AI智能体开发实战:从提示工程转向上下文工程的完整指南
还记得去年各大公司给提示工程师开出30万美元年薪的疯狂时期吗?现在这些招聘信息基本销声匿迹了。从技术角度看,提示工程确实有些"投机取巧"的意味——本质上就是让人们相信自己在做"工程"工作的华丽包装。
不过现在情况完全不同了。人们开始把传统软件工程的严谨方法和大语言模型的能力结合起来。这篇文章会深入探讨如何构建真正可扩展、生产环境稳定的智能体工作流。
上下文工程才是核心
虽然我从一开始就对提示工程持保留态度,但不得不承认这个领域的确积累了不少有价值的经验。没有万能的提示技巧,但针对特定数据集和场景,某些提示方法确实能带来明显的性能提升。
既然特定的提示技巧能让语言模型表现更好,我们当然应该了解这个技术图谱,合理运用各种提示方法。
关键在于,单纯的提示远远不够——它只是"上下文工程"的一个小组成部分。
软件开发最初采用有向图结构,类似流程图的形式来表示顺序或分支逻辑。后来出现了Apache Airflow、Prefect、Dagster这些工具,将工作流正式化为DAG,支持监控、重试、模块化和可观测性。
随着机器学习的发展ML模型变得实用起来,DAG开始嵌入模型处理步骤(比如分类、摘要),但整体还是确定性的——LLM只是静态流水线中的一个环节。
智能体的出现改变了这种静态DAG的局限。你不需要编码每一个步骤,而是定义目标和允许的状态转换,让LLM来动态规划执行路径。这意味着代码量更少,错误恢复能力更强,智能体的行为也更具创造性和适应性。
微智能体模式的工作原理很直接:
LLM生成JSON格式的工具调用(下一步动作),确定性代码执行这个调用,将结果追加到上下文中,然后重复这个过程直到任务完成。
这种方式用灵活的迭代工作流取代了固定的DAG执行。
上下文增长会导致智能体"漂移",出现重复动作或失去连贯性的问题。长上下文窗口(10-20轮对话)会严重降低可靠性,即使是高质量的LLM在这种情况下也会表现不佳。
许多研究表明,LLM在超过32k上下文窗口后可靠性显著下降,即便它们能处理百万级token。上下文越长,产生幻觉的概率就越高。
自然语言到工具调用的转换
软件本质上就是控制信息流,使用自由形式的LLM(大多数情况下)帮助不大。我们真正需要的是结构化、可控的输出。
结构化输出通过将意图绑定到明确定义的操作来防止歧义和执行错误,同时支持确定性程序执行,让智能体行为变得可预测和可追踪。
每个智能体动作都应该对应一个离散、定义明确的工具调用(比如"summarize_email"、"deploy_service")。要避免多步骤或模糊的指令,力求每次调用都是单一意图的转换。
如果模型对意图不确定(置信度低于阈值),应该升级到人工干预,而不是冒险执行错误的操作。

用户输入:“Show me tomorrow’s meetings.”
智能体输出:
{ "action": "get_calendar_events", "date": "2025‑08‑05" }
掌控提示内容
始终完全控制你的提示内容——把提示当作一等公民的软件工件,而不是不透明的抽象层或框架管理的黑盒。

提示即函数的模式示例:
function determineNextStep(thread: string): NextStep { prompt = ` You are a helpful assistant that manages deployments. Conversation: ${thread} What should the next step be? `
}

掌控提示的核心优势包括:
完全控制意味着你能精确编写智能体需要的指令,不存在黑盒抽象;测试和评估方面,你可以像测试其他代码一样测试和评估提示;快速迭代,基于实际表现修改提示;透明性,清楚知道智能体在使用什么指令;角色"黑客"技巧,利用支持非标准user/assistant角色用法的API,比如已弃用的非聊天版OpenAI “completions” API,包括一些"model gaslighting"技术。
注意: 提示是应用逻辑和LLM之间的主要接口。
完全控制提示为生产级智能体提供了必需的灵活性和可控性。我不知道什么是"最佳提示",但我知道你需要能够尝试所有方法的灵活性。
上下文窗口的精准管理
控制对软件来说就是一切。Karpathy的建议永远值得听。

