CLIP:开启多模态AI新时代的密钥(上)
CLIP 论文逐段精读【论文精读】
CLIP 改进工作串讲(上)【论文精读·42】
传统计算机视觉模型依赖固定类别标注数据,存在泛化能力弱、任务迁移成本高、标注依赖性强等局限。OpenAI提出的CLIP模型通过自然语言监督信号,在海量网络图像-文本对上进行对比学习,实现了无需任务特定微调即可执行零样本分类的能力。其核心突破在于:
-
对比学习框架:将图像与文本编码为联合嵌入空间,通过最大化正样本对的相似度实现跨模态对齐;
-
提示工程:通过模板化提示(如“A photo of a {label}”)解决预训练与推理时的分布差异;
-
零样本迁移:在超过30个视觉数据集上达到接近全监督模型的性能。
基于CLIP的后续工作如LSeg(语言驱动的语义分割)、GroupViT(无监督分组分割)和ViLD(视觉语言蒸馏目标检测)进一步扩展了其在下游多模态任务中的应用。本文将系统介绍CLIP的技术原理、关键实验及衍生应用,为多模态学习研究提供深入参考。
1. CLIP 对抗式 文本-图像预训练
Contrastive Language-lmage Pre-Training
Learning Transferable Visual Models From Natural Language Supervision
1. 背景&特色
迁移能力强 在ImageNet上做 zero-shot 达到ResNet-50准确率(极强泛化能力)。
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. 当前视觉工作都是在固定物品集合上做分类。
OpenAI 的工作:只需提供待识别视觉类别的名称,CLIP即可应用于任何视觉分类基准任务——这与GPT-2和GPT-3展现的"零样本"能力颇为相似。通过互联网上海量可用的自然语言标注数据,在丰富多样的图像上进行训练。其设计初衷是能够直接用自然语言指令执行多种分类基准任务,而无需针对特定基准进行直接优化。
典型的视觉数据集不仅创建过程需要耗费大量人力成本,且只能教会系统有限范围的视觉概念;标准视觉模型往往仅擅长单一任务,要适应新任务必须付出代价巨大调整;那些在基准测试中表现优异的模型,在压力测试中的表现却令人失望地糟糕。
