【学习】通义DeepResearch之WebWalker-让大模型“深度潜水”网页信息
检索增强生成(RAG)在开放域问答任务中表现出卓越的性能。然而,传统搜索引擎可能会检索到浅层内容,限制了大型语言模型(LLMs)处理复杂、多层次信息的能力。为解决这一问题,我们引入了WebWalkerQA,这是一个旨在评估大型语言模型(LLMs)网页遍历能力的基准。它用于评估大型语言模型(LLMs)遍历网站子页面以系统性提取高质量数据的能力。我们提出了WebWalker,这是一个多智能体框架,通过探索-评判范式模拟人类的网页导航方式。大量实验结果表明,WebWalkerQA具有挑战性,并且通过在现实场景中的横向和纵向整合,证明了RAG与WebWalker相结合的有效性。
一、背景:RAG 的“天花板”
检索增强生成(RAG)几乎成了给大模型“续命”的标准方案,但传统搜索引擎只做横向召回:把一堆相关网页平铺到 LLM 眼前。
问题来了——真正关键的信息往往藏在第 N 层子页面里,LLM 看到的只是“目录”,而不是“正文”。在开放域问答等复杂任务里,这种浅层召回直接限制了模型的上限。
二、阿里做了什么?
阿里团队把“横向”与“纵向”检索拆开,做了两件事:
- 造了一个会考倒模型的题库——WebWalkerQA
- 写了一个会点按钮的 Agent——WebWalker
二者合体,把 RAG 升级成二维检索:横向找网页,纵向挖网页。
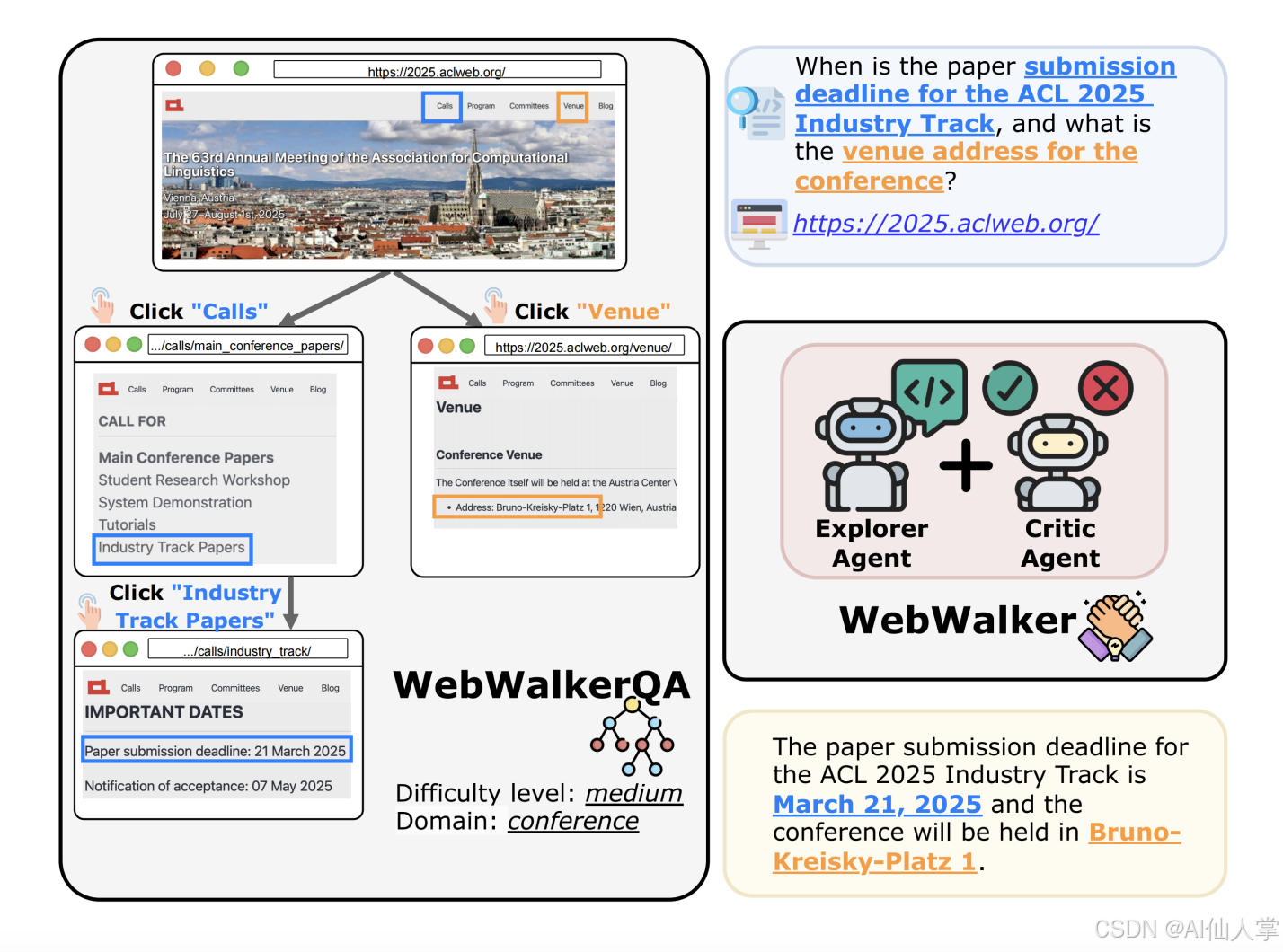
三、WebWalkerQA:680 道题的“地狱试卷”
| 维度 | 数据 |
|---|---|
| 题目 | 680 条(中英双语) |
| 网页 | 1 373 个真实页面 |
| 领域 | 会议、机构、教育、游戏 |
| 类型 | 单源 / 多源 |
| 难度 | 简单(2 跳)、中等(3 跳)、困难(4 跳) |
- 单源题:答案藏在同一条“链路”里,模型必须逐层点进去。
- 多源题:需要把多个分支的信息拼在一起才能回答。
- 跳数越深,正确率越低——GPT-4o 也只能拿到 40% 的分数,足见其挑战性 。
四、WebWalker:会“点击”的 Multi-Agent
框架极简,却极有效:
| 角色 | 任务 | 类比 |
|---|---|---|
| Explorer | 负责“点按钮”,用 ReAct 循环一路向下爬 | 侦察兵 |
| Critic | 每轮判断刚拿到的文本有没有用、够不够答 | 评审团 |
- Thought:LLM 分析当前页面
- Action:选择可点击元素(自动映射真实 URL)
- Observation:拿到新页面 Markdown + 截图
- Memory:Critic 把有效信息剪进“记忆池”
- 循环直到 Critic 认为“信息足够”→ 输出 Final Answer
整个流程在 Streamlit 里可视化,每一步点击、截图、思考、记忆更新都一目了然 。
五、实验结果:RAG × WebWalker 的“二维”威力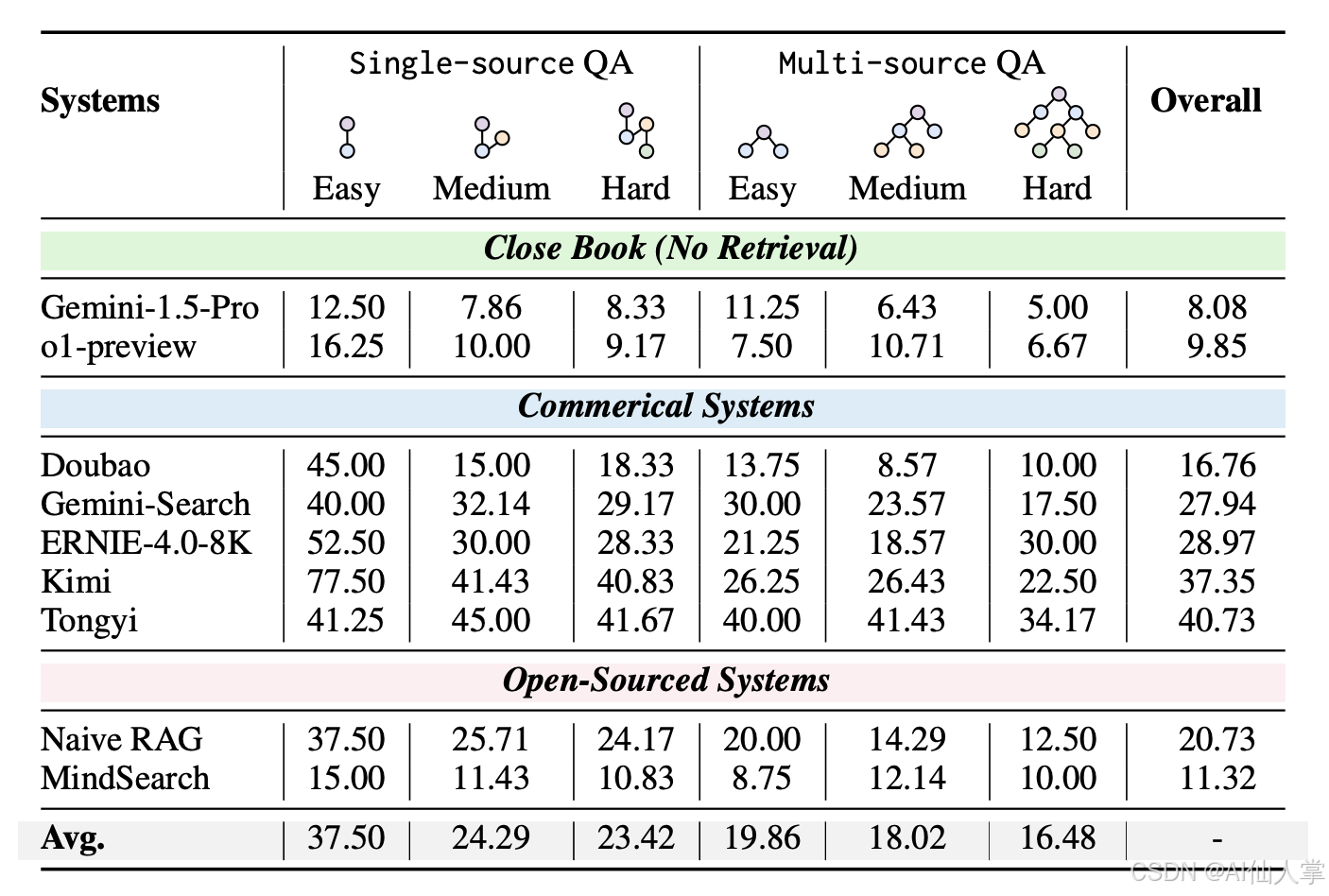
-
纯 RAG 已撞墙
最好系统(Tongyi)在 WebWalkerQA 上仅 40% 准确率,多源题更低 。 -
纯 WebWalker 也不完美
GPT-4o 做 backbone 才 38%,但纵向挖掘出的 memory 质量极高。 -
横向+纵向 = 真香
把 WebWalker 的 memory 拼回 RAG 的 context,所有难度段准确率再涨 5-10 个百分点,多源题提升最明显——首次验证“二维检索”在真实场景中的互补性 。 -
推理时 Scaling 新角度
增加 Explorer 点击预算 K,memory 越丰富,RAG 收益越大,为“test-time scale”提供了除“采样”之外的新维度 。
六、错误分析:模型的“不耐烦”
- 小模型易放弃:才点 2-3 层就强行给出答案,被作者戏称为“不耐烦现象”。
- 推理错误:即使翻到答案页,LLM 也因长上下文噪声而“视而不见”。
- 语言 & 领域:会议类网页按钮清晰,得分最高;中英双语表现接近,归功于基座模型双语 SFT 。
七、局限与未来
- 题库规模仍小,视觉信息(图片、PDF)尚未利用。
- WebWalker 没做任务级微调,完全零样本,后续可引入强化学习让“点击”更精准。
- 真实点击延迟高,作者计划把离线抓取 + 在线决策混合,降低成本。
八、WebWalker端到端工作流程
1. 问题接收与初始化
WebWalker接收用户查询后,首先进行系统初始化: File: WebAgent/WebWalker/src/agent.py (L22-46)
