ICML 2025|GAPrompt:用于3D视觉模型的几何感知点云提示
论文信息
题目:GAPrompt: Geometry-Aware Point Cloud Prompt for 3D Vision Model
GAPrompt:用于3D视觉模型的几何感知点云提示
作者:Zixiang Ai、Zichen Liu、Yuanhang Lei、Zhenyu Cui、Xu Zou、Jiahuan Zhou
源码:https://github.com/zhoujiahuan1991/ICML2025-GAPrompt
论文创新点
- 提出全新提示学习方法:论文提出GAPrompt,一种专为预训练3D视觉模型设计的几何感知提示学习方法。该方法在显著降低计算和存储开销的同时,实现了与完全微调相媲美的性能。
- 设计三个关键算法模块:引入Point Prompt、Point Shift Prompter和Prompt Propagation机制这三个关键算法设计,使模型能够有效地捕捉和利用点云固有的几何信息,从而增强其表征能力。
- 展现卓越实验效果:通过在各种基准测试上进行广泛实验,证明了GAPrompt的卓越效率和有效性,在准确性和资源利用方面均优于现有方法。
- 实现细粒度几何信息捕捉:与以往方法不同,该方法不仅包含提示令牌,还能有效捕捉细粒度的点级几何信息。
摘要
预训练的3D视觉模型因其在点云数据上的出色表现而备受关注。然而,针对下游任务对这些模型进行完全微调,计算成本高昂且存储需求大。现有的参数高效微调(PEFT)方法主要聚焦于输入令牌提示,但由于其捕捉点云固有几何信息的能力有限,难以取得具有竞争力的性能。为应对这一挑战,作者提出了一种新颖的几何感知点云提示(GAPrompt),该方法利用几何线索来增强3D视觉模型的适应性。首先,作者引入了点提示,作为原始点云的辅助输入,明确引导模型捕捉细粒度的几何细节。此外,作者还提出了点移位提示器,旨在从点云中提取全局形状信息,从而在输入层面实现针对实例的几何调整。而且,作者提出的提示传播机制将形状信息融入模型的特征提取过程,进一步增强了模型捕捉关键几何特征的能力。大量实验表明,GAPrompt显著优于当前最先进的PEFT方法,并且在各种基准测试中与完全微调相比取得了具有竞争力的结果,同时仅使用了2.19%的可训练参数。
关键词
3D视觉;预训练模型;参数高效微调;几何感知;点云提示
引言
扫描传感器设备的出现极大地方便了3D点云数据的获取,这是一种本质上不规则且无结构的几何表示形式。这一进展推动了各种3D视觉应用的发展,包括3D重建(Xu等人,2022;Lu等人,2024)和自动驾驶(Zhao等人,2024)。最近,预训练的3D视觉模型(Yu等人,2022;Zhang等人,2022;Zha等人,2024)在处理点云数据方面展现出卓越的性能,使其能够通过完全微调直接应用于各种下游3D任务。然而,对整个预训练模型进行微调会带来巨大的计算成本,并且需要大量的标记数据。此外,如果不冻结预训练模型,就存在相当大的灾难性遗忘风险,这可能导致关键的预训练知识丢失。