CLIP在ImageNet和 ResNet101相当;在其他类型的数据远超。

2. 基于CLIP的一些有趣应用
https://github.com/orpatashnik/StyleCLIP 结合CLIP和GAN 把图片向文字方向改变(风格版Style-GAN)

CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders 简笔画

https://github.com/johanmodin/clifs
CLIFS 是一个基于 CLIP 和 ImageBind 的跨模态文件搜索工具。
使用自然语言或一种类型的文件来搜索另一种类型的文件。
例如,你可以:
-
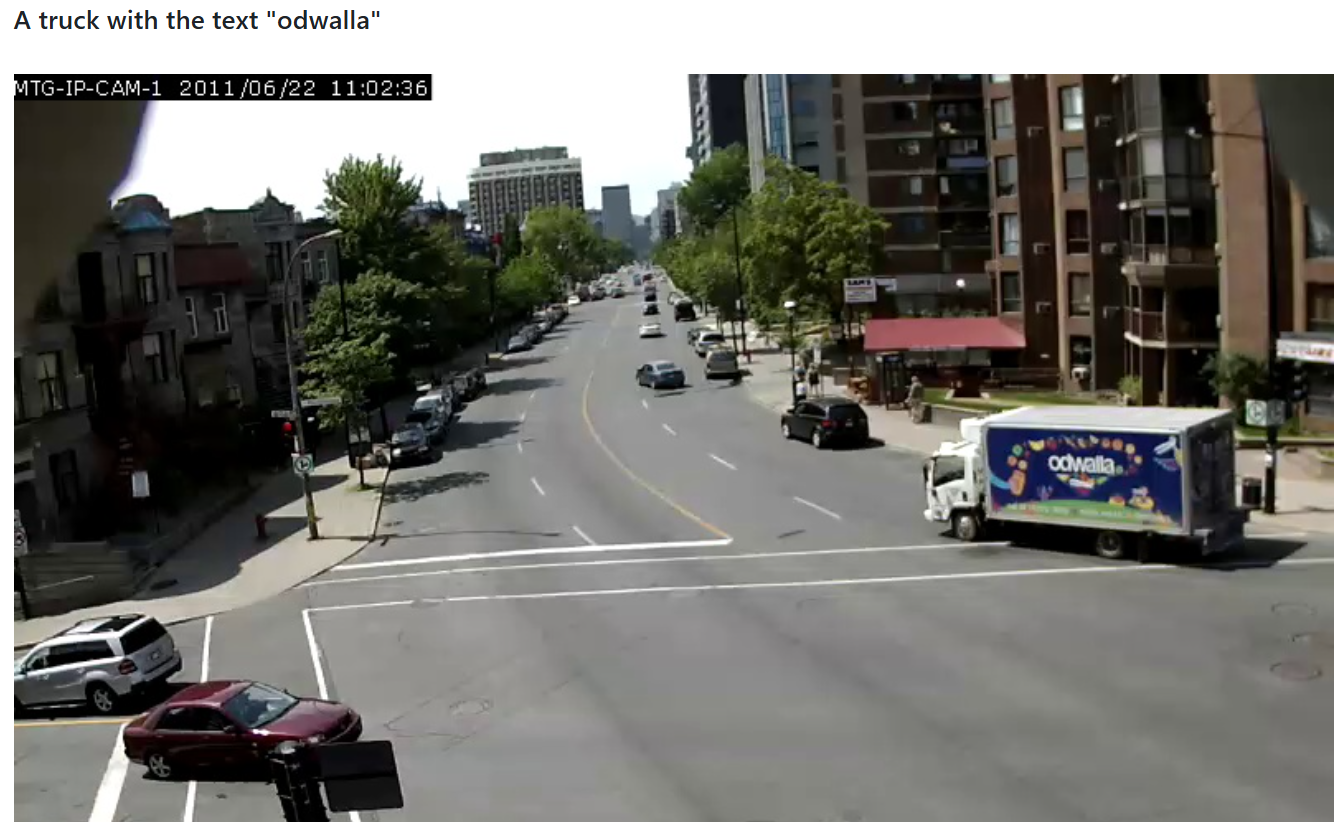
用一段文字(如“A truck with the text "odwalla"”)来搜索相关的图片、视频或音频文件。
-
用一张图片来搜索相似的图片或视频。
-
甚至用一段音频来搜索相关的图片或视频。
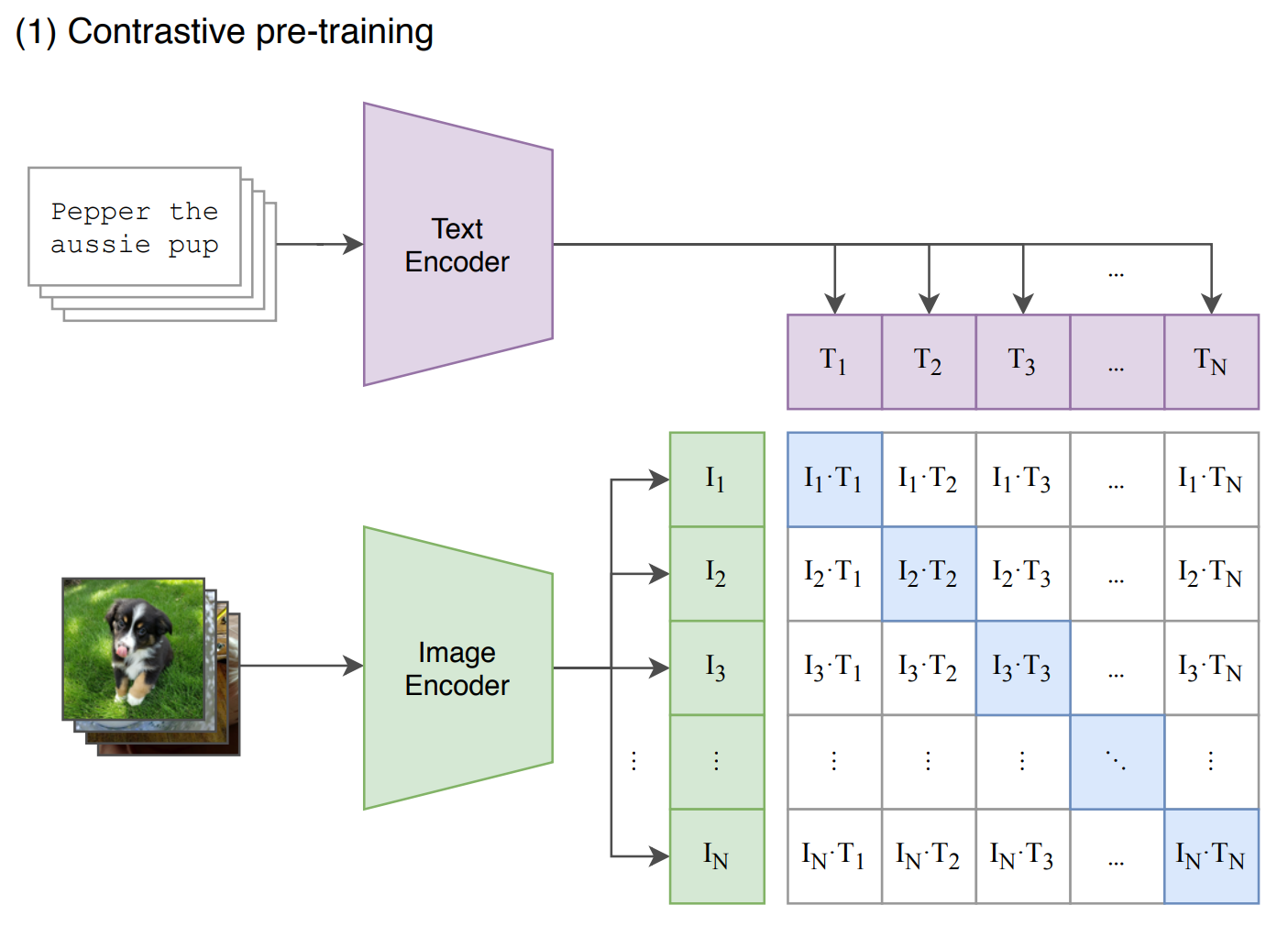
3. 架构 + prompt
构建400M 的数据集WebImageText(WIT)有4亿个图像-文本数据对
更容易训练的任务:描述性任务(根据图片预测文本) -> 对比任务(图文是否配对)大大提升训练效率。
预训练 对比学习;文本和图像分别过编码器;对角线对应的 N 个正样本;剩余 N^2-N 负样本。
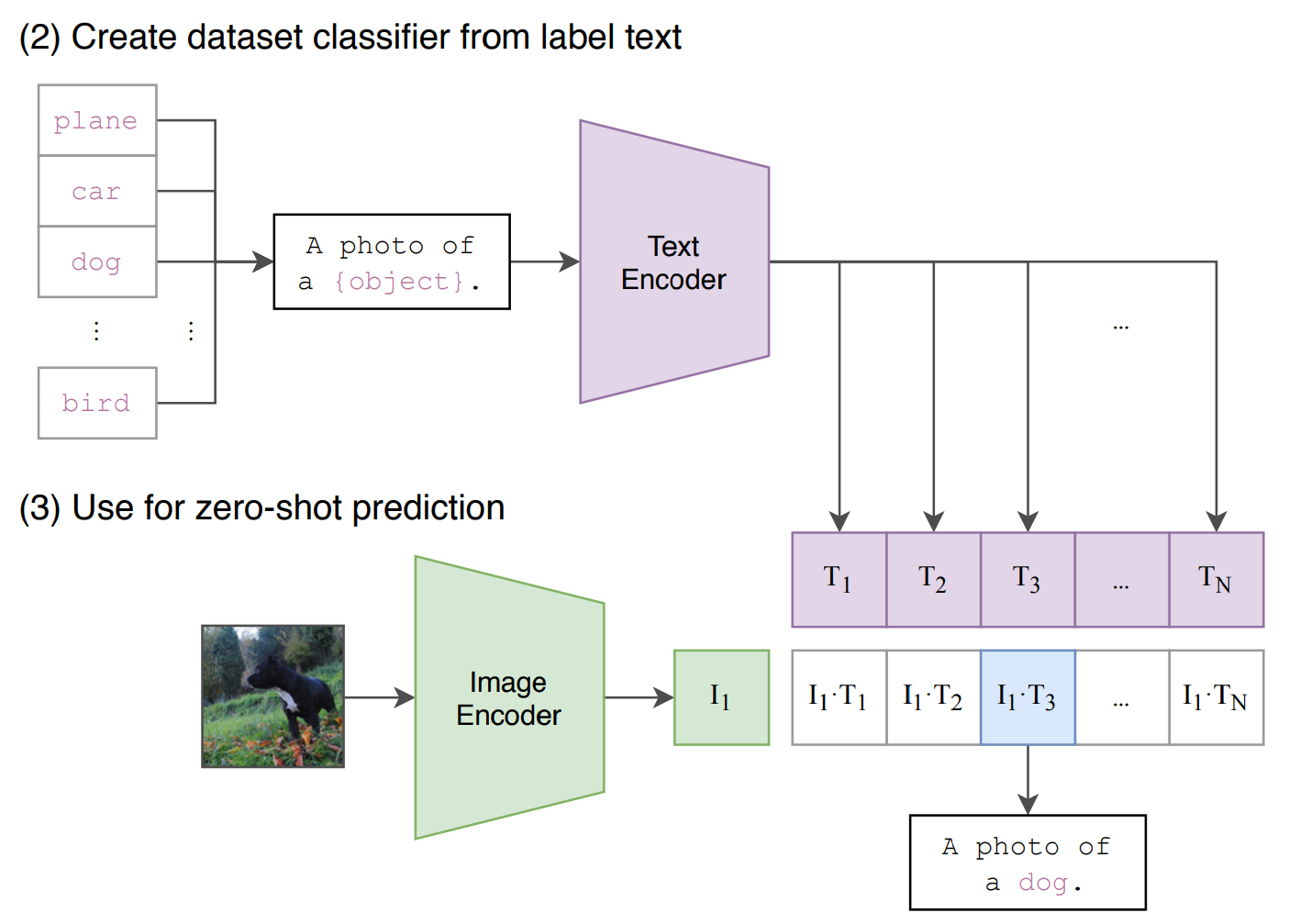
但我只学到了两个编码器 后续分类需要:
prompt engineering 特征工程
原因1:不同语境下单词的多义性 polysemy
原因2:Usually the text is a full sentence describing the image in some way. To help bridge this distribution gap, we found that using the prompt template “A photo of a {label}.”
