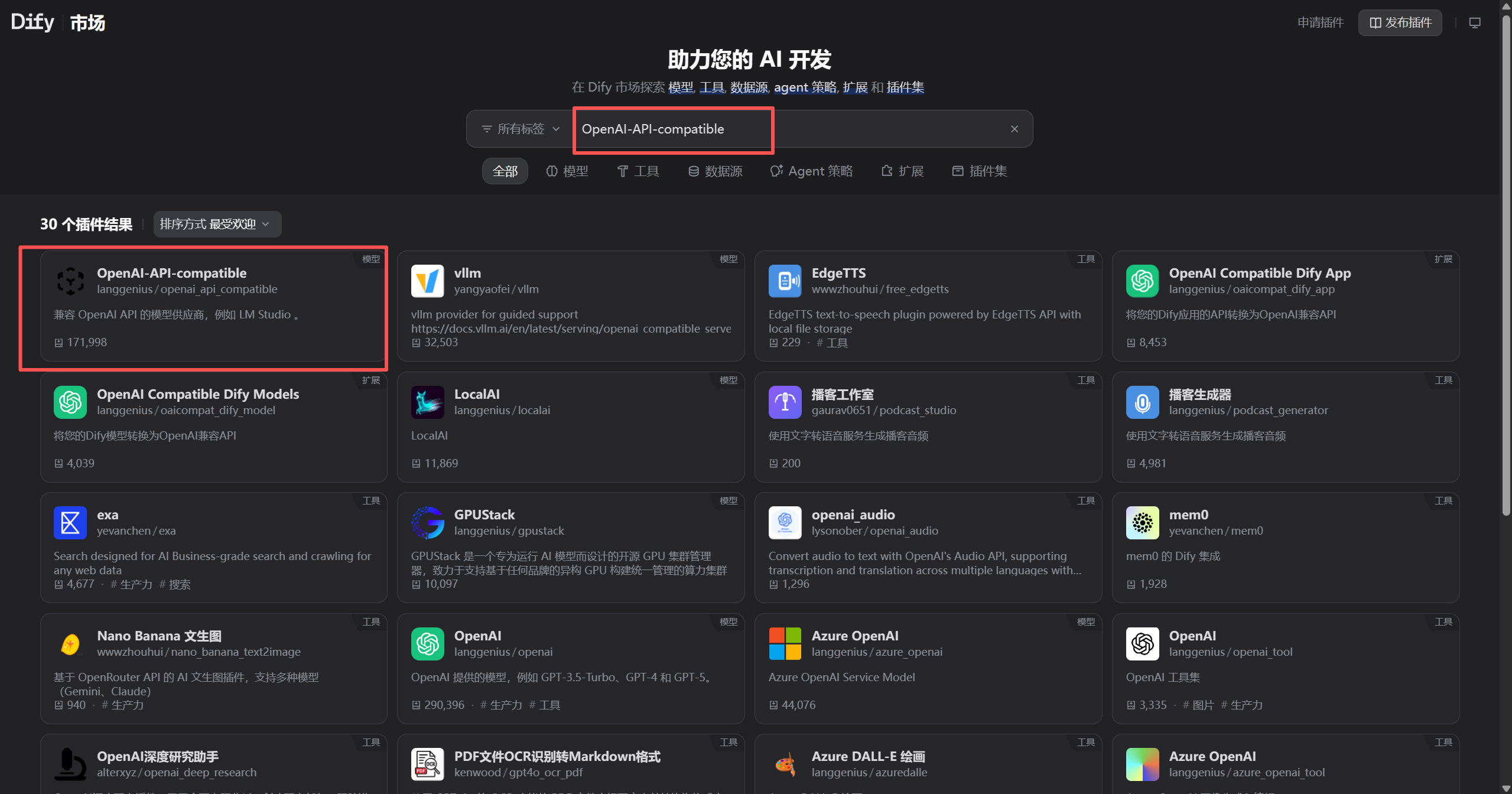
-
安装后,进入“模型供应商”设置页面,点击“添加模型”。
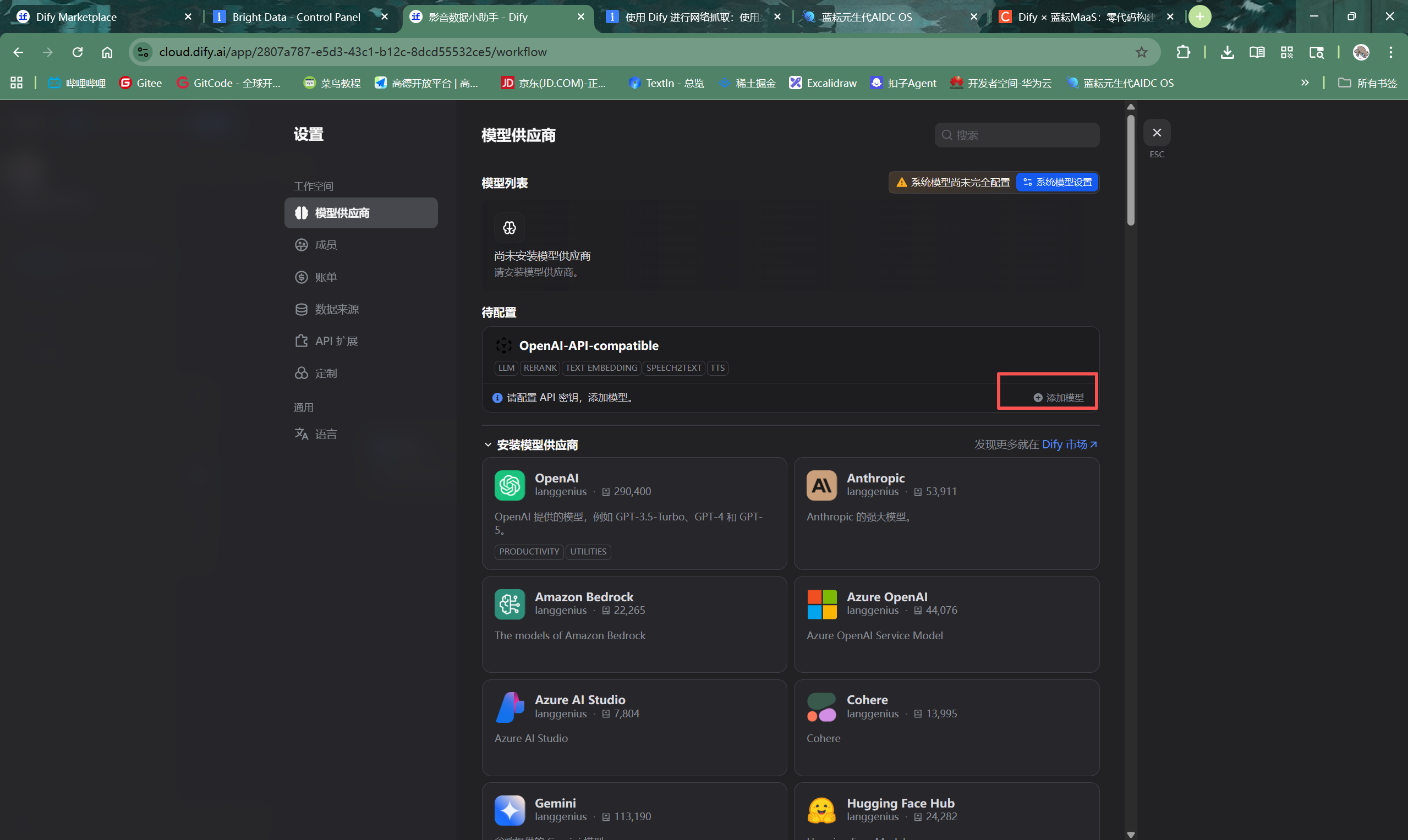
-
填写以下配置信息:
- API Base URL:
https://maas-api.lanyun.net/v1 - API Key: 粘贴从蓝耘平台获取的API Key。
- 模型名称: 自定义一个易于识别的名称,例如
Lanyun-Qwen2.5-72B。 - 模型ID: 填写蓝耘平台提供的具体模型标识符,例如
