Mysql杂志(十九)——InnoDB的索引结构
InnoDB的索引
上一篇我们说到了索引,但是索引结构其实并没有仔细去讲解,只是说了索引是一个树形结构,这一篇我们细锁一下,来说说InnoDB的索引吧,他呢就是典型的B+树的结构,特有的聚簇索引。
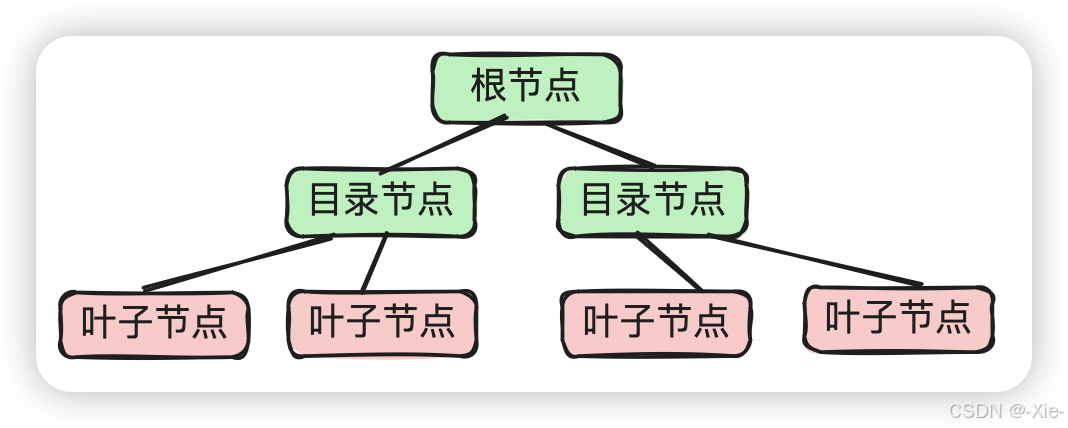
这个就是大概的一个树形结构,但是要知道InnoDB的根节点是永远不变的,就是不管存储了多少数据原始的根节点是不会改变的,根节点永远不变。假如我们建了一个表自然而然的就会创建这个索引,这个时候我们假设没有数据那么这个时候的根节点就是一个数据页里面没有一条数据,随着数据的增加一个数据页(默认16KB)饭不下了就会进行分裂,分裂之后原来的数据页就会变成目录页,流程如下: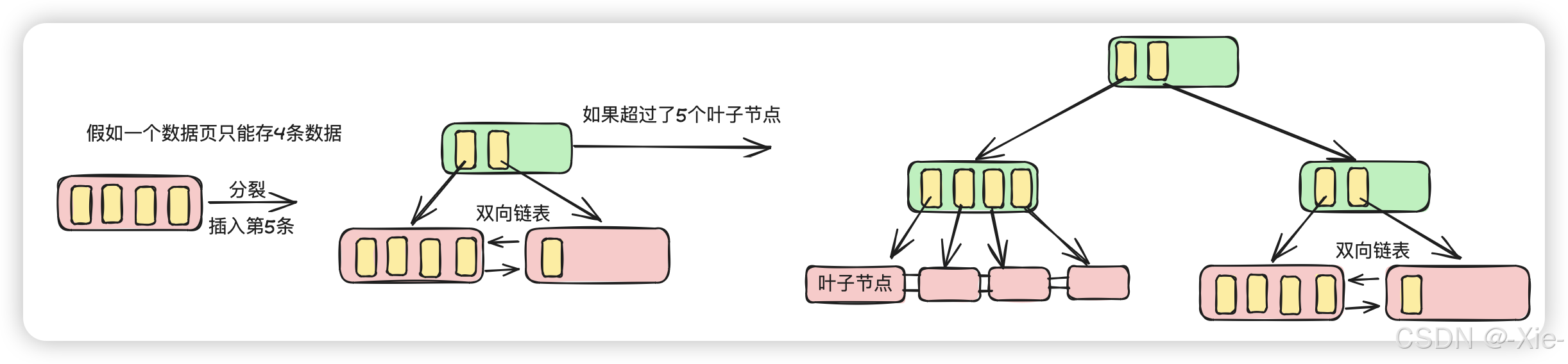
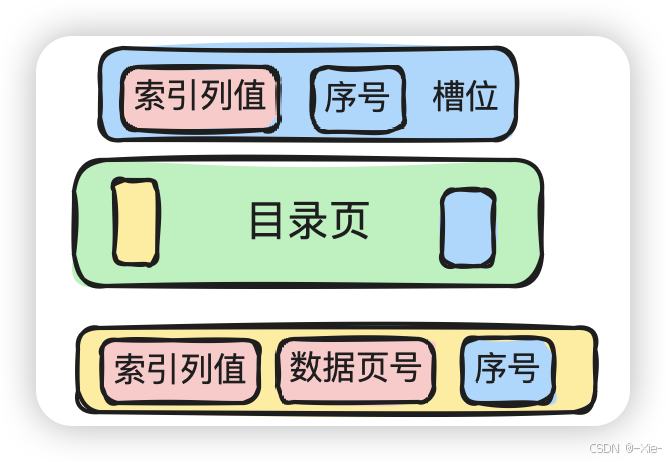
目录页:
[目录页16KB]
├─ 文件头 (38字节)
├─ 页头 (56字节)
├─ 索引头 (36字节)
├─ 记录列表(键值+指针)
│ ├─ 记录1: (min_key, child_page_no)
│ ├─ 记录2: (key2, child_page_no)
│ └─ ...
├─ 页目录(槽位数组)
├─ 空闲空间
└─ 文件尾 (8字节)组成部分 | 大小 | 存储内容说明 | 功能作用 |
|---|---|---|---|
文件头 | 38字节 | - 页号(4B) | 标识页基本信息,维护页链关系,提供崩溃恢复能力 |
页头 | 56字节 | - 槽位数量(2B) | 管理页内空间分配和记录组织 |
索引头 | 36字节 | - 索引层级(2B) | 维护索引树结构信息,支持事务和并发控制 |
记录列表 | 变长 | - 键值数组(有序) | 存储索引路由信息,每个条目包含: |
页目录(槽位) | 每槽位2字节 | - 槽位数组(稀疏索引) | 实现页内二分查找,通常每4-8条记录设置一个槽位 |
空闲空间 | 变长 | - 未使用的存储区域 | 用于后续插入新记录 |
文件尾 | 8字节 | - 校验和(4B) | 数据完整性校验,与文件头校验和配合使用 |
上面的这个作为了解就好了,细锁结构的我们留在下次说,这次我们主要讲索引,目录页顾名思义就是导航的,他的作用就是为了找到数据页的。
def find_leaf_page(root_page, target_id):# 这是在节点内部的槽位数组中查找low = 0high = root_page.num_entries - 1while low <= high:mid = (low + high) / 2 # 计算中间位置current_key = root_page.entries[mid].keyif target_id < current_key:high = mid - 1 # 向左半部分查找else:low = mid + 1 # 向右半部分查找# 此时high指向最后一个<=target_id的条目return root_page.entries[high].pointer