因为预训练时 CLIP看到的都是句子,所以在应用到ImageNet上需要进行prompt template,
把只有一个单词的 [图片] 改成 a photo of [图片] ; 再看图像和哪个文本相似度最高。
# image_encoder - ResNet or Vision Transformer 图像编码器
# text_encoder - CBOW or Text Transformer 文本编码器
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed 投影
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter# 文本图像编码
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]# 投影 + 正则化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 点乘计算相似度
logits = np.dot(I_e, T_e.T) * np.exp(t)# 计算损失
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
此外 如果提前知道一些信息 明确类别:比如 Oxford-IIIT Pets 里面都是动物,Food101里面都是食物。
prompt ensembling 特征集成 template具体到物体所处的各种环境 再将结果集成。

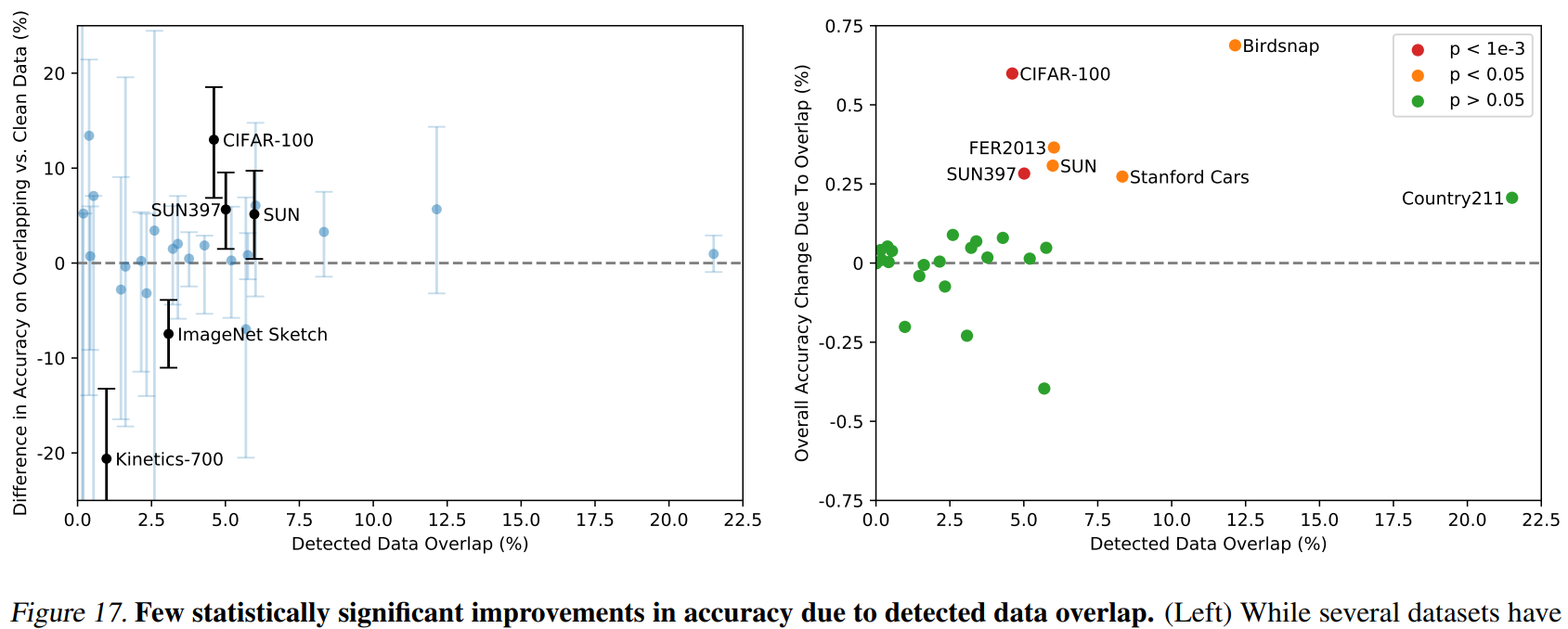
4. 实验证明泛化能力
实验结果回应 证明泛化能力 不是因为训练数据集与测试集的重合(泄题)
重合带来的增益 最多只有 Birdsnap上的 0.6%。
5. 调用实践
一个红包的图片,算与一组 text 匹配度softmax
# pip install ftfy(修复乱码) regex(加强的re正则) tqdm (进度条)
# pip install clip-anytorch(安装clip)
给一组不含红包的名词集 每个类别都有0.25上下的概率结果 代表没检索到;
含有红包的名词集合中 以很高概率显示。