/maas/qwen/Qwen2.5-72B-Instruct。
- API Base URL:
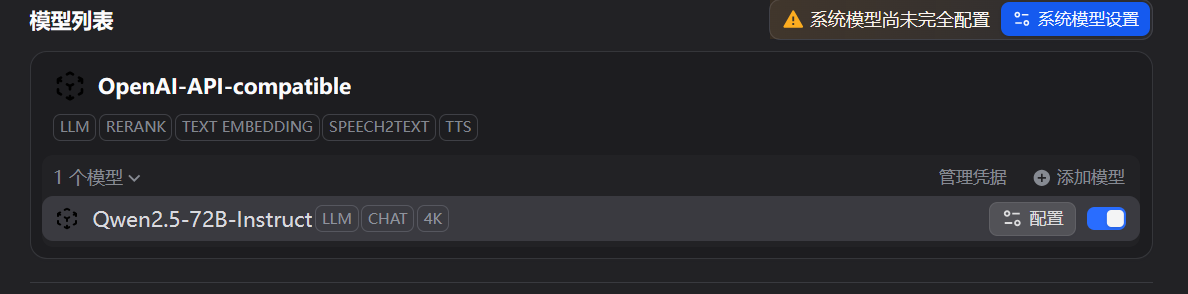
配置完成后,这个强大的Qwen2.5-72B模型就可以在Dify的任何工作流中作为LLM节点被调用了。
4.3 构建智能分析节点
在亮数据MCP节点之后,添加一个“LLM”节点。在模型选择下拉框中,我们就能看到刚刚配置好的Lanyun-Qwen2.5-72B模型。
接下来是核心的Prompt工程。我们在“PROMPT”输入框中设计一个指令,引导LLM扮演特定角色并完成指定任务。