def __init__(self,function_list: Optional[List[Union[str, Dict, BaseTool]]] = None,llm: Optional[Union[Dict, BaseChatModel]] = None,system_message: Optional[str] = DEFAULT_SYSTEM_MESSAGE,name: Optional[str] = None,description: Optional[str] = None,files: Optional[List[str]] = None,**kwargs):super().__init__(function_list=function_list,llm=llm,system_message=system_message,name=name,description=description,files=files,**kwargs)self.extra_generate_cfg = merge_generate_cfgs(base_generate_cfg=self.extra_generate_cfg,new_generate_cfg={'stop': ['Observation:', 'Observation:\n']},)self.client = OpenAI(api_key=llm['api_key'], base_url=llm['model_server'],)self.llm_cfg = llmself.momery = []
- 配置LLM客户端和基础参数
- 初始化空的记忆列表
self.momery = [] - 设置查询参数
self.llm_cfg["query"] = query
2. 起始页面访问与观察
系统从指定的根URL开始遍历:File: WebAgent/WebWalker/src/app.py (L168-192)
start_prompt = "query:\n{query} \nofficial website:\n{website}".format(query=query, website=website)st.markdown('**🌐Now visit**')st.write(website)html, markdown, screenshot = asyncio.run(get_info(website))with col2:st.markdown('**📸Observation**')if screenshot:st.session_state.image_index = 0print("get screenshot!")image_folder = "images/"if not os.path.exists(image_folder):os.makedirs(image_folder)with open(image_folder+str(st.session_state.image_index)+".png", "wb") as f:f.write(base64.b64decode(screenshot))image_files = os.listdir(image_folder)image_files = [f for f in image_files if f.endswith(('.png', '.jpg', '.jpeg'))]image_path = os.path.join(image_folder, image_files[st.session_state.image_index])image = Image.open(image_folder+str(st.session_state.image_index)+".png")st.image(image, caption='Start Obervation', width=400)buttons = extract_links_with_text(html)response = "website information:\n\n" + markdown + "\n\n"response += "clickable button:\n\n" + buttons + "\n\nEach button is wrapped in a <button> tag"start_prompt += "\nObservation:" + response + "\n\n"messages.append({'role': 'user', 'content':start_prompt})
- 访问起始网页并获取HTML内容、Markdown文本和截图
- 通过
extract_links_with_text提取所有可点击按钮 - 构建初始观察结果,包含网页信息和可点击按钮列表
3. ReAct循环推理
核心推理循环在_run方法中执行:File: WebAgent/WebWalker/src/agent.py (L112-134)