查找ID=1500的流程:
数据页一页存100条,槽位间隔假设为4,索引列为ID,假设数据有7k条,那就有70个数据页
槽位数组: [ (记录数组[0]指针地址), (记录数组[1]指针地址), (记录数组[2]指针地址), (记录数组[3]指针地址) , (记录数组[4]指针地址....,, (记录数组[16]指针地址))]第一次:high=17-1=16,low=0,mid=mid=low(0)+high(16)/2=8,low <= high?是
先利用指针地址找多对应的记录数组的值
比较1500与3200 -> 1500 < 3200 -> 向左,high=mid-1=7
第二次:mid=low(0)+high(7)/2=3,low <= high?是
比较1500与1200 -> 1500 > 1200 -> 向右,low=mid+1=4
第三次:mid=low(4)+high(7)/2=5,low <= high?是
比较1500与2000 -> 1500 < 2001 -> 向左,high=mid-1=4
第四次:low=4,high=4,low <= high?否,没有第四次循环结束。最终 high=4, 槽位数组[4]---->对应记录数组[3]再进行线性对比,也就是一个一个对比,
第一次:1500>1200 再对比
第二次:1500>1300 再对比
第三次:1500>1400 再对比
第四次:1500=1500 再对比 ,返回对应的数据页,
如果这个时候查找的ID是1554这种不是边界的值,就会再进行对比:
第五次:1554<1600 结束返回上一次对比的数据页,因为目录页记录的是当前数据页最小的索引值这个是伪代码,下面是主包手打的过程,大家仔细看看,其实查找都是通过槽位数组进行比较的,并不是所有的记录数组,因为一个槽位才2个字节而且槽位的间隔是4、6、8这几种,也就是对比记录数组的内存占用最少4倍,而我们进行运算都是在cpu中,大家应该也知道CPU中有L1级到L3级缓存,L1最快但是容量也最少,所有相对于把全部的记录数组放入cpu是不然槽位数组比对快的,而且使用使用槽位是二分法加线性对比,而记录数组全是二分法,二分法是随机读取是比顺序读取慢的。
数据页:
数据页和目录页其实是一样的结构,只是他们的类型不一样而已,下次我们说页的结构的时候会细锁这个,然后读取的方式也是一样的,使用的也是槽位数组的二分法和线性查找,因为数据页之间是双向链表天然利好线性对比,如果是聚簇索引会直接返回数据,然后是非聚簇索引也就是二级索引会先找对应的数据id,再查聚簇索引。
B+树索引的注意事项
1.根节点始终不变:
这个上面说过了,所有的目录页和数据页其实都是先从根节点分裂出来的。