你是一位专业的影音数据分析专家,专门负责处理通过亮数据MCP节点获取的影音数据。在我们的工作流中,亮数据MCP根据指定链接返回了相应的影音数据。现在你将对这些数据进行处理分析。请你对这些影音数据进行全面的分析,包括但不限于内容识别、情感分析、关键信息提取等。分析过程要详细、全面,考虑各种可能的因素。返回你的分析结果data:
在data:之后,我们同样通过输入/来引用上游节点(亮数据MCP)的输出。亮数据节点成功执行后,其提取的结构化数据(通常是JSON格式的文本)会作为名为text的变量输出。我们将这个text变量插入到提示词的末尾。
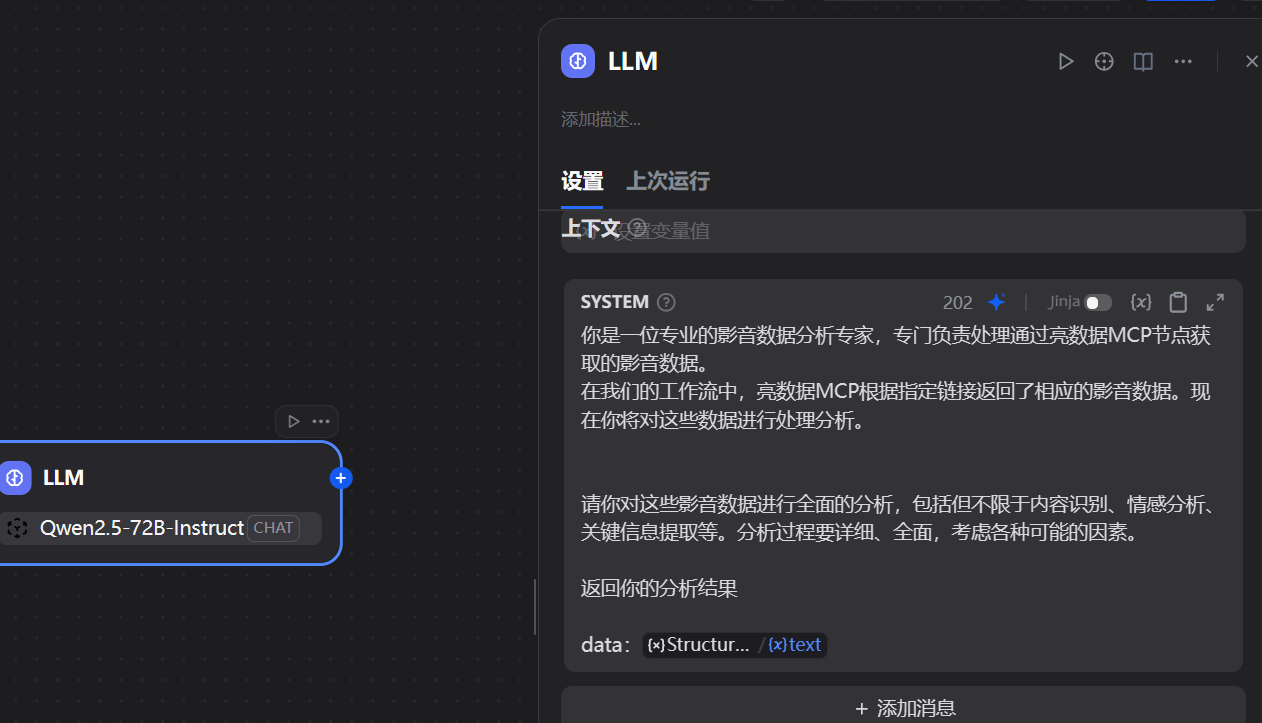
4.4 定义工作流最终输出
最后,添加一个“结束(End)”节点,用于输出整个工作流的最终结果。我们将LLM节点的输出(一个包含分析结果的字符串)连接到结束节点的输出变量上。
我们可以对LLM节点进行单独测试,确保其能够根据模拟数据成功返回分析内容。
第五章:执行与验证——从链接到洞察的瞬间
现在,整个自动化工作流已经构建完成。我们点击右上角的“运行”按钮,在product_url输入框中,提供一个真实的TikTok视频链接进行测试。