为应对这些挑战,参数高效微调(PEFT)方法应运而生,特别是在2D视觉中,以提高预训练模型适应的效率和效果。PEFT的核心概念是冻结预训练模型,仅对新添加的模块进行微调,从而在保留原始知识的同时,弥合预训练任务与下游任务之间的分布差距。两种值得注意的PEFT策略是提示调整(Lester等人,2021;Li和Liang,2021;Liu等人,2024)和适配器调整(Houlsby等人,2019;He等人,2021)。然而,由于点云固有的稀疏性和不规则性,这些PEFT方法从2D到3D视觉的转变面临重大挑战。具体而言,随机初始化的令牌提示往往无法很好地与点云数据对齐,导致在仅由预测损失监督下游任务时难以收敛。同样,主要关注令牌特征的适配器调整,难以捕捉嵌入在3D空间中离散点分布中的关键几何信息。
最近,一些研究(Zha等人,2023;Zhou等人,2024)已经认识到开发3D特定PEFT方法的迫切需求,并初步尝试设计更适合在3D领域进行适应的网络。这些方法通常侧重于构建复杂的网络来建模令牌交互并动态生成令牌提示,或者采用动态适配器,同时生成提示令牌和适配器调整的缩放因子。然而,由于主要集中在编码输入令牌上,这些方法未能捕捉点云固有的丰富几何信息,这严重限制了它们取得具有竞争力性能的能力,如图1所示。
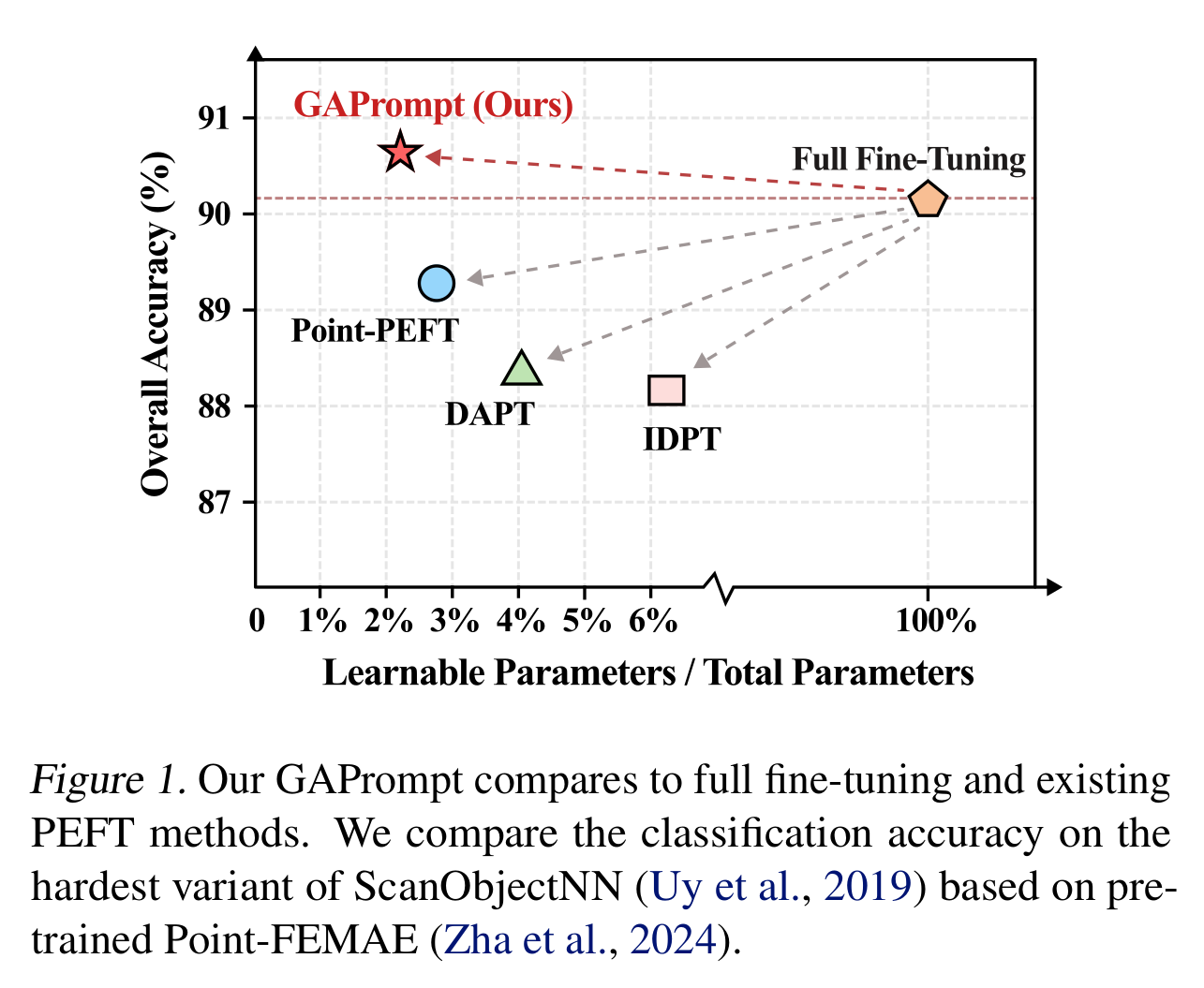
为此,作者提出了一种新颖的几何感知点云提示(GAPrompt),专门用于3D模型的参数高效微调。作者的方法从引入点提示开始,该提示明确将点云数据作为输入,使模型能够更好地捕捉微妙的几何特征。为了进一步增强利用实例特定几何信息的能力,作者引入了点移位提示器。该模块从原始点云中提取全局形状信息,并相应地移动点,从而在输入层面丰富几何特征。此外,作者提出了一种提示传播机制,将点移位提示器提取的实例形状信息无缝集成到模型的特征提取过程中。这种设计增强了模型从点云中捕捉和利用关键几何信息的能力,从而实现更准确、高效的处理。
总之,这项工作的主要贡献有:(1)作者提出了GAPrompt,这是一种专为预训练3D视觉模型设计的新颖几何感知提示学习方法。GAPrompt在显著降低计算和存储开销的同时,实现了与完全微调相当的竞争力性能。(2)作者引入了三个关键算法设计,包括点提示、点移位提示器和提示传播机制,它们共同使模型能够有效地捕捉和利用点云固有的几何信息,从而增强其表示能力。(3)在各种基准测试上进行的大量实验证明了GAPrompt卓越的效率和有效性,在准确性和资源利用方面均优于现有方法。
所提方法
作者详细阐述用于高效微调预训练3D视觉模型的GAPrompt方法,该方法包含三个几何感知提示模块:点提示、点移位提示器和提示传播机制。如图3所示,给定一个具有N个模块的预训练3D变换器和特定的下游任务,作者冻结主干网络,仅更新新引入的GAPrompt模块和分类头。
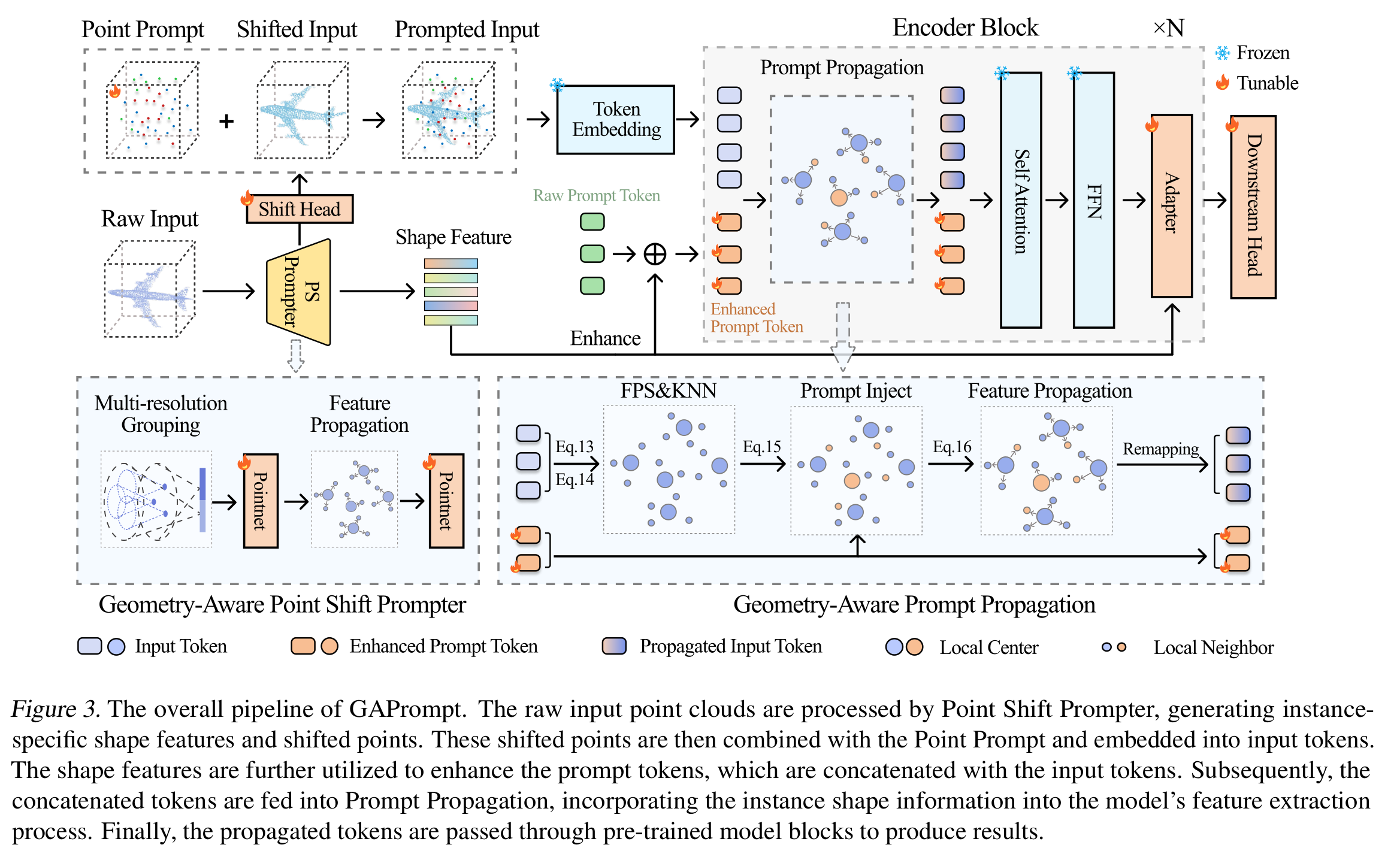
点提示
为促进对点云的明确感知并帮助模型捕捉微妙的几何特征,作者设计了点提示,它明确使用可学习的点云作为提示。与提示令牌相比,它与点云数据具有更强的内在相关性,有助于模型从本质上不规则且无结构的点云中捕捉几何特征。点提示P∈RP×3P \in \mathbb{R}^{P \times 3}P∈RP×3以均匀分布初始化:
z∼U(−r,+r)z \sim U(-r, +r)z∼U(−r,+r)
其中zzz是zzz轴上的坐标,其他两个维度具有相同的分布。rrr表示坐标单个维度的范围。