要有意识地设计上下文,而不是被动地通过聊天日志或一刀切的消息格式来填充。

为什么这很关键
信息效率:XML/YAML等结构化格式能用更少的token表达更多含义,最大化稀缺的上下文容量。错误恢复:在上下文中记录工具输出和错误状态,让模型能够推理出错的原因并智能重试。隐私和安全:主动排除无关或敏感数据,降低风险并满足合规要求。格式灵活性:随着系统演进调整schema,在运行时重构或裁剪条目。与工具和记忆的集成:上下文可以嵌入RAG检索的文档、过去的工具调用和记忆摘要,支持更丰富的推理。
掌控上下文窗口的关键好处:信息密度最大化LLM的理解;错误处理以帮助LLM恢复的格式包含错误信息,考虑在错误解决后从上下文中隐藏它们;安全性控制传递给LLM的信息,过滤敏感数据;灵活性随着用例学习调整格式;Token效率为token效率和LLM理解优化上下文格式。
工具作为结构化输出
不要把工具调用当作黑盒API代理,而应该视为显式的、结构化的决策文档——通常是JSON格式——包含明确定义的字段。这些输出是LLM推理和实际执行动作的确定性软件之间的接口。
定义一个显式schema(比如通过JSON Schema或类型化数据类)来强制包含关键字段,如action_type、target、可选元数据和confidence_score。例如:
{ "action": "deploy_service", "service": "backend", "version": "v1.2.3", "requires_approval": true, "confidence": 0.92
}

关于"纯文本提示" vs “工具调用” vs "JSON模式"的优劣以及各自的性能权衡,已经有很多讨论了,这里就不细说了
统一执行状态和业务状态
即使在非AI领域,许多基础设施系统也试图分离"执行状态"和"业务状态"。对于AI应用这可能涉及复杂的抽象来跟踪当前步骤、下一步、等待状态、重试次数等。这种分离会带来复杂性,有时是值得的,但对你的用例可能是过度设计。
选择权在你手里。但不要认为你必须分别管理它们。
执行状态包括当前步骤、下一步、等待状态、重试次数等;业务状态是智能体工作流到目前为止发生的事情(比如OpenAI消息列表、工具调用和结果列表等)。
如果可能的话,简化——尽最大可能统一这些状态。

这种方法有几个好处:
简单性——所有状态的单一真实来源;
序列化——线程可以轻松序列化/反序列化;
调试——整个历史在一个地方可见;
灵活性——通过添加新事件类型就能轻松添加新状态;
恢复——通过加载线程就能从任何点恢复;
分叉——通过将线程的某个子集复制到新的上下文/状态ID,可以在任何点分叉线程;
人类界面和可观测性——轻松将线程转换为人类可读的markdown或丰富的Web应用UI。
用户、应用、流水线和其他智能体应该能够通过简单的API启动智能体。智能体及其编排的确定性代码应该能在需要长时间运行的操作时暂停智能体。webhook等外部触发器应该能让智能体从中断的地方恢复,而不需要与智能体编排器深度集成。

生命周期管理:启动、暂停、恢复
默认情况下,LLM API依赖一个根本性的高风险token选择:我们是返回纯文本内容,还是返回结构化数据?


好处:
清晰指令——不同类型人类交互的工具让LLM能给出更具体的指令;内环vs外环——支持传统ChatGPT风格界面之外的智能体工作流,控制流和上下文初始化可能是Agent->Human而不是Human->Agent(想想由cron或事件触发的智能体);多人类访问——通过结构化事件轻松跟踪和协调不同人类的输入;多智能体——简单抽象可以轻松扩展以支持Agent->Agent请求和响应;持久性——结合上述因素,这使得持久、可靠、可检查的多人工作流成为可能。
控制流的自主管理
如果你掌控控制流,就能做很多有趣的事情。完全控制智能体的主要"思考-行动循环":由你决定何时迭代、暂停、升级或停止。不要把工作流排序交给LLM,把逻辑保留在确定性代码中。
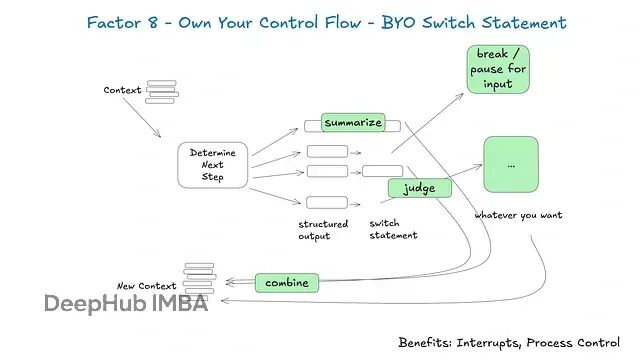
构建适合特定用例的自定义控制结构。特别是,某些类型的工具调用可能需要跳出循环,等待人类响应或其他长时间运行的任务(如训练流水线)。你可能还想要合并自定义实现:工具调用结果的摘要或缓存;基于结构化输出的LLM判断;上下文窗口压缩或其他记忆管理;日志记录、追踪和指标;客户端速率限制;持久睡眠/暂停/“等待事件”。
使用结构化循环(伪代码示例)
while not done: decision = determine_next_step(prompt_from(thread)) if decision.intent == "request_clarification": send_human_contact(decision) save_state(thread) break # pause until human responds elif decision.intent == "fetch_data": result = call_tool(decision) thread.events.append({"type": decision.intent + "_result", "data": result}) continue # proceed to next loop iteration elif decision.intent == "trigger_action": execute_action(decision) done = True
这允许在立即执行工具、暂停等待人类输入或终止之间进行受控分支。
我对所有AI框架的头号功能请求是:我们需要能够中断正在工作的智能体并稍后恢复,特别是在工具选择和工具调用执行之间。
没有这种级别的可恢复性/粒度,就无法在工具调用执行前审查/批准,这意味着你被迫选择:在等待长时间运行的任务完成时将任务暂停在内存中(比如while...sleep),如果进程中断就从头重新开始;将智能体限制为只能进行低风险、低价值的调用,如研究和摘要;给智能体访问权限做更大、更有用的事情,然后祈祷它不会搞砸。
错误信息的上下文压缩
这部分比较简短但值得一提。智能体的一个好处是"自愈"——对于短任务,LLM可能调用某个工具失败。好的LLM有相当高的机会读取错误消息或堆栈跟踪,并找出在后续工具调用中需要更改的内容。
大多数框架都实现了这一点,但你也可以只做这一件事而不做其他任何因素。示例:
while True: next_step = await determine_next_step(thread_to_prompt(thread)) thread["events"].append({ "type": next_step.intent, "data": next_step, }) try: result = await handle_next_step(thread, next_step) # our switch statement except Exception as e: # if we get an error, we can add it to the context window and try again thread["events"].append({ "type": 'error', "data": format_error(e), }) # loop, or do whatever else here to try to recover
你可能想为特定工具调用实现一个errorCounter,将单个工具的尝试限制在大约3次,或者其他适合你用例的逻辑。
好处:
自愈——LLM可以读取错误消息并找出在后续工具调用中需要更改的内容;持久性——即使一个工具调用失败,智能体也可以继续运行。
我确信如果你做得过多,智能体会开始失控,可能会一遍又一遍地重复同样的错误。
模块化、可访问和无状态
智能体应该是特定领域的,范围有限(通常3-20步),避免单体工作流。
减少上下文窗口漂移;提高可靠性、可测试性、调试性和推理清晰度;支持可组合性——团队可以独立演进或扩展智能体。
智能体应该由任何相关触发器激活——Slack、电子邮件、SMS、webhook、cron或其他事件——并通过同一渠道响应。
增强可访问性和采用度——智能体成为数字同事;支持"外环"自动化:智能体在触发时自主运行,需要时升级到人类;通过将用户监督集成到自然工作流中,实现高风险操作。
将智能体设计为纯函数:给定输入状态(来自上下文/历史)和触发器,产生新状态+工具调用/输出。智能体本身在运行之间不保持内部状态。
促进确定性行为——给定相同输入,智能体输出是可重现的;支持水平扩展:任何实例都可以处理任何请求;简化测试、调试、重放和审计。

作者:Vishal Rajput