对 model(image, text1) 得到的 logits_per_image 进行softmax 即可。
模型还带有 图像/文本编码器 可得编码后的特征值。
# pip install ftfy regex tqdm
# pip install clip-anytorch
import torch
import clip
from PIL import Image# 设置设备(GPU或CPU)
device = "cuda" if torch.cuda.is_available() else "cpu"# 加载CLIP模型和预处理函数
model, preprocess = clip.load("ViT-B/32", device=device)# 预处理图像并转换为张量
image = preprocess(Image.open("red_envelope.png")).unsqueeze(0).to(device)# 创建文本标签并tokenize
text1 = clip.tokenize(["money", "new year", "red", "envelope", "red envelope", "China"]).to(device)
text2 = clip.tokenize(["plane", "dog", "car", "bird"]).to(device)
# 在不计算梯度的情况下进行推理
with torch.no_grad():# 提取图像特征#image_features = model.encode_image(image)# 提取文本特征#text_features = model.encode_text(text)# 计算图像和文本之间的相似度logits_per_image1, logits_per_text = model(image, text1)logits_per_image2, logits_per_text = model(image, text2)# 将相似度转换为概率分布probs1 = logits_per_image1.softmax(dim=-1).cpu().numpy()probs2 = logits_per_image2.softmax(dim=-1).cpu().numpy()# 打印各个标签的概率