给定一个具有SSS个点的原始输入点云x∈RS×3x \in \mathbb{R}^{S \times 3}x∈RS×3,首先将点提示P∈RP×3P \in \mathbb{R}^{P \times 3}P∈RP×3混合到其3D空间中,表示为[x;P]∈R(S+P)×3[x; P] \in \mathbb{R}^{(S + P) \times 3}[x;P]∈R(S+P)×3,其中“[ ][ \ ][ ]”表示连接,PPP是可学习点的数量。此外,作者使用点移位提示器修改xxx的形状,生成一个移位后的点云x~∈RS×3\widetilde{x} \in \mathbb{R}^{S \times 3}x∈RS×3。该模块还生成特定实例的信息形状特征f∈RDf \in \mathbb{R}^{D}f∈RD,其中DDD是变换器的嵌入维度,公式表示为:
x~,f=Point-Shift-Prompter(x)\widetilde{x}, f = \text{Point-Shift-Prompter}(x)x,f=Point-Shift-Prompter(x)
然后,混合后的点云[x;P][x; P][x;P]成为带提示的输入点云[x~;P]∈R(S+P)×3[\widetilde{x}; P] \in \mathbb{R}^{(S + P) \times 3}[x;P]∈R(S+P)×3。
按照预训练模型的原始架构,带提示的点云由令牌嵌入模块编码为LtL_tLt个点令牌h1h_1h1。作者将第iii个模块的输入令牌表示为hi∈RLt×Dh_i \in \mathbb{R}^{L_t \times D}hi∈RLt×D。之后,将输入令牌hih_ihi与由形状特征fff增强的LpL_pLp个提示令牌pi∈RLp×Dp_i \in \mathbb{R}^{L_p \times D}pi∈RLp×D连接,表示为[hi;pi][h_i; p_i][hi;pi]。然后将这些令牌输入到作者的提示传播机制中,将提示令牌注入到特征提取过程中:
h~i=Prompt-Propagation([hi;pi])\widetilde{h}_i = \text{Prompt-Propagation}([h_i; p_i])hi=Prompt-Propagation([hi;pi])
其中h~i∈RLt×D\widetilde{h}_i \in \mathbb{R}^{L_t \times D}hi∈RLt×D是传播后的输入令牌。最后,作者将带有增强提示令牌pip_ipi的h~i\widetilde{h}_ihi输入到视觉变换器注意力层,该层由自注意力层和前馈层组成。此外,作者使用由形状特征fff增强的适配器调整令牌。
h^i,p^i=Attn.([h~i,pi])\widehat{h}_i, \widehat{p}_i = \text{Attn.}([\widetilde{h}_i, p_i])hi,pi=Attn.([hi,pi])
hi+1=h^i+Adapter(h^i+f⋅βa)h_{i + 1} = \widehat{h}_i + \text{Adapter}(\widehat{h}_i + f \cdot \beta_a)hi+1=hi+Adapter(hi+f⋅βa)