输入链接:
https://www.tiktok.com/@adamshewmaker/video/7532966063072365879?is_from_webapp=1&sender_device=pc
点击“运行”后,工作流开始执行:
- “开始”节点将URL传递给亮数据MCP节点。
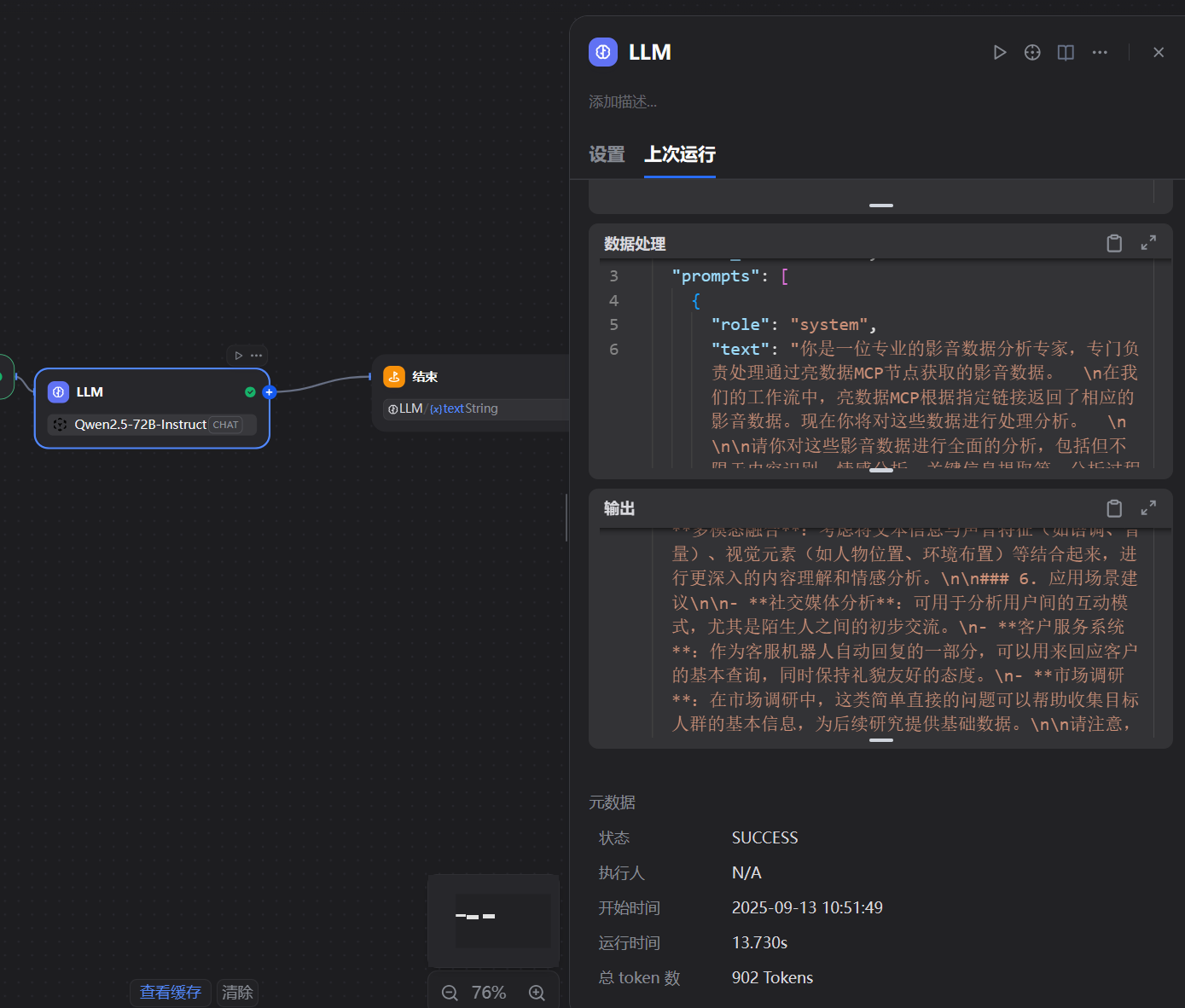
- 亮数据MCP节点调用其强大的数据采集网络,访问该TikTok链接,绕过所有访问限制,解析页面并提取出关键的结构化数据。执行日志显示,该节点成功返回了包含视频详情的JSON数据。