def _run(self, messages: List[Message], lang: Literal['en', 'zh'] = 'en', **kwargs) -> Iterator[List[Message]]:text_messages = self._prepend_react_prompt(messages, lang=lang)num_llm_calls_available = MAX_LLM_CALL_PER_RUNresponse: str = 'Thought: 'query = self.llm_cfg["query"]action_count = self.llm_cfg.get("action_count", MAX_LLM_CALL_PER_RUN)num_llm_calls_available = action_countwhile num_llm_calls_available > 0:num_llm_calls_available -= 1output = []for output in self._call_llm(messages=text_messages):if output:yield [Message(role=ASSISTANT, content=output[-1].content)]# Accumulate the current responseif output:response += output[-1].contenthas_action, action, action_input, thought = self._detect_tool("\n"+output[-1].content)if not has_action:if "Final Answer: " in output[-1].content:breakelse:continue
每轮循环包含:
- Thought(思考):LLM分析当前情况并制定行动计划
- Action(行动):选择要执行的工具(如VisitPage)
- Action Input(行动输入):指定具体的按钮或参数
- Observation(观察):获取行动执行结果
4. 双阶段信息处理
阶段一:信息有用性评估
每次获得观察结果后,系统评估信息价值: File: WebAgent/WebWalker/src/agent.py (L48-75)
def observation_information_extraction(self, query, observation):user_prompt = "- Query: {query}\n- Observation: {observation}".format(query=query, observation=observation)messages = [{'role': 'system', 'content': STSTEM_CRITIIC_INFORMATION},{'role': 'user', 'content': user_prompt}]max_retries = 10for attempt in range(max_retries):try:response = self.client.chat.completions.create(model=self.llm_cfg['model'],response_format={"type": "json_object"},messages=messages)print(response.choices[0].message.content)# response_content = json.loads(response.choices[0].message.content)if "true" in response.choices[0].message.content:try:return json.loads(response.choices[0].message.content)["information"]except:return response.choices[0].message.contentelse:return Noneexcept Exception as e:print(e)if attempt < max_retries - 1:time.sleep(1 * (2 ** attempt)) # Exponential backoffelse:raise e # Raise the exception if the last retry fails
- 使用
STSTEM_CRITIIC_INFORMATION提示模板 - 判断观察结果是否包含与查询相关的有用信息
- 如果有用,提取关键信息并添加到记忆中
阶段二:答案充分性判断
当记忆中积累信息后,评估是否足以回答查询: File: WebAgent/WebWalker/src/agent.py (L77-110)