其中h^i,p^i∈RLt×D\widehat{h}_i, \widehat{p}_i \in \mathbb{R}^{L_t \times D}hi,pi∈RLt×D是注意力层的中间输出,βa\beta_aβa是用于增强适配器的比例因子。在接下来的部分,作者将分别展示点移位提示器和提示传播的细节。
点移位提示器
除了使用点提示捕捉微妙的几何细节外,作者还利用点移位提示器从原始输入点云中提取有信息的形状特征。如前所述,为相应地调整点云形状,作者将点级形状特征通过一个浅移位头,为每个输入点生成一个坐标移位。此外,形状特征可用于增强提示令牌和适配器的几何感知。
形状特征
具体而言,为在不产生过多计算成本的情况下获取点云的全局形状信息,作者采用分层下采样策略。如图3所示,原始输入点云xxx通过参考PointNet++(Qi等人,2017b)的多分辨率分组进行采样,在第jjj个分辨率级别通过最远点采样(FPS)迭代找出CjC_jCj个中心点xj∈RCj×3x_j \in \mathbb{R}^{C_j \times 3}xj∈RCj×3。然后,作者使用K近邻(KNN)算法分别找出与每个中心点对应的KjK_jKj个邻点nj∈RCj×Kj×3n_j \in \mathbb{R}^{C_j \times K_j \times 3}nj∈RCj×Kj×3:
xj+1=FPS(xj)x_{j + 1} = \text{FPS}(x_j)xj+1=FPS(xj)
nj=KNN(xj,xj+1)n_j = \text{KNN}(x_j, x_{j + 1})nj=KNN(xj,xj+1)
获取这样的分层空间信息后,作者使用轻量级点网(Qi等人,2017a)将点坐标xjx_jxj嵌入到特征dj∈RCj×Djd_j \in \mathbb{R}^{C_j \times D_j}dj∈RCj×Dj中,该点网是卷积层的组合,公式表示为:
d~j=Pointnet(xj)\widetilde{d}_j = \text{Pointnet}(x_j)dj=Pointnet(xj)
经过kkk级下采样后,作者获得中心点特征d~k∈RCk×Dk\widetilde{d}_k \in \mathbb{R}^{C_k \times D_k}dk∈RCk×Dk,其中Ck×Dk=DC_k \times D_k = DCk×Dk=D,并将它们连接为形状特征fff,
f=Reshape(d~k)∈RDf = \text{Reshape}(\widetilde{d}_k) \in \mathbb{R}^{D}f=Reshape(dk)∈RD
这就是输入点云的整体形状信息。
移位输入
此外,为为每个点生成特定实例的移位,作者需要获取所有原始点xxx的特征。首先,采用上采样策略将特征从中心点传播到邻点。然后,作者使用另一个点网进一步处理这些特征:
d~jn=Pointnet(Propagate(d~j))\widetilde{d}^n_j = \text{Pointnet}(\text{Propagate}(\widetilde{d}_j))djn=Pointnet(Propagate(dj))