print("Label probs:", probs1) # 红包99.7%遥遥领先
# Label probs: [[5.132e-05 2.497e-05 1.556e-04 3.731e-04 9.971e-01 2.115e-03]]
print("Label probs:", probs2) # 各类别都接近 说明text中没有与图像匹配的
# Label probs: [[0.3718 0.2477 0.1367 0.2438]]2. Semantic Segmentation 语义分割
2.1 LSeg 文字驱动的语义分割
LANGUAGE-DRIVEN SEMANTIC SEGMENTATION
language guided 文字指导抠图
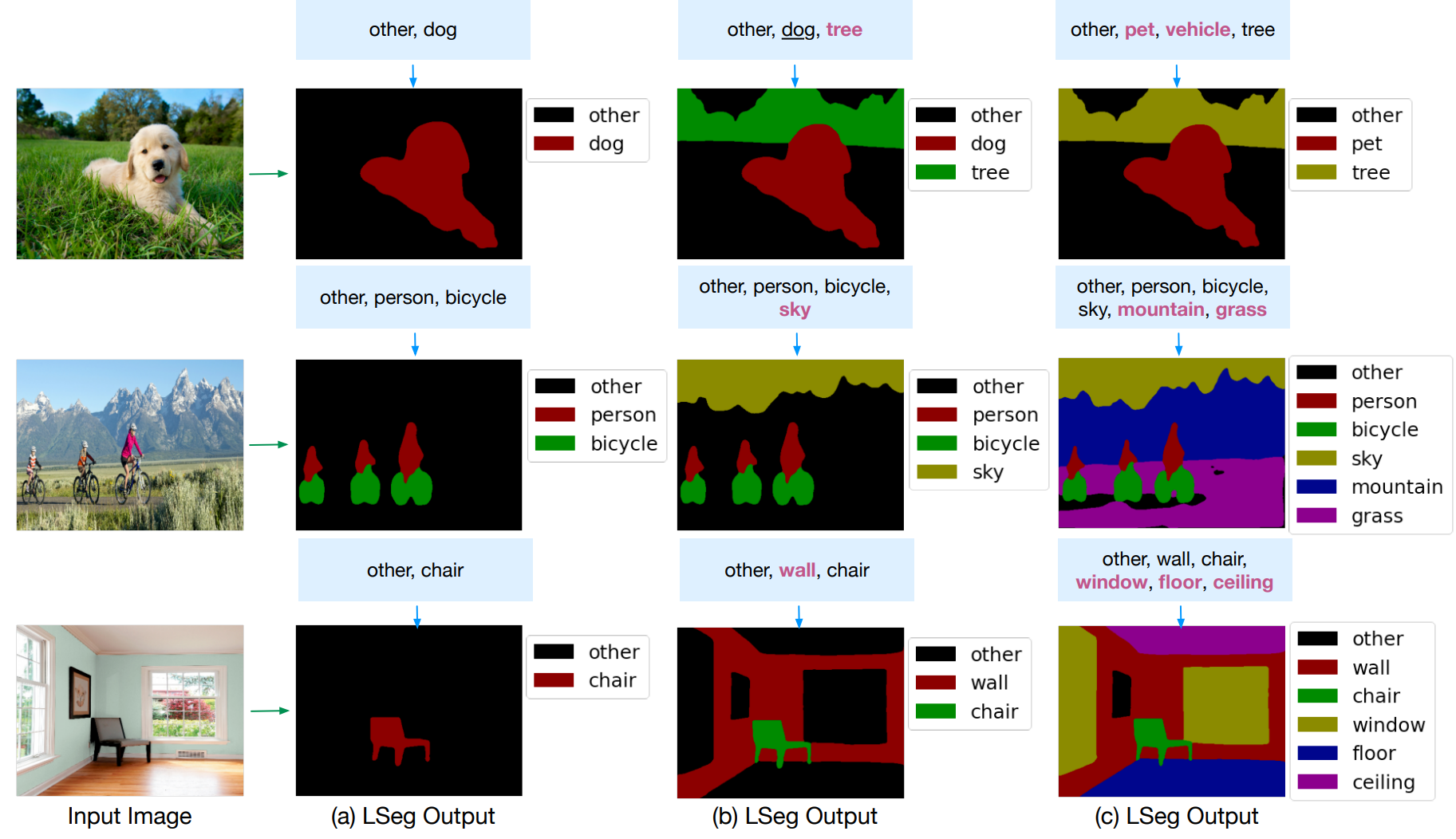
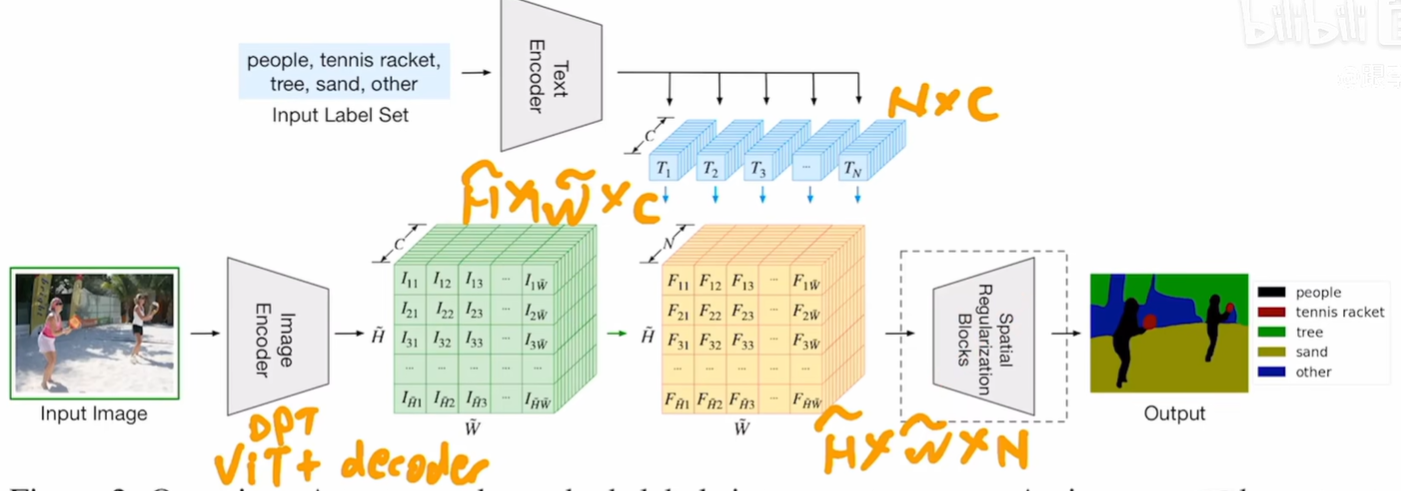
把文本 加入到传统有监督分割的图像pipeline(编码为 H*W*C)
原图像分割的升维操作 upscaling 变成与文本编码器结果(N个词 每个词特征长度为C)做内积
H*W*C 乘以 C*N 得到 H*W*N (相当于得到 每个像素 对N个类别的值) 再和 手动标注的ground truth交叉熵
文本编码器沿用CLIP的(因为训练的7个数据集太小了)训练目标函数还是有监督的。
(局限性 没有把文本当做监督信号 还是依赖于手动标注的 mask)
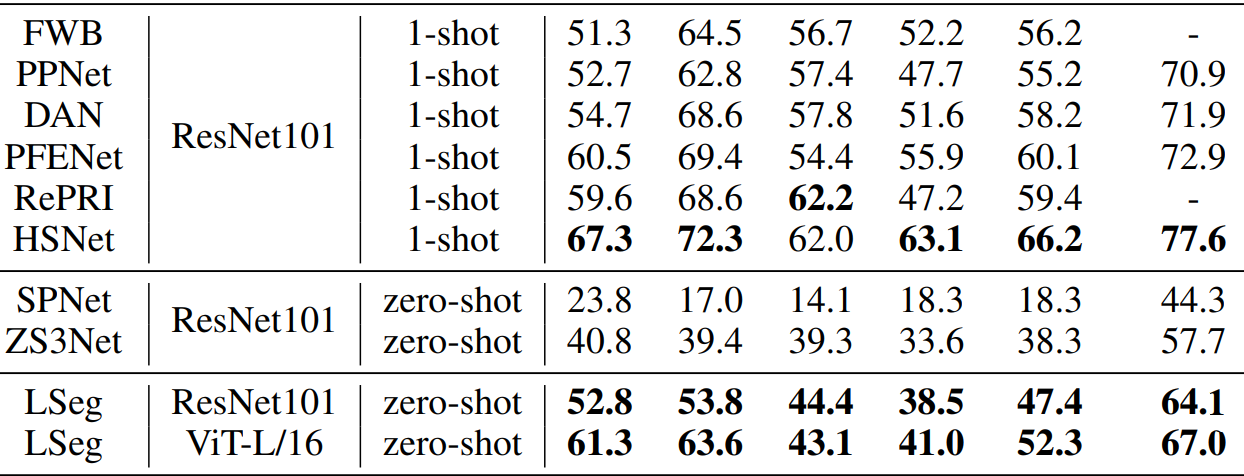
实验结果(表格前4个值 为数据4折交叉验证分别结果)
LSeg的 zero-shot 好于之前别人的zero-shot;
但即使用了ViT架构 仍然差于 之前SOTA的1-shot
2.2 GroupViT 文本监督的语义分割 聚类grouping
GroupViT: Semantic Segmentation Emerges from Text Supervision
核心问题: 能否不依赖任何像素级人工标注,仅使用图像-文本对(例如网络爬取的图片及其标题)这种更容易获取的数据,来让模型学会语义分割?