def critic_information(self, query, memory): memory = "-".join(memory)user_prompt = "- Query: {query}\n- Accumulated Information: {memory}".format(query = query, memory=memory)messages = [{'role': 'system', 'content': STSTEM_CRITIIC_ANSWER},{'role': 'user', 'content': user_prompt}]response = self.client.chat.completions.create(model=self.llm_cfg['model'],response_format={"type": "json_object"},messages=messages)max_retries = 10for attempt in range(max_retries):try:response = self.client.chat.completions.create(model=self.llm_cfg['model'],response_format={"type": "json_object"},messages=messages)print(response.choices[0].message.content)if "true" in response.choices[0].message.content:try:return json.loads(response.choices[0].message.content)["answer"]except:return response.choices[0].message.contentelse:return Noneexcept Exception as e:print(e)if attempt < max_retries - 1:time.sleep(1 * (2 ** attempt)) # Exponential backoffelse:raise e # Raise the exception if the last retry fails
- 使用
STSTEM_CRITIIC_ANSWER提示模板 - 综合评估累积的所有信息
- 如果信息充分,直接生成最终答案
5. 网页导航与交互
当需要访问新页面时:File: WebAgent/WebWalker/src/app.py (L228-266)
def call(self, params: str, **kwargs) -> str:if not params.strip().endswith("}"):if "}" in params.strip():params = "{" + get_content_between_a_b("{","}",params) + "}"else:if not params.strip().endswith("\""):params = params.strip() + "\"}"else:params = params.strip() + "}"params = "{" + get_content_between_a_b("{","}",params) + "}"if 'button' in json5.loads(params):with open("BUTTON_URL_ADIC.json", "r") as f:BUTTON_URL_ADIC = json.load(f)if json5.loads(params)['button'].replace("<button>","") in BUTTON_URL_ADIC:st.markdown('**👆Click Button**')st.write(json5.loads(params)['button'].replace("<button>",""))url = BUTTON_URL_ADIC[json5.loads(params)['button'].replace("<button>","")]html, markdown, screenshot = asyncio.run(get_info(url))st.markdown('**🌐Now Visit**')st.write(url)with col2:st.write("")st.markdown('**📸Observation**')if screenshot:print("get screenshot!")image_folder = "images/"with open(image_folder+str(st.session_state.image_index+1)+".png", "wb") as