其中d~jn∈RCj×Kj×Dj\widetilde{d}^n_j \in \mathbb{R}^{C_j \times K_j \times D_j}djn∈RCj×Kj×Dj是第jjj级邻点njn_jnj的特征。从第kkk级上采样到第1级后,特征传播过程产生d~1n\widetilde{d}^n_1d1n。作者将d~1n\widetilde{d}^n_1d1n和d~1\widetilde{d}_1d1连接并输入到一个小的多层感知器(MLP),即移位头,以生成x~\widetilde{x}x:
x~=Shift-Head([d~1n,d~1])\widetilde{x} = \text{Shift-Head}([\widetilde{d}^n_1, \widetilde{d}_1])x=Shift-Head([d1n,d1])
此外,形状特征f∈RDf \in \mathbb{R}^{D}f∈RD可用于增强提示令牌,赋予其丰富的几何感知:
pi=pi′+f⋅βpp_i = p'_i + f \cdot \beta_ppi=pi′+f⋅βp
其中pi′∈RLp×Dp'_i \in \mathbb{R}^{L_p \times D}pi′∈RLp×D表示原始提示令牌,pi∈RLp×Dp_i \in \mathbb{R}^{L_p \times D}pi∈RLp×D是增强后的提示令牌,βp\beta_pβp是比例因子。
提示传播
通过点移位提示器用全局形状特征增强提示令牌后,作者进一步利用这些令牌增强模型的几何感知。为实现这一点,作者设计了一种提示传播机制,将特定实例的形状信息集成到模型的特征提取过程中。
给定第iii个模块中的一组输入令牌[hi;pi]∈R(Lt+Lp)×D[h_i; p_i] \in \mathbb{R}^{(L_t + L_p) \times D}[hi;pi]∈R(Lt+Lp)×D,作者可以通过FPS和KNN找到输入令牌之间的几何关系。公式表示如下:
hic=FPS(hi)h^c_i = \text{FPS}(h_i)hic=FPS(hi)
hin=KNN(hi,hic)h^n_i = \text{KNN}(h_i, h^c_i)hin=KNN(hi,hic)
随后,作者将增强后的提示令牌pip_ipi随机替换到hich^c_ihic和hinh^n_ihin的输入令牌中,即提示注入。ccc和nnn分别表示中心点和邻点的索引。受随机失活(dropout)思想(Srivastava等人,2014)的启发,提示注入过程使作者的模型在适应下游任务时更加稳健。在消融研究中将详细讨论各种交替的替换方法。作者将此过程公式表示为:
hic′,hin′=Inject(hic,hin,pi)h^{c'}_i, h^{n'}_i = \text{Inject}(h^c_i, h^n_i, p_i)hic′,hin′=Inject(hic,hin,pi)
其中hic∈RC×Dh^c_i \in \mathbb{R}^{C \times D}hic∈RC×D,hin∈RC×K×Dh^n_i \in \mathbb{R}^{C \times K \times D}hin∈RC×K×D表示由中心点和邻点索引的令牌,hic′,hin′h^{c'}_i, h^{n'}_ihic′,hin′表示注入后的令牌。然后作者将特征从局部中心点传播到所有输入令牌,公式表示为:
h~i=Propagate(hic′)\widetilde{h}_i = \text{Propagate}(h^{c'}_i)hi=Propagate(hic′)
其中h~i\widetilde{h}_ihi是传播后的输入令牌。
更多关于公式15和16的细节可在附录中找到。
作者方法的核心在于增强提示令牌的策略性注入。没有这种增强,输入令牌之间的传播过程将导致平凡解,性能提升甚微。具体而言,当提供中心点的特征,并以计算邻点的特征为目标时,作者的传播机制执行特征插值。这种插值利用了中心点和邻点之间的空间距离,使模型能够有效地在令牌之间传递和细化特征信息,从而确保性能提升。
分析与讨论
作者方法的目标是通过整合几何感知提示机制来促进特定任务的模型适应。与先前的方法相比,作者的方法不仅包含提示令牌,还能有效捕捉细粒度的点级几何信息。带有提示整合的注意力机制可以正式表示如下:
oi=Attn.(WQhi,WKhi,WVhi)o_i = \text{Attn.}(W_Qh_i, W_Kh_i, W_Vh_i)oi=Attn.(WQhi,WKhi,WVhi)
o^i=Attn.(WQhi,WK[pi,hi],WV[pi,hi])\widehat{o}_i = \text{Attn.}(W_Qh_i, W_K[p_i, h_i], W_V[p_i, h_i])oi=Attn.(WQhi,WK[pi,hi],WV[pi,hi])
其中oio_ioi和o^i\widehat{o}_ioi分别表示没有和有提示整合的注意力输出。
基于(He等人,2021)建立的理论,作者可以推导出公式18的等效变换为:
o^i=∑pk∈piAikWVpk+(1−∑kAik)oi\widehat{o}_i = \sum_{p_k \in p_i} A_{ik}W_Vp_k + (1 - \sum_{k} A_{ik})o_ioi=pk∈pi∑AikWVpk+(1−k∑Aik)oi
其中AikA_{ik}Aik表示变换器为查询hih_ihi分配给提示pkp_kpk的注意力权重。这个公式揭示了两个关键方面:软提示机制诱导头部位置输出的线性插值,偏差项有助于在偏移子空间内进行适应。
作者方法的关键区别在于点级操作,解决了先前主要在令牌级操作的提示方法的局限性。由于现有方法在令牌级适应约束下往往难以捕捉细粒度的几何特征,作者的点提示和点移位提示器机制直接在公式17和公式18中调制hih_ihi,能够在点级精确调整潜在空间。这种操作粒度的根本差异有助于增强几何特征表示,并使点云模型更有效地进行模型适应。
实验
作者在点云分类任务上评估所提出的GAPrompt的性能。作者使用四个预训练模型Point-MAE(Pang等人,2022)、ReCon(Qi等人,2023)、Point-GPT(Chen等人,2024)和Point-FEMAE(Zha等人,2024)作为基线。为进行公平比较,作者对每个基线采用与完全微调方法相同的数据增强。超参数设置为βa=0.5\beta_a = 0.5βa=0.5,βp=0.5\beta_p = 0.5βp=0.5和P=20P = 20P=20。关于βa\beta_aβa和PPP的更多分析可在附录中找到。
实验设置