grouping思想: 将聚类中心点向周围发散 包含邻域相似点 即得到一个分割。
2.2.1 架构与训练
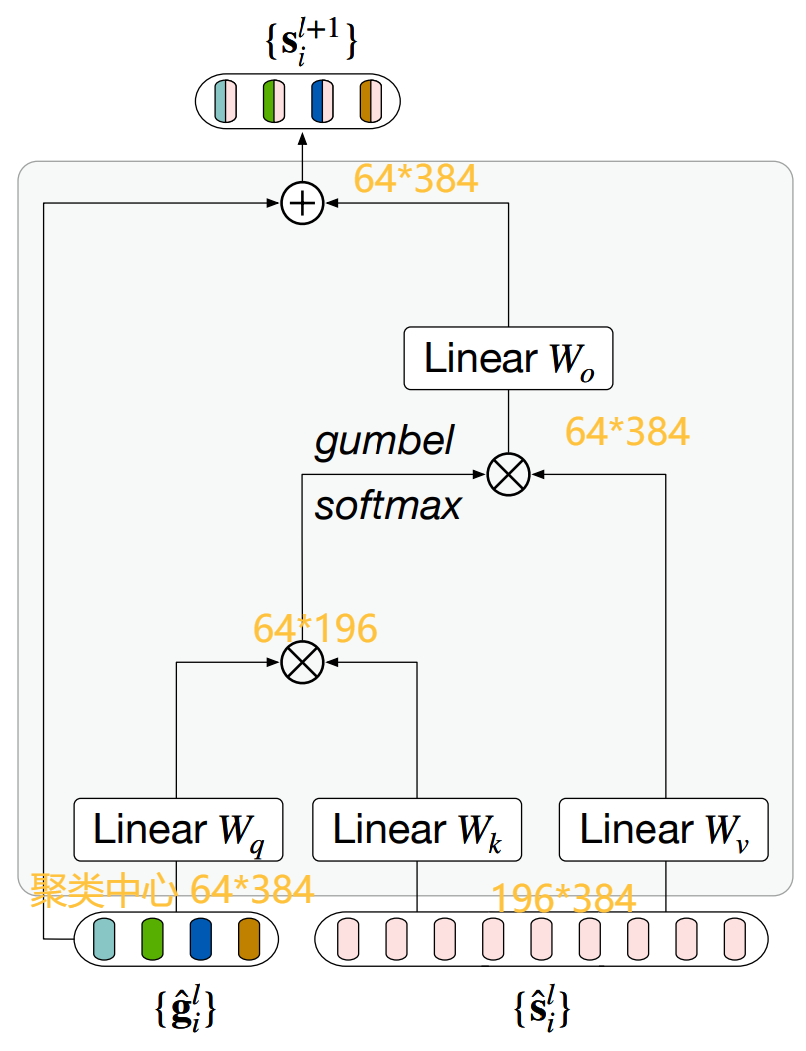
在原有ViT框架中 加入 Grouping Blocks(聚类分配) 和 learnable grouping tokens(代表聚类中心)
若特征维度都是384;图像进行ViT那样的 分割+embedding 得到14*14=196维的图像数据,再加上64个可学习聚类中心。
在 Transformer Layers 学习注意力后进行 Grouping Blocks 的聚类中心投影 得到64维数据。
再加上 8个聚类中心 同样进行 注意力学习+聚类投影。
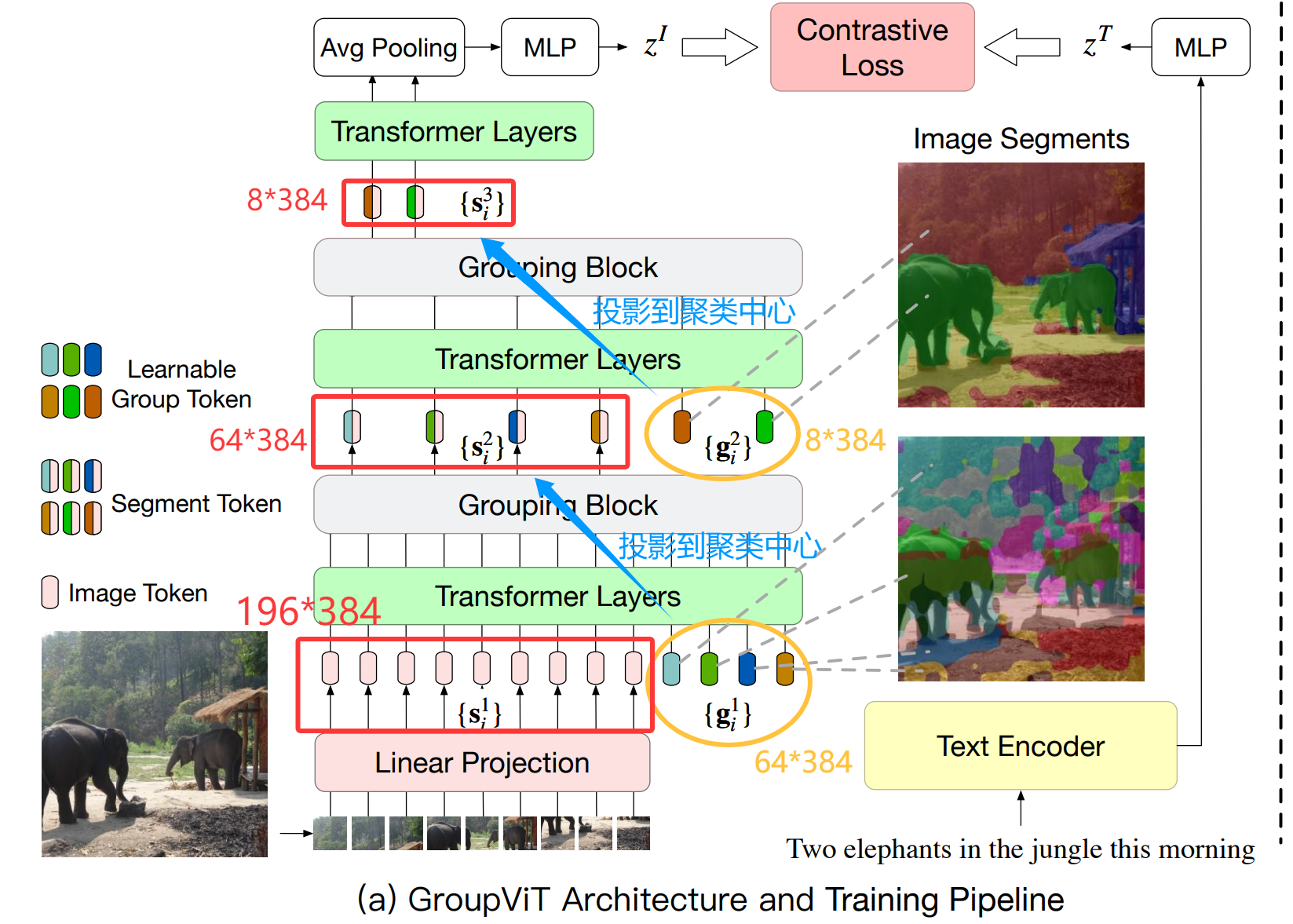
把最后的8个特征 再进行全局合并 与文本编码器结果进行对比学习。
Grouping Blocks 操作流程
q*k实现分配 想实现离散分配(每个像素点属于哪个聚类中心 类似one-hot的结果)
直接 argmax 会导致过程不可导,为使得梯度可以反向传播 进行 gumbel softmax 加入噪声+调节温度
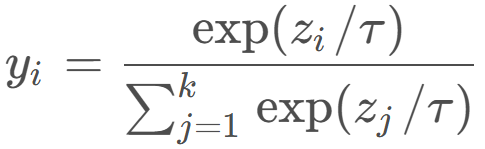
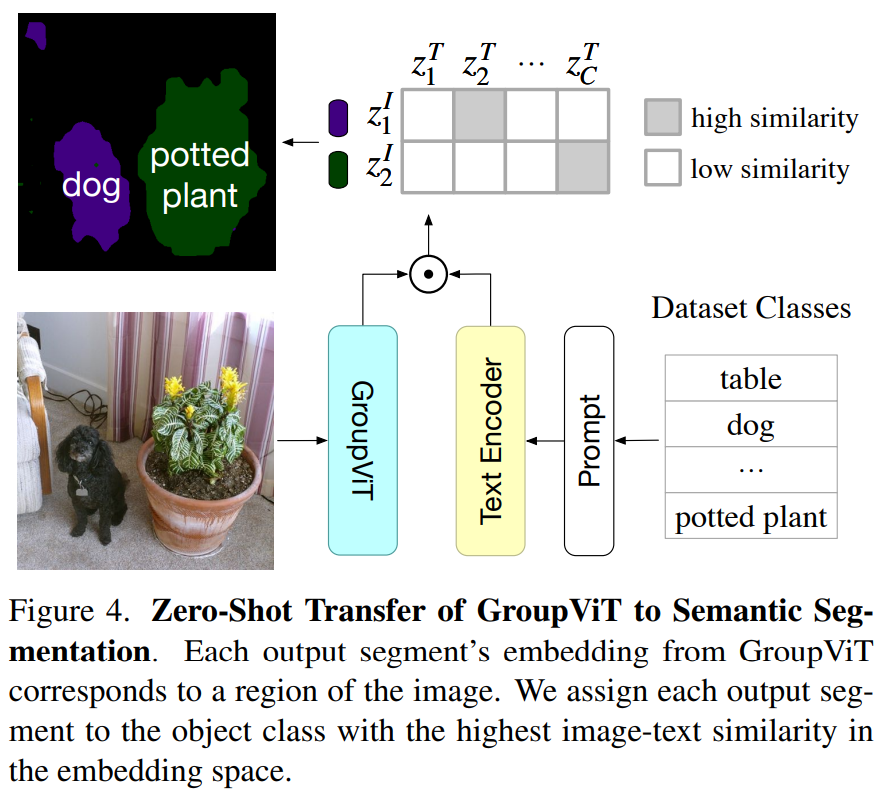
zero-shot推理 文本与得到的这8个块 相似度最高的打上标志
在实验中 对比实验发现 64/8 的grouping tokens 设置结果最好,但最后8个聚类中心,最多只能识别8个类别的一张图(局限性之一 固定组数限制)
局限性之二:没有很好的运用 dense prediction特性(像素级 细粒度)精度比较粗糙
3. ViLD 视觉语言知识蒸馏 开放词汇目标检测
OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION
目标检测 两个准确度指标 bonding box 划分的准确度 以及类别划分准确度。
但数据集标注类别很有限 叫做base category。想要具有识别 新novel 类别的能力。
检测出 训练数据已有类别base 以外的新类别 novel.