f:f.write(base64.b64decode(screenshot))st.session_state.image_index += 1image = Image.open(image_folder+str(st.session_state.image_index)+".png")st.image(image, caption='Step ' + str(st.session_state.image_index) + ' Obervation', width=400)response_bottons = extract_links_with_text(html)response_content = markdownif response_content:response = "The web informtaion if:\n\n" + response_content + "\n\n"else:response = "The information of the current page is not accessible\n\n"response += "Clickable buttons are wrapped in <button> tag" + response_bottons
- 解析智能体选择的按钮文本
- 从
BUTTON_URL_ADIC.json映射文件中找到对应URL - 访问新页面并提取内容和按钮
- 生成新的观察结果供下一轮推理使用
6. 记忆管理与累积
系统通过记忆机制管理信息:File: WebAgent/WebWalker/src/agent.py (L139-145)
stage1 = self.observation_information_extraction(query, observation)if stage1:self.momery.append(stage1+"\n")if len(self.momery) > 1:yield [Message(role=ASSISTANT, content= "Memory:\n" + "-".join(self.momery)+"\"}")]else:yield [Message(role=ASSISTANT, content= "Memory:\n" + "-" + self.momery[0]+"\"}")]
- 将有用信息添加到
self.momery列表 - 在界面中显示记忆更新状态
- 为后续的答案判断提供信息基础
7. 终止条件与答案生成
WebWalker通过三种方式结束遍历:
方式1:信息充分终止
最理想的终止方式: File: WebAgent/WebWalker/src/agent.py (L146-150)
stage2 = self.critic_information(query, self.momery)if stage2:response = f'Final Answer: {stage2}'yield [Message(role=ASSISTANT, content=response)]break
- 当
critic_information判断信息充分时 - 生成
Final Answer并结束
方式2:轮次限制终止
资源保护机制:
- 当达到最大轮次限制时强制停止
方式3:显式答案终止
LLM主动结束:
- 当输出包含"Final Answer: "时直接停止
8. 提示工程支持
整个流程由三个专门的提示模板驱动:File: WebAgent/WebWalker/src/prompts.py (L1-65)
SYSTEM_EXPLORER = """Digging through the buttons to find quailty sources and the right information. You have access to the following tools:{tool_descs}Use the following format:Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more 20 times)Notice:
- You must take action at every step. When you take action, you must use the tool with the correct format and output the action input.
- When you can not find the information you need, you should visit page of previous page recursively until you find the information you need.