ScanObjectNN:ScanObjectNN(Uy等人,2019)是一个极具挑战性的3D数据集,包含15个类别中的15000个真实世界物体。这些物体由扫描获得的室内场景数据组成,具有杂乱背景和遮挡等特征。如表1所示,作者在ScanObjectNN的三个变体上进行实验,每个变体的复杂度逐渐增加。注意,作者在ScanObjectNN数据集上的实验为每个点云采样2048个点作为输入,与先前工作(Wang等人,2021;Liu等人,2022)一致。
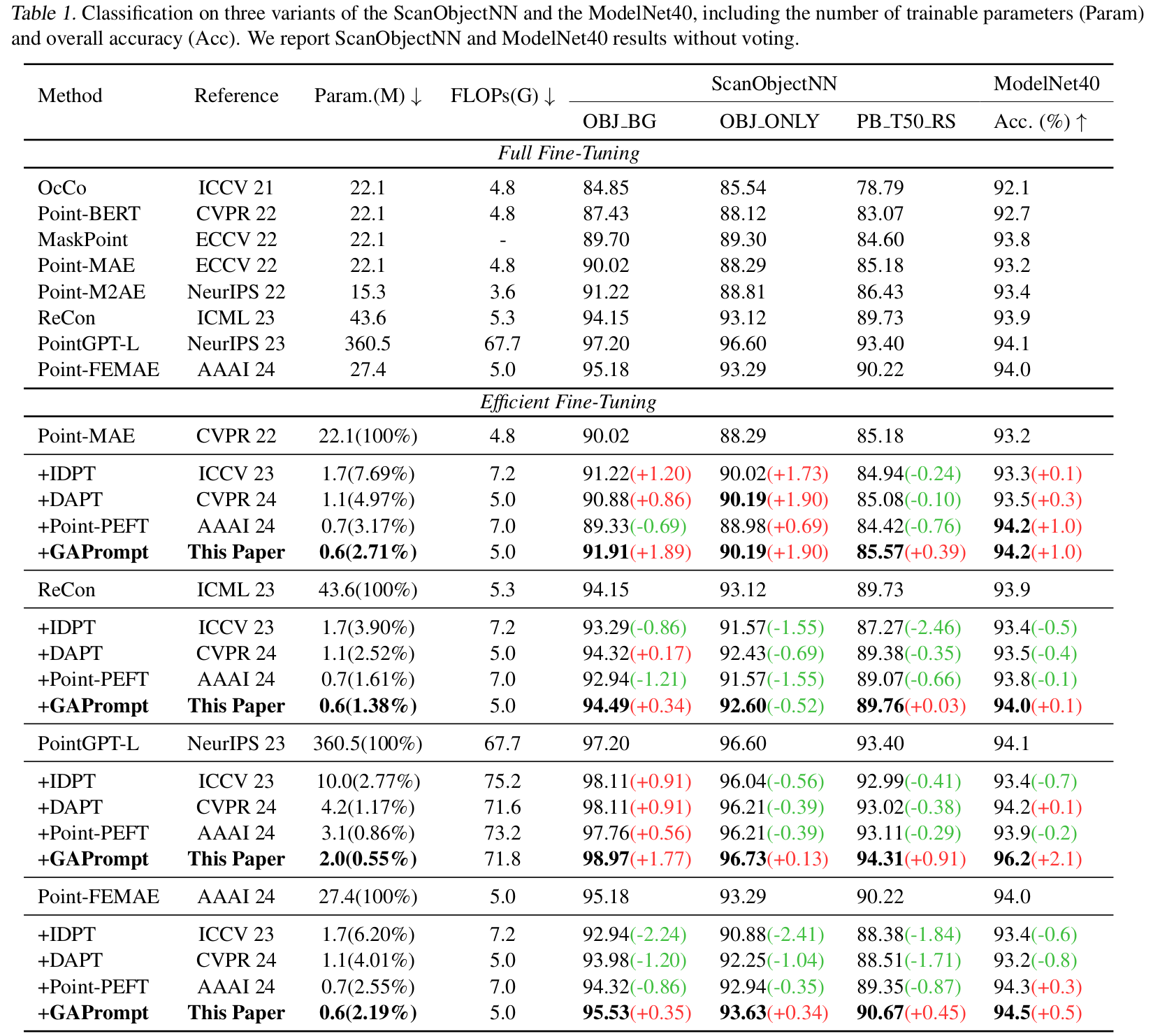
ModelNet40:ModelNet40(Wu等人,2015)包含40个类别的12311个原始3D CAD模型,其点云完整、均匀且无噪声,简化了任务。遵循基线,作者为每个实例采样1024个点。由于投票(Liu等人,2019)耗时,作者主要报告不进行投票的总体准确率。
定量分析
ScanObjectNN上的性能:如表1所示,作者的方法GAPrompt在所有3D视觉模型的参数高效微调方法中实现了最高准确率。此外,作者甚至在ScanObjectNN的OBJ BG变体上分别比Point-MAE、ReCon、Point-GPT和Point-FEMAE的完全微调高出1.89%、0.34%、1.77%、0.35%,并减少了超过97%的可训练参数。这归因于作者的GAPrompt能够捕捉原始点云的特定实例几何信息,并有效地将其整合到预训练模型的特征提取过程中。相比之下,IDPT、DAPT和Point-PEFT由于从点云中捕捉几何信息的能力有限,未能达到完全微调的性能。此外,作者的方法在效率和计算成本方面也很突出。仅使用0.6M可训练参数,作者的GAPrompt所需的参数远少于IDPT和DAPT。在FLOPs方面,与基线相比,作者的方法几乎没有增加额外的计算负担,显著优于IDPT和Point-PEFT。这归功于作者轻量级的点移位提示器和无参数的提示传播机制。
ModelNet40上的性能:如表1所示,尽管ModelNet40上的结果几乎已饱和,但由于从点云中提取的特定实例形状特征和对点云的明确感知,作者的GAPrompt仍优于先前的工作。此外,即使使用少于3%的可训练参数和少于0.1G FLOPs的计算增量,GAPrompt在所有四个基线上都取得了正增长,这验证了即使在无噪声点云上采用几何信息进行提示的有效性和高效性。值得注意的是,作者的GAPrompt基于Point-GPT,在基本的缩放和平移增强且不进行投票的情况下,达到了96.2%的当前最优性能。
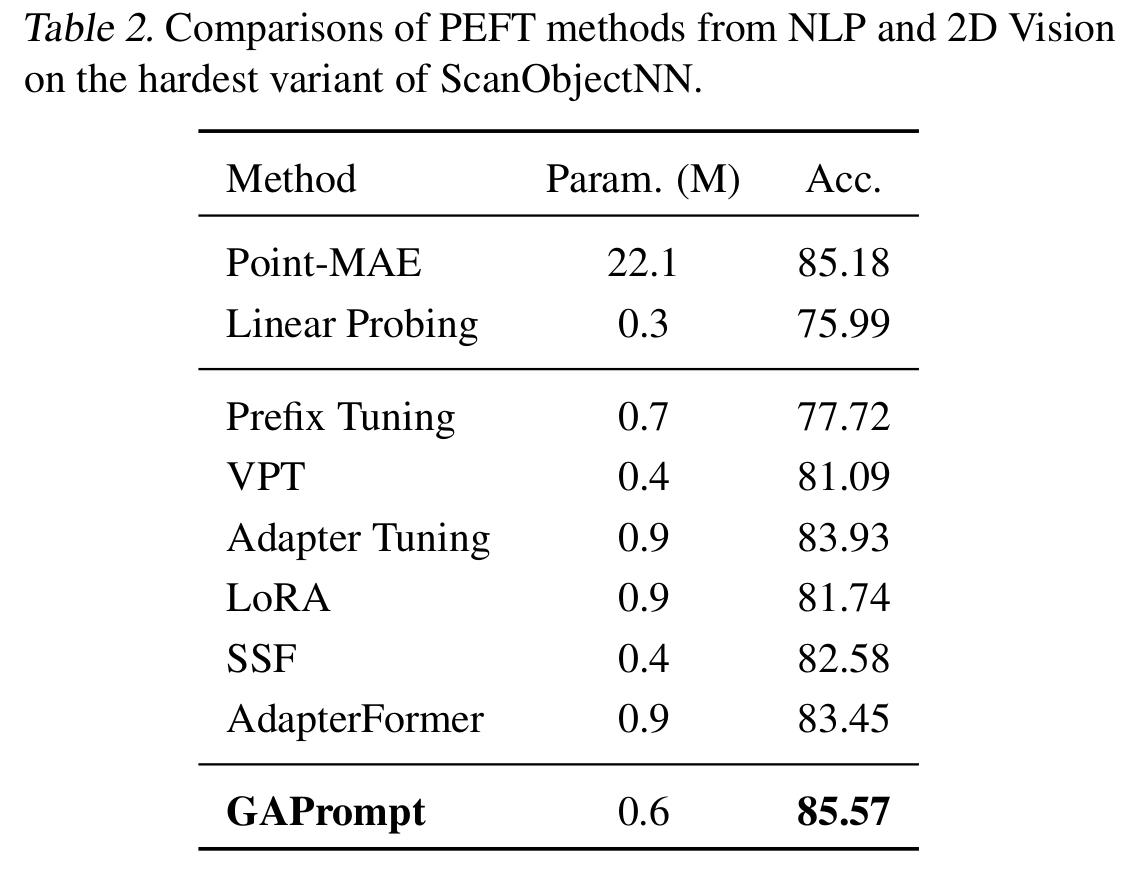
与PEFT方法的比较:为进一步说明作者方法的优越性,作者将GAPrompt与来自自然语言处理(NLP)和2D视觉的几种PEFT方法(Chen等人,2022;Lian等人,2022)进行比较。如表2所示,作者选择最复杂的PB T50 RS变体,以Point-MAE为基线。尽管这些基本方法相对于线性探测有不同程度的改进,但由于点云结构的不规则性和复杂性,与完全微调仍存在相当大的性能差距。作者具有3D特定设计的方法分别比VPT和Adapter高出4.48%和1.64%,这归因于将特定实例形状特征整合到预训练模型的特征提取中。此外,作者的GAPrompt与这些基本方法相比,可训练参数相当,这归因于点移位提示器的紧凑设计,它直接从点云中提取几何特征。