如下面这张图里 base 为标注玩具toy 三个蓝色框框;想实现 输入玩具鸭子 / 黄色玩具也能检测出来。
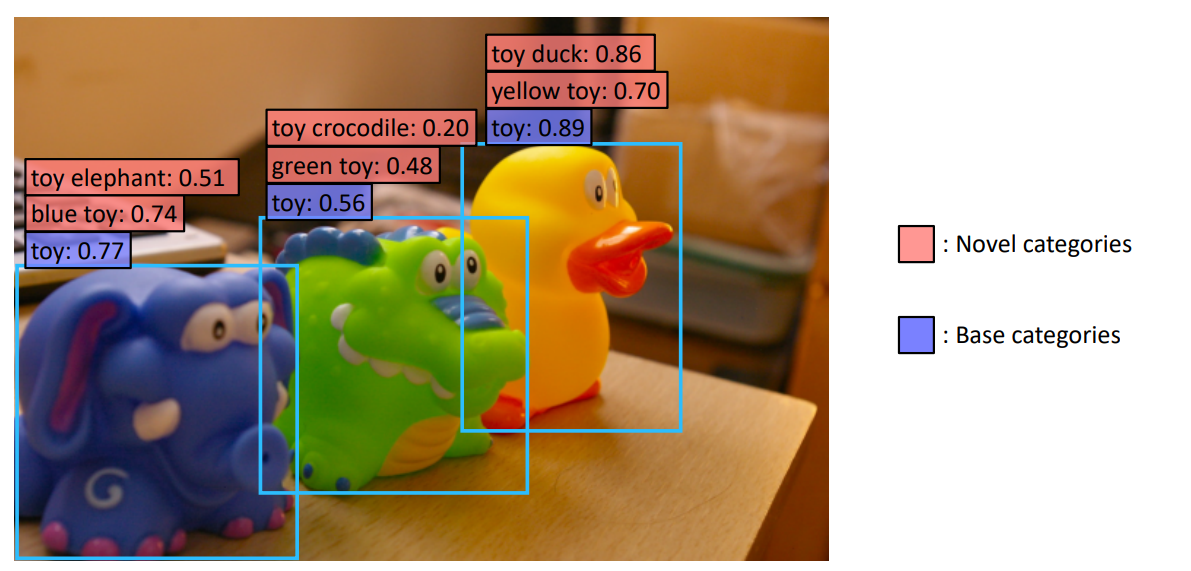
(a) baseline 两阶段检测器 R-CNN 第一阶段生成N个候选框Proposals 再第二阶段分类(本文关注第二阶段)
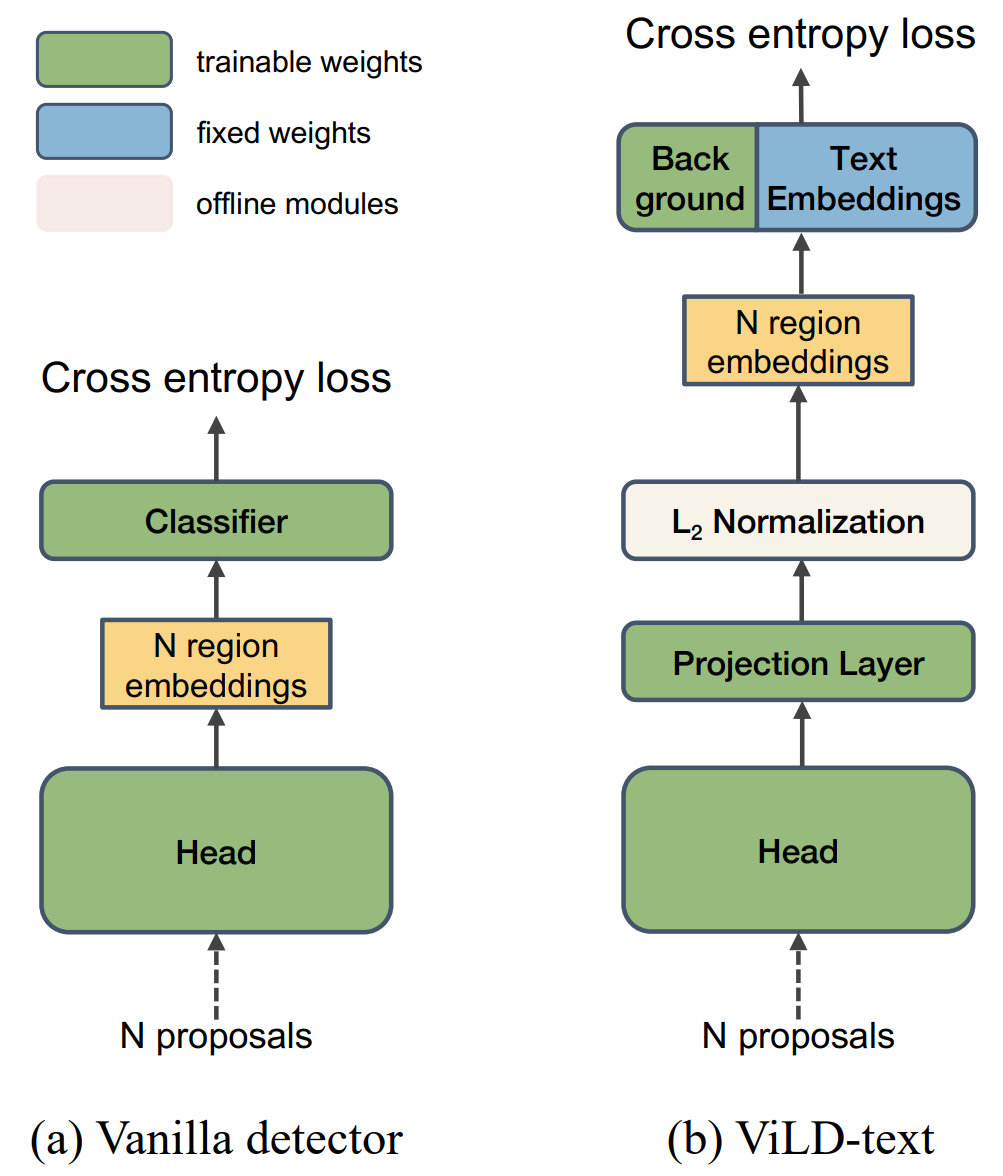
- ViLD-text:将类别名称输入预训练好的 text encoder 来得到 text embedding,然后使用推理的 text embedding 结果来对检测到的区域进行分类。ViLD-text 只从基础类别中学习,在基础类上进行有监督训练,将图像特征和文本特征联系起来。对于不在基础类里的其他类别,都归到 Background 背景类,背景类有专门的 embedding 需要学习。
输出分为基础类别和背景类。 每个区域嵌入与每个类别嵌入的余弦相似度。 再计算交叉熵损失。