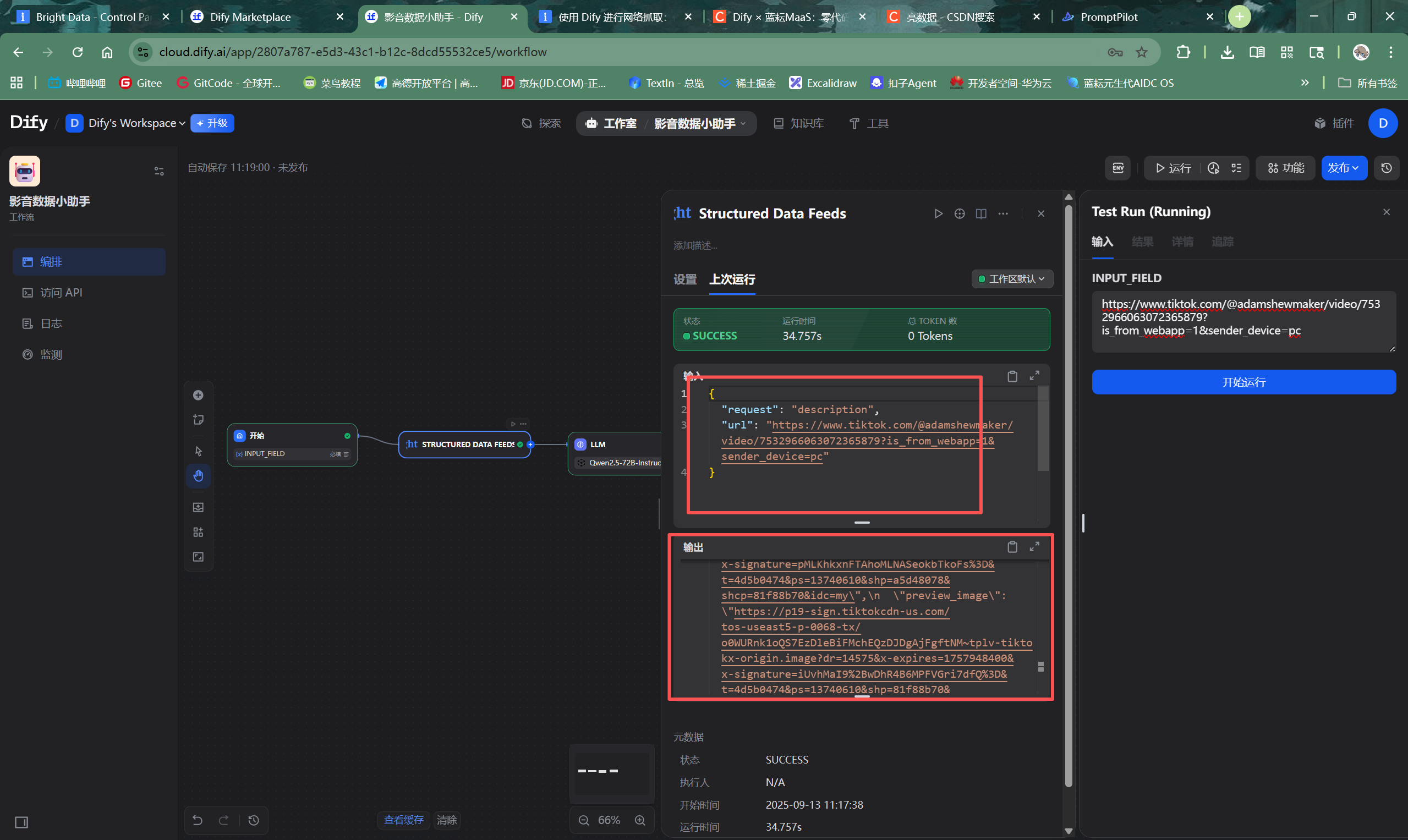
- 提取出的数据被注入到LLM节点的提示词中。
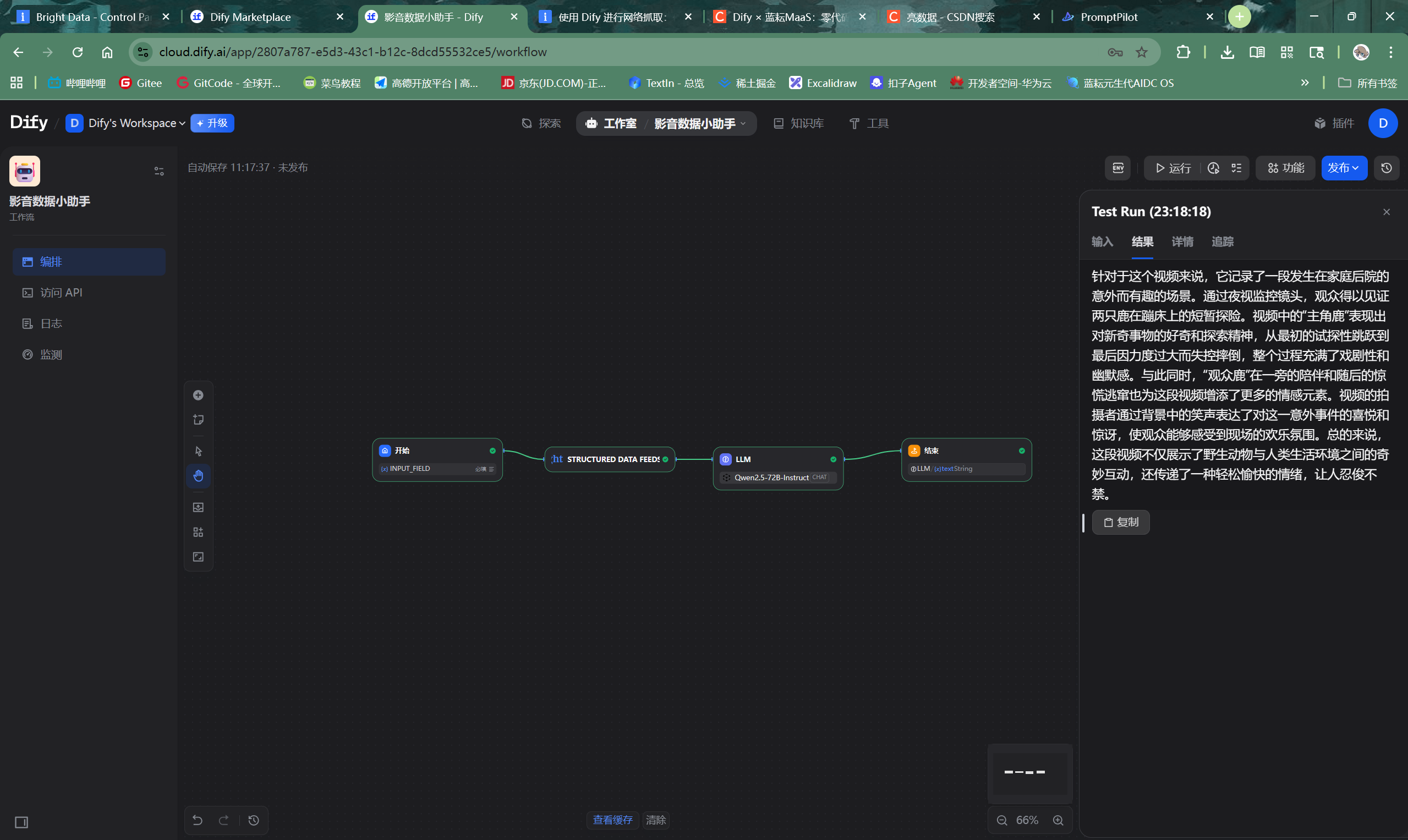
- Qwen2.5-72B模型接收到完整的指令和数据,开始扮演“影音数据分析专家”的角色,对数据进行深度分析。
- 最终,LLM生成的分析报告被传递给“结束”节点,并作为最终结果展示出来。
结论
本次实践完整地展示了如何将亮数据MCP的顶尖网络数据抓取能力与Dify平台的可视化工作流编排能力、以及蓝耘大语言模型的智能分析能力相结合,构建一个端到端的自动化视频数据处理管道。亮数据MCP在此流程中扮演了不可或缺的角色,它解决了数据获取阶段最困难、最繁琐的挑战,使得开发者和分析师能够将精力完全集中在数据应用和价值挖掘上。这种“专业工具+编排平台+AI模型”的组合范式,不仅极大地降低了数据采集和分析的技术门槛,也为从海量视频内容中提取商业智能、进行市场研究和舆情监控提供了前所未有的效率和深度。
立即免费试用 Bright Data MCP Server,获取你的5,000次/月额度
https://get.brightdata.com/u-mcpserver