- You can not say "I'm sorry, but I cannot assist with this request."!!! You must explore.
- You do not need to provide the final answer, but you must explore.
- Action Input should be valid JSON.Begin!{query}
"""STSTEM_CRITIIC_INFORMATION = """You are an information extraction agent. Your task is to analyze the given observation and extract information relevant to the current query. You need to decide if the observation contains useful information for the query. If it does, return a JSON object with a "usefulness" value of true and an "information" field with the relevant details. If not, return a JSON object with a "usefulness" value of false.**Input:**
- Query: "<Query>"
- Observation: "<Current Observation>"**Output (JSON):**
{"usefulness": true,"information": "<Extracted Useful Information> using string format"
}
Or, if the observation does not contain useful information:
{"usefulness": false
}
Only respond with valid JSON."""STSTEM_CRITIIC_ANSWER = """You are a query answering agent. Your task is to evaluate whether the accumulated useful information is sufficient to answer the current query. If it is sufficient, return a JSON object with a "judge" value of true and an "answer" field with the answer. If the information is insufficient, return a JSON object with a "judge" value of false.**Input:**
- Query: "<Query>"
- Accumulated Information: "<Accumulated Useful Information>"**Output (JSON):**
{"judge": true,"answer": "<Generated Answer> using string format"
}
Or, if the information is insufficient to answer the query:
{"judge": false
}
Only respond with valid JSON.
"""
- SYSTEM_EXPLORER:定义ReAct格式和探索规则
- STSTEM_CRITIIC_INFORMATION:评估观察结果有用性
- STSTEM_CRITIIC_ANSWER:判断答案充分性
9. 用户界面反馈
在Streamlit界面中,用户可以实时看到:
- 智能体的思考过程
- 记忆更新状态
- 最终答案输出
WebWalker的完整工作流程体现了一个端到端的智能网页遍历系统:从问题接收开始,通过ReAct循环进行推理和导航,利用双阶段信息处理机制进行智能筛选,最终通过多种终止条件确保生成高质量答案。整个流程既保证了探索的全面性,又通过记忆管理和智能判断确保了效率和准确性。
九、写在最后
WebWalker 让大模型第一次像人类一样“翻网页”:
- 横向,RAG 快速圈定相关站点;
- 纵向,Agent 逐层深挖,把被搜索引擎忽略的暗信息拖进上下文。
当“横向召回”卷到尽头,“纵向交互”或许就是 RAG 的下一个 10 分点。如果你也在做知识密集型应用,不妨把 WebWalker 的 memory 模块搬进自己的链路,让搜索从“平面”走向“立体”。
论文 & 代码已开源
论文:arXiv:2501.07572
代码:Alibaba-nlp/WebWalker