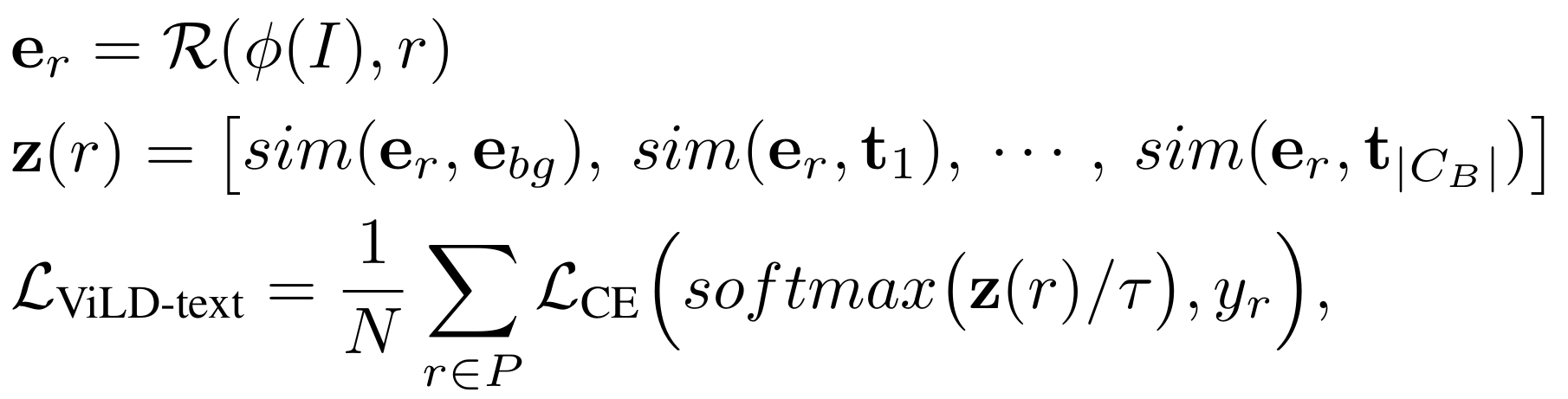
- ViLD-image:将 object proposal 经过 NMS 算法过滤(因为大的CLIP计算太贵了)后,在原图上裁剪,裁剪出的区域送入 CLIP 的 image encoder 中,得到的输出作为教师特征。然后训练一个 Mask R-CNN,使其检测到的框的区域嵌入与这些图像嵌入对齐。由于N proposals 可以检测包含新对象 novel的区域,所以 ViLD-image 会同时从基础类和新类中蒸馏知识。
CLIP教师网络 + N proposals中包含新类 实现蒸馏学习开放词汇。
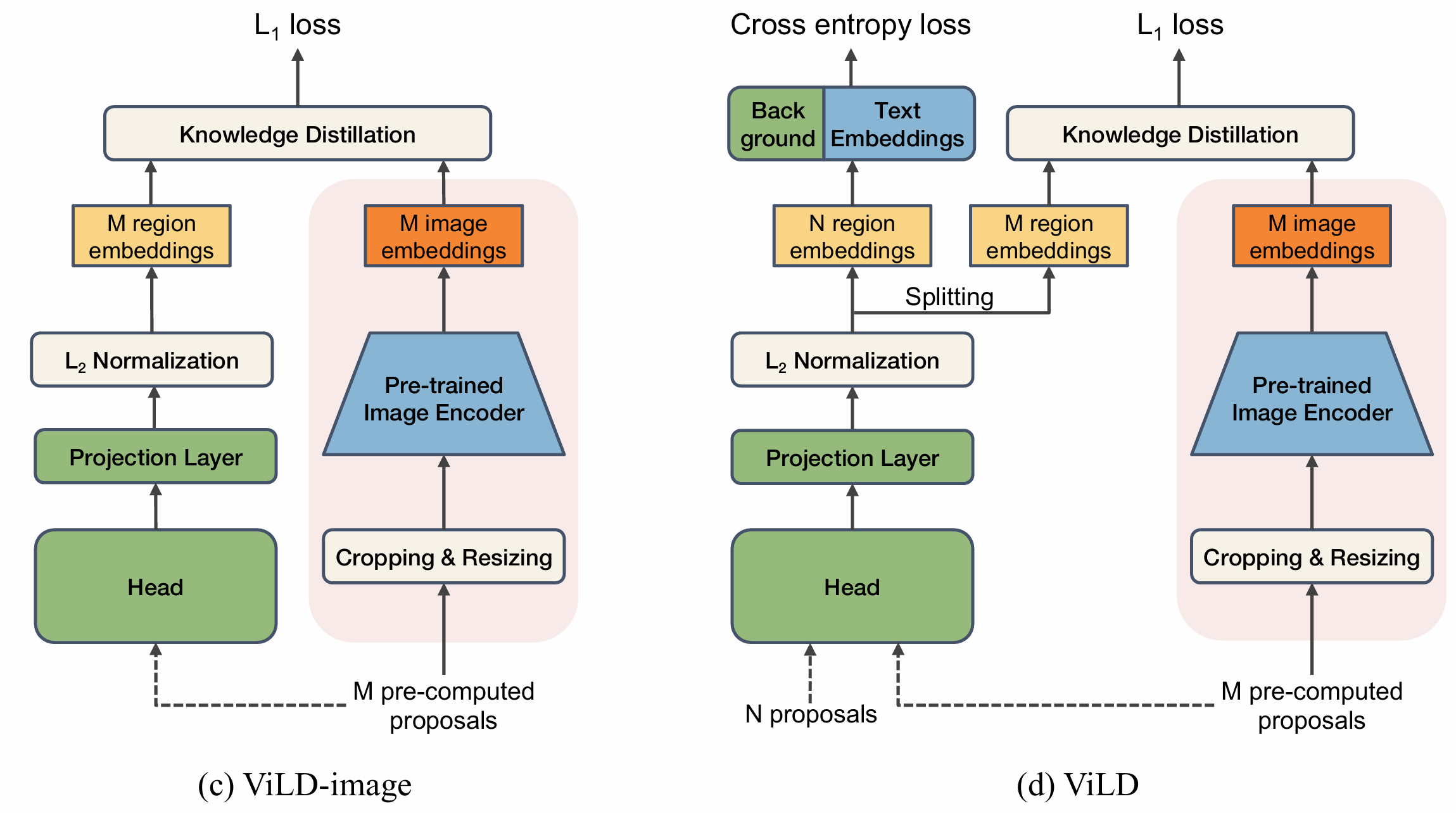
其中右边蒸馏 只在训练中使用;最后的ViLD是 text和image的综合,头-投影-正则化三部分在图像文字中都出现,所以可以输入时把 N个proposals 和 M个筛过的proposals一起输入,再splitting embeddings。
最终损失函数为两部分损失的加权和。