2.尽量确保目录页记录数组的索引列数据唯一性,或者叫选择合适的列(高选择性):
这个是为什么呢?如果我们以name为列,假设我们表中全部都是一个名字,虽然索引不会报错,但是不亚于全扫描了,所以我们选择列做索引的时候需要选择区分度高的列,不容易重复的列。
3.最左前缀原则:
如果我们的二级索引是多个列组成的,一定先要确定顺序,都是先对左边的进行排序的,我们查询的时候也是左侧原则条件位置不对可能会造成索引不能命中。必须得有左侧的索引,不然就使用不到对应的索引,如果顺序不对没关系,我们的mysql优化器会帮我们调整顺序,之前在mysql逻辑结构里说过。
-- 创建复合索引
CREATE INDEX idx_name_age_city ON employees(last_name, first_name, city);-- 能使用索引的查询
SELECT * FROM employees WHERE last_name = 'Smith';
SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John';
SELECT * FROM employees WHERE last_name = 'Smith' AND first_name = 'John' AND city = 'New York';-- 不能使用索引(或不能完全使用)的查询
SELECT * FROM employees WHERE first_name = 'John'; -- 跳过了last_name
SELECT * FROM employees WHERE last_name = 'Smith' AND city = 'New York'; -- 跳过了first_name4. 避免过度索引:
因为INSERT、UPDATE、DELETE需要维护所有相关索引,降低写性能。还有就是索引占用磁盘和内存空间。
5.避免对索引列进行计算或函数操作:
-- 坏:索引失效
SELECT * FROM orders WHERE YEAR(order_date) = 2023;
SELECT * FROM products WHERE price * 1.1 > 100;-- 好:使用索引
SELECT * FROM orders WHERE order_date >= '2023-01-01' AND order_date < '2024-01-01';
SELECT * FROM products WHERE price > 100 / 1.1;6.注意LIKE查询的写法:
只有前缀匹配才能利用前缀索引,这个我们上一篇说过。想要词匹配就要使用全文索引了。
7.谨慎使用NOT、<>、!=:
B+树擅长查找“存在”的值,而不擅长证明“不存在”。这类操作通常会导致全索引扫描或全表扫描。
8.注意OR条件:
OR可能导致索引失效,尤其是涉及多个列时。
总结
本篇主要讲了InnoDB的索引结构和查找的流程,本来还想说一下MyISAM的但是篇幅太长了下篇讲吧。