消融研究
作者在基于Point-FEMAE的最具挑战性的PB T50 RS变体上进行消融研究,以探究作者的GAPrompt的合理性和有效性。
主要组件分析
如表3所示,为量化每个主要组件的贡献,作者逐步进行消融实验,直至完整的GAPrompt方案。仅引入点提示时,性能可达87.85%,这是因为它促进了对点云的明确感知并帮助模型捕捉微妙的几何特征。然后添加点移位提示器,由于捕捉到特定实例的几何信息,性能提升1.89%。最后,使用提示传播机制将结果提升至90.67%,超过了完全微调,这归因于将增强的提示整合到预训练模型的特征提取中。

点移位提示器组件的效果
如表4所示,作者以递增的方式评估点移位提示器中每个组件的有效性。基本上,作者仅使用移位头生成移位后的点云作为编码器的输入,准确率达到88.23%。此外,分别用提取的形状特征增强提示和适配器,可将性能提升至峰值。这种提升归因于特定实例的形状特征提高了令牌提示和适配器的几何感知。
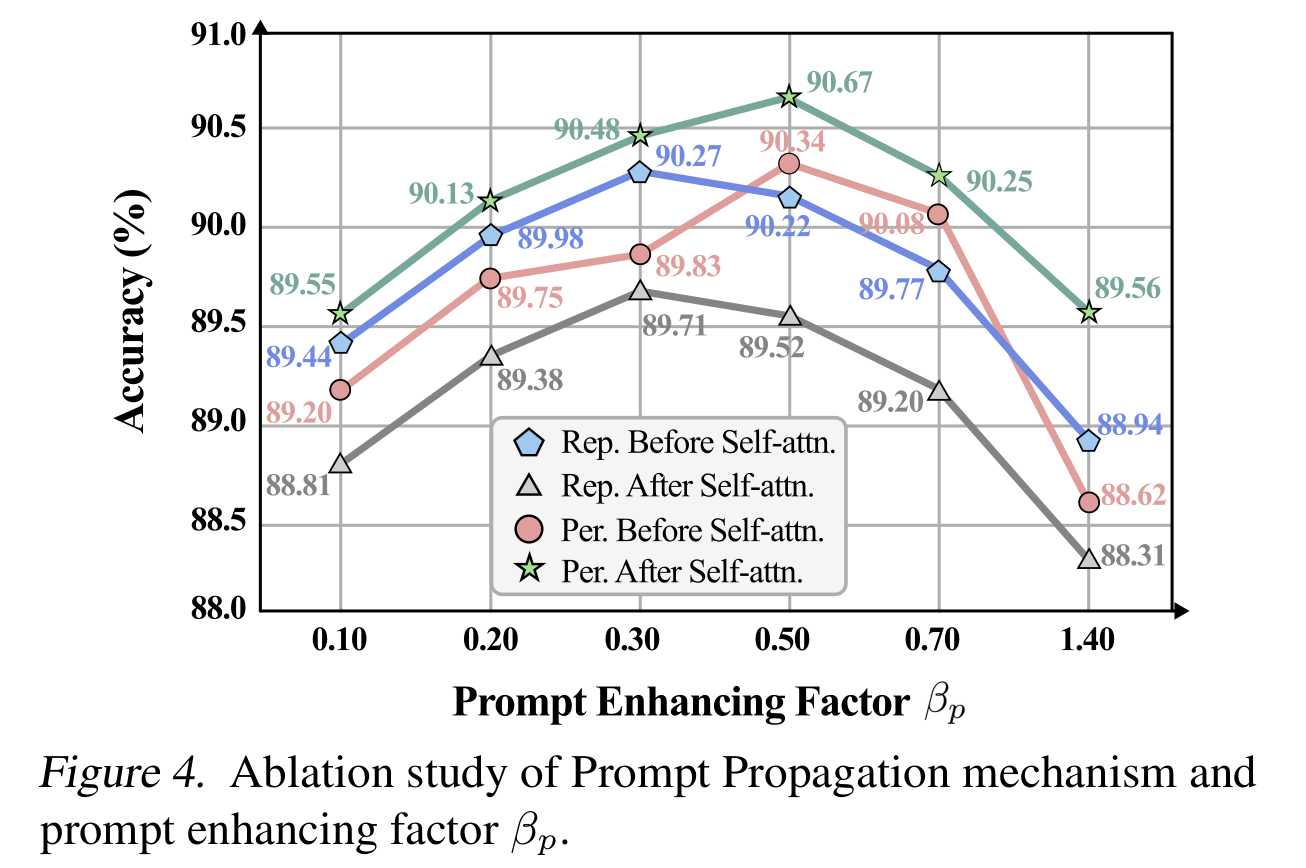
提示传播设置和βp\beta_pβp的分析
如图4所示,作者对提示传播设置和提示增强因子βp\beta_pβp进行消融实验。作者的提示传播机制有两种交替方式,在自注意力层之前或之后操作,表示为“Before Self-attn.”和“After Self-attn.”。此外,作者设计了两种不同的提示注入选项,分别通过直接替换和间接排列实现。这些选择的组合产生了图4中的四条曲线。很明显,在自注意力层之后使用排列并将βp\beta_pβp设为0.5可获得最佳性能。直观地说,这是因为这种设置带来了更多的随机性,导致更稳健的收敛。
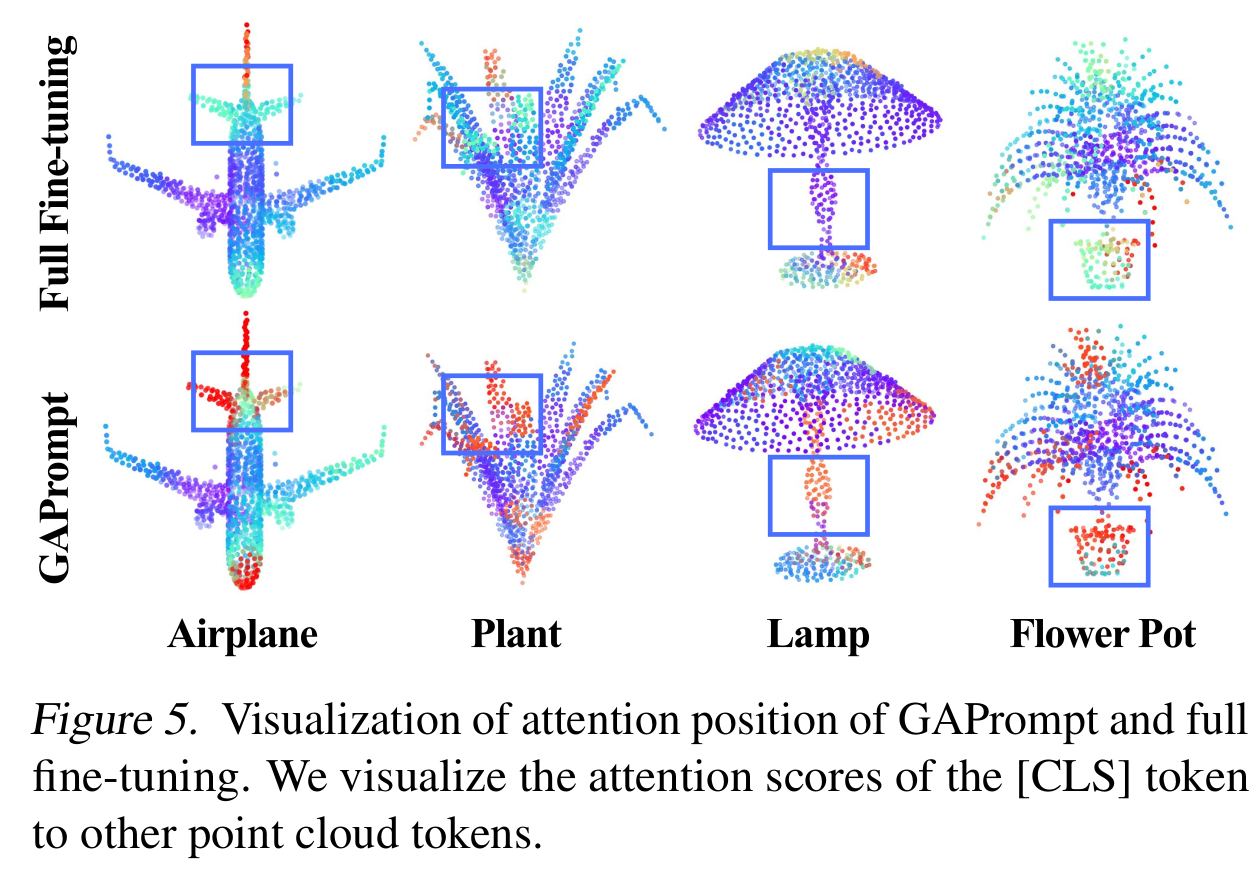
注意力位置的可视化
在图5中,作者分别可视化了GAPrompt和完全微调的[CLS]令牌的注意力位置,其中暖色表示更高的值。如图所示,GAPrompt的[CLS]令牌捕捉到更多关键的3D语义,如飞机的头部和垂直稳定器、灯的支架和花盆的盆。但完全微调的[CLS]令牌仅捕捉到垂直尾部和灯的底座。这表明,借助点云中固有的几何线索,GAPrompt有效地抓住了关键信息,进一步有利于点云理解。
移位点云的可视化
图6描绘了ScanObjectNN测试集中的原始点云和移位后的点云。原始点云嘈杂且分散,反映了真实世界数据固有的复杂性。请注意,绿色映射仅为方便识别。可以看到,由点移位提示器移位后的点云趋于更紧凑,边界更清晰,更易于识别,特别是在矩形突出显示的区域。这表明点移位提示器可以在输入层面增强点云的几何特征,从而有助于提高性能。此外,点云包含可学习的点提示,在训练过程中倾向于移动到点云的内部空间。

结论
在本文中,作者引入了几何感知点云提示(GAPrompt),这是一种专门针对预训练3D视觉模型的参数高效微调方法。作者发现捕捉特定实例的形状特征是增强提示几何感知的有效方法。为捕捉和利用点云中固有的几何线索,作者开发了点提示、点移位提示器和提示传播机制,极大地提升了提示的表示能力。作者的方法优于其他当前最先进的参数高效微调方法,并显著减少了可训练